Gemini API cho phép tính năng Tạo sinh tăng cường truy xuất ("RAG") thông qua công cụ Tìm kiếm tệp. Tính năng Tìm kiếm tệp nhập, chia thành khối và lập chỉ mục dữ liệu của bạn để cho phép truy xuất nhanh thông tin liên quan dựa trên một câu lệnh được cung cấp. Sau đó, thông tin được truy xuất này sẽ được dùng làm bối cảnh cho mô hình, cho phép mô hình cung cấp câu trả lời chính xác và phù hợp hơn. Tính năng tìm kiếm tệp cũng có thể cung cấp các chức năng đa phương thức với các vectơ nhúng văn bản được gemini-embedding-001 hỗ trợ và vectơ nhúng hình ảnh/đa phương thức được gemini-embedding-2 hỗ trợ.
Bạn có thể lưu trữ tệp và tạo các mục nhúng miễn phí tại thời điểm truy vấn, đồng thời chỉ phải trả phí khi tạo các mục nhúng trong lần đầu tiên lập chỉ mục tệp và chi phí mã thông báo đầu vào / đầu ra của mô hình Gemini thông thường. Mô hình thanh toán mới này giúp Công cụ tìm kiếm tệp dễ dàng hơn và tiết kiệm chi phí hơn khi xây dựng và mở rộng quy mô. Hãy xem phần định giá để biết thông tin chi tiết.
Tải trực tiếp lên kho lưu trữ Tìm kiếm tệp
Ví dụ này cho biết cách tải trực tiếp một tệp lên kho lưu trữ tìm kiếm tệp:
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
file_search_store = client.file_search_stores.create(
config={
'display_name': 'your-fileSearchStore-name',
'embedding_model': 'models/gemini-embedding-2'
}
)
operation = client.file_search_stores.upload_to_file_search_store(
file='sample.txt',
file_search_store_name=file_search_store.name,
config={
'display_name' : 'display-file-name',
}
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Can you tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
if content_block.annotations:
print("\nSources:")
for annotation in content_block.annotations:
if annotation.type == "file_citation":
print(f" - {annotation.file_name}: {annotation.source}")
JavaScript
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
async function run() {
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'your-fileSearchStore-name',
embeddingModel: 'models/gemini-embedding-2'
}
});
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
}
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Can you tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
if (contentBlock.annotations) {
console.log("\nSources:");
for (const annotation of contentBlock.annotations) {
if (annotation.type === 'file_citation') {
console.log(` - ${annotation.file_name}: ${annotation.source}`);
}
}
}
}
}
}
}
}
run();
Hãy xem Tài liệu tham khảo API uploadToFileSearchStore để biết thêm thông tin.
Nhập tệp
Ngoài ra, bạn có thể tải một tệp hiện có lên và nhập tệp đó vào kho lưu trữ tìm kiếm tệp:
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
sample_file = client.files.upload(file='sample.txt', config={'display_name': 'display_file_name'})
file_search_store = client.file_search_stores.create(
config={
'display_name': 'your-fileSearchStore-name',
'embedding_model': 'models/gemini-embedding-2'
}
)
operation = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Can you tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
JavaScript
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
async function run() {
const sampleFile = await ai.files.upload({
file: 'sample.txt',
config: { displayName: 'file-name' }
});
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'your-fileSearchStore-name',
embeddingModel: 'models/gemini-embedding-2'
}
});
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation: operation });
}
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Can you tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
}
}
}
}
}
run();
Hãy xem Tài liệu tham khảo API importFile để biết thêm thông tin.
Cấu hình phân đoạn
Khi bạn nhập một tệp vào một kho lưu trữ Tìm kiếm tệp, tệp đó sẽ tự động được chia thành các đoạn, được nhúng, lập chỉ mục và tải lên kho lưu trữ Tìm kiếm tệp của bạn. Nếu cần kiểm soát thêm về chiến lược phân đoạn, bạn có thể chỉ định chế độ cài đặt chunking_config để đặt số lượng mã thông báo tối đa cho mỗi đoạn và số lượng mã thông báo trùng lặp tối đa.
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
operation = client.file_search_stores.upload_to_file_search_store(
file_search_store_name=file_search_store.name,
file='sample.txt',
config={
'chunking_config': {
'white_space_config': {
'max_tokens_per_chunk': 200,
'max_overlap_tokens': 20
}
}
}
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
print("Custom chunking complete.")
JavaScript
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
chunkingConfig: {
whiteSpaceConfig: {
maxTokensPerChunk: 200,
maxOverlapTokens: 20
}
}
}
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
console.log("Custom chunking complete.");
Để sử dụng cửa hàng Tìm kiếm tệp, hãy truyền cửa hàng đó dưới dạng một công cụ cho phương thức interactions.create, như trong ví dụ Tải lên và Nhập.
Cách hoạt động
Tính năng Tìm kiếm tệp sử dụng một kỹ thuật gọi là tìm kiếm ngữ nghĩa để tìm thông tin liên quan đến câu lệnh của người dùng. Không giống như tìm kiếm dựa trên từ khoá thông thường, tìm kiếm ngữ nghĩa hiểu được ý nghĩa và bối cảnh của cụm từ tìm kiếm.
Khi bạn nhập một tệp, tệp đó sẽ được chuyển đổi thành các biểu diễn bằng số gọi là embedding (mã nhúng), giúp nắm bắt ý nghĩa ngữ nghĩa của nội dung được tải lên. Các vectơ nhúng này được lưu trữ trong một cơ sở dữ liệu Tìm kiếm tệp chuyên biệt. Khi bạn đưa ra một câu hỏi, câu hỏi đó cũng sẽ được chuyển đổi thành một vectơ nhúng. Sau đó, hệ thống sẽ thực hiện một thao tác Tìm kiếm tệp để tìm các đoạn tài liệu tương tự và phù hợp nhất trong kho lưu trữ Tìm kiếm tệp.
Không có Thời gian tồn tại (TTL) cho các mục nhúng; các mục này sẽ tồn tại cho đến khi bị xoá theo cách thủ công hoặc khi mô hình không còn được dùng nữa. Tuy nhiên, các tệp sẽ bị xoá sau 48 giờ.
Sau đây là thông tin chi tiết về quy trình sử dụng API Tìm kiếm tệp uploadToFileSearchStore:
Tạo một kho lưu trữ Tìm kiếm tệp: Kho lưu trữ Tìm kiếm tệp chứa dữ liệu đã xử lý từ các tệp của bạn. Đây là vùng chứa liên tục cho các mục nhúng mà tính năng tìm kiếm ngữ nghĩa sẽ hoạt động.
Tải tệp lên và nhập vào một kho lưu trữ Tìm kiếm tệp: Tải đồng thời một tệp lên và nhập kết quả vào kho lưu trữ Tìm kiếm tệp. Thao tác này sẽ tạo một đối tượng
Filetạm thời, là một tham chiếu đến tài liệu thô của bạn. Sau đó, dữ liệu đó sẽ được chia thành các khối, chuyển đổi thành các vectơ nhúng của tính năng Tìm kiếm tệp và được lập chỉ mục. Đối tượngFilesẽ bị xoá sau 48 giờ, trong khi dữ liệu được nhập vào kho lưu trữ Tìm kiếm tệp sẽ được lưu trữ vô thời hạn cho đến khi bạn chọn xoá dữ liệu đó.Truy vấn bằng tính năng Tìm kiếm tệp: Cuối cùng, bạn sử dụng công cụ
FileSearchtrong cuộc gọigenerateContent. Trong cấu hình công cụ, bạn chỉ định mộtFileSearchRetrievalResource, trỏ đếnFileSearchStoremà bạn muốn tìm kiếm. Điều này yêu cầu mô hình thực hiện một tìm kiếm ngữ nghĩa trên Kho lưu trữ tìm kiếm tệp cụ thể đó để tìm thông tin liên quan nhằm đưa ra câu trả lời.
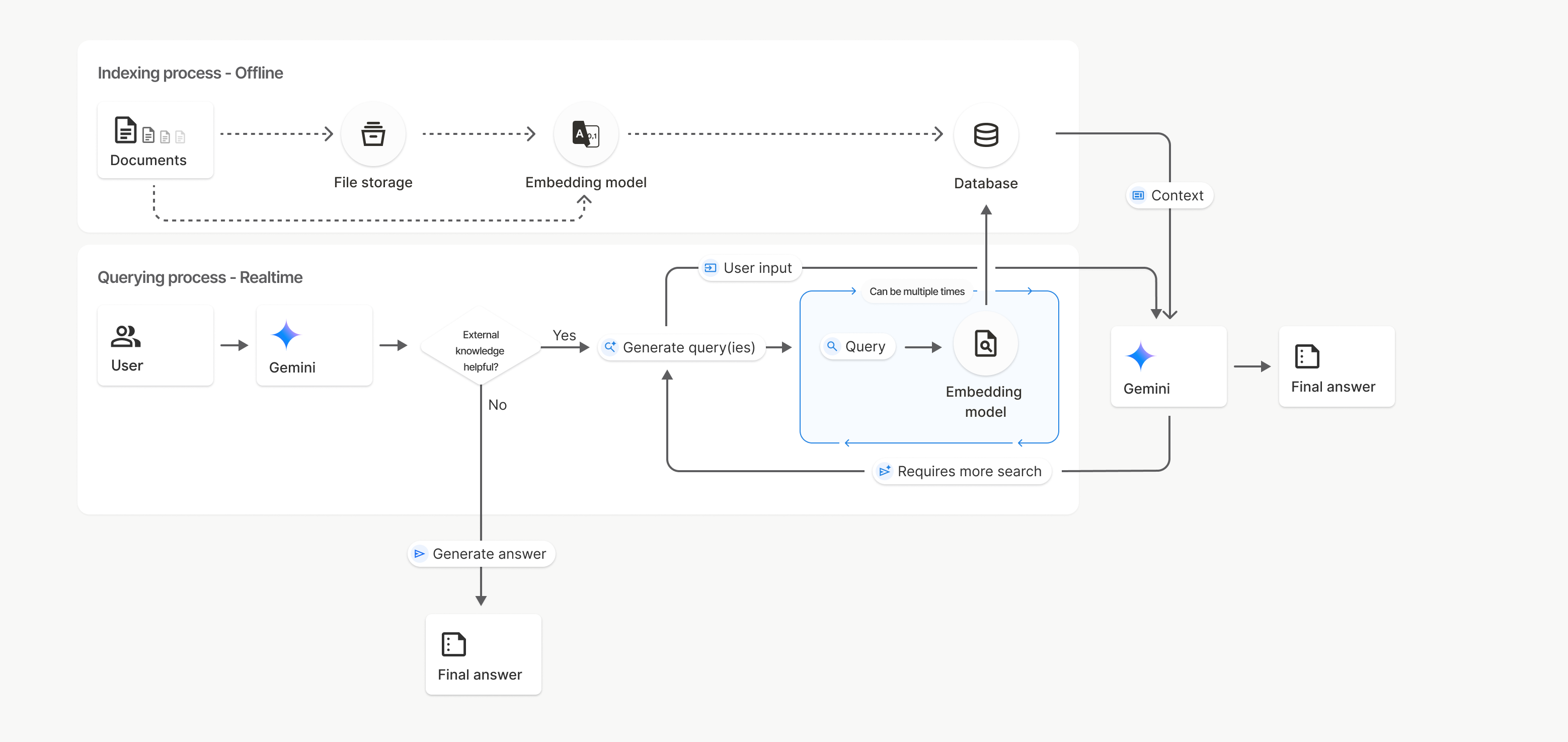
Trong sơ đồ này, đường nét đứt từ Documents (Tài liệu) đến Embedding model (Mô hình nhúng) (sử dụng gemini-embedding-001) biểu thị API uploadToFileSearchStore (bỏ qua File storage (Bộ nhớ tệp)).
Nếu không, việc sử dụng Files API để tạo riêng rồi nhập tệp sẽ di chuyển quy trình lập chỉ mục từ Documents (Tài liệu) sang File storage (Bộ nhớ tệp) rồi đến Embedding model (Mô hình nhúng).
Tìm kiếm trong các tệp
Kho lưu trữ Tìm kiếm tệp là một vùng chứa cho các vectơ nhúng tài liệu của bạn. Mặc dù các tệp thô được tải lên thông qua File API sẽ bị xoá sau 48 giờ, nhưng dữ liệu được nhập vào một kho lưu trữ Tìm kiếm tệp sẽ được lưu trữ vô thời hạn cho đến khi bạn xoá theo cách thủ công. Bạn có thể tạo nhiều kho lưu trữ Tìm kiếm tệp để sắp xếp tài liệu. API FileSearchStore cho phép bạn tạo, liệt kê, nhận và xoá để quản lý các kho lưu trữ tìm kiếm tệp. Tên cửa hàng Tìm kiếm tệp có phạm vi trên toàn cầu.
Sau đây là một số ví dụ về cách quản lý các cửa hàng trong tính năng Tìm kiếm tệp:
Python
file_search_store = client.file_search_stores.create(
config={
'display_name': 'my-file_search-store-123',
'embedding_model': 'models/gemini-embedding-2'
}
)
for file_search_store in client.file_search_stores.list():
print(file_search_store)
my_file_search_store = client.file_search_stores.get(name='fileSearchStores/my-file_search-store-123')
client.file_search_stores.delete(name='fileSearchStores/my-file_search-store-123', config={'force': True})
JavaScript
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'my-file_search-store-123',
embeddingModel: 'models/gemini-embedding-2'
}
});
const fileSearchStores = await ai.fileSearchStores.list();
for await (const store of fileSearchStores) {
console.log(store);
}
const myFileSearchStore = await ai.fileSearchStores.get({
name: 'fileSearchStores/my-file_search-store-123'
});
await ai.fileSearchStores.delete({
name: 'fileSearchStores/my-file_search-store-123',
config: { force: true }
});
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}" \
-H "Content-Type: application/json" \
-d '{ "displayName": "My Store", "embedding_model": "models/gemini-embedding-2" }'
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}" \
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123?key=${GEMINI_API_KEY}"
curl -X DELETE "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123?key=${GEMINI_API_KEY}"
Tài liệu về tính năng Tìm kiếm tệp
Bạn có thể quản lý từng tài liệu trong kho lưu trữ tệp bằng API File Search Documents để list từng tài liệu trong kho lưu trữ tìm kiếm tệp, get thông tin về một tài liệu và delete một tài liệu theo tên.
Python
for document_in_store in client.file_search_stores.documents.list(parent='fileSearchStores/my-file_search-store-123'):
print(document_in_store)
file_search_document = client.file_search_stores.documents.get(name='fileSearchStores/my-file_search-store-123/documents/my_doc')
print(file_search_document)
client.file_search_stores.documents.delete(name='fileSearchStores/my-file_search-store-123/documents/my_doc', config={'force': True})
JavaScript
const documents = await ai.fileSearchStores.documents.list({
parent: 'fileSearchStores/my-file_search-store-123'
});
for await (const doc of documents) {
console.log(doc);
}
const fileSearchDocument = await ai.fileSearchStores.documents.get({
name: 'fileSearchStores/my-file_search-store-123/documents/my_doc'
});
await ai.fileSearchStores.documents.delete({
name: 'fileSearchStores/my-file_search-store-123/documents/my_doc'
});
REST
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents?key=${GEMINI_API_KEY}"
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents/my_doc?key=${GEMINI_API_KEY}"
curl -X DELETE "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents/my_doc?key=${GEMINI_API_KEY}&force=true"
Siêu dữ liệu của tệp
Bạn có thể thêm siêu dữ liệu tuỳ chỉnh vào tệp để lọc hoặc cung cấp thêm bối cảnh. Siêu dữ liệu là một tập hợp các cặp khoá-giá trị.
Python
op = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name,
config={
'custom_metadata': [
{"key": "author", "string_value": "Robert Graves"},
{"key": "year", "numeric_value": 1934}
]
}
)
JavaScript
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name,
config: {
customMetadata: [
{ key: "author", stringValue: "Robert Graves" },
{ key: "year", numericValue: 1934 }
]
}
});
Điều này sẽ hữu ích khi bạn có nhiều tài liệu trong một kho lưu trữ Tìm kiếm tệp và chỉ muốn tìm kiếm một số tài liệu trong số đó.
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Tell me about the book 'I, Claudius'",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name],
"metadata_filter": 'author="Robert Graves"',
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Tell me about the book 'I, Claudius'",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name],
metadata_filter: 'author="Robert Graves"',
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
}
}
}
}
REST
curl "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"model": "gemini-3.5-flash",
"input": [{"type": "text", "text": "Tell me about the book I, Claudius"}],
"tools": [{
"type": "file_search",
"file_search_store_names": ["'$STORE_NAME'"],
"metadata_filter": "author = \"Robert Graves\""
}]
}' 2> /dev/null > response.json
cat response.json
Bạn có thể xem hướng dẫn về cách triển khai cú pháp bộ lọc danh sách cho metadata_filter tại google.aip.dev/160
Tìm kiếm tệp đa phương thức
Tính năng Tìm kiếm tệp đa phương thức cho phép bạn nhúng và tìm kiếm hình ảnh một cách tự nhiên, từ đó tạo ra các ứng dụng RAG đa phương thức phong phú.
Định cấu hình mô hình nhúng
Khi tạo FileSearchStore, bạn phải ghi đè mô hình nhúng chỉ có văn bản mặc định để sử dụng mô hình đa phương thức. Sử dụng models/gemini-embedding-2 để xử lý cả văn bản và hình ảnh.
Python
store = client.file_search_stores.create(
config={
"display_name": "Multimodal Catalog",
"embedding_model": "models/gemini-embedding-2",
}
)
JavaScript
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: "Multimodal Catalog",
embeddingModel: "models/gemini-embedding-2",
},
});
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=$GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"display_name": "Multimodal Catalog",
"embedding_model": "models/gemini-embedding-2"
}'
Tải hình ảnh lên
Sau khi tạo kho lưu trữ bằng mô hình nhúng đa phương thức, bạn có thể tải trực tiếp các tệp hình ảnh lên bằng cách sử dụng cùng một API tải lên được mô tả trong phần Tải trực tiếp lên kho lưu trữ Tìm kiếm tệp hoặc Nhập tệp.
Yêu cầu đối với tệp hình ảnh:
- Tệp hình ảnh phải có độ phân giải tối đa là 4K x 4K pixel.
- Các định dạng được hỗ trợ là PNG, JPEG.
Trích dẫn
Khi bạn sử dụng tính năng Tìm kiếm tệp, câu trả lời của mô hình có thể bao gồm các trích dẫn nêu rõ những phần nào trong tài liệu bạn tải lên được dùng để tạo câu trả lời. Điều này giúp ích cho việc kiểm chứng và xác minh.
Bạn có thể truy cập thông tin trích dẫn thông qua thuộc tính annotations bên trong các khối content của model_output trong bước phản hồi.
Python
for step in interaction.steps:
if step.type == 'model_output':
for content in step.content:
if content.type == 'text' and content.annotations:
print(content.annotations)
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text' && contentBlock.annotations) {
console.log(JSON.stringify(contentBlock.annotations, null, 2));
}
}
}
}
Để biết thông tin chi tiết về cấu trúc của trích dẫn, hãy xem Tài liệu tham khảo API cho Lượt tương tác.
Số trang
Khi bạn sử dụng tính năng Tìm kiếm tệp với những tài liệu có trang (chẳng hạn như tệp PDF), câu trả lời của mô hình có thể bao gồm số trang nơi thông tin được tìm thấy.
Bạn có thể truy cập vào thông tin này thông qua thuộc tính page_number của chú thích file_citation.
Python
for step in interaction.steps:
if step.type == "model_output":
for content in step.content:
if content.type == "text" and content.annotations:
for annotation in content.annotations:
if annotation.type == "file_citation" and annotation.page_number:
print(f"Cited Page: {annotation.page_number}")
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const block of step.content) {
if (block.type === 'text' && block.annotations) {
for (const annotation of block.annotations) {
if (annotation.type === 'file_citation' && annotation.pageNumber) {
console.log(`Cited Page: ${annotation.pageNumber}`);
}
}
}
}
}
}
Trích dẫn nội dung nghe nhìn
Khi mô hình tham chiếu một khối hình ảnh trong quá trình tạo, API sẽ trả về một chú thích thuộc loại file_citation trong các chú thích bao gồm một media_id. Bạn có thể sử dụng mã nhận dạng này để tải chính xác đoạn hình ảnh mà mô hình đã tham chiếu. media_id này vẫn tồn tại trong nhiều lệnh gọi tìm kiếm, cho phép bạn truy xuất cùng một hình ảnh một cách đáng tin cậy hoặc lưu vào bộ nhớ đệm bằng mã nhận dạng.
Đoạn mã sau đây là một ví dụ về bước phản hồi REST:
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"type": "file_citation",
"file_name": "product_image",
"media_id": "fileSearchStores/my-store-123/media/BlobId-456"
}
]
}
]
}
Các đoạn mã sau đây minh hoạ cách truy xuất media_id và tải nội dung nghe nhìn xuống:
Python
for step in interaction.steps:
if step.type == "model_output":
for content in step.content:
if content.type == "text" and content.annotations:
for annotation in content.annotations:
if annotation.type == "file_citation" and annotation.media_id:
print(f"Cited Media ID: {annotation.media_id}")
blob_content = client.file_search_stores.download_media(
media_id=annotation.media_id
)
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const block of step.content) {
if (block.type === 'text' && block.annotations) {
for (const annotation of block.annotations) {
if (annotation.type === 'file_citation' && annotation.mediaId) {
console.log(`Cited Media ID: ${annotation.mediaId}`);
const blobContent = await ai.fileSearchStores.downloadMedia(annotation.mediaId);
}
}
}
}
}
}
REST
curl -X GET "https://generativelanguage.googleapis.com/v1/fileSearchStores/my-store-123/media/BlobId-456" \
-H "x-goog-api-key: $GEMINI_API_KEY"
Siêu dữ liệu tuỳ chỉnh
Nếu đã thêm siêu dữ liệu tuỳ chỉnh vào tệp, bạn có thể truy cập vào siêu dữ liệu đó trong chú thích của câu trả lời của mô hình. Điều này hữu ích cho việc truyền thêm ngữ cảnh (chẳng hạn như URL, số trang hoặc tác giả) từ tài liệu nguồn sang logic ứng dụng của bạn. Mỗi chú thích trích dẫn thuộc loại file_citation đều chứa siêu dữ liệu tuỳ chỉnh này.
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.annotations:
for annotation in content_block.annotations:
print(annotation)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.annotations) {
contentBlock.annotations.forEach((annotation) => {
console.log(annotation);
});
}
}
}
}
REST
{
"steps": [
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"file_name": "...",
"source": "...",
"custom_metadata": [
{
"key": "author",
"string_value": "Robert Graves"
},
{
"key": "year",
"numeric_value": 1934
}
]
}
]
}
]
}
]
}
Đầu ra có cấu trúc
Bắt đầu từ các mô hình Gemini 3, bạn có thể kết hợp công cụ tìm kiếm tệp với đầu ra có cấu trúc.
Python
from pydantic import BaseModel, Field
class Money(BaseModel):
amount: str = Field(description="The numerical part of the amount.")
currency: str = Field(description="The currency of amount.")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="What is the minimum hourly wage in Tokyo right now?",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}],
response_format={
"type": "text",
"mime_type": "application/json",
"schema": Money.model_json_schema()
},
)
result = Money.model_validate_json(interaction.output_text)
print(result)
JavaScript
import { z } from "zod";
const moneyJsonSchema = {
type: "object",
properties: {
amount: { type: "string", description: "The numerical part of the amount." },
currency: { type: "string", description: "The currency of amount." }
},
required: ["amount", "currency"]
};
const moneySchema = z.fromJSONSchema(moneyJsonSchema);
async function run() {
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "What is the minimum hourly wage in Tokyo right now?",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name],
}],
response_format: {
type: 'text',
mime_type: 'application/json',
schema: moneyJsonSchema
},
});
const result = moneySchema.parse(JSON.parse(interaction.output_text));
console.log(result);
}
run();
REST
curl "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"model": "gemini-3.5-flash",
"input": "What is the minimum hourly wage in Tokyo right now?",
"tools": [{
"type": "file_search",
"file_search_store_names": ["$FILE_SEARCH_STORE_NAME"]
}],
"response_format": {
"type": "text",
"mime_type": "application/json",
"schema": {
"type": "object",
"properties": {
"amount": {"type": "string", "description": "The numerical part of the amount."},
"currency": {"type": "string", "description": "The currency of amount."}
},
"required": ["amount", "currency"]
}
}
}'
Mô hình được hỗ trợ
Các mô hình sau đây hỗ trợ tính năng Tìm kiếm tệp:
| Mô hình | Tìm kiếm tệp |
|---|---|
| Gemini 3.5 Flash | ✔️ |
| Bản dùng thử Gemini 3.1 Pro | ✔️ |
| Gemini 3.1 Flash-Lite | ✔️ |
| Bản dùng thử Gemini 3 Flash | ✔️ |
| Gemini 2.5 Pro | ✔️ |
| Gemini 2.5 Flash-Lite | ✔️ |
Các tổ hợp công cụ được hỗ trợ
Các mô hình Gemini 3 hỗ trợ kết hợp các công cụ tích hợp (như Tìm kiếm tệp) với các công cụ tuỳ chỉnh (gọi hàm). Tìm hiểu thêm trên trang các tổ hợp công cụ.
Các loại tệp được hỗ trợ
Tính năng Tìm kiếm tệp hỗ trợ nhiều định dạng tệp, được liệt kê trong các phần sau.
Các loại tệp ứng dụng
application/dartapplication/ecmascriptapplication/jsonapplication/ms-javaapplication/mswordapplication/pdfapplication/sqlapplication/typescriptapplication/vnd.curlapplication/vnd.dartapplication/vnd.ibm.secure-containerapplication/vnd.jupyterapplication/vnd.ms-excelapplication/vnd.oasis.opendocument.textapplication/vnd.openxmlformats-officedocument.presentationml.presentationapplication/vnd.openxmlformats-officedocument.spreadsheetml.sheetapplication/vnd.openxmlformats-officedocument.wordprocessingml.documentapplication/vnd.openxmlformats-officedocument.wordprocessingml.templateapplication/x-cshapplication/x-hwpapplication/x-hwp-v5application/x-latexapplication/x-phpapplication/x-powershellapplication/x-shapplication/x-shellscriptapplication/x-texapplication/x-zshapplication/xmlapplication/zip
Loại tệp văn bản
text/1d-interleaved-parityfectext/REDtext/SGMLtext/cache-manifesttext/calendartext/cqltext/cql-extensiontext/cql-identifiertext/csstext/csvtext/csv-schematext/dnstext/encaprtptext/enrichedtext/exampletext/fhirpathtext/flexfectext/fwdredtext/gff3text/grammar-ref-listtext/hl7v2text/htmltext/javascripttext/jcr-cndtext/jsxtext/markdowntext/mizartext/n3text/parameterstext/parityfectext/phptext/plaintext/provenance-notationtext/prs.fallenstein.rsttext/prs.lines.tagtext/prs.prop.logictext/raptorfectext/rfc822-headerstext/rtftext/rtp-enc-aescm128text/rtploopbacktext/rtxtext/sgmltext/shaclctext/shextext/spdxtext/stringstext/t140text/tab-separated-valuestext/texmacstext/trofftext/tsvtext/tsxtext/turtletext/ulpfectext/uri-listtext/vcardtext/vnd.DMClientScripttext/vnd.IPTC.NITFtext/vnd.IPTC.NewsMLtext/vnd.atext/vnd.abctext/vnd.ascii-arttext/vnd.curltext/vnd.debian.copyrighttext/vnd.dvb.subtitletext/vnd.esmertec.theme-descriptortext/vnd.exchangeabletext/vnd.familysearch.gedcomtext/vnd.ficlab.flttext/vnd.flytext/vnd.fmi.flexstortext/vnd.gmltext/vnd.graphviztext/vnd.hanstext/vnd.hgltext/vnd.in3d.3dmltext/vnd.in3d.spottext/vnd.latex-ztext/vnd.motorola.reflextext/vnd.ms-mediapackagetext/vnd.net2phone.commcenter.commandtext/vnd.radisys.msml-basic-layouttext/vnd.senx.warpscripttext/vnd.sositext/vnd.sun.j2me.app-descriptortext/vnd.trolltech.linguisttext/vnd.wap.sitext/vnd.wap.sltext/vnd.wap.wmltext/vnd.wap.wmlscripttext/vtttext/wgsltext/x-asmtext/x-bibtextext/x-bootext/x-ctext/x-c++hdrtext/x-c++srctext/x-cassandratext/x-chdrtext/x-coffeescripttext/x-componenttext/x-cshtext/x-csharptext/x-csrctext/x-cudatext/x-dtext/x-difftext/x-dsrctext/x-emacs-lisptext/x-erlangtext/x-gff3text/x-gotext/x-haskelltext/x-javatext/x-java-propertiestext/x-java-sourcetext/x-kotlintext/x-lilypondtext/x-lisptext/x-literate-haskelltext/x-luatext/x-moctext/x-objcsrctext/x-pascaltext/x-pcs-gcdtext/x-perltext/x-perl-scripttext/x-pythontext/x-python-scripttext/x-r-markdowntext/x-rsrctext/x-rsttext/x-ruby-scripttext/x-rusttext/x-sasstext/x-scalatext/x-schemetext/x-script.pythontext/x-scsstext/x-setexttext/x-sfvtext/x-shtext/x-siestatext/x-sostext/x-sqltext/x-swifttext/x-tcltext/x-textext/x-vbasictext/x-vcalendartext/xmltext/xml-dtdtext/xml-external-parsed-entitytext/yaml
Các điểm hạn chế
- Live API: File Search không được hỗ trợ trong Live API.
- Không tương thích với các công cụ: Hiện tại, bạn không thể kết hợp tính năng Tìm kiếm tệp với các công cụ khác như Bám sát nguồn bằng Google Tìm kiếm, Bối cảnh URL, v. v.
Giới hạn số lượng yêu cầu
File Search API có các giới hạn sau để đảm bảo tính ổn định của dịch vụ:
- Kích thước tệp tối đa / giới hạn cho mỗi tài liệu: 100 MB
- Tổng kích thước của bộ nhớ Tìm kiếm tệp dự án (dựa trên cấp người dùng):
- Miễn phí: 1 GB
- Cấp 1: 10 GB
- Bậc 2: 100 GB
- Bậc 3: 1 TB
- Đề xuất: Giới hạn kích thước của mỗi kho lưu trữ Tìm kiếm tệp dưới 20 GB để đảm bảo độ trễ truy xuất tối ưu.
Giá
- Bạn sẽ bị tính phí cho các mục nhúng tại thời điểm lập chỉ mục dựa trên mức giá hiện tại cho mục nhúng.
- Dịch vụ lưu trữ không tính phí.
- Bạn không phải trả phí cho các mục nhúng thời gian truy vấn.
- Các mã thông báo tài liệu đã truy xuất sẽ được tính phí dưới dạng mã thông báo ngữ cảnh thông thường.
Bước tiếp theo
- Truy cập vào tài liệu tham khảo API cho File Search Stores và Documents (Tài liệu) của File Search.