API-ja Gemini mundëson Gjenerimin e Shtuar të Rikthimit ("RAG") përmes mjetit të Kërkimit të Skedarëve. Kërkimi i Skedarëve importon, ndan në copa dhe indekson të dhënat tuaja për të mundësuar rikthimin e shpejtë të informacionit përkatës bazuar në një kërkesë të dhënë. Ky informacion i marrë përdoret më pas si kontekst për modelin, duke i lejuar atij të ofrojë përgjigje më të sakta dhe përkatëse. Kërkimi i skedarëve është gjithashtu në gjendje të ofrojë aftësi multimodale me ngulitje teksti të mbështetura nga gemini-embedding-001 dhe ngulitje imazhi/multimodale të mbështetur nga gemini-embedding-2 .
Ruajtja e skedarëve dhe gjenerimi i ngulitjeve në kohën e pyetjeve është falas, dhe ju do të paguani për krijimin e ngulitjeve vetëm kur indeksoni për herë të parë skedarët tuaj dhe kostoja normale e tokenëve të hyrjes/daljes së modelit Gemini. Kjo paradigmë e re faturimi e bën Mjetin e Kërkimit të Skedarëve më të lehtë dhe më kosto-efektiv për t'u ndërtuar dhe për t'u shkallëzuar. Shihni seksionin e çmimeve për detaje.
Ngarkoje direkt në dyqanin e Kërkimit të Skedarëve
Ky shembull tregon se si të ngarkoni drejtpërdrejt një skedar në dyqanin e kërkimit të skedarëve :
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
file_search_store = client.file_search_stores.create(
config={
'display_name': 'your-fileSearchStore-name',
'embedding_model': 'models/gemini-embedding-2'
}
)
operation = client.file_search_stores.upload_to_file_search_store(
file='sample.txt',
file_search_store_name=file_search_store.name,
config={
'display_name' : 'display-file-name',
}
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Can you tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
if content_block.annotations:
print("\nSources:")
for annotation in content_block.annotations:
if annotation.type == "file_citation":
print(f" - {annotation.file_name}: {annotation.source}")
JavaScript
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
async function run() {
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'your-fileSearchStore-name',
embeddingModel: 'models/gemini-embedding-2'
}
});
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
}
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Can you tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
if (contentBlock.annotations) {
console.log("\nSources:");
for (const annotation of contentBlock.annotations) {
if (annotation.type === 'file_citation') {
console.log(` - ${annotation.file_name}: ${annotation.source}`);
}
}
}
}
}
}
}
}
run();
Kontrolloni referencën API për uploadToFileSearchStore për më shumë informacion.
Importimi i skedarëve
Si alternativë, mund të ngarkoni një skedar ekzistues dhe ta importoni atë në dyqanin tuaj të kërkimit të skedarëve :
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
sample_file = client.files.upload(file='sample.txt', config={'display_name': 'display_file_name'})
file_search_store = client.file_search_stores.create(
config={
'display_name': 'your-fileSearchStore-name',
'embedding_model': 'models/gemini-embedding-2'
}
)
operation = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Can you tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
JavaScript
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
async function run() {
const sampleFile = await ai.files.upload({
file: 'sample.txt',
config: { displayName: 'file-name' }
});
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'your-fileSearchStore-name',
embeddingModel: 'models/gemini-embedding-2'
}
});
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation: operation });
}
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Can you tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
}
}
}
}
}
run();
Kontrolloni referencën API për importFile për më shumë informacion.
Konfigurimi i ndarjes në grupe
Kur importoni një skedar në një dyqan të Kërkimit të Skedarëve, ai ndahet automatikisht në pjesë, integrohet, indeksohet dhe ngarkohet në dyqanin tuaj të Kërkimit të Skedarëve. Nëse keni nevojë për më shumë kontroll mbi strategjinë e ndarjes së pjesëve, mund të specifikoni një cilësim chunking_config për të vendosur një numër maksimal të tokenëve për pjesë dhe numrin maksimal të tokenëve që mbivendosen.
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
operation = client.file_search_stores.upload_to_file_search_store(
file_search_store_name=file_search_store.name,
file='sample.txt',
config={
'chunking_config': {
'white_space_config': {
'max_tokens_per_chunk': 200,
'max_overlap_tokens': 20
}
}
}
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
print("Custom chunking complete.")
JavaScript
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
chunkingConfig: {
whiteSpaceConfig: {
maxTokensPerChunk: 200,
maxOverlapTokens: 20
}
}
}
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
console.log("Custom chunking complete.");
Për të përdorur dyqanin tuaj të Kërkimit të Skedarëve, kalojeni atë si mjet te metoda interactions.create , siç tregohet në shembujt e Ngarkimit dhe Importimit .
Si funksionon
Kërkimi i Skedarëve përdor një teknikë të quajtur kërkim semantik për të gjetur informacion që lidhet me kërkesën e përdoruesit. Ndryshe nga kërkimi standard i bazuar në fjalë kyçe, kërkimi semantik kupton kuptimin dhe kontekstin e pyetjes suaj.
Kur importoni një skedar, ai konvertohet në përfaqësime numerike të quajtura ngulitje , të cilat kapin kuptimin semantik të përmbajtjes së ngarkuar. Këto ngulitje ruhen në një bazë të dhënash të specializuar të Kërkimit të Skedarëve. Kur bëni një pyetje, edhe ajo konvertohet në një ngulitje. Pastaj sistemi kryen një Kërkim Skedarësh për të gjetur pjesët më të ngjashme dhe më relevante të dokumentit nga dyqani i Kërkimit të Skedarëve.
Nuk ka Kohë për të Jetuar (TTL) për ngulitje; ato vazhdojnë derisa të fshihen manualisht ose kur modeli të jetë i vjetëruar. Megjithatë, skedarët fshihen pas 48 orësh.
Ja një përshkrim i hollësishëm i procesit për përdorimin e File Search uploadToFileSearchStore API:
Krijo një depo të Kërkimit të Skedarëve : Një depo e Kërkimit të Skedarëve përmban të dhënat e përpunuara nga skedarët tuaj. Është kontejneri i përhershëm për ngulitje mbi të cilin do të veprojë kërkimi semantik.
Ngarko një skedar dhe importo në një depo të Kërkimit të Skedarëve : Ngarko njëkohësisht një skedar dhe importo rezultatet në depon tënd të Kërkimit të Skedarëve. Kjo krijon një objekt të përkohshëm
File, i cili është një referencë për dokumentin tënd të papërpunuar. Këto të dhëna më pas ndahen në copa, konvertohen në ngulitje të Kërkimit të Skedarëve dhe indeksohen. ObjektiFilefshihet pas 48 orësh, ndërsa të dhënat e importuara në depon e Kërkimit të Skedarëve do të ruhen për një kohë të pacaktuar derisa të zgjedhësh t'i fshish.Pyetje me File Search : Së fundmi, përdorni mjetin
FileSearchnë një thirrjegenerateContent. Në konfigurimin e mjetit, ju specifikoni njëFileSearchRetrievalResource, i cili tregon teFileSearchStoreqë dëshironi të kërkoni. Kjo i tregon modelit të kryejë një kërkim semantik në atë dyqan specifik të File Search për të gjetur informacionin përkatës për të bazuar përgjigjen e tij.
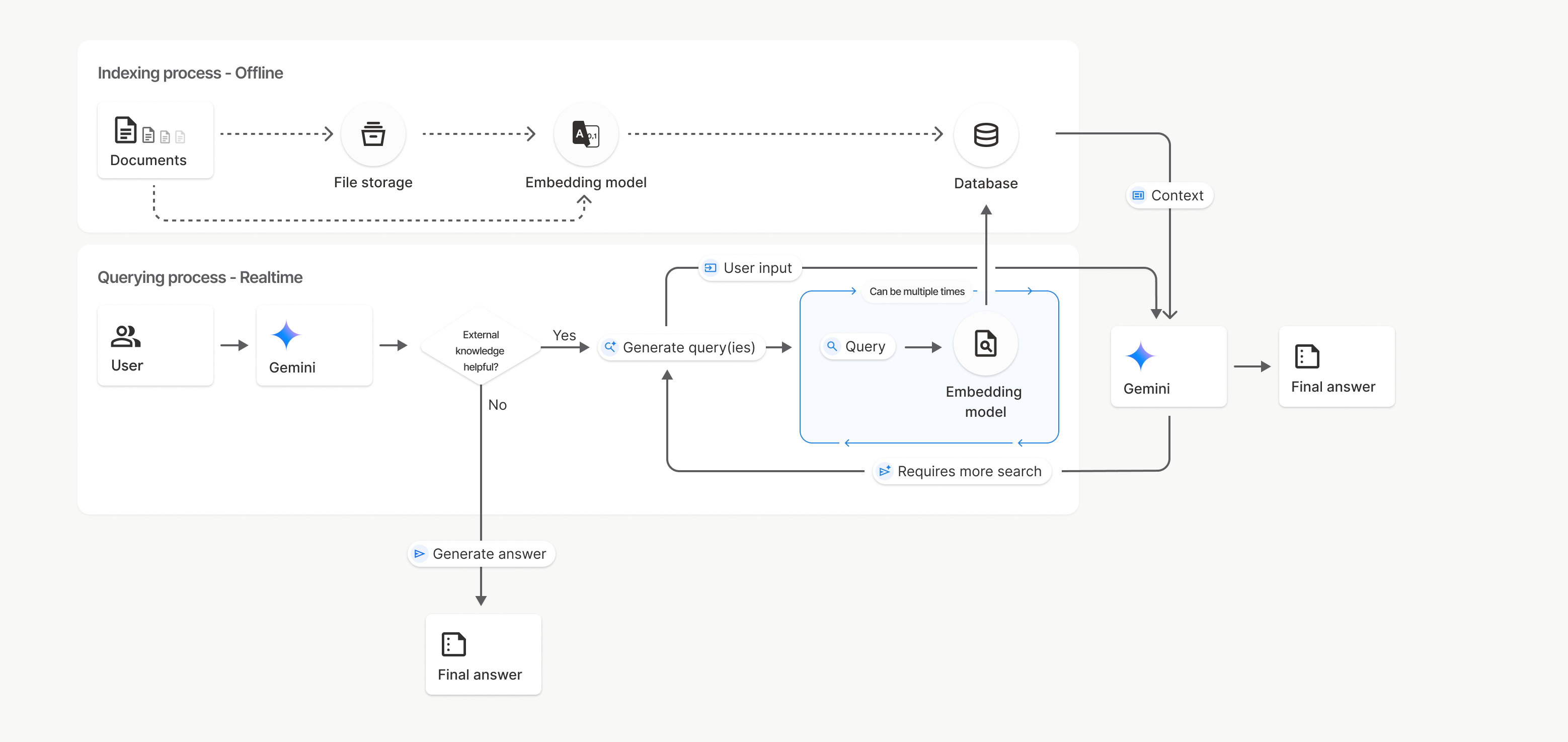
Në këtë diagram, vija me pika nga Dokumentet te modeli i Embedding (duke përdorur gemini-embedding-001 ) përfaqëson API- uploadToFileSearchStore (duke anashkaluar ruajtjen e skedarëve ). Përndryshe, përdorimi i API-së së Skedarëve për të krijuar dhe më pas importuar veçmas skedarë e zhvendos procesin e indeksimit nga Dokumentet te ruajtja e skedarëve dhe më pas te modeli i Embedding .
Dyqanet e Kërkimit të Skedarëve
Një depo File Search është një kontejner për ngulitje dokumentesh. Ndërsa skedarët e papërpunuar të ngarkuar përmes File API fshihen pas 48 orësh, të dhënat e importuara në një depo File Search ruhen për një kohë të pacaktuar derisa t'i fshini manualisht. Mund të krijoni disa depo File Search për të organizuar dokumentet tuaja. FileSearchStore API ju lejon të krijoni, listoni, merrni dhe fshini për të menaxhuar depot e kërkimit të skedarëve. Emrat e depove File Search janë të shtrira globalisht.
Ja disa shembuj se si të menaxhoni dyqanet e Kërkimit të Skedarëve:
Python
file_search_store = client.file_search_stores.create(
config={
'display_name': 'my-file_search-store-123',
'embedding_model': 'models/gemini-embedding-2'
}
)
for file_search_store in client.file_search_stores.list():
print(file_search_store)
my_file_search_store = client.file_search_stores.get(name='fileSearchStores/my-file_search-store-123')
client.file_search_stores.delete(name='fileSearchStores/my-file_search-store-123', config={'force': True})
JavaScript
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'my-file_search-store-123',
embeddingModel: 'models/gemini-embedding-2'
}
});
const fileSearchStores = await ai.fileSearchStores.list();
for await (const store of fileSearchStores) {
console.log(store);
}
const myFileSearchStore = await ai.fileSearchStores.get({
name: 'fileSearchStores/my-file_search-store-123'
});
await ai.fileSearchStores.delete({
name: 'fileSearchStores/my-file_search-store-123',
config: { force: true }
});
PUSHTIM
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}" \
-H "Content-Type: application/json" \
-d '{ "displayName": "My Store", "embedding_model": "models/gemini-embedding-2" }'
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}" \
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123?key=${GEMINI_API_KEY}"
curl -X DELETE "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123?key=${GEMINI_API_KEY}"
Dokumentet e Kërkimit të Skedarëve
Ju mund të menaxhoni dokumente individuale në depot tuaja të skedarëve me API-n e Dokumenteve të Kërkimit të Skedarëve për list çdo dokument në një depo kërkimi skedarësh, get informacion rreth një dokumenti dhe delete një dokument sipas emrit.
Python
for document_in_store in client.file_search_stores.documents.list(parent='fileSearchStores/my-file_search-store-123'):
print(document_in_store)
file_search_document = client.file_search_stores.documents.get(name='fileSearchStores/my-file_search-store-123/documents/my_doc')
print(file_search_document)
client.file_search_stores.documents.delete(name='fileSearchStores/my-file_search-store-123/documents/my_doc', config={'force': True})
JavaScript
const documents = await ai.fileSearchStores.documents.list({
parent: 'fileSearchStores/my-file_search-store-123'
});
for await (const doc of documents) {
console.log(doc);
}
const fileSearchDocument = await ai.fileSearchStores.documents.get({
name: 'fileSearchStores/my-file_search-store-123/documents/my_doc'
});
await ai.fileSearchStores.documents.delete({
name: 'fileSearchStores/my-file_search-store-123/documents/my_doc'
});
PUSHTIM
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents?key=${GEMINI_API_KEY}"
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents/my_doc?key=${GEMINI_API_KEY}"
curl -X DELETE "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents/my_doc?key=${GEMINI_API_KEY}&force=true"
Metadatat e skedarit
Mund të shtoni meta të dhëna të personalizuara në skedarët tuaj për t'i filtruar ato ose për të ofruar kontekst shtesë. Meta të dhënat janë një grup çiftesh çelës-vlerë.
Python
op = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name,
config={
'custom_metadata': [
{"key": "author", "string_value": "Robert Graves"},
{"key": "year", "numeric_value": 1934}
]
}
)
JavaScript
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name,
config: {
customMetadata: [
{ key: "author", stringValue: "Robert Graves" },
{ key: "year", numericValue: 1934 }
]
}
});
Kjo është e dobishme kur keni dokumente të shumta në një dyqan të Kërkimit të Skedarëve dhe dëshironi të kërkoni vetëm në një nëngrup të tyre.
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Tell me about the book 'I, Claudius'",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name],
"metadata_filter": 'author="Robert Graves"',
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Tell me about the book 'I, Claudius'",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name],
metadata_filter: 'author="Robert Graves"',
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
}
}
}
}
PUSHTIM
curl "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"model": "gemini-3.5-flash",
"input": [{"type": "text", "text": "Tell me about the book I, Claudius"}],
"tools": [{
"type": "file_search",
"file_search_store_names": ["'$STORE_NAME'"],
"metadata_filter": "author = \"Robert Graves\""
}]
}' 2> /dev/null > response.json
cat response.json
Udhëzime mbi zbatimin e sintaksës së filtrit të listës për metadata_filter mund të gjenden në google.aip.dev/160
Kërkim Multimodal i Skedarëve
Kërkimi Multimodal i Skedarëve ju lejon të ngulisni dhe kërkoni në mënyrë native përmes imazheve, duke mundësuar aplikacione RAG të pasura dhe multimodale.
Konfiguro modelin e ngulitur
Kur krijoni një FileSearchStore , duhet të anashkaloni modelin e parazgjedhur të ngulitjes vetëm me tekst për të përdorur një model multimodal. Përdorni models/gemini-embedding-2 për të përpunuar si tekstin ashtu edhe imazhet.
Python
store = client.file_search_stores.create(
config={
"display_name": "Multimodal Catalog",
"embedding_model": "models/gemini-embedding-2",
}
)
JavaScript
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: "Multimodal Catalog",
embeddingModel: "models/gemini-embedding-2",
},
});
PUSHTIM
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=$GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"display_name": "Multimodal Catalog",
"embedding_model": "models/gemini-embedding-2"
}'
Ngarko imazhe
Pasi të krijoni dyqanin me një model ngulitjeje multimodale, mund të ngarkoni skedarë imazhesh direkt duke përdorur të njëjtat API të ngarkimit të përshkruara në Ngarkim direkt në dyqanin e Kërkimit të Skedarëve ose Importim skedarësh .
Kërkesat për skedarin e imazhit:
- Skedarët e imazheve duhet të jenë me rezolucion maksimal 4K x 4K piksel.
- Formatet e mbështetura janë PNG, JPEG.
Citime
Kur përdorni Kërkimin e Skedarëve, përgjigjja e modelit mund të përfshijë citime që specifikojnë se cilat pjesë të dokumenteve të ngarkuara janë përdorur për të gjeneruar përgjigjen. Kjo ndihmon me verifikimin dhe verifikimin e fakteve.
Mund të qaseni në informacionin e citimeve përmes atributit të annotations brenda blloqeve content së hapit model_output të përgjigjes.
Python
for step in interaction.steps:
if step.type == 'model_output':
for content in step.content:
if content.type == 'text' and content.annotations:
print(content.annotations)
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text' && contentBlock.annotations) {
console.log(JSON.stringify(contentBlock.annotations, null, 2));
}
}
}
}
Për informacion të detajuar mbi strukturën e citimeve, shihni referencën API për Ndërveprimet .
Numrat e faqeve
Kur përdorni Kërkimin e Skedarëve me dokumente që kanë faqe (si PDF-të), përgjigjja e modelit mund të përfshijë numrin e faqes ku është gjetur informacioni. Mund t'i qaseni këtij informacioni përmes atributit page_number të një shënimi file_citation .
Python
for step in interaction.steps:
if step.type == "model_output":
for content in step.content:
if content.type == "text" and content.annotations:
for annotation in content.annotations:
if annotation.type == "file_citation" and annotation.page_number:
print(f"Cited Page: {annotation.page_number}")
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const block of step.content) {
if (block.type === 'text' && block.annotations) {
for (const annotation of block.annotations) {
if (annotation.type === 'file_citation' && annotation.pageNumber) {
console.log(`Cited Page: ${annotation.pageNumber}`);
}
}
}
}
}
}
Citime mediatike
Kur modeli i referohet një pjese të imazhit gjatë gjenerimit, API kthen një shënim të tipit file_citation në shënime që përfshin një media_id . Mund ta përdorni këtë ID për të shkarkuar pjesën e saktë të imazhit që modeli i referohet. Ky media_id është i vazhdueshëm në shumë thirrje kërkimi, gjë që ju lejon të merrni në mënyrë të besueshme të njëjtin imazh ose ta ruani atë në memorien e përkohshme duke përdorur ID-në.
Fragmenti i mëposhtëm është një shembull i një hapi përgjigjeje REST:
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"type": "file_citation",
"file_name": "product_image",
"media_id": "fileSearchStores/my-store-123/media/BlobId-456"
}
]
}
]
}
Fragmentet e mëposhtme të kodit tregojnë se si të merrni media_id dhe të shkarkoni median:
Python
for step in interaction.steps:
if step.type == "model_output":
for content in step.content:
if content.type == "text" and content.annotations:
for annotation in content.annotations:
if annotation.type == "file_citation" and annotation.media_id:
print(f"Cited Media ID: {annotation.media_id}")
blob_content = client.file_search_stores.download_media(
media_id=annotation.media_id
)
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const block of step.content) {
if (block.type === 'text' && block.annotations) {
for (const annotation of block.annotations) {
if (annotation.type === 'file_citation' && annotation.mediaId) {
console.log(`Cited Media ID: ${annotation.mediaId}`);
const blobContent = await ai.fileSearchStores.downloadMedia(annotation.mediaId);
}
}
}
}
}
}
PUSHTIM
curl -X GET "https://generativelanguage.googleapis.com/v1/fileSearchStores/my-store-123/media/BlobId-456" \
-H "x-goog-api-key: $GEMINI_API_KEY"
Meta të dhëna të personalizuara
Nëse keni shtuar meta të dhëna të personalizuara në skedarët tuaj, mund t'i qaseni ato në shënimet e përgjigjes së modelit. Kjo është e dobishme për kalimin e kontekstit shtesë (si URL-të, numrat e faqeve ose autorët) nga dokumentet tuaja burimore në logjikën e aplikacionit tuaj. Çdo shënim citimi i tipit file_citation përmban këto meta të dhëna të personalizuara.
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.annotations:
for annotation in content_block.annotations:
print(annotation)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.annotations) {
contentBlock.annotations.forEach((annotation) => {
console.log(annotation);
});
}
}
}
}
PUSHTIM
{
"steps": [
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"file_name": "...",
"source": "...",
"custom_metadata": [
{
"key": "author",
"string_value": "Robert Graves"
},
{
"key": "year",
"numeric_value": 1934
}
]
}
]
}
]
}
]
}
Prodhim i strukturuar
Duke filluar me modelet Gemini 3, mund të kombinoni mjetin e kërkimit të skedarëve me rezultatet e strukturuara .
Python
from pydantic import BaseModel, Field
class Money(BaseModel):
amount: str = Field(description="The numerical part of the amount.")
currency: str = Field(description="The currency of amount.")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="What is the minimum hourly wage in Tokyo right now?",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}],
response_format={
"type": "text",
"mime_type": "application/json",
"schema": Money.model_json_schema()
},
)
result = Money.model_validate_json(interaction.output_text)
print(result)
JavaScript
import { z } from "zod";
const moneyJsonSchema = {
type: "object",
properties: {
amount: { type: "string", description: "The numerical part of the amount." },
currency: { type: "string", description: "The currency of amount." }
},
required: ["amount", "currency"]
};
const moneySchema = z.fromJSONSchema(moneyJsonSchema);
async function run() {
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "What is the minimum hourly wage in Tokyo right now?",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name],
}],
response_format: {
type: 'text',
mime_type: 'application/json',
schema: moneyJsonSchema
},
});
const result = moneySchema.parse(JSON.parse(interaction.output_text));
console.log(result);
}
run();
PUSHTIM
curl "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"model": "gemini-3.5-flash",
"input": "What is the minimum hourly wage in Tokyo right now?",
"tools": [{
"type": "file_search",
"file_search_store_names": ["$FILE_SEARCH_STORE_NAME"]
}],
"response_format": {
"type": "text",
"mime_type": "application/json",
"schema": {
"type": "object",
"properties": {
"amount": {"type": "string", "description": "The numerical part of the amount."},
"currency": {"type": "string", "description": "The currency of amount."}
},
"required": ["amount", "currency"]
}
}
}'
Modelet e mbështetura
Modelet e mëposhtme mbështesin Kërkimin e Skedarëve:
| Model | Kërkimi i skedarëve |
|---|---|
| Binjakët 3.5 Flash | ✔️ |
| Pamje paraprake e Gemini 3.1 Pro | ✔️ |
| Gemini 3.1 Flash-Lite | ✔️ |
| Pamje paraprake e shpejtë e Gemini 3 | ✔️ |
| Gemini 2.5 Pro | ✔️ |
| Gemini 2.5 Flash-Lite | ✔️ |
Kombinimet e mjeteve të mbështetura
Modelet Gemini 3 mbështesin kombinimin e mjeteve të integruara (si Kërkimi i Skedarëve) me mjete të personalizuara (thirrja e funksioneve). Mësoni më shumë në faqen e kombinimeve të mjeteve .
Llojet e skedarëve të mbështetur
Kërkimi i skedarëve mbështet një gamë të gjerë formatesh skedarësh, të listuara në seksionet vijuese.
Llojet e skedarëve të aplikacionit
-
application/dart -
application/ecmascript -
application/json -
application/ms-java -
application/msword -
application/pdf -
application/sql -
application/typescript -
application/vnd.curl -
application/vnd.dart -
application/vnd.ibm.secure-container -
application/vnd.jupyter -
application/vnd.ms-excel -
application/vnd.oasis.opendocument.text -
application/vnd.openxmlformats-officedocument.presentationml.presentation -
application/vnd.openxmlformats-officedocument.spreadsheetml.sheet -
application/vnd.openxmlformats-officedocument.wordprocessingml.document -
application/vnd.openxmlformats-officedocument.wordprocessingml.template -
application/x-csh -
application/x-hwp -
application/x-hwp-v5 -
application/x-latex -
application/x-php -
application/x-powershell -
application/x-sh -
application/x-shellscript -
application/x-tex -
application/x-zsh -
application/xml -
application/zip
Llojet e skedarëve të tekstit
-
text/1d-interleaved-parityfec -
text/RED -
text/SGML -
text/cache-manifest -
text/calendar -
text/cql -
text/cql-extension -
text/cql-identifier -
text/css -
text/csv -
text/csv-schema -
text/dns -
text/encaprtp -
text/enriched -
text/example -
text/fhirpath -
text/flexfec -
text/fwdred -
text/gff3 -
text/grammar-ref-list -
text/hl7v2 -
text/html -
text/javascript -
text/jcr-cnd -
text/jsx -
text/markdown -
text/mizar -
text/n3 -
text/parameters -
text/parityfec -
text/php -
text/plain -
text/provenance-notation -
text/prs.fallenstein.rst -
text/prs.lines.tag -
text/prs.prop.logic -
text/raptorfec -
text/rfc822-headers -
text/rtf -
text/rtp-enc-aescm128 -
text/rtploopback -
text/rtx -
text/sgml -
text/shaclc -
text/shex -
text/spdx -
text/strings -
text/t140 -
text/tab-separated-values -
text/texmacs -
text/troff -
text/tsv -
text/tsx -
text/turtle -
text/ulpfec -
text/uri-list -
text/vcard -
text/vnd.DMClientScript -
text/vnd.IPTC.NITF -
text/vnd.IPTC.NewsML -
text/vnd.a -
text/vnd.abc -
text/vnd.ascii-art -
text/vnd.curl -
text/vnd.debian.copyright -
text/vnd.dvb.subtitle -
text/vnd.esmertec.theme-descriptor -
text/vnd.exchangeable -
text/vnd.familysearch.gedcom -
text/vnd.ficlab.flt -
text/vnd.fly -
text/vnd.fmi.flexstor -
text/vnd.gml -
text/vnd.graphviz -
text/vnd.hans -
text/vnd.hgl -
text/vnd.in3d.3dml -
text/vnd.in3d.spot -
text/vnd.latex-z -
text/vnd.motorola.reflex -
text/vnd.ms-mediapackage -
text/vnd.net2phone.commcenter.command -
text/vnd.radisys.msml-basic-layout -
text/vnd.senx.warpscript -
text/vnd.sosi -
text/vnd.sun.j2me.app-descriptor -
text/vnd.trolltech.linguist -
text/vnd.wap.si -
text/vnd.wap.sl -
text/vnd.wap.wml -
text/vnd.wap.wmlscript -
text/vtt -
text/wgsl -
text/x-asm -
text/x-bibtex -
text/x-boo -
text/xc -
text/x-c++hdr -
text/x-c++src -
text/x-cassandra -
text/x-chdr -
text/x-coffeescript -
text/x-component -
text/x-csh -
text/x-csharp -
text/x-csrc -
text/x-cuda -
text/xd -
text/x-diff -
text/x-dsrc -
text/x-emacs-lisp -
text/x-erlang -
text/x-gff3 -
text/x-go -
text/x-haskell -
text/x-java -
text/x-java-properties -
text/x-java-source -
text/x-kotlin -
text/x-lilypond -
text/x-lisp -
text/x-literate-haskell -
text/x-lua -
text/x-moc -
text/x-objcsrc -
text/x-pascal -
text/x-pcs-gcd -
text/x-perl -
text/x-perl-script -
text/x-python -
text/x-python-script -
text/xr-markdown -
text/x-rsrc -
text/x-rst -
text/x-ruby-script -
text/x-rust -
text/x-sass -
text/x-scala -
text/x-scheme -
text/x-script.python -
text/x-scss -
text/x-setext -
text/x-sfv -
text/x-sh -
text/x-siesta -
text/x-sos -
text/x-sql -
text/x-swift -
text/x-tcl -
text/x-tex -
text/x-vbasic -
text/x-vcalendar -
text/xml -
text/xml-dtd -
text/xml-external-parsed-entity -
text/yaml
Kufizime
- API Live: Kërkimi i skedarëve nuk mbështetet në API-n Live .
- Papajtueshmëria e mjeteve: Kërkimi i skedarëve nuk mund të kombinohet me mjete të tjera si Grounding with Google Search , URL Context , etj., për momentin.
Limitet e tarifave
API-ja e Kërkimit të Skedarëve ka kufizimet e mëposhtme për të zbatuar stabilitetin e shërbimit:
- Madhësia maksimale e skedarit / limiti për dokument : 100 MB
- Madhësia totale e ruajtjeve të Kërkimit të Skedarëve të projektit (bazuar në nivelin e përdoruesit):
- Falas : 1 GB
- Niveli 1 : 10 GB
- Niveli 2 : 100 GB
- Niveli 3 : 1 TB
- Rekomandim : Kufizoni madhësinë e secilës hapësirë ruajtjeje të Kërkimit të Skedarëve në nën 20 GB për të siguruar vonesa optimale të rikuperimit.
Çmimet
- Ju faturoheni për integrimet në kohën e indeksimit bazuar në çmimet ekzistuese të integrimeve .
- Magazinimi është falas.
- Integrimet në kohën e pyetjeve janë pa pagesë.
- Tokenët e dokumentit të marrë tarifohen si tokenë të rregullt konteksti .
Çfarë vjen më pas
- Vizitoni referencën API për Depozitat e Kërkimit të Skedarëve dhe Dokumentet e Kërkimit të Skedarëve.