L'API Gemini fournit un outil d'exécution de code qui permet au modèle de générer et d'exécuter du code Python. Le modèle peut ensuite apprendre des résultats de l'exécution du code de manière itérative jusqu'à ce qu'il parvienne à une sortie finale. Vous pouvez utiliser l'exécution de code pour créer des applications qui bénéficient d'un raisonnement basé sur du code. Par exemple, vous pouvez utiliser l'exécution de code pour résoudre des équations ou traiter du texte. Vous pouvez également utiliser les bibliothèques incluses dans l'environnement d'exécution de code pour effectuer des tâches plus spécialisées.
Gemini ne peut exécuter du code qu'en Python. Vous pouvez toujours demander à Gemini de générer du code dans un autre langage, mais le modèle ne peut pas utiliser l'outil d'exécution de code pour l'exécuter.
Activer l'exécution de code
Pour activer l'exécution de code, configurez l'outil d'exécution de code sur le modèle. Cela permet au modèle de générer et d'exécuter du code.
Python
from google import genai
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="What is the sum of the first 50 prime numbers? "
"Generate and run code for the calculation, and make sure you get all 50.",
tools=[{"type": "code_execution"}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif step.type == "code_execution_call":
print(step.arguments.code)
elif step.type == "code_execution_result":
print(step.result)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: "What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and make sure you get all 50.",
tools: [{ type: "code_execution" }]
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
}
}
} else if (step.type === "code_execution_call") {
console.log(step.arguments.code);
} else if (step.type === "code_execution_result") {
console.log(step.result);
}
}
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": "What is the sum of the first 50 prime numbers? Generate and run code for the calculation, and make sure you get all 50.",
"tools": [{"type": "code_execution"}]
}'
La sortie peut se présenter comme suit (mise en forme pour une meilleure lisibilité) :
Okay, I need to calculate the sum of the first 50 prime numbers. Here's how I'll
approach this:
1. **Generate Prime Numbers:** I'll use an iterative method to find prime
numbers. I'll start with 2 and check if each subsequent number is divisible
by any number between 2 and its square root. If not, it's a prime.
2. **Store Primes:** I'll store the prime numbers in a list until I have 50 of
them.
3. **Calculate the Sum:** Finally, I'll sum the prime numbers in the list.
Here's the Python code to do this:
def is_prime(n):
"""Efficiently checks if a number is prime."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
primes = []
num = 2
while len(primes) < 50:
if is_prime(num):
primes.append(num)
num += 1
sum_of_primes = sum(primes)
print(f'{primes=}')
print(f'{sum_of_primes=}')
primes=[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67,
71, 73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151,
157, 163, 167, 173, 179, 181, 191, 193, 197, 199, 211, 223, 227, 229]
sum_of_primes=5117
The sum of the first 50 prime numbers is 5117.
Cette sortie combine plusieurs parties de contenu renvoyées par le modèle lors de l'utilisation de l'exécution de code :
text: texte intégré généré par le modèlecode_execution_call: code généré par le modèle et destiné à être exécutécode_execution_result: résultat du code exécutable
Exécution de code avec des images (Gemini 3)
Le modèle Gemini 3 Flash peut désormais écrire et exécuter du code Python pour manipuler et inspecter activement des images.
Cas d'utilisation
- Zoom et inspection : le modèle détecte implicitement lorsque les détails sont trop petits (par exemple, la lecture d'une jauge éloignée) et écrit du code pour recadrer et réexaminer la zone à une résolution plus élevée.
- Mathématiques visuelles : le modèle peut exécuter des calculs en plusieurs étapes à l'aide de code (par exemple, additionner les éléments d'une facture).
- Annotation d'images : le modèle peut annoter des images pour répondre à des questions, par exemple en dessinant des flèches pour montrer des relations.
Activer l'exécution de code avec des images
L'exécution de code avec des images est officiellement prise en charge dans Gemini 3 Flash. Vous pouvez activer ce comportement en activant à la fois l'exécution de code en tant qu'outil et la réflexion.
Python
from google import genai
import requests
import base64
from PIL import Image
import io
image_path = "https://goo.gle/instrument-img"
image_bytes = requests.get(image_path).content
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "image", "data": base64.b64encode(image_bytes).decode('\utf-8'), "mime_type": "image/jpeg"},
{"type": "text", "text": "Zoom into the expression pedals and tell me how many pedals are there?"}
],
tools=[{"type": "code_execution"}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
display(Image.open(io.BytesIO(base64.b64decode(content_block.data))))
elif step.type == "code_execution_call":
print(step.arguments.code)
elif step.type == "code_execution_result":
print(step.result)
JavaScript
import { GoogleGenAI } from "@google/genai";
async function main() {
const client = new GoogleGenAI({});
const imageUrl = "https://goo.gle/instrument-img";
const response = await fetch(imageUrl);
const imageArrayBuffer = await response.arrayBuffer();
const base64ImageData = Buffer.from(imageArrayBuffer).toString('base64');
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{
type: "image",
data: base64ImageData,
mime_type: "image/jpeg"
},
{ type: "text", text: "Zoom into the expression pedals and tell me how many pedals are there?" }
],
tools: [{ type: "code_execution" }]
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log("Text:", contentBlock.text);
}
}
} else if (step.type === "code_execution_call") {
console.log(`\nGenerated Code:\n`, step.arguments.code);
} else if (step.type === "code_execution_result") {
console.log(`\nExecution Output:\n`, step.result);
}
}
}
main();
REST
IMG_URL="https://goo.gle/instrument-img"
MODEL="gemini-3.5-flash"
MIME_TYPE=$(curl -sIL "$IMG_URL" | grep -i '^content-type:' | awk -F ': ' '{print $2}' | sed 's/\r$//' | head -n 1)
if [[ -z "$MIME_TYPE" || ! "$MIME_TYPE" == image/* ]]; then
MIME_TYPE="image/jpeg"
fi
if [[ "$(uname)" == "Darwin" ]]; then
IMAGE_B64=$(curl -sL "$IMG_URL" | base64 -b 0)
elif [[ "$(base64 --version 2>&1)" = *"FreeBSD"* ]]; then
IMAGE_B64=$(curl -sL "$IMG_URL" | base64)
else
IMAGE_B64=$(curl -sL "$IMG_URL" | base64 -w0)
fi
# Use jq to create the JSON payload to avoid "Argument list too long" error with large base64 strings
echo -n "$IMAGE_B64" > image_b64.txt
jq -n \
--rawfile b64 image_b64.txt \
--arg mime "$MIME_TYPE" \
'{
model: "gemini-3.5-flash",
input: [
{type: "image", data: $b64, mime_type: $mime},
{type: "text", text: "Zoom into the expression pedals and tell me how many pedals are there?"}
],
tools: [{type: "code_execution"}]
}' > payload.json
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d @payload.json
Utiliser l'exécution de code dans des interactions multitours
Vous pouvez également utiliser l'exécution de code dans une conversation multitours à l'aide de previous_interaction_id.
Python
from google import genai
client = genai.Client()
interaction1 = client.interactions.create(
model="gemini-3.5-flash",
input="I have a math question for you.",
tools=[{"type": "code_execution"}]
)
print(interaction1.output_text)
interaction2 = client.interactions.create(
model="gemini-3.5-flash",
previous_interaction_id=interaction1.id,
input="What is the sum of the first 50 prime numbers? "
"Generate and run code for the calculation, and make sure you get all 50.",
tools=[{"type": "code_execution"}]
)
for step in interaction2.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif step.type == "code_execution_call":
print(step.arguments.code)
elif step.type == "code_execution_result":
print(step.result)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const interaction1 = await client.interactions.create({
model: "gemini-3.5-flash",
input: "I have a math question for you.",
tools: [{ type: "code_execution" }]
});
console.log(interaction1.output_text);
const interaction2 = await client.interactions.create({
model: "gemini-3.5-flash",
previous_interaction_id: interaction1.id,
input: "What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and make sure you get all 50.",
tools: [{ type: "code_execution" }]
});
for (const step of interaction2.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
}
}
} else if (step.type === "code_execution_call") {
console.log(step.arguments.code);
} else if (step.type === "code_execution_result") {
console.log(step.result);
}
}
REST
# First turn
RESPONSE1=$(curl -s -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": "I have a math question for you.",
"tools": [{"type": "code_execution"}]
}')
INTERACTION_ID=$(echo $RESPONSE1 | jq -r '.id')
# Second turn with previous_interaction_id
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"previous_interaction_id": "'"$INTERACTION_ID"'",
"input": "What is the sum of the first 50 prime numbers? Generate and run code for the calculation, and make sure you get all 50.",
"tools": [{"type": "code_execution"}]
}'
Entrée/Sortie (E/S)
À partir de Gemini 2.0 Flash, l'exécution de code prend en charge l'entrée de fichiers et la sortie de graphiques. Grâce à ces fonctionnalités d'entrée et de sortie , vous pouvez importer des fichiers CSV et texte, poser des questions sur les fichiers et générer des graphiques Matplotlib dans la réponse. Les fichiers de sortie sont renvoyés sous forme d'images intégrées dans la réponse.
Tarifs des E/S
Lorsque vous utilisez les E/S d'exécution de code, vous êtes facturé pour les jetons d'entrée et les jetons de sortie :
Jetons d'entrée :
- Prompt de l'utilisateur
Jetons de sortie :
- Code généré par le modèle
- Sortie d'exécution de code dans l'environnement de code
- Jetons de réflexion
- Résumé généré par le modèle
Détails des E/S
Lorsque vous travaillez avec les E/S d'exécution de code, tenez compte des détails techniques suivants :
- La durée d'exécution maximale de l'environnement de code est de 30 secondes.
- Si l'environnement de code génère une erreur, le modèle peut décider de régénérer la sortie de code. Cela peut se produire jusqu'à cinq fois.
- La taille maximale de l'entrée de fichier est limitée par la fenêtre de jetons du modèle. Si vous importez un fichier qui dépasse la fenêtre de contexte maximale du modèle, l'API renvoie une erreur.
- L'exécution de code fonctionne mieux avec les fichiers texte et CSV.
- Le fichier d'entrée peut être transmis en tant que données intégrées ou importé à l'aide de l' API Files, et le fichier de sortie est toujours renvoyé en tant que données intégrées.
Facturation
L'activation de l'exécution de code à partir de l'API Gemini n'entraîne aucun frais supplémentaire. Vous serez facturé au tarif actuel des jetons d'entrée et de sortie en fonction du modèle Gemini que vous utilisez.
Voici quelques autres informations à connaître concernant la facturation de l'exécution de code :
- Vous ne serez facturé qu'une seule fois pour les jetons d'entrée que vous transmettez au modèle, et vous serez facturé pour les jetons de sortie finaux qui vous sont renvoyés par le modèle.
- Les jetons représentant le code généré sont comptabilisés comme des jetons de sortie. Le code généré peut inclure du texte et une sortie multimodale, comme des images.
- Les résultats de l'exécution de code sont également comptabilisés comme des jetons de sortie.
Le modèle de facturation est illustré dans le schéma suivant :
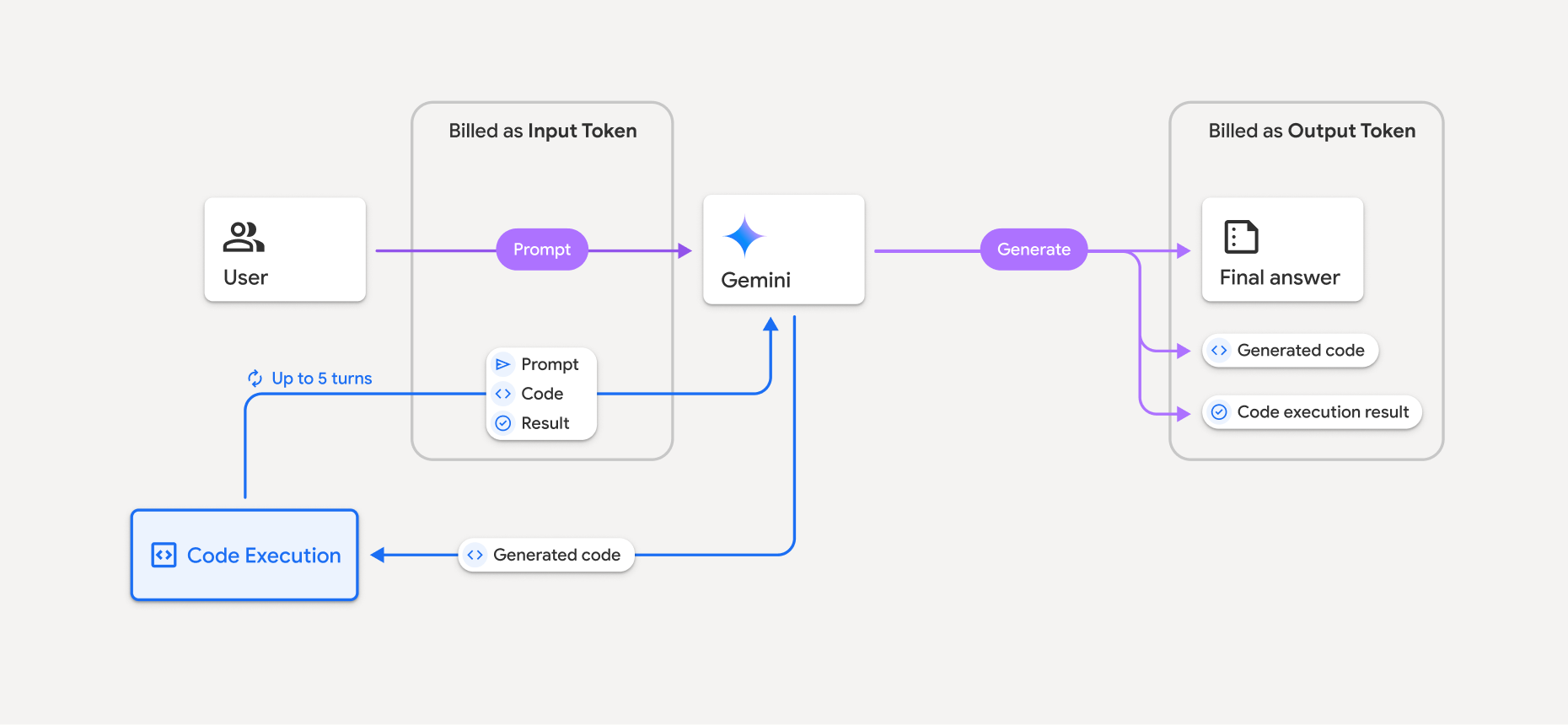
- Vous êtes facturé au tarif actuel des jetons d'entrée et de sortie en fonction du modèle Gemini que vous utilisez.
- Si Gemini utilise l'exécution de code pour générer votre réponse, le prompt d'origine, le code généré et le résultat du code exécuté sont désignés comme des jetons intermédiaires et sont facturés en tant que jetons d'entrée.
- Gemini génère ensuite un résumé et renvoie le code généré, le résultat du code exécuté et le résumé final. Ils sont facturés en tant que jetons de sortie.
- L'API Gemini inclut un nombre de jetons intermédiaires dans la réponse de l'API. Vous savez ainsi pourquoi vous obtenez des jetons d'entrée supplémentaires au-delà de votre prompt initial.
Limites
- Le modèle ne peut que générer et exécuter du code. Il ne peut pas renvoyer d'autres artefacts tels que des fichiers multimédias.
- Dans certains cas, l'activation de l'exécution de code peut entraîner des régressions dans d'autres domaines de la sortie du modèle (par exemple, l'écriture d'une histoire).
- La capacité des différents modèles à utiliser l'exécution de code avec succès varie.
Combinaisons d'outils compatibles
L'outil d'exécution de code peut être combiné à l'ancrage avec la recherche Google pour des cas d'utilisation plus complexes.
Les modèles Gemini 3 permettent de combiner des outils intégrés (comme l'exécution de code) avec des outils personnalisés (appel de fonction).
Bibliothèques prises en charge
L'environnement d'exécution de code inclut les bibliothèques suivantes :
- attrs
- échecs
- contourpy
- fpdf
- geopandas
- imageio
- jinja2
- joblib
- jsonschema
- jsonschema-specifications
- lxml
- matplotlib
- mpmath
- numpy
- opencv-python
- openpyxl
- packaging
- pandas
- pillow
- protobuf
- pylatex
- pyparsing
- PyPDF2
- python-dateutil
- python-docx
- python-pptx
- reportlab
- scikit-learn
- scipy
- seaborn
- six
- striprtf
- sympy
- tabulate
- tensorflow
- toolz
- xlrd
Vous ne pouvez pas installer vos propres bibliothèques.
Étape suivante
- Essayez le
- En savoir plus sur les autres outils de l'API Gemini :