رابط برنامهنویسی نرمافزار Gemini تنظیمات ایمنی را ارائه میدهد که میتوانید در مرحله نمونهسازی اولیه آنها را تنظیم کنید تا مشخص شود که آیا برنامه شما به پیکربندی ایمنی کم و بیش محدودکننده نیاز دارد یا خیر. میتوانید این تنظیمات را در چهار دسته فیلتر تنظیم کنید تا انواع خاصی از محتوا را محدود یا مجاز کنید.
این راهنما نحوه مدیریت تنظیمات ایمنی و فیلترینگ توسط رابط برنامهنویسی Gemini و نحوه تغییر تنظیمات ایمنی برنامه شما را پوشش میدهد.
فیلترهای ایمنی
فیلترهای ایمنی قابل تنظیم Gemini API دستههای زیر را پوشش میدهند:
| دسته بندی | توضیحات |
|---|---|
| آزار و اذیت | نظرات منفی یا مضر که هویت و/یا ویژگیهای محافظتشده را هدف قرار میدهند. |
| سخنان نفرتپراکنانه | محتوایی که بیادبانه، توهینآمیز یا رکیک باشد. |
| صریح جنسی | حاوی اشاراتی به اعمال جنسی یا سایر محتوای مستهجن است. |
| خطرناک | اعمال مضر را ترویج، تسهیل یا تشویق میکند. |
این دستهها در HarmCategory تعریف شدهاند. میتوانید از این فیلترها برای تنظیم موارد مناسب برای مورد استفاده خود استفاده کنید. به عنوان مثال، اگر در حال ساخت دیالوگ بازی ویدیویی هستید، ممکن است مجاز بدانید که به دلیل ماهیت بازی، محتوای بیشتری که به عنوان خطرناک رتبهبندی شده است، مجاز باشد.
علاوه بر فیلترهای ایمنی قابل تنظیم، رابط برنامهنویسی نرمافزار Gemini دارای محافظتهای داخلی در برابر آسیبهای اصلی، مانند محتوایی که ایمنی کودکان را به خطر میاندازد، است. این نوع آسیبها همیشه مسدود میشوند و قابل تنظیم نیستند.
سطح فیلترینگ ایمنی محتوا
رابط برنامهنویسی Gemini سطح احتمال ناامن بودن محتوا را به صورت HIGH ، MEDIUM ، LOW یا NEGLIGIBLE طبقهبندی میکند.
رابط برنامهنویسی نرمافزار Gemini محتوا را بر اساس احتمال ناامن بودن محتوا و نه شدت آن مسدود میکند. توجه به این نکته مهم است زیرا برخی از محتواها میتوانند احتمال ناامن بودن کمی داشته باشند، حتی اگر شدت آسیب آنها همچنان بالا باشد. برای مثال، جملات زیر را با هم مقایسه کنید:
- ربات به من مشت زد.
- ربات به من حمله کرد.
جمله اول ممکن است احتمال ناامن بودن را بیشتر کند، اما شما ممکن است جمله دوم را از نظر خشونت، شدت بالاتری در نظر بگیرید. با توجه به این موضوع، مهم است که با دقت آزمایش کنید و در نظر بگیرید که سطح مناسب مسدود کردن برای پشتیبانی از موارد استفاده کلیدی شما و در عین حال به حداقل رساندن آسیب به کاربران نهایی، چیست.
فیلترینگ ایمن بر اساس درخواست
شما میتوانید تنظیمات ایمنی را برای هر درخواستی که به API میدهید، تنظیم کنید. وقتی درخواستی ارسال میکنید، محتوا تجزیه و تحلیل شده و یک رتبهبندی ایمنی به آن اختصاص داده میشود. رتبهبندی ایمنی شامل دستهبندی و احتمال طبقهبندی آسیب است. برای مثال، اگر محتوا به دلیل احتمال بالای دستهبندی آزار و اذیت مسدود شده باشد، رتبهبندی ایمنی برگردانده شده، دستهبندی برابر با HARASSMENT و احتمال آسیب را روی HIGH تنظیم میکند.
با توجه به ایمنی ذاتی مدل، فیلترهای اضافی به طور پیشفرض خاموش هستند. اگر آنها را فعال کنید، میتوانید سیستم را طوری پیکربندی کنید که محتوا را بر اساس احتمال ناامن بودن آن مسدود کند. رفتار پیشفرض مدل، اکثر موارد استفاده را پوشش میدهد، بنابراین فقط در صورتی که این تنظیمات به طور مداوم برای برنامه شما مورد نیاز است، باید آنها را تنظیم کنید.
جدول زیر تنظیمات مسدودسازی را که میتوانید برای هر دسته تنظیم کنید، شرح میدهد. برای مثال، اگر تنظیمات مسدودسازی را برای دستهی سخنان نفرتپراکن روی «مسدود کردن تعداد کمی» تنظیم کنید، هر چیزی که احتمال بالایی برای محتوای نفرتپراکن داشته باشد مسدود میشود. اما هر چیزی با احتمال پایینتر مجاز است.
| آستانه (استودیوی هوش مصنوعی گوگل) | آستانه (API) | توضیحات |
|---|---|---|
| خاموش | OFF | فیلتر ایمنی را خاموش کنید |
| هیچ کدام را مسدود نکنید | BLOCK_NONE | صرف نظر از احتمال محتوای ناامن، همیشه نمایش داده شود |
| چند مورد را مسدود کنید | BLOCK_ONLY_HIGH | مسدود کردن در صورت احتمال بالای ناامن بودن محتوا |
| برخی را مسدود کنید | BLOCK_MEDIUM_AND_ABOVE | مسدود کردن در صورت احتمال متوسط یا زیاد محتوای ناامن |
| مسدود کردن اکثر | BLOCK_LOW_AND_ABOVE | مسدود کردن در صورت احتمال کم، متوسط یا زیاد محتوای ناامن |
| ناموجود | HARM_BLOCK_THRESHOLD_UNSPECIFIED | آستانه نامشخص است، با استفاده از آستانه پیشفرض مسدود کنید |
اگر آستانه تنظیم نشده باشد، آستانه بلوک پیشفرض برای مدلهای Gemini 2.5 و 3 خاموش است.
شما میتوانید این تنظیمات را برای هر درخواستی که به سرویس مولد ارسال میکنید، تنظیم کنید. برای جزئیات بیشتر به مرجع HarmBlockThreshold API مراجعه کنید.
بازخورد ایمنی
generateContent یک GenerateContentResponse برمیگرداند که شامل بازخورد ایمنی است.
بازخورد سریع در promptFeedback گنجانده شده است. اگر promptFeedback.blockReason تنظیم شده باشد، محتوای prompt مسدود شده است.
بازخورد کاندید پاسخ در Candidate.finishReason و Candidate.safetyRatings گنجانده شده است. اگر محتوای پاسخ مسدود شده باشد و finishReason برابر SAFETY باشد، میتوانید safetyRatings برای جزئیات بیشتر بررسی کنید. محتوایی که مسدود شده است، بازگردانده نمیشود.
تنظیمات ایمنی را تنظیم کنید
این بخش نحوه تنظیم تنظیمات ایمنی را هم در Google AI Studio و هم در کد شما پوشش میدهد.
استودیوی هوش مصنوعی گوگل
میتوانید تنظیمات ایمنی را در Google AI Studio تنظیم کنید.
برای باز کردن پنجرهی تنظیمات اجرای ایمنی ، در قسمت تنظیمات پیشرفته (Advanced settings) در پنل تنظیمات اجرا (Run settings) ، روی تنظیمات ایمنی (Safety settings) کلیک کنید. در این پنجره، میتوانید از اسلایدرها برای تنظیم سطح فیلتر محتوا بر اساس دستهبندی ایمنی استفاده کنید:
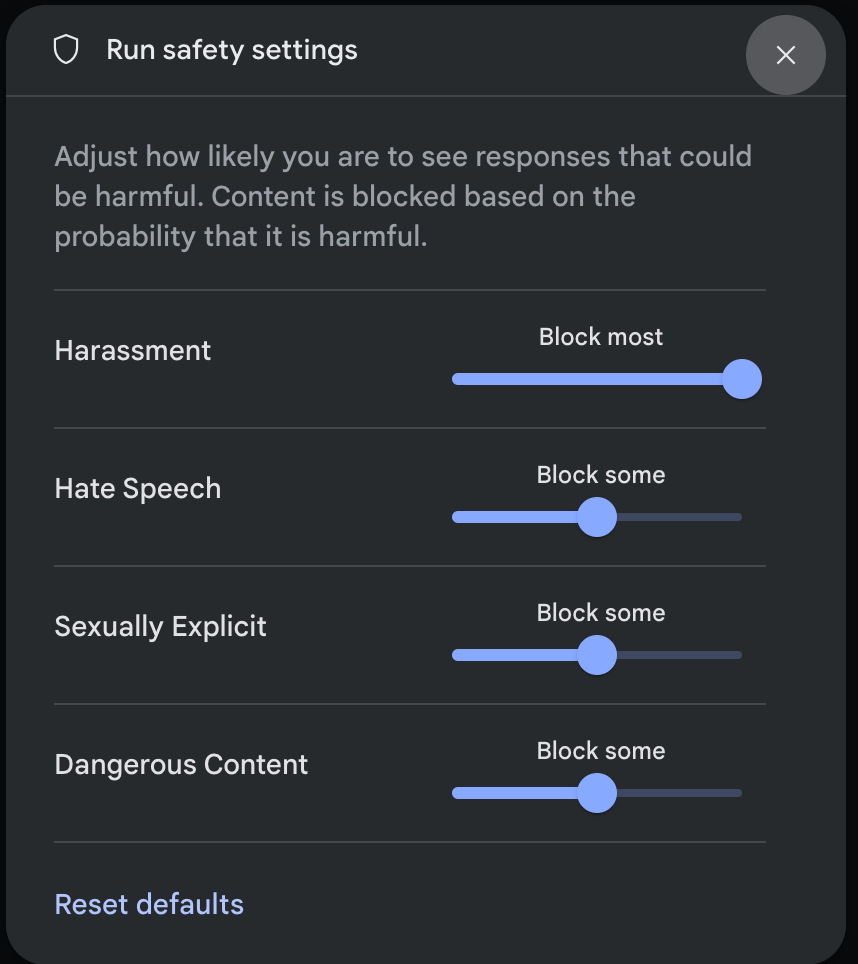
وقتی درخواستی ارسال میکنید (مثلاً با پرسیدن یک سوال از مدل)، اگر محتوای درخواست مسدود شده باشد، یک پیام عنوان «محتوای مسدود شده » ظاهر میشود. برای مشاهده جزئیات بیشتر، اشارهگر را روی متن «محتوای مسدود شده» نگه دارید تا دستهبندی و احتمال طبقهبندی آسیب را مشاهده کنید.
مثالهای کد
قطعه کد زیر نحوه تنظیم تنظیمات ایمنی در فراخوانی GenerateContent شما را نشان میدهد. این، آستانهای را برای دستهبندی نفرتپراکنی ( HARM_CATEGORY_HATE_SPEECH ) تعیین میکند. تنظیم این دستهبندی روی BLOCK_LOW_AND_ABOVE هر محتوایی را که احتمال کم یا زیادی برای نفرتپراکنی داشته باشد، مسدود میکند. برای درک تنظیمات آستانه، به بخش فیلترینگ ایمنی به ازای هر درخواست مراجعه کنید.
پایتون
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
برو
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
جاوا اسکریپت
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
جاوا
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
استراحت
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
مراحل بعدی
- برای کسب اطلاعات بیشتر در مورد API کامل، به مرجع API مراجعه کنید.
- برای آشنایی کلی با ملاحظات ایمنی هنگام توسعه با LLM، راهنمای ایمنی را مرور کنید.
- درباره ارزیابی احتمال در مقابل شدت از تیم Jigsaw بیشتر بیاموزید.
- درباره محصولاتی که به راهکارهای ایمنی مانند Perspective API کمک میکنند، بیشتر بدانید. * میتوانید از این تنظیمات ایمنی برای ایجاد یک طبقهبندیکننده سمیت استفاده کنید. برای شروع، به مثال طبقهبندی مراجعه کنید.