
Page du modèle:CodeGemma
Ressources et documentation technique:
Conditions d'utilisation:Conditions
Auteurs:Google
Informations relatives au modèle
Récapitulatif du modèle
Description
CodeGemma est une famille de modèles de code ouvert légers basés sur Gemma. Les modèles CodeGemma sont des modèles de décodeur uniquement de texte à texte et de texte à code. Ils sont disponibles en tant que variante pré-entraînée de 7 milliards de paramètres spécialisée dans les tâches de complétion et de génération de code, une variante adaptée aux instructions de 7 milliards de paramètres pour le chat de code et le suivi des instructions, et une variante pré-entraînée de 2 milliards de paramètres pour une complétion rapide du code.
Entrées et sorties
Entrée:pour les variantes de modèle préentraînées: préfixe de code et éventuellement suffixe pour les scénarios de complétion et de génération de code, ou texte/requête en langage naturel. Pour la variante de modèle optimisée par les instructions: texte ou requête en langage naturel.
Sortie:pour les variantes de modèle préentraînées: complétion de code fill-in-the-middle, code et langage naturel. Pour la variante de modèle optimisée par instruction : code et langage naturel.
Citation
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
Données du modèle
Ensemble de données d'entraînement
En utilisant Gemma comme modèle de base, les variantes pré-entraînées CodeGemma 2B et 7B sont ensuite entraînées sur 500 à 1 000 milliards de jetons supplémentaires de données en anglais provenant d'ensembles de données mathématiques Open Source et de code généré de manière synthétique.
Traitement des données d'entraînement
Les techniques de prétraitement des données suivantes ont été appliquées pour entraîner CodeGemma:
- FIM : les modèles CodeGemma pré-entraînés se concentrent sur les tâches de remplissage des espaces vides (FIM, fill-in-the-middle). Les modèles sont entraînés pour fonctionner avec les modes PSM et SPM. Nos paramètres FIM sont compris entre 80% et 90 %, avec un taux de FIM de 50/50 PSM/SPM.
- Techniques de mise en paquet basées sur le graphe des dépendances et de mise en paquet lexicale basée sur les tests unitaires : pour améliorer l'alignement du modèle sur les applications réelles, nous avons structuré des exemples d'entraînement au niveau du projet/du dépôt afin de placer les fichiers sources les plus pertinents dans chaque dépôt. Plus précisément, nous avons utilisé deux techniques heuristiques: le conditionnement basé sur un graphique de dépendances et le conditionnement lexical basé sur des tests unitaires.
- Nous avons développé une nouvelle technique pour diviser les documents en préfixe, milieu et suffixe afin que le suffixe commence à un point syntaxiquement plus naturel plutôt qu'à une distribution purement aléatoire.
- Sécurité: comme Gemma, nous avons déployé un filtrage de sécurité rigoureux, y compris le filtrage des données à caractère personnel, le filtrage des contenus relevant de la pornographie enfantine et d'autres filtres basés sur la qualité et la sécurité des contenus, conformément à nos Règles.
Informations d'implémentation
Matériel et frameworks utilisés pendant l'entraînement
Comme Gemma, CodeGemma a été entraîné sur la dernière génération de matériel TPU (Tensor Processing Unit) (TPUv5e), à l'aide de JAX et de ML Pathways.
Informations sur l'évaluation
Résultats du benchmark
Approche d'évaluation
- Benchmarks de complétion de code: HumanEval (HE) (saisie d'une ou de plusieurs lignes)
- Benchmarks de génération de code: HumanEval, MBPP, BabelCode (BC) [C++, C#, Go, Java, JavaScript, Kotlin, Python, Rust]
- Questions/Réponses: BoolQ, PIQA, TriviaQA
- Natural Language: ARC-Challenge, HellaSwag, MMLU, WinoGrande
- Raisonnement mathématique: GSM8K, MATH
Résultats des benchmarks de codage
| Benchmark | 2 Mrds | 2B (1.1) | 7B | 7B-IT | 7B-IT (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37.8 | 44.5 | 56.1 | 60,4 |
| MBPP | 43,6 | 49,2 | 56,2 | 54.2 | 55,6 |
| HumanEval Single Line | 78,4 | 79,3 | 76,1 | 68,3 | 77,4 |
| HumanEval Multi Line | 51.4 | 51 | 58.4 | 20.1 | 23,7 |
| BC HE C++ | 24.2 | 19,9 | 32,9 | 42.2 | 46,6 |
| BC HE C# | 10.6 | 26.1 | 22,4 | 26,7 | 54,7 |
| BC HE Go | 20,5 | 18.0 | 21.7 | 28,6 | 34,2 |
| BC HE Java | 29,2 | 29,8 | 41 | 48,4 | 50,3 |
| JavaScript BC HE | 21.7 | 28.0 | 39,8 | 46 | 48,4 |
| BC HE Kotlin | 28.0 | 32.3 | 39,8 | 51,6 | 47,8 |
| Python BC HE | 21.7 | 36,6 | 42.2 | 48,4 | 54 |
| BC HE Rust | 26,7 | 24.2 | 34.1 | 36 | 37,3 |
| BC MBPP C++ | 47.1 | 38,9 | 53,8 | 56,7 | 63,5 |
| BC MBPP C# | 28,7 | 45.3 | 32,5 | 41,2 | 62,0 |
| BC MBPP Go | 45,6 | 38,9 | 43,3 | 46,2 | 53.2 |
| Java BC MBPP | 41.8 | 49,7 | 50,3 | 57.3 | 62,9 |
| JavaScript BC MBPP | 45.3 | 45,0 | 58.2 | 61.4 | 61.4 |
| BC MBPP Kotlin | 46,8 | 49,7 | 54,7 | 59,9 | 62,6 |
| Python BC MBPP | 38,6 | 52,9 | 59.1 | 62,0 | 60.2 |
| Rouille du MBPP BC | 45.3 | 47,4 | 52,9 | 53,5 | 52,3 |
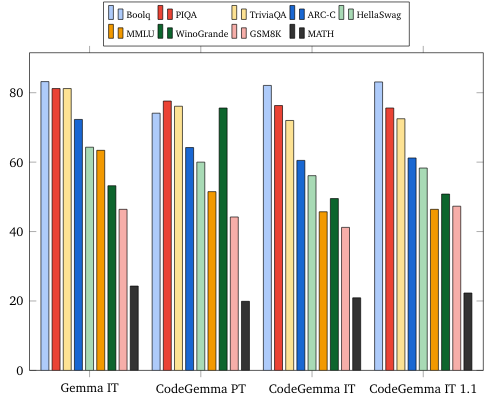
Benchmarks de langage naturel (sur des modèles de 7 milliards)
Éthique et sécurité
Évaluations de l'éthique et de la sécurité
Approche d'évaluation
Nos méthodes d'évaluation incluent des évaluations structurées et des tests internes de red teaming sur les règles de contenu pertinentes. La simulation d'attaque a été menée par plusieurs équipes différentes, chacune ayant des objectifs et des métriques d'évaluation humaines différents. Ces modèles ont été évalués en fonction d'un certain nombre de catégories différentes liées à l'éthique et à la sécurité, y compris les suivantes:
Évaluation humaine des invites concernant la sécurité des contenus et les risques de représentation. Pour en savoir plus sur l'approche d'évaluation, consultez la fiche de modèle Gemma.
Tests spécifiques des capacités de cyberattaque, en se concentrant sur les tests des capacités de piratage autonome et en veillant à ce que les dommages potentiels soient limités.
Résultats d'évaluation
Les résultats des évaluations éthiques et de sécurité sont conformes aux seuils acceptables pour respecter les Règles internes dans les catégories telles que la sécurité des enfants, la sécurité des contenus, les préjudices représentationnels, la mémorisation et les préjudices à grande échelle. Pour en savoir plus, consultez la fiche de modèle Gemma.
Utilisation et limites des modèles
Limites connues
Les grands modèles de langage (LLM) présentent des limites en fonction de leurs données d'entraînement et des limites inhérentes à la technologie. Pour en savoir plus sur les limites des LLM, consultez la fiche de modèle Gemma.
Considérations et risques éthiques
Le développement de grands modèles de langage (LLM) soulève plusieurs questions éthiques. Nous avons pris en compte plusieurs aspects lors du développement de ces modèles.
Pour en savoir plus sur le modèle, consultez la même discussion dans la fiche de modèle Gemma.
Utilisation prévue
Application
Les modèles Code Gemma ont un large éventail d'applications, qui varient selon les modèles IT et PT. La liste suivante des utilisations potentielles n'est pas exhaustive. L'objectif de cette liste est de fournir des informations contextuelles sur les cas d'utilisation possibles que les créateurs de modèles ont pris en compte lors de l'entraînement et du développement du modèle.
- Complétion de code: les modèles PT peuvent être utilisés pour compléter le code à l'aide d'une extension d'IDE
- Génération de code: le modèle IT peut être utilisé pour générer du code avec ou sans extension d'IDE.
- Code Conversation: le modèle IT peut alimenter des interfaces de conversation qui discutent du code
- Enseignement du codage: le modèle IT permet des expériences d'apprentissage du code interactives, aide à corriger la syntaxe ou fournit de la pratique du codage
Avantages
Au moment de la publication, cette famille de modèles fournit des implémentations de grands modèles de langage axées sur le code ouvert hautes performances, conçues dès le départ pour le développement d'une IA responsable par rapport aux modèles de taille similaire.
En utilisant les métriques d'évaluation du benchmark de codage décrites dans ce document, il a été démontré que ces modèles offrent des performances supérieures à celles d'autres modèles ouverts de taille comparable.