
MediaPipe 동작 인식기 태스크를 사용하면 손 동작을 실시간으로 인식하고 인식된 손 동작 결과와 감지된 손의 손 지형지물을 제공할 수 있습니다. 이 안내에서는 웹 및 JavaScript 앱에서 동작 감지기를 사용하는 방법을 보여줍니다.
데모를 보면서 이 작업이 실행되는 모습을 확인할 수 있습니다. 이 태스크의 기능, 모델, 구성 옵션에 관한 자세한 내용은 개요를 참고하세요.
코드 예
동작 감지기의 예시 코드는 참고용으로 JavaScript에서 이 작업을 완전히 구현합니다. 이 코드는 이 작업을 테스트하고 자체 동작 인식 앱을 빌드하는 데 도움이 됩니다. 웹브라우저만 사용하여 동작 감지기 예시 코드를 보고, 실행하고, 수정할 수 있습니다.
설정
이 섹션에서는 특히 동작 감지기를 사용하도록 개발 환경을 설정하는 주요 단계를 설명합니다. 플랫폼 버전 요구사항을 비롯한 웹 및 JavaScript 개발 환경 설정에 관한 일반적인 정보는 웹 설정 가이드를 참고하세요.
JavaScript 패키지
동작 감지기 코드는 MediaPipe @mediapipe/tasks-vision
NPM 패키지를 통해 사용할 수 있습니다. 플랫폼 설정 가이드의 안내에 따라 이러한 라이브러리를 찾아 다운로드할 수 있습니다.
다음 명령어를 사용하여 NPM을 통해 필요한 패키지를 설치할 수 있습니다.
npm install @mediapipe/tasks-vision
콘텐츠 전송 네트워크 (CDN) 서비스를 통해 작업 코드를 가져오려면 HTML 파일의 <head> 태그에 다음 코드를 추가합니다.
<!-- You can replace JSDeliver with another CDN if you prefer to -->
<head>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision/vision_bundle.mjs"
crossorigin="anonymous"></script>
</head>
모델
MediaPipe 동작 인식기 태스크를 실행하려면 이 태스크와 호환되는 학습된 모델이 필요합니다. 동작 감지기에 사용할 수 있는 학습된 모델에 관한 자세한 내용은 작업 개요 모델 섹션을 참고하세요.
모델을 선택하고 다운로드한 후 프로젝트 디렉터리 내에 저장합니다.
<dev-project-root>/app/shared/models/
할 일 만들기
동작 감지기 createFrom...() 함수 중 하나를 사용하여 추론 실행 작업을 준비합니다. 학습된 모델 파일의 상대 또는 절대 경로와 함께 createFromModelPath() 함수를 사용합니다.
모델이 이미 메모리에 로드된 경우 createFromModelBuffer() 메서드를 사용할 수 있습니다.
아래의 코드 예는 createFromOptions() 함수를 사용하여 태스크를 설정하는 방법을 보여줍니다. createFromOptions 함수를 사용하면 구성 옵션으로 동작 인식기를 맞춤설정할 수 있습니다. 구성 옵션에 관한 자세한 내용은 구성 옵션을 참고하세요.
다음 코드는 맞춤 옵션으로 작업을 빌드하고 구성하는 방법을 보여줍니다.
// Create task for image file processing:
const vision = await FilesetResolver.forVisionTasks(
// path/to/wasm/root
"https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision@latest/wasm "
);
const gestureRecognizer = await GestureRecognizer.createFromOptions(vision, {
baseOptions: {
modelAssetPath: "https://storage.googleapis.com/mediapipe-tasks/gesture_recognizer/gesture_recognizer.task"
},
numHands: 2
});
구성 옵션
이 작업에는 웹 애플리케이션의 다음과 같은 구성 옵션이 있습니다.
| 옵션 이름 | 설명 | 값 범위 | 기본값 |
|---|---|---|---|
runningMode |
태스크의 실행 모드를 설정합니다. 모드는 두 가지가 있습니다. IMAGE: 단일 이미지 입력의 모드입니다. 동영상: 동영상의 디코딩된 프레임 또는 카메라와 같은 입력 데이터의 라이브 스트림에 관한 모드입니다. |
{IMAGE, VIDEO} |
IMAGE |
num_hands |
GestureRecognizer는 최대 GestureRecognizer개의 손을 감지할 수 있습니다.
|
Any integer > 0 |
1 |
min_hand_detection_confidence |
손바닥 감지 모델에서 손 감지가 성공으로 간주되기 위한 최소 신뢰도 점수입니다. | 0.0 - 1.0 |
0.5 |
min_hand_presence_confidence |
손 지형지물 감지 모델에서 손 존재 점수의 최소 신뢰도 점수입니다. 동작 인식기의 동영상 모드 및 라이브 스트림 모드에서 손 랜드마크 모델의 손 존재 신뢰도 점수가 이 기준점 미만이면 손바닥 감지 모델이 트리거됩니다. 그렇지 않으면 경량 손 추적 알고리즘을 사용하여 후속랜드마크 감지를 위한 손의 위치를 결정합니다. | 0.0 - 1.0 |
0.5 |
min_tracking_confidence |
손 추적이 성공으로 간주되는 최소 신뢰도 점수입니다. 현재 프레임과 마지막 프레임의 손 사이의 경계 상자 IoU 임곗값입니다. 동작 인식기의 동영상 모드 및 스트림 모드에서 추적이 실패하면 동작 인식기가 손 감지를 트리거합니다. 그렇지 않으면 손 감지가 건너뜁니다. | 0.0 - 1.0 |
0.5 |
canned_gestures_classifier_options |
사전 준비된 동작 분류기 동작을 구성하기 위한 옵션입니다. 미리 준비된 동작은 ["None", "Closed_Fist", "Open_Palm", "Pointing_Up", "Thumb_Down", "Thumb_Up", "Victory", "ILoveYou"]입니다. |
|
|
custom_gestures_classifier_options |
맞춤 동작 분류기 동작을 구성하기 위한 옵션입니다. |
|
|
데이터 준비
동작 감지기는 호스트 브라우저에서 지원하는 모든 형식의 이미지에서 동작을 인식할 수 있습니다. 이 작업은 크기 조절, 회전, 값 정규화 등 데이터 입력 전처리도 처리합니다. 동영상에서 동작을 인식하려면 API를 사용하여 한 번에 하나의 프레임을 빠르게 처리하고 프레임의 타임스탬프를 사용하여 동영상 내에서 동작이 발생하는 시점을 결정할 수 있습니다.
태스크 실행
동작 인식기는 recognize() (실행 모드 'image' 사용) 및 recognizeForVideo() (실행 모드 'video' 사용) 메서드를 사용하여 추론을 트리거합니다. 태스크는 데이터를 처리하고 손 동작을 인식하려고 시도한 후 결과를 보고합니다.
다음 코드는 태스크 모델로 처리를 실행하는 방법을 보여줍니다.
이미지
const image = document.getElementById("image") as HTMLImageElement; const gestureRecognitionResult = gestureRecognizer.recognize(image);
동영상
await gestureRecognizer.setOptions({ runningMode: "video" }); let lastVideoTime = -1; function renderLoop(): void { const video = document.getElementById("video"); if (video.currentTime !== lastVideoTime) { const gestureRecognitionResult = gestureRecognizer.recognizeForVideo(video); processResult(gestureRecognitionResult); lastVideoTime = video.currentTime; } requestAnimationFrame(() => { renderLoop(); }); }
동작 감지기 recognize() 및 recognizeForVideo() 메서드 호출은 동기식으로 실행되고 사용자 인터페이스 스레드를 차단합니다. 기기 카메라의 동영상 프레임에서 동작을 인식하면 각 인식은 기본 스레드를 차단합니다. 웹 워커를 구현하여 recognize() 및 recognizeForVideo() 메서드를 다른 스레드에서 실행하면 이를 방지할 수 있습니다.
동작 감지기 작업 실행의 더 완전한 구현은 코드 예시를 참고하세요.
결과 처리 및 표시
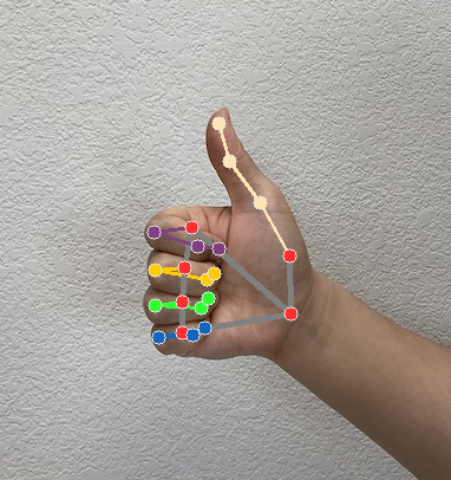
동작 인식기는 각 인식 실행에 대해 동작 감지 결과 객체를 생성합니다. 결과 객체에는 이미지 좌표의 손 지형지물, 세계 좌표의 손 지형지물, 손잡이(왼손/오른손), 감지된 손의 손 동작 카테고리가 포함됩니다.
다음은 이 태스크의 출력 데이터 예시입니다.
결과 GestureRecognizerResult에는 4개의 구성요소가 포함되며 각 구성요소는 배열입니다. 여기서 각 요소는 감지된 단일 손의 감지 결과를 포함합니다.
주로 사용하는 손
손잡이는 감지된 손이 왼손인지 오른손인지 나타냅니다.
동작
감지된 손의 인식된 동작 카테고리입니다.
명소
손 랜드마크는 21개 있으며 각 랜드마크는
x,y,z좌표로 구성됩니다.x및y좌표는 각각 이미지 너비와 높이에 따라 [0.0, 1.0] 으로 정규화됩니다.z좌표는 랜드마크 깊이를 나타내며, 손목의 깊이가 원점입니다. 값이 작을수록 랜드마크가 카메라에 가까워집니다.z의 크기는x와 거의 동일한 크기를 사용합니다.세계 명소
21개의 손 랜드마크도 세계 좌표로 표시됩니다. 각 랜드마크는
x,y,z로 구성되며, 손의 기하학적 중심을 원점으로 하는 실제 3D 좌표를 미터 단위로 나타냅니다.
GestureRecognizerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Gestures:
Categories #0:
score : 0.76893
categoryName : Thumb_Up
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
다음 이미지는 태스크 출력의 시각화를 보여줍니다.
동작 감지기 작업 만들기의 더 완전한 구현은 코드 예시를 참고하세요.