O Imagen é o modelo de geração de imagens de alta fidelidade do Google, capaz de gerar imagens realistas e de alta qualidade com base em comandos de texto. Todas as imagens geradas incluem uma marca-d'água do SynthID. Para saber mais sobre as variantes disponíveis do modelo Imagen, consulte a seção Versões do modelo.
Gerar imagens usando os modelos do Imagen
Este exemplo demonstra como gerar imagens com um modelo do Imagen:
Python
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
response = client.models.generate_images(
model='imagen-4.0-generate-001',
prompt='Robot holding a red skateboard',
config=types.GenerateImagesConfig(
number_of_images= 4,
)
)
for generated_image in response.generated_images:
generated_image.image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const response = await ai.models.generateImages({
model: 'imagen-4.0-generate-001',
prompt: 'Robot holding a red skateboard',
config: {
numberOfImages: 4,
},
});
let idx = 1;
for (const generatedImage of response.generatedImages) {
let imgBytes = generatedImage.image.imageBytes;
const buffer = Buffer.from(imgBytes, "base64");
fs.writeFileSync(`imagen-${idx}.png`, buffer);
idx++;
}
}
main();
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateImagesConfig{
NumberOfImages: 4,
}
response, _ := client.Models.GenerateImages(
ctx,
"imagen-4.0-generate-001",
"Robot holding a red skateboard",
config,
)
for n, image := range response.GeneratedImages {
fname := fmt.Sprintf("imagen-%d.png", n)
_ = os.WriteFile(fname, image.Image.ImageBytes, 0644)
}
}
REST
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/imagen-4.0-generate-001:predict" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"instances": [
{
"prompt": "Robot holding a red skateboard"
}
],
"parameters": {
"sampleCount": 4
}
}'

Configuração do Imagen
No momento, a Imagen só aceita comandos em inglês e os seguintes parâmetros:
numberOfImages: o número de imagens a serem geradas, de 1 a 4 (inclusive). O padrão é 4.imageSize: o tamanho da imagem gerada. Isso só é compatível com os modelos Standard e Ultra. Os valores aceitos são1Ke2K. O padrão é1K.aspectRatio: muda a proporção da imagem gerada. Os valores aceitos são"1:1","3:4","4:3","9:16"e"16:9". O padrão é"1:1".personGeneration: permite que o modelo gere imagens de pessoas. Os valores a seguir são aceitos:"dont_allow": bloqueia a geração de imagens de pessoas."allow_adult": gerar imagens de adultos, mas não de crianças. Esse é o padrão."allow_all": gerar imagens que incluam adultos e crianças.
Guia de comandos do Imagen
Esta seção do guia do Imagen mostra como a modificação de um comando de texto para imagem pode produzir resultados diferentes, além de exemplos de imagens que você pode criar.
Noções básicas para escrever comandos
Um bom comando é descritivo e claro, e usa palavras-chave e modificadores significativos. Comece pensando no assunto, no contexto e no estilo.

Assunto: a primeira coisa a considerar com qualquer solicitação é o assunto: o objeto, a pessoa, o animal ou o cenário de que você quer uma imagem.
Contexto e plano de fundo: o mais importante é o plano de fundo ou o contexto em que o assunto será colocado. Tente colocar o objeto de várias formas. Por exemplo, um estúdio com fundo branco, ambientes externos ou ambientes internos.
Estilo: por fim, adicione o estilo da imagem que você quer usar. Os estilos podem ser gerais (pintura, fotografia, esboços) ou muito específicos (pintura pastel, desenho a carvão, isométrico 3D). Também é possível combinar estilos.
Depois de escrever uma primeira versão do comando, refine-o adicionando mais detalhes até chegar à imagem desejada. A iteração é importante. Comece estabelecendo sua ideia principal e depois refine e expanda essa ideia até que a imagem gerada fique parecida com sua visão.

|

|

|
Os modelos do Imagen podem transformar suas ideias em imagens detalhadas, sejam seus comandos curtos ou longos e detalhados. Refine sua visão com comandos iterativos, adicionando detalhes até alcançar o resultado perfeito.
|
Comandos curtos permitem gerar uma imagem rapidamente. 
|
Comandos mais longos permitem adicionar detalhes específicos e criar sua imagem. 
|
Outras dicas para escrever comandos do Imagen:
- Use uma linguagem descritiva: use adjetivos e advérbios detalhados para criar uma imagem clara para o Imagen.
- Contextualize: se necessário, inclua informações básicas para ajudar a IA a entender.
- Referencie artistas ou estilos específicos: se você tiver uma estética específica em mente, referenciar artistas ou movimentos artísticos pode ser útil.
- Use ferramentas de engenharia de comando: considere usar ferramentas ou recursos de engenharia de comando para refinar seus comandos e alcançar os melhores resultados.
- Melhorar os detalhes faciais nas suas imagens pessoais e em grupo: especifique os detalhes faciais como foco da foto (por exemplo, use a palavra "retrato" no comando).
Gerar texto em imagens
Os modelos do Imagen podem adicionar texto às imagens, abrindo mais possibilidades criativas de geração de imagens. Use as orientações a seguir para aproveitar ao máximo esse recurso:
- Itere com confiança: talvez seja necessário regenerar imagens até conseguir o resultado desejado. A integração de texto do Imagen ainda está em evolução, e às vezes várias tentativas geram os melhores resultados.
- Seja breve: limite o texto a 25 caracteres ou menos para uma geração ideal.
Várias frases: teste duas ou três frases distintas para fornecer mais informações. Evite usar mais de três frases para composições mais limpas.

Comando: um pôster com o texto "Summerland" em negrito como um título. Abaixo desse texto, está o slogan "O verão nunca foi tão bom" Posicionamento de guia: embora o Imagen possa tentar posicionar o texto conforme indicado, variações ocasionais são esperadas. Esse recurso está em constante melhoria.
Estilo de fonte inspirador: especifique um estilo de fonte geral para influenciar sutilmente as escolhas da Imagen. Não dependa da replicação precisa da fonte, mas espere interpretações criativas.
Tamanho da fonte: especifique um tamanho de fonte ou uma indicação geral de tamanho (por exemplo, pequeno, médio, grande) para influenciar a geração do tamanho da fonte.
Parametrização de comandos
Para controlar melhor os resultados, pode ser útil parametrizar as entradas no Imagen. Por exemplo, suponha que você queira que seus clientes possam gerar logos para a empresa deles e queira garantir que os logos sejam sempre gerados em um fundo de cor sólida. Você também quer limitar as opções que o cliente pode selecionar em um menu.
Neste exemplo, é possível criar um comando parametrizado semelhante ao seguinte:
A {logo_style} logo for a {company_area} company on a solid color background. Include the text {company_name}.Na sua interface do usuário personalizada, o cliente pode inserir os parâmetros usando um menu, e o valor escolhido preenche o comando que o Imagen recebe.
Exemplo:
Comando:
A minimalist logo for a health care company on a solid color background. Include the text Journey.
Comando:
A modern logo for a software company on a solid color background. Include the text Silo.
Comando:
A traditional logo for a baking company on a solid color background. Include the text Seed.
Técnicas avançadas para a criação de prompts
Use os exemplos a seguir para criar comandos mais específicos com base em atributos como descritores de fotografia, formas e materiais, movimentos de arte históricos e modificadores de qualidade de imagem.
Fotografia
- A solicitação inclui: "Uma foto de..."
Para usar esse estilo, comece usando palavras-chave que informem claramente ao Imagen que você está procurando uma fotografia. Inicie suas solicitações com "Uma foto de . ". Por exemplo:

|

|

|
Fonte da imagem: cada imagem foi gerada usando a solicitação de texto correspondente com o modelo Imagen 4.
Modificadores de fotografia
Nos exemplos abaixo, você pode ver vários modificadores e parâmetros específicos para fotografia. Você pode combinar vários modificadores para ter um controle mais preciso.
Proximidade da câmera - Close-up, tirada de longe

Prompt: uma foto de perto de grãos de café 
Prompt: uma foto afastada de um pequeno saco de grãos de café
em uma cozinha bagunçadaPosição da câmera: aéreo, vista de baixo

Comando: foto aérea de uma cidade urbana com arranha-céus 
Comando: foto de um dossel florestal com céu azul abaixo Iluminação: natural, dramático, calor, frio

Prompt: foto de estúdio de uma cadeira moderna, iluminação natural 
Prompt: foto de estúdio de uma cadeira moderna, iluminação dramática Configurações da câmera — desfoque de movimento, foco suave, bokeh, retrato

Comando: foto de uma cidade com arranha-céus dentro de um carro com desfoque de movimento 
Comando: filtro difusor na fotografia de uma ponte em uma cidade urbana à noite Tipos de lentes - 35 mm, 50 mm, olho de peixe, grande angular, macro

Comando: foto de uma folha, lente macro 
Instrução: fotografia de rua, cidade de Nova York, lente olho de peixe Tipos de filme - preto e branco, polaroid

Comando: um retrato polaroide de um cachorro usando óculos escuros 
Instrução: foto em preto e branco de um cachorro usando óculos escuros
Fonte da imagem: cada imagem foi gerada usando a solicitação de texto correspondente com o modelo Imagen 4.
Ilustração e arte
- A solicitação inclui: "A painting de...", "Um sketch de..."
Os estilos de arte variam de estilos monocromáticos como esboços a lápis à arte digital realista. Por exemplo, as imagens a seguir usam a mesma solicitação com estilos diferentes:
"Um [art style or creation technique] de um sedan elétrico esportivo angular com arranha-céus em segundo plano"

|

|

|

|

|

|
Fonte da imagem: cada imagem foi gerada usando o comando de texto correspondente com o modelo Imagen 2.
Formas e materiais
- A solicitação inclui: "...made of...", "...na forma de..."
Um dos pontos fortes dessa tecnologia é a possibilidade de criar imagens que seriam difíceis ou impossíveis. Por exemplo, é possível recriar o logotipo da empresa em diferentes materiais e texturas.

|

|

|
Fonte da imagem: cada imagem foi gerada usando a solicitação de texto correspondente com o modelo Imagen 4.
Referências de arte históricas
- A solicitação inclui: "...in the style of..."
Alguns estilos se tornaram icônicos ao longo dos anos. Confira algumas ideias de pintura histórica ou estilos de arte que você pode testar.
"gere uma imagem no estilo de [art period or movement] : um parque eólico"

|

|

|
Fonte da imagem: cada imagem foi gerada usando a solicitação de texto correspondente com o modelo Imagen 4.
Modificadores de qualidade da imagem
Algumas palavras-chave podem informar ao modelo que você está procurando um recurso de alta qualidade. Veja alguns exemplos de modificadores de qualidade:
- Modificadores gerais: alta qualidade, bonito, estilizado
- Fotos: fotos 4K, HDR e do Studio
- Arte, Ilustração: por um profissional, detalhado
Veja a seguir alguns exemplos de prompts sem modificadores de qualidade e o mesmo com modificadores de qualidade.

|
 Comando (com modificadores de qualidade): 4K HDR bonito
Comando (com modificadores de qualidade): 4K HDR bonito foto de uma haste de milho tirada por um fotógrafo profissional de |
Fonte da imagem: cada imagem foi gerada usando a solicitação de texto correspondente com o modelo Imagen 4.
Proporções
A geração de imagens do Imagen permite definir cinco proporções de imagem distintas.
- Quadrado (1:1, padrão): uma foto quadrada padrão. Usos comuns para essa proporção incluem postagens de mídias sociais.
Tela cheia (4:3): essa proporção é usada com frequência em mídias ou filmes. Elas também têm as mesmas dimensões da maioria das TVs e câmeras de formato médio antigas. Ela captura mais da cena horizontalmente (em comparação com 1:1), o que a torna uma proporção preferencial para fotografia.

Instrução: close dos dedos de um músico tocando piano, filme em preto e branco, vintage (proporção de 4:3) 
Instrução: uma foto profissional de um estúdio que mostra batatas fritas para um restaurante sofisticado, no estilo de uma revista de culinária (proporção de 4:3) Tela cheia em modo retrato (3:4): é a proporção de tela cheia girada em 90 graus. Isso permite capturar mais da cena verticalmente em comparação com a proporção de 1:1.

Instrução: uma mulher caminhando, perto de suas botas refletidas em uma poça, grandes montanhas ao fundo, no estilo de um anúncio, ângulos dramáticos (proporção 3:4) 
Instrução: imagem aérea de um rio fluindo por um vale místico (proporção 3:4) Widescreen (16:9): essa proporção substituiu a de 4:3 e agora é a proporção mais comum para TVs, monitores e telas de smartphones (paisagem). Use essa proporção quando quiser capturar mais do plano de fundo (por exemplo, paisagens panorâmicas).

Instrução: um homem vestindo roupas brancas sentado na praia, de perto, com iluminação de golden hour (proporção de 16:9) Retrato (9:16): essa proporção é widescreen, mas girada. Essa é uma proporção relativamente nova que ficou conhecida por apps de vídeos mais curtos (por exemplo, YouTube Shorts). Use essa opção para objetos altos com fortes orientações verticais, como edifícios, árvores, cachoeiras ou outros objetos semelhantes.

Instrução: uma renderização digital de um arranha-céu enorme, moderno, grandioso, épico com um lindo pôr do sol ao fundo (proporção de 9:16)
Imagens fotorrealistas
Versões diferentes do modelo de geração de imagens podem oferecer uma combinação de saídas artísticas e fotorrealistas. Use a seguinte palavra nos comandos para gerar uma saída mais fotorrealista com base no assunto que quiser gerar.
| Caso de uso | Tipo de lente | Distâncias focais | Mais detalhes |
|---|---|---|---|
| Pessoas (retratos) | Prime, zoom | 24-35mm | filme em preto e branco, Filme noir, Profundidade de campo, duotone (mencione duas cores) |
| Comida, insetos, plantas (objetos, natureza morta) | Macro | 60-105mm | Alto nível de detalhes, foco preciso, iluminação controlada |
| Esportes, vida selvagem (movimento) | Zoom telefoto | 100-400mm | Velocidade rápida do obturador, rastreamento de ação ou movimento |
| Astronômico, paisagem (amplo angular) | Grande angular | 10-24mm | Longos tempos de exposição, foco nítido, exposição longa, água suave ou nuvens |
Retratos
| Caso de uso | Tipo de lente | Distâncias focais | Mais detalhes |
|---|---|---|---|
| Pessoas (retratos) | Prime, zoom | 24-35mm | filme em preto e branco, Filme noir, Profundidade de campo, duotone (mencione duas cores) |
Usando várias palavras-chave da tabela, o Imagen pode gerar os seguintes retratos:

|

|

|

|
Comando: uma mulher, retrato de 35 mm, duotons azul e cinza
Modelo: imagen-4.0-generate-001

|

|

|

|
Comando: uma mulher, retrato de 35 mm, film noir
Modelo: imagen-4.0-generate-001
Objetos
| Caso de uso | Tipo de lente | Distâncias focais | Mais detalhes |
|---|---|---|---|
| Comida, insetos, plantas (objetos, natureza morta) | Macro | 60-105mm | Alto nível de detalhes, foco preciso, iluminação controlada |
Usando várias palavras-chave da tabela, o Imagen pode gerar as seguintes imagens de objeto:

|

|

|

|
Comando: folha de uma planta de oração, lente macro, 60 mm
Modelo: imagen-4.0-generate-001

|

|

|

|
Comando: um prato de macarrão, lente macro de 100 mm
Modelo: imagen-4.0-generate-001
Movimento
| Caso de uso | Tipo de lente | Distâncias focais | Mais detalhes |
|---|---|---|---|
| Esportes, vida selvagem (movimento) | Zoom telefoto | 100-400mm | Velocidade rápida do obturador, rastreamento de ação ou movimento |
Usando várias palavras-chave da tabela, o Imagen pode gerar as seguintes imagens em movimento:

|

|
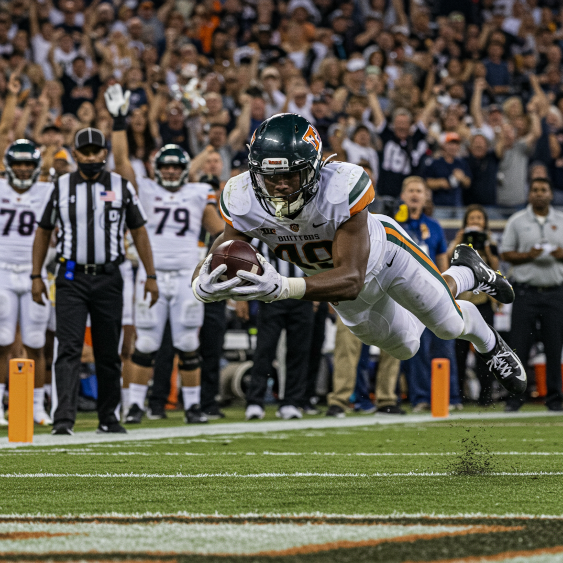
|

|
Comando: um touchdown vencedor, velocidade do obturador rápida e rastreamento de movimento
Modelo: imagen-4.0-generate-001

|

|

|

|
Comando: um cervo correndo na floresta, alta velocidade do obturador, rastreamento de movimento
Modelo: imagen-4.0-generate-001
Grande angular
| Caso de uso | Tipo de lente | Distâncias focais | Mais detalhes |
|---|---|---|---|
| Astronômico, paisagem (amplo angular) | Grande angular | 10-24mm | Longos tempos de exposição, foco nítido, exposição longa, água suave ou nuvens |
Usando várias palavras-chave da tabela, o Imagen pode gerar as seguintes imagens grande angulares:

|

|

|

|
Comando: uma ampla cordilheira, ângulo amplo de paisagem de 10 mm
Modelo: imagen-4.0-generate-001

|

|

|

|
Comando: uma foto da lua, fotografia astronômica, ângulo amplo de 10 mm
Modelo: imagen-4.0-generate-001
Versões do modelo
Imagen 4
| Propriedade | Descrição |
|---|---|
| Código do modelo |
API Gemini
|
| Tipos de dados aceitos |
Entrada Texto Saída Imagens |
| Limites de token[*] |
Limite de tokens de entrada 480 tokens (texto) Imagens de saída 1 a 4 (Ultra/Standard/Fast) |
| Última atualização | Junho de 2025 |
Imagen 3
O modelo Imagen 3 foi desativado.