

Zadanie MediaPipe Pose Landmarker umożliwia wykrywanie punktów orientacyjnych ciała ludzkiego na obrazie lub filmie. Za pomocą tego zadania możesz identyfikować kluczowe części ciała, analizować postawę oraz kategoryzować ruchy. To zadanie korzysta z modeli systemów uczących się, które działają z pojedynczymi obrazami lub filmami. Zadanie wyprowadza punkty orientacyjne postawy ciała w współrzędnych obrazu i w trójwymiarowych współrzędnych świata.
Rozpocznij
Aby zacząć korzystać z tego zadania, postępuj zgodnie z instrukcjami implementacji dla wybranej platformy docelowej. Te przewodniki dotyczące poszczególnych platform zawierają podstawowe informacje o wdrażaniu tego zadania, w tym zalecany model i przykład kodu z zalecanymi opcjami konfiguracji:
- Android – przykład kodu – przewodnik
- Python – przykład kodu – przewodnik
- Web – przykład kodu – przewodnik
Szczegóły działania
W tej sekcji opisano możliwości, dane wejściowe, dane wyjściowe i opcje konfiguracji tego zadania.
Funkcje
- Przetwarzanie wejściowego obrazu – przetwarzanie obejmuje obrót, zmianę rozmiaru, normalizację i konwersję przestrzeni barw.
- Progień wyniku – filtrowanie wyników według progu wyniku prognozy.
| Dane wejściowe zadania | Dane wyjściowe |
|---|---|
Model Pose Landmarker przyjmuje dane wejściowe w jednym z tych typów:
|
Wyznaczanie punktów orientacyjnych pozy zwraca te wyniki:
|
Opcje konfiguracji
To zadanie ma te opcje konfiguracji:
| Nazwa opcji | Opis | Zakres wartości | Wartość domyślna |
|---|---|---|---|
running_mode |
Ustawia tryb działania zadania. Dostępne są 3 tryby: OBRAZ: tryb dla pojedynczych obrazów wejściowych. FILM: tryb dekodowanych klatek filmu. LIVE_STREAM: tryb transmisji na żywo danych wejściowych, takich jak dane z kamery. W tym trybie należy wywołać metodę resultListener, aby skonfigurować odbiornik, który będzie asynchronicznie odbierał wyniki. |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
num_poses |
Maksymalna liczba poz, które może wykryć Landmarker poz. | Integer > 0 |
1 |
min_pose_detection_confidence |
Minimalna wartość ufności wykrywania pozycji, która jest uznawana za prawidłową. | Float [0.0,1.0] |
0.5 |
min_pose_presence_confidence |
Minimalny wynik ufności obecności pozycji w wykrywaniu punktów orientacyjnych postawy. | Float [0.0,1.0] |
0.5 |
min_tracking_confidence |
Minimalny wynik ufności śledzenia pozycji ciała, aby uznać go za udany. | Float [0.0,1.0] |
0.5 |
output_segmentation_masks |
Określa, czy narzędzie Pose Landmarker wygeneruje maskę segmentacji dla wykrytej postawy. | Boolean |
False |
result_callback |
Ustawia odbiornik wyników tak, aby asynchronicznie otrzymywał wyniki wyszukiwania punktów orientacyjnych, gdy punkt orientacyjny w ramach funkcji Pose Landmarker jest w trybie transmisji na żywo.
Można go używać tylko wtedy, gdy tryb działania ma wartość LIVE_STREAM. |
ResultListener |
N/A |
Modele
Narzędzie do wykrywania punktów orientacyjnych pozy korzysta z szeregu modeli do przewidywania punktów orientacyjnych pozy. Pierwszy model wykrywa obecność ludzkich ciał w ramce obrazu, a drugi – punkty orientacyjne na ciałach.
Te modele są zapakowane w pakiet do pobrania:
- Model wykrywania pozycji ciała: wykrywa obecność ciał na podstawie kilku kluczowych punktów odniesienia.
- Model punktowania pozy: dodaje pełne mapowanie pozy. Model zwraca oszacowanie 33 3D-wymiarowych punktów orientacyjnych postawy.
Ten pakiet korzysta z konwolucyjnej sieci neuronowej podobnej do MobileNetV2 i jest zoptymalizowany pod kątem aplikacji fitness działających w czasie rzeczywistym na urządzeniu. Ta wersja modelu BlazePose korzysta z GHUM, czyli 3D human shape modeling pipeline, aby oszacować pełną 3D postawę ciała osoby na obrazach lub filmach.
| Pakiet modeli | Kształt wejściowy | Typ danych | Karty modeli | Wersje |
|---|---|---|---|---|
| Wyznaczanie pozycji za pomocą punktów orientacyjnych (lite) | Detektor pozy: 224 × 224 × 3 Oznaczanie pozy: 256 × 256 × 3 |
float 16 | info | Najnowsze |
| Punkt orientacyjny pozy (pełny) | Detektor pozy: 224 × 224 × 3 Oznaczanie pozy: 256 × 256 × 3 |
float 16 | info | Najnowsze |
| Punkt orientacyjny pozy (ciężki) | Detektor pozy: 224 × 224 × 3 Oznaczanie pozy: 256 × 256 × 3 |
float 16 | info | Najnowsze |
Model wyodrębniania punktów orientacyjnych w pozie
Model wyodrębniania punktów orientacyjnych pozy śledzi 33 lokalizacje punktów orientacyjnych ciała, które odpowiadają przybliżonej lokalizacji tych części ciała:
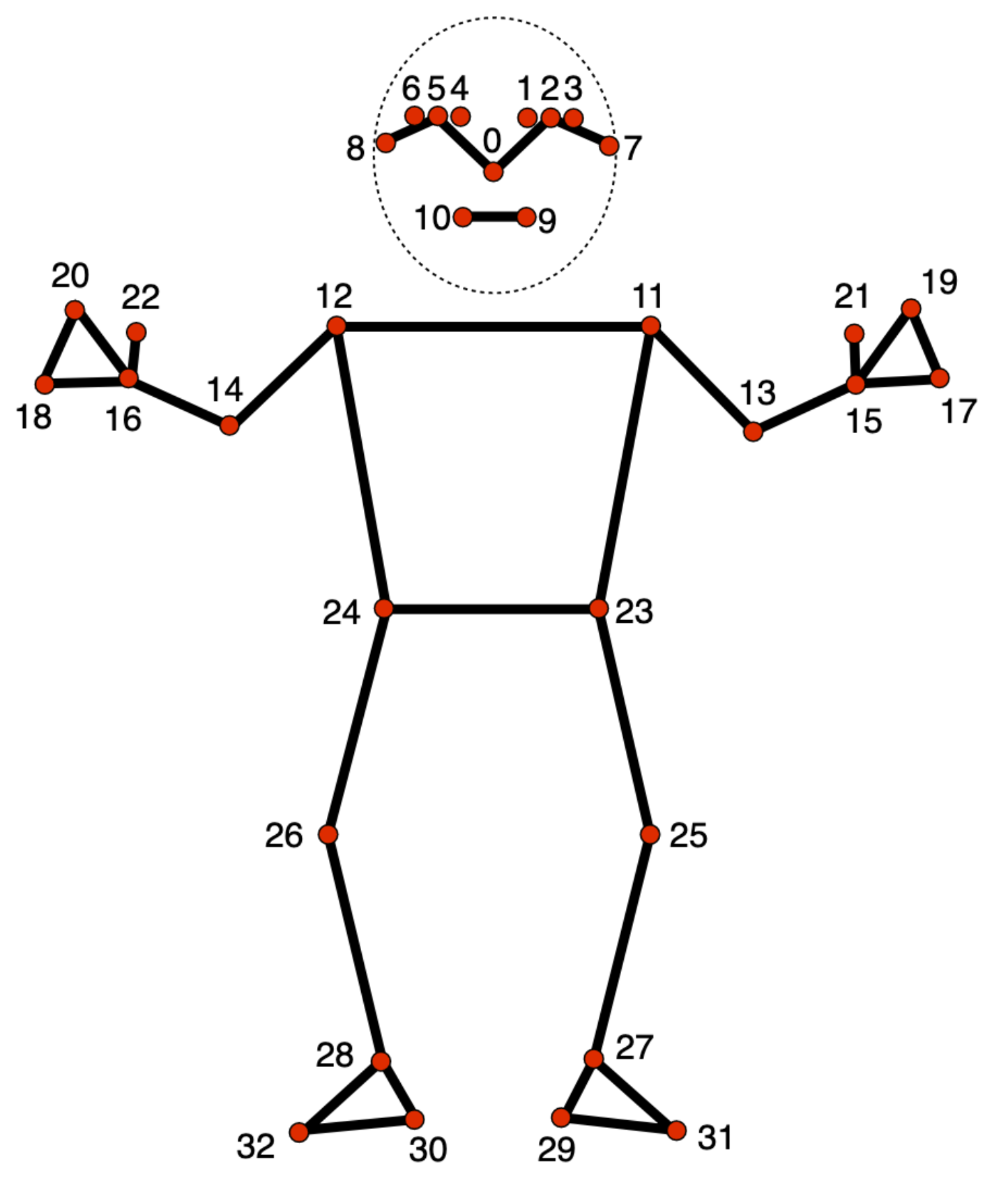
0 - nose
1 - left eye (inner)
2 - left eye
3 - left eye (outer)
4 - right eye (inner)
5 - right eye
6 - right eye (outer)
7 - left ear
8 - right ear
9 - mouth (left)
10 - mouth (right)
11 - left shoulder
12 - right shoulder
13 - left elbow
14 - right elbow
15 - left wrist
16 - right wrist
17 - left pinky
18 - right pinky
19 - left index
20 - right index
21 - left thumb
22 - right thumb
23 - left hip
24 - right hip
25 - left knee
26 - right knee
27 - left ankle
28 - right ankle
29 - left heel
30 - right heel
31 - left foot index
32 - right foot index
Dane wyjściowe modelu zawierają zarówno współrzędne normalizowane (Landmarks), jak i współrzędne globalne (WorldLandmarks) dla każdego punktu orientacyjnego.