

L'attività MediaPipe Pose Landmarker consente di rilevare i punti di riferimento dei corpi umani in un'immagine o un video. Puoi utilizzare questa attività per identificare le posizioni chiave del corpo, analizzare la postura e classificare i movimenti. Questa attività utilizza modelli di machine learning (ML) che lavorano con singole immagini o video. L'attività genera i punti di riferimento della posa del corpo nelle coordinate dell'immagine e nelle coordinate del mondo tridimensionale.
Inizia
Per iniziare a utilizzare questa attività, segui la guida all'implementazione per la piattaforma di destinazione. Queste guide specifiche per la piattaforma illustrano un'implementazione di base di questa attività, incluso un modello consigliato e un esempio di codice con le opzioni di configurazione consigliate:
- Android - Esempio di codice - Guide
- Python - Esempio di codice - Guida
- Web - Esempio di codice - Guida
Dettagli attività
Questa sezione descrive le funzionalità, gli input, gli output e le opzioni di configurazione di questa attività.
Funzionalità
- Elaborazione delle immagini di input: l'elaborazione include la rotazione, il ridimensionamento, la normalizzazione e la conversione dello spazio colore delle immagini.
- Soglia di punteggio: filtra i risultati in base ai punteggi di previsione.
| Input delle attività | Output delle attività |
|---|---|
Il rilevamento di punti di riferimento della posa accetta uno dei seguenti tipi di dati:
|
Il rilevamento di punti di riferimento della posa restituisce i seguenti risultati:
|
Opzioni di configurazione
Questa attività ha le seguenti opzioni di configurazione:
| Nome opzione | Descrizione | Intervallo di valori | Valore predefinito |
|---|---|---|---|
running_mode |
Imposta la modalità di esecuzione dell'attività. Esistono tre
modalità: IMMAGINE: la modalità per l'inserimento di singole immagini. VIDEO: la modalità per i fotogrammi decodificati di un video. LIVE_STREAM: la modalità per un live streaming di dati di input, ad esempio da una videocamera. In questa modalità, resultListener deve essere chiamato per configurare un ascoltatore per ricevere i risultati in modo asincrono. |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
num_poses |
Il numero massimo di pose che possono essere rilevate da Pose Landmarker. | Integer > 0 |
1 |
min_pose_detection_confidence |
Il punteggio di attendibilità minimo per il rilevamento della posa da considerare positivo. | Float [0.0,1.0] |
0.5 |
min_pose_presence_confidence |
Il punteggio di attendibilità minimo del punteggio di presenza della posa nel rilevamento dei punti di riferimento della posa. | Float [0.0,1.0] |
0.5 |
min_tracking_confidence |
Il punteggio di attendibilità minimo per il monitoraggio della posa da considerare riuscito. | Float [0.0,1.0] |
0.5 |
output_segmentation_masks |
Indica se l'indicatore di posizione della posa restituisce una maschera di segmentazione per la posa rilevata. | Boolean |
False |
result_callback |
Imposta l'ascoltatore dei risultati in modo da ricevere i risultati del rilevamento di punti di riferimento
in modo asincrono quando la funzionalità è in modalità live streaming.
Può essere utilizzato solo quando la modalità di esecuzione è impostata su LIVE_STREAM |
ResultListener |
N/A |
Modelli
Il rilevamento di punti di riferimento della posa utilizza una serie di modelli per prevedere i punti di riferimento della posa. Il primo modello rileva la presenza di corpi umani all'interno di un frame immagine e il secondo modello individua i punti di riferimento sui corpi.
I seguenti modelli sono raggruppati in un pacchetto scaricabile:
- Modello di rilevamento della posizione: rileva la presenza di corpi con alcuni punti di riferimento chiave della posizione.
- Modello di landmarker della posa: aggiunge una mappatura completa della posa. Il modello genera una stima di 33 punti di riferimento della posa tridimensionali.
Questo bundle utilizza una rete neurale convoluzionale simile a MobileNetV2 ed è ottimizzato per le applicazioni per il fitness in tempo reale on-device. Questa variante del modello BlazePose utilizza GHUM, una pipeline di modellazione 3D delle forme umane, per stimare la posa completa del corpo 3D di un individuo in immagini o video.
| Pacchetto di modelli | Forma di input | Tipo di dati | Schede del modello | Versioni |
|---|---|---|---|---|
| Indicatore di posizione (lite) | Rilevamento pose: 224 x 224 x 3 Indicatore di pose: 256 x 256 x 3 |
float 16 | info | Ultime notizie |
| Indicatore di pose (completo) | Rilevamento pose: 224 x 224 x 3 Indicatore di pose: 256 x 256 x 3 |
float 16 | info | Ultime notizie |
| Indicatore di pose (intenso) | Rilevamento pose: 224 x 224 x 3 Indicatore di pose: 256 x 256 x 3 |
float 16 | info | Ultime notizie |
Modello di rilevamento di punti di riferimento per le pose
Il modello di rilevamento di punti di riferimento della posa monitora 33 posizioni di punti di riferimento del corpo, che rappresentano la posizione approssimativa delle seguenti parti del corpo:
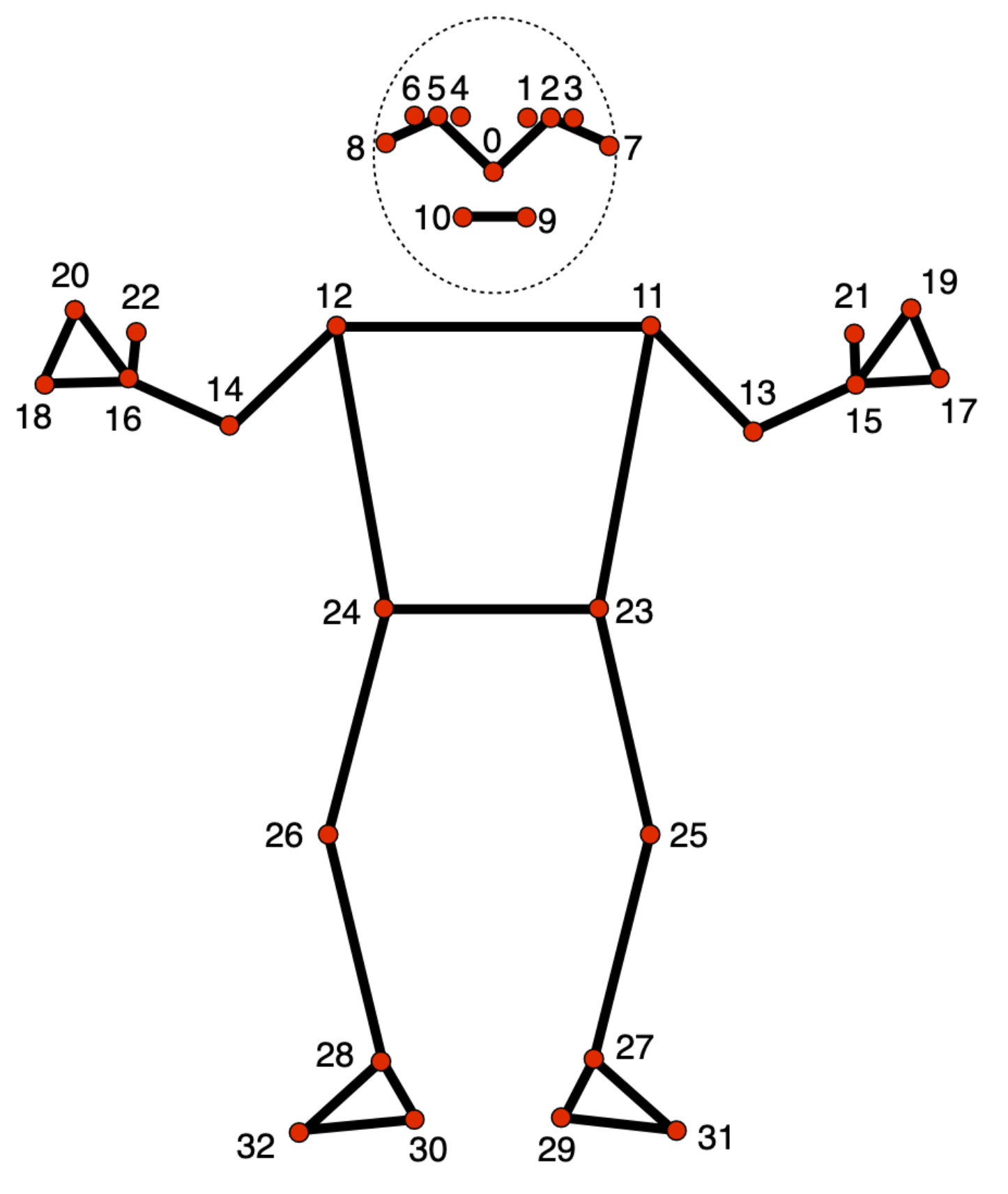
0 - nose
1 - left eye (inner)
2 - left eye
3 - left eye (outer)
4 - right eye (inner)
5 - right eye
6 - right eye (outer)
7 - left ear
8 - right ear
9 - mouth (left)
10 - mouth (right)
11 - left shoulder
12 - right shoulder
13 - left elbow
14 - right elbow
15 - left wrist
16 - right wrist
17 - left pinky
18 - right pinky
19 - left index
20 - right index
21 - left thumb
22 - right thumb
23 - left hip
24 - right hip
25 - left knee
26 - right knee
27 - left ankle
28 - right ankle
29 - left heel
30 - right heel
31 - left foot index
32 - right foot index
L'output del modello contiene sia le coordinate normalizzate (Landmarks) sia le coordinate mondiali (WorldLandmarks) per ogni punto di riferimento.