Gemini Robotics-ER 1.6 est un modèle de vision-langage (VLM) qui apporte les capacités agentiques de Gemini à la robotique. Il est conçu pour un raisonnement avancé dans le monde physique, permettant aux robots d'interpréter des données visuelles complexes, d'effectuer un raisonnement spatial et de planifier des actions à partir de commandes en langage naturel.
Notez que si vous utilisiez Gemini Robotics-ER 1.5, vous pouvez commencer à utiliser le modèle 1.6 en remplaçant le nom du modèle de model="gemini-robotics-er-1.5-preview" par model="gemini-robotics-er-1.6-preview" dans l'appel d'API.
Principales caractéristiques et principaux avantages :
- Autonomie améliorée : les robots peuvent raisonner, s'adapter et réagir aux changements dans des environnements ouverts.
- Interaction en langage naturel : facilite l'utilisation des robots en permettant d'attribuer des tâches complexes en langage naturel.
- Orchestration des tâches : décompose les commandes en langage naturel en sous-tâches et s'intègre aux contrôleurs et comportements de robot existants pour effectuer des tâches à long terme.
- Fonctionnalités polyvalentes : localise et identifie des objets, comprend les relations entre les objets, planifie les saisies et les trajectoires, et interprète les scènes dynamiques.
Ce document décrit ce que fait le modèle et vous présente plusieurs exemples qui mettent en évidence les capacités agentiques du modèle.
Si vous souhaitez vous lancer immédiatement, vous pouvez tester le modèle dans Google AI Studio.
Sécurité
Bien que Gemini Robotics-ER 1.6 ait été conçu en pensant à la sécurité, il vous incombe de maintenir un environnement sûr autour du robot. Les modèles d'IA générative peuvent faire des erreurs et les robots physiques peuvent causer des dommages. La sécurité est une priorité. La sécurisation des modèles d'IA générative lorsqu'ils sont utilisés avec la robotique dans le monde réel est un domaine de recherche actif et essentiel pour nous. Pour en savoir plus, consultez la page Google DeepMind sur la sécurité des robots.
Premiers pas : trouver des objets dans une scène
L'exemple suivant illustre un cas d'utilisation courant de la robotique. Il montre comment transmettre une image et une invite de texte au modèle à l'aide de la méthode generateContent pour obtenir une liste des objets identifiés avec leurs points 2D correspondants.
Le modèle renvoie des points pour les éléments qu'il a identifiés dans une image, en indiquant leurs coordonnées 2D et leurs libellés normalisés.
Vous pouvez utiliser cette sortie avec une API de robotique ou appeler un modèle VLA (vision-language-action) ou toute autre fonction définie par l'utilisateur tiers pour générer des actions qu'un robot doit effectuer.
Python
from google import genai
from google.genai import types
PROMPT = """
Point to no more than 10 items in the image. The label returned
should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format
normalized to 0-1000.
"""
client = genai.Client()
# Load your image
with open("my-image.png", 'rb') as f:
image_bytes = f.read()
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/png',
),
PROMPT
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
REST
# First, ensure you have the image file locally.
# Encode the image to base64
IMAGE_BASE64=$(base64 -w 0 my-image.png)
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-robotics-er-1.6-preview:generateContent \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{
"parts": [
{
"inlineData": {
"mimeType": "image/png",
"data": "'"${IMAGE_BASE64}"'"
}
},
{
"text": "Point to no more than 10 items in the image. The label returned should be an identifying name for the object detected. The answer should follow the json format: [{\"point\": [y, x], \"label\": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000."
}
]
}
],
"generationConfig": {
"temperature": 0.5,
"thinkingConfig": {
"thinkingBudget": 0
}
}
}'
Le résultat sera un tableau JSON contenant des objets, chacun avec un point (coordonnées [y, x] normalisées) et un label identifiant l'objet.
JSON
[
{"point": [376, 508], "label": "small banana"},
{"point": [287, 609], "label": "larger banana"},
{"point": [223, 303], "label": "pink starfruit"},
{"point": [435, 172], "label": "paper bag"},
{"point": [270, 786], "label": "green plastic bowl"},
{"point": [488, 775], "label": "metal measuring cup"},
{"point": [673, 580], "label": "dark blue bowl"},
{"point": [471, 353], "label": "light blue bowl"},
{"point": [492, 497], "label": "bread"},
{"point": [525, 429], "label": "lime"}
]
L'image suivante montre comment ces points peuvent être affichés :

Fonctionnement
Gemini Robotics-ER 1.6 permet à vos robots de contextualiser et de travailler dans le monde physique grâce à la compréhension spatiale. Elle prend en entrée des images, des vidéos ou de l'audio, ainsi que des requêtes en langage naturel pour :
- Comprendre les objets et le contexte de la scène : identifie les objets et raisonne sur leur relation avec la scène, y compris leurs affordances.
- Comprendre les instructions des tâches : interprète les tâches données en langage naturel, comme "trouve la banane".
- Raisonnement spatial et temporel : comprendre les séquences d'actions et la façon dont les objets interagissent avec une scène au fil du temps.
- Fournir une sortie structurée : renvoie les coordonnées (points ou cadres de délimitation) représentant les emplacements des objets.
Cela permet aux robots de "voir" et de "comprendre" leur environnement de manière programmatique.
Gemini Robotics-ER 1.6 est également agentique, ce qui signifie qu'il peut décomposer des tâches complexes (comme "mettre la pomme dans le bol") en sous-tâches pour orchestrer des tâches à long terme :
- Séquence de sous-tâches : décompose les commandes en une séquence logique d'étapes.
- Appels de fonction/Exécution de code : exécute les étapes en appelant vos fonctions/outils robotiques existants ou en exécutant le code généré.
Pour en savoir plus sur le fonctionnement des appels de fonctions avec Gemini, consultez la page Appels de fonctions.
Utiliser le budget de réflexion avec Gemini Robotics-ER 1.6
Gemini Robotics-ER 1.6 dispose d'un budget de réflexion flexible qui vous permet de contrôler le compromis entre latence et précision. Pour les tâches de compréhension spatiale telles que la détection d'objets, le modèle peut atteindre des performances élevées avec un petit budget de réflexion. Les tâches de raisonnement plus complexes, comme le comptage et l'estimation du poids, bénéficient d'un budget de réflexion plus important. Cela vous permet d'équilibrer le besoin de réponses à faible latence avec des résultats de haute précision pour les tâches plus difficiles.
Pour en savoir plus sur les budgets de réflexion, consultez la page sur les capacités de base de Réflexion.
Raisonnement spatial standard
Les exemples suivants illustrent des tâches de perception robotique et de raisonnement spatial à l'aide de requêtes en langage naturel, allant du pointage et de la recherche d'objets dans une image à la planification de trajectoires. Par souci de simplicité, les extraits de code de ces exemples ont été réduits pour n'afficher que l'invite et l'appel à l'API generate_content.
Le code exécutable complet ainsi que d'autres exemples sont disponibles dans le cookbook de robotique.
Pointer vers des objets
Pointer et trouver des objets dans des images ou des images vidéo est un cas d'utilisation courant pour les modèles vision et langage (VLM) en robotique. L'exemple suivant demande au modèle de trouver des objets spécifiques dans une image et de renvoyer leurs coordonnées.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
queries = [
"bread",
"starfruit",
"banana",
]
prompt = f"""
Get all points matching the following objects: {', '.join(queries)}. The
label returned should be an identifying name for the object detected.
The answer should follow the json format:
[{{"point": , "label": }}, ...]. The points are in
[y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Le résultat serait semblable à l'exemple de prise en main, à savoir un fichier JSON contenant les coordonnées des objets trouvés et leurs libellés.
[
{"point": [671, 317], "label": "bread"},
{"point": [738, 307], "label": "bread"},
{"point": [702, 237], "label": "bread"},
{"point": [629, 307], "label": "bread"},
{"point": [833, 800], "label": "bread"},
{"point": [609, 663], "label": "banana"},
{"point": [770, 483], "label": "starfruit"}
]

Utilisez la requête suivante pour demander au modèle d'interpréter des catégories abstraites telles que "fruit" au lieu d'objets spécifiques et de localiser toutes les instances dans l'image.
Python
prompt = f"""
Get all points for fruit. The label returned should be an identifying
name for the object detected.
""" + """The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...]. The points are in
[y, x] format normalized to 0-1000."""
Consultez la page compréhension d'images pour découvrir d'autres techniques de traitement des images.
Suivre des objets dans une vidéo
Gemini Robotics-ER 1.6 peut également analyser les images vidéo pour suivre les objets au fil du temps. Consultez Entrées vidéo pour obtenir la liste des formats vidéo acceptés.
Voici l'invite de base utilisée pour trouver des objets spécifiques dans chaque frame analysé par le modèle :
Python
# Define the objects to find
queries = [
"pen (on desk)",
"pen (in robot hand)",
"laptop (opened)",
"laptop (closed)",
]
base_prompt = f"""
Point to the following objects in the provided image: {', '.join(queries)}.
The answer should follow the json format:
[{{"point": , "label": }}, ...].
The points are in [y, x] format normalized to 0-1000.
If no objects are found, return an empty JSON list [].
"""
Le résultat montre un stylo et un ordinateur portable suivis dans les images vidéo.
![]()
Pour obtenir le code exécutable complet, consultez le cookbook de robotique.
Détection d'objets et cadres de délimitation
Au-delà des points uniques, le modèle peut également renvoyer des cadres de délimitation 2D, qui fournissent une région rectangulaire englobant un objet.
Cet exemple demande des cadres de délimitation 2D pour les objets identifiables sur une table. Le modèle est invité à limiter la sortie à 25 objets et à nommer plusieurs instances de manière unique.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return bounding boxes as a JSON array with labels. Never return masks
or code fencing. Limit to 25 objects. Include as many objects as you
can identify on the table.
If an object is present multiple times, name them according to their
unique characteristic (colors, size, position, unique characteristics, etc..).
The format should be as follows: [{"box_2d": [ymin, xmin, ymax, xmax],
"label": <label for the object>}] normalized to 0-1000. The values in
box_2d must only be integers
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Les boîtes renvoyées par le modèle sont affichées ci-dessous.
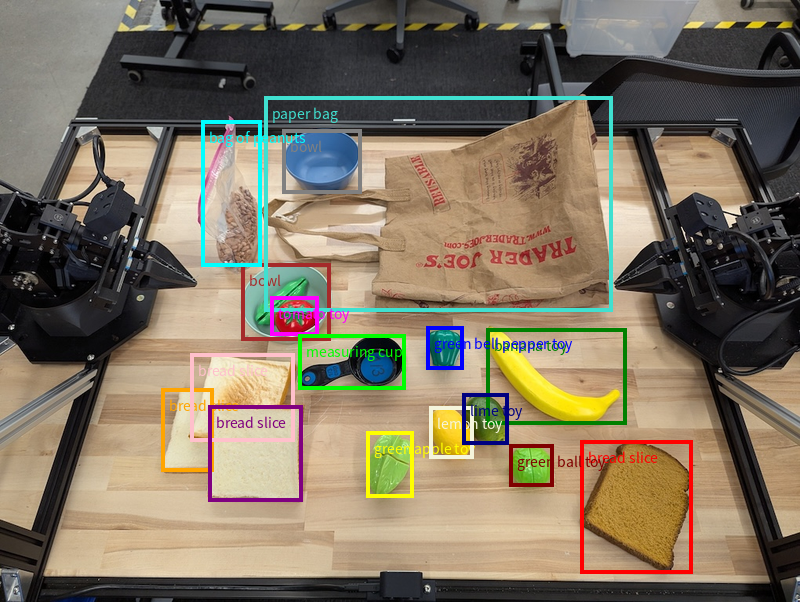
Pour obtenir le code exécutable complet, consultez le cookbook Robotics. La page Compréhension des images contient également d'autres exemples de tâches visuelles, comme la détection d'objets et des exemples de cadres de délimitation.
Trajectoires
Gemini Robotics-ER 1.6 peut générer des séquences de points qui définissent une trajectoire, ce qui est utile pour guider le mouvement d'un robot.
Cet exemple demande une trajectoire pour déplacer un stylo rouge vers un organiseur, y compris le point de départ et une série de points intermédiaires.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
points_data = []
prompt = """
Place a point on the red pen, then 15 points for the trajectory of
moving the red pen to the top of the organizer on the left.
The points should be labeled by order of the trajectory, from '0'
(start point at left hand) to <n> (final point)
The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(image_response.text)
La réponse est un ensemble de coordonnées qui décrivent la trajectoire du chemin que le stylo rouge doit suivre pour le déplacer sur l'organisateur :
[
{"point": [550, 610], "label": "0"},
{"point": [500, 600], "label": "1"},
{"point": [450, 590], "label": "2"},
{"point": [400, 580], "label": "3"},
{"point": [350, 550], "label": "4"},
{"point": [300, 520], "label": "5"},
{"point": [250, 490], "label": "6"},
{"point": [200, 460], "label": "7"},
{"point": [180, 430], "label": "8"},
{"point": [160, 400], "label": "9"},
{"point": [140, 370], "label": "10"},
{"point": [120, 340], "label": "11"},
{"point": [110, 320], "label": "12"},
{"point": [105, 310], "label": "13"},
{"point": [100, 305], "label": "14"},
{"point": [100, 300], "label": "15"}
]

Capacités agentiques
Les exemples suivants illustrent le raisonnement robotique avancé à l'aide des capacités agentiques du modèle, en particulier l'exécution de code. Dans ces scénarios, le modèle peut décider d'écrire et d'exécuter du code Python pour manipuler des images (par exemple, faire un zoom avant, recadrer ou faire pivoter) afin de résoudre les ambiguïtés ou d'améliorer la précision avant de répondre.
Détection d'objets (zoom et recadrage)
L'exemple suivant montre comment utiliser l'exécution de code pour zoomer et recadrer une image afin d'obtenir une vue plus claire lors de la détection d'objets et du renvoi de cadres de sélection.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return JSON in the format {label: val, y: val, x: val, y2: val, x2: val} for
the compostable objects in this scene. Please Zoom and crop the image for a
clearer view. Return an annotated image of the final result with the bounding
boxes drawn on it to the API caller as a part of your process.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Le résultat du modèle ressemblerait à ce qui suit :
[
{"label": "compostable", "y": 256, "x": 482, "y2": 295, "x2": 546},
{"label": "compostable", "y": 317, "x": 478, "y2": 350, "x2": 542},
{"label": "compostable", "y": 586, "x": 556, "y2": 668, "x2": 595},
{"label": "compostable", "y": 463, "x": 669, "y2": 511, "x2": 718},
{"label": "compostable", "y": 178, "x": 565, "y2": 250, "x2": 609}
]
Les boîtes renvoyées par le modèle sont affichées ci-dessous.

Lire un indicateur analogique et appliquer une logique
L'exemple suivant montre comment utiliser le modèle pour lire un indicateur analogique et effectuer des calculs de temps. Il utilise une instruction système pour appliquer une sortie JSON.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('clock.jpg', 'rb') as f:
image_bytes = f.read()
q_time = """
Tell me what the value is. Please respond in the following JSON format:\n {\n "hours": X,\n "minutes": Y,\n}. Zoom in or crop as necessary to confirm location of the clock hands.
"""
system_instruction = "Be precise. When JSON is requested, reply with ONLY that JSON (no preface, no code block)."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
system_instruction + " " + q_time
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(response.text)
Voici un exemple d'entrée d'image.

Le résultat du modèle ressemblerait à ce qui suit :
Time Response: {
"hours": 12,
"minutes": 44
}
Mesurer un liquide dans un récipient
L'exemple suivant montre comment utiliser l'exécution de code pour lire un compteur et calculer le niveau de liquide en pourcentage.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('meter.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
How full is the meter of liquid?
To read it,
1) Find the points for the top of the sight window, bottom of the sight window and the liquid level, formatted as [y, x] with values ranging from 0-1000;
2) Use math to determine the liquid level as a percentage;
3) Output "Answer: ??" on a separate line, where ?? is a number without % or unit.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Voici une image agrandie de l'entrée.

Lire les marquages sur une carte de circuit imprimé
L'exemple suivant montre comment utiliser l'exécution de code pour lire du texte sur une puce de circuit imprimé, ce qui permet au modèle de faire un zoom avant, de recadrer et de faire pivoter l'image si nécessaire.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('circuit_board.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = "What is the number on the ESMT chip? Zoom, crop, and rotate if needed."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Voici une image agrandie de l'entrée.

Annotation d'images
L'exemple suivant montre comment utiliser l'exécution de code pour annoter une image (par exemple, en dessinant des flèches pour les instructions d'élimination) et renvoyer l'image modifiée.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Look at this image and return it as an annotated version using arrows of
different colors to represent which items should go in which bins for
disposal. You must return the final image to the API caller.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Voici un exemple d'entrée d'image.

Le résultat du modèle ressemblerait à ce qui suit :
The annotated image shows the suggested disposal locations for the items on the table:
- **Green bin (Compost/Organic)**: Green chili, red chili, grapes, and cherries.
- **Blue bin (Recycling)**: Yellow crushed can and plastic container.
- **Black bin (Trash)**: Chocolate bar wrapper, Welch's packet, and white tissue.
Orchestration
Gemini Robotics-ER 1.6 peut effectuer la planification des tâches et le raisonnement spatial de niveau supérieur, en déduisant des actions ou en identifiant des emplacements optimaux en fonction de la compréhension du contexte pour orchestrer des tâches à long terme.
Faire de la place pour un ordinateur portable
Cet exemple montre comment Gemini Robotics-ER peut raisonner sur un espace. La requête demande au modèle d'identifier l'objet à déplacer pour faire de la place à un autre élément.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Point to the object that I need to remove to make room for my laptop
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
La réponse contient une coordonnée 2D de l'objet qui répond à la question de l'utilisateur, en l'occurrence l'objet qui doit se déplacer pour faire de la place à un ordinateur portable.
[
{"point": [672, 301], "label": "The object that I need to remove to make room for my laptop"}
]

Préparer un déjeuner
Le modèle peut également fournir des instructions pour les tâches en plusieurs étapes et pointer vers les objets pertinents pour chaque étape. Cet exemple montre comment le modèle planifie une série d'étapes pour préparer un sac de déjeuner.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-of-lunch.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Explain how to pack the lunch box and lunch bag. Point to each
object that you refer to. Each point should be in the format:
[{"point": [y, x], "label": }], where the coordinates are
normalized between 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
La réponse à cette requête est un ensemble d'instructions détaillées sur la façon de préparer un sac à lunch à partir de l'image fournie.
Image d'entrée

Résultats du modèle
Based on the image, here is a plan to pack the lunch box and lunch bag:
1. **Pack the fruit into the lunch box.** Place the [apple](apple), [banana](banana), [red grapes](red grapes), and [green grapes](green grapes) into the [blue lunch box](blue lunch box).
2. **Add the spoon to the lunch box.** Put the [blue spoon](blue spoon) inside the lunch box as well.
3. **Close the lunch box.** Secure the lid on the [blue lunch box](blue lunch box).
4. **Place the lunch box inside the lunch bag.** Put the closed [blue lunch box](blue lunch box) into the [brown lunch bag](brown lunch bag).
5. **Pack the remaining items into the lunch bag.** Place the [blue snack bar](blue snack bar) and the [brown snack bar](brown snack bar) into the [brown lunch bag](brown lunch bag).
Here is the list of objects and their locations:
* [{"point": [899, 440], "label": "apple"}]
* [{"point": [814, 363], "label": "banana"}]
* [{"point": [727, 470], "label": "red grapes"}]
* [{"point": [675, 608], "label": "green grapes"}]
* [{"point": [706, 529], "label": "blue lunch box"}]
* [{"point": [864, 517], "label": "blue spoon"}]
* [{"point": [499, 401], "label": "blue snack bar"}]
* [{"point": [614, 705], "label": "brown snack bar"}]
* [{"point": [448, 501], "label": "brown lunch bag"}]
Appeler une API de robot personnalisé
Cet exemple montre l'orchestration de tâches avec une API de robot personnalisée. Il présente une API fictive conçue pour une opération de prise et de dépose. La tâche consiste à prendre un bloc bleu et à le placer dans un bol orange :

Comme pour les autres exemples de cette page, le code exécutable complet est disponible dans le cookbook Robotics.
La première étape consiste à localiser les deux éléments à l'aide de la requête suivante :
Python
prompt = """
Locate and point to the blue block and the orange bowl. The label
returned should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
La réponse du modèle inclut les coordonnées normalisées du bloc et du bol :
[
{"point": [389, 252], "label": "orange bowl"},
{"point": [727, 659], "label": "blue block"}
]
Cet exemple utilise l'API de robot fictive suivante :
Python
def move(x, y, high):
print(f"moving to coordinates: {x}, {y}, {15 if high else 5}")
def setGripperState(opened):
print("Opening gripper" if opened else "Closing gripper")
def returnToOrigin():
print("Returning to origin pose")
L'étape suivante consiste à appeler une séquence de fonctions d'API avec la logique nécessaire pour exécuter l'action. La requête suivante inclut une description de l'API du robot que le modèle doit utiliser pour orchestrer cette tâche.
Python
prompt = f"""
You are a robotic arm with six degrees-of-freedom. You have the
following functions available to you:
def move(x, y, high):
# moves the arm to the given coordinates. The boolean value 'high' set
to True means the robot arm should be lifted above the scene for
avoiding obstacles during motion. 'high' set to False means the robot
arm should have the gripper placed on the surface for interacting with
objects.
def setGripperState(opened):
# Opens the gripper if opened set to true, otherwise closes the gripper
def returnToOrigin():
# Returns the robot to an initial state. Should be called as a cleanup
operation.
The origin point for calculating the moves is at normalized point
y={robot_origin_y}, x={robot_origin_x}. Use this as the new (0,0) for
calculating moves, allowing x and y to be negative.
Perform a pick and place operation where you pick up the blue block at
normalized coordinates ({block_x}, {block_y}) (relative coordinates:
{block_relative_x}, {block_relative_y}) and place it into the orange
bowl at normalized coordinates ({bowl_x}, {bowl_y})
(relative coordinates: {bowl_relative_x}, {bowl_relative_y}).
Provide the sequence of function calls as a JSON list of objects, where
each object has a "function" key (the function name) and an "args" key
(a list of arguments for the function).
Also, include your reasoning before the JSON output.
For example:
Reasoning: To pick up the block, I will first move the arm to a high
position above the block, open the gripper, move down to the block,
close the gripper, lift the arm, move to a high position above the bowl,
move down to the bowl, open the gripper, and then lift the arm back to
a high position.
"""
Vous trouverez ci-dessous un exemple de résultat possible du modèle en fonction de l'invite et de l'API du robot fictif. La sortie inclut le processus de réflexion du modèle et les tâches qu'il a planifiées en conséquence. Il affiche également la sortie des appels de fonction du robot que le modèle a séquencés ensemble.
Reasoning: To perform the pick and place operation, I will first move the
robotic arm to a high position above the blue block to ensure clearance. Then, I
will open the gripper in preparation for grasping. Next, I will lower the arm to
the surface level to position the gripper around the block and close the gripper
to secure it. After picking up the block, I will lift the arm to clear the
surface and move towards the orange bowl, maintaining a high position to avoid
collisions. Once positioned above the bowl, I will lower the arm to place the
block inside. I will then open the gripper to release the block. Finally, I will
lift the arm out of the bowl and call `returnToOrigin` to reset the robot's
state.
[
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
163,
427,
false
]
},
{
"function": "setGripperState",
"args": [
false
]
},
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "move",
"args": [
-247,
90,
false
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "returnToOrigin",
"args": []
}
]
Executing Function Calls:
moving to coordinates: 163, 427, 15
Opening gripper
moving to coordinates: 163, 427, 5
Closing gripper
moving to coordinates: 163, 427, 15
moving to coordinates: -247, 90, 15
moving to coordinates: -247, 90, 5
Opening gripper
moving to coordinates: -247, 90, 15
Returning to origin pose
Bonnes pratiques
Pour optimiser les performances et la précision de vos applications robotiques, il est essentiel de comprendre comment interagir efficacement avec le modèle Gemini. Cette section présente les bonnes pratiques et les stratégies clés pour créer des requêtes, gérer les données visuelles et structurer les tâches afin d'obtenir les résultats les plus fiables.
Utilise un langage clair et simple.
Utilisez un langage naturel : le modèle Gemini est conçu pour comprendre le langage naturel et conversationnel. Structurez vos requêtes de manière sémantiquement claire et en imitant la façon dont une personne donnerait naturellement des instructions.
Utilisez un langage courant : privilégiez un langage courant plutôt qu'un jargon technique ou spécialisé. Si le modèle ne répond pas comme prévu à un terme spécifique, essayez de le reformuler avec un synonyme plus courant.
Optimisez l'entrée visuelle.
Faire un zoom avant pour plus de détails : lorsque vous traitez des objets petits ou difficiles à distinguer dans une prise de vue plus large, utilisez une fonction de cadre de délimitation pour isoler l'objet qui vous intéresse. Vous pouvez ensuite recadrer l'image sur cette sélection et envoyer la nouvelle image ciblée au modèle pour une analyse plus détaillée.
Expérimentez avec la luminosité et les couleurs : la perception du modèle peut être affectée par des conditions d'éclairage difficiles et un contraste des couleurs insuffisant.
Décomposez les problèmes complexes en étapes plus petites. En traitant chaque petite étape individuellement, vous pouvez guider le modèle vers un résultat plus précis et plus efficace.
Améliorer la précision grâce au consensus. Pour les tâches qui nécessitent un haut degré de précision, vous pouvez interroger le modèle plusieurs fois avec la même requête. En faisant la moyenne des résultats renvoyés, vous pouvez obtenir un "consensus" qui est souvent plus précis et plus fiable.
Limites
Tenez compte des limites suivantes lorsque vous développez avec Gemini Robotics-ER 1.6 :
- État de la version Preview : le modèle est actuellement disponible en version Preview. Les API et les fonctionnalités peuvent changer. Elles ne conviennent peut-être pas aux applications critiques pour la production sans tests approfondis.
- Latence : les requêtes complexes, les entrées haute résolution ou les
thinking_budgetvolumineux peuvent entraîner une augmentation des temps de traitement. - Hallucinations : comme tous les grands modèles de langage, Gemini Robotics-ER 1.6 peut parfois "halluciner" ou fournir des informations incorrectes, en particulier pour les requêtes ambiguës ou les entrées hors distribution.
- Dépendance à la qualité de la requête : la qualité de la sortie du modèle dépend fortement de la clarté et de la spécificité de la requête d'entrée. Les requêtes vagues ou mal structurées peuvent entraîner des résultats non optimaux.
- Coût de calcul : l'exécution du modèle, en particulier avec des entrées vidéo ou un
thinking_budgetélevé, consomme des ressources de calcul et engendre des coûts. Pour en savoir plus, consultez la page Réflexion. - Types d'entrées : consultez les rubriques suivantes pour en savoir plus sur les limites de chaque mode.
Avis de confidentialité
Vous reconnaissez que les modèles référencés dans ce document (les "Modèles de robotique") exploitent des données vidéo et audio pour faire fonctionner et déplacer votre matériel conformément à vos instructions. Vous pouvez donc utiliser les modèles de robotique de sorte que les données de personnes identifiables, telles que les données vocales, d'images et de ressemblance ("Données à caractère personnel"), soient collectées par les modèles de robotique. Si vous choisissez d'utiliser les modèles de robotique de manière à collecter des données à caractère personnel, vous acceptez de ne pas autoriser de personnes identifiables à interagir avec les modèles de robotique ou à se trouver dans la zone environnante, sauf si ces personnes ont été suffisamment informées et ont consenti au fait que leurs données à caractère personnel peuvent être fournies à Google et utilisées par celui-ci, comme indiqué dans les Conditions d'utilisation supplémentaires de l'API Gemini disponibles à l'adresse https://ai.google.dev/gemini-api/terms (les "Conditions d'utilisation"), y compris conformément à la section intitulée "Comment Google utilise vos données". Vous veillerez à ce que cet avis autorise la collecte et l'utilisation des données à caractère personnel telles que décrites dans les Conditions d'utilisation, et vous ferez tout votre possible sur le plan commercial pour minimiser la collecte et la distribution de données à caractère personnel en utilisant des techniques telles que le floutage des visages et en faisant fonctionner les modèles robotiques dans des zones ne contenant pas de personnes identifiables dans la mesure du possible.
Tarifs
Pour en savoir plus sur les tarifs et les régions disponibles, consultez la page Tarifs.
Versions de modèle
Robotics-ER 1.6 Preview
| Propriété | Description |
|---|---|
| Code du modèle | gemini-robotics-er-1.6-preview |
| Types de données acceptés pour |
Entrées Texte, images, vidéo, audio Résultat Texte |
| Limites de jetons[*] |
Limite de jetons d'entrée 131 072 Limite de jetons de sortie 65 536 |
| Fonctionnalités | Not supported Compatible Compatible Compatible Compatible Compatible Compatible Not supported Not supported Compatible Compatible Compatible Compatible |
| Options de consommation |
Compatible Compatible Compatible |
| Versions |
|
| Dernière mise à jour | Décembre 2025 |
| Date limite des connaissances | Janvier 2025 |
Étapes suivantes
- Explorez d'autres fonctionnalités et continuez à tester différents prompts et entrées pour découvrir d'autres applications pour Gemini Robotics-ER 1.6. Pour obtenir d'autres exemples, consultez le Colab de démarrage pour la robotique.
- Pour en savoir plus sur la façon dont les modèles Gemini Robotics ont été conçus en tenant compte de la sécurité, consultez la page Google DeepMind sur la sécurité de la robotique.
- Pour en savoir plus sur les dernières mises à jour des modèles Gemini Robotics, consultez la page de destination Gemini Robotics.