

MediaPipe Pose Landmarker タスクを使用すると、画像または動画内の人体のランドマークを検出できます。このタスクを使用すると、体の主要な位置を特定し、姿勢を分析して、動きを分類できます。このタスクでは、単一の画像または動画を処理する ML モデルを使用します。このタスクは、画像座標と 3 次元ワールド座標でボディポーズのランドマークを出力します。
使ってみる
このタスクを使用するには、対象プラットフォームの実装ガイドに沿って操作します。以下のプラットフォーム固有のガイドでは、推奨モデルや、推奨構成オプションを含むコード例など、このタスクの基本的な実装について説明します。
タスクの詳細
このセクションでは、このタスクの機能、入力、出力、構成オプションについて説明します。
機能
- 入力画像の処理 - 処理には、画像の回転、サイズ変更、正規化、色空間の変換が含まれます。
- スコアしきい値 - 予測スコアに基づいて結果をフィルタします。
| タスク入力 | タスクの出力 |
|---|---|
Pose Landmarker は、次のいずれかのデータ型の入力を受け入れます。
|
Pose Landmarker は次の結果を出力します。
|
構成オプション
このタスクには、次の構成オプションがあります。
| オプション名 | 説明 | 値の範囲 | デフォルト値 |
|---|---|---|---|
running_mode |
タスクの実行モードを設定します。モードは次の 3 つです。 IMAGE: 単一画像入力のモード。 動画: 動画のデコードされたフレームのモード。 LIVE_STREAM: カメラなどからの入力データのライブ配信モード。 このモードでは、resultListener を呼び出して、結果を非同期で受信するリスナーを設定する必要があります。 |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
num_poses |
Pose Landmarker で検出できるポーズの最大数。 | Integer > 0 |
1 |
min_pose_detection_confidence |
ポーズ検出が成功と見なされるための最小信頼度スコア。 | Float [0.0,1.0] |
0.5 |
min_pose_presence_confidence |
ポーズランドマーク検出でのポーズ存在スコアの最小信頼度スコア。 | Float [0.0,1.0] |
0.5 |
min_tracking_confidence |
ポーズ トラッキングが成功とみなされるための最小信頼スコア。 | Float [0.0,1.0] |
0.5 |
output_segmentation_masks |
Pose Landmarker が検出されたポーズのセグメンテーション マスクを出力するかどうか。 | Boolean |
False |
result_callback |
Pose Landmarker がライブ配信モードの場合に、ランドマークの結果を非同期で受信するように結果リスナーを設定します。実行モードが LIVE_STREAM に設定されている場合にのみ使用できます。 |
ResultListener |
N/A |
モデル
ポーズ ランドマークは、一連のモデルを使用してポーズ ランドマークを予測します。最初のモデルは画像フレーム内の人間の存在を検出し、2 つ目のモデルは身体上のランドマークを特定します。
次のモデルは、ダウンロード可能なモデル バンドルにまとめられています。
- ポーズ検出モデル: いくつかの重要なポーズ ランドマークを使用して、身体の存在を検出します。
- ポーズ ランドマークモデル: ポーズの完全なマッピングを追加します。モデルは、33 個の 3 次元ポーズランドマークの推定値を出力します。
このバンドルは MobileNetV2 に似た畳み込みニューラル ネットワークを使用しており、オンデバイスのリアルタイム フィットネス アプリ用に最適化されています。BlazePose モデルのこのバリアントは、3D 人間形状モデリング パイプラインである GHUM を使用して、画像または動画内の個人の完全な 3D ボディポーズを推定します。
| モデル バンドル | 入力シェイプ | データ型 | モデルカード | バージョン |
|---|---|---|---|---|
| Pose Landmarker(Lite) | ポーズ検出器: 224 x 224 x 3 ポーズ ランドマーク: 256 x 256 x 3 |
float 16 | info | 最新 |
| Pose Landmarker(完全版) | ポーズ検出器: 224 x 224 x 3 ポーズ ランドマーク: 256 x 256 x 3 |
float 16 | info | 最新 |
| ポーズ ランドマーク(負荷が高い) | ポーズ検出器: 224 x 224 x 3 ポーズ ランドマーク: 256 x 256 x 3 |
float 16 | info | 最新 |
ポーズ ランドマークモデル
ポーズ ランドマーク モデルは、次の体の部分のおおよその位置を表す 33 個の体のランドマークの位置を追跡します。
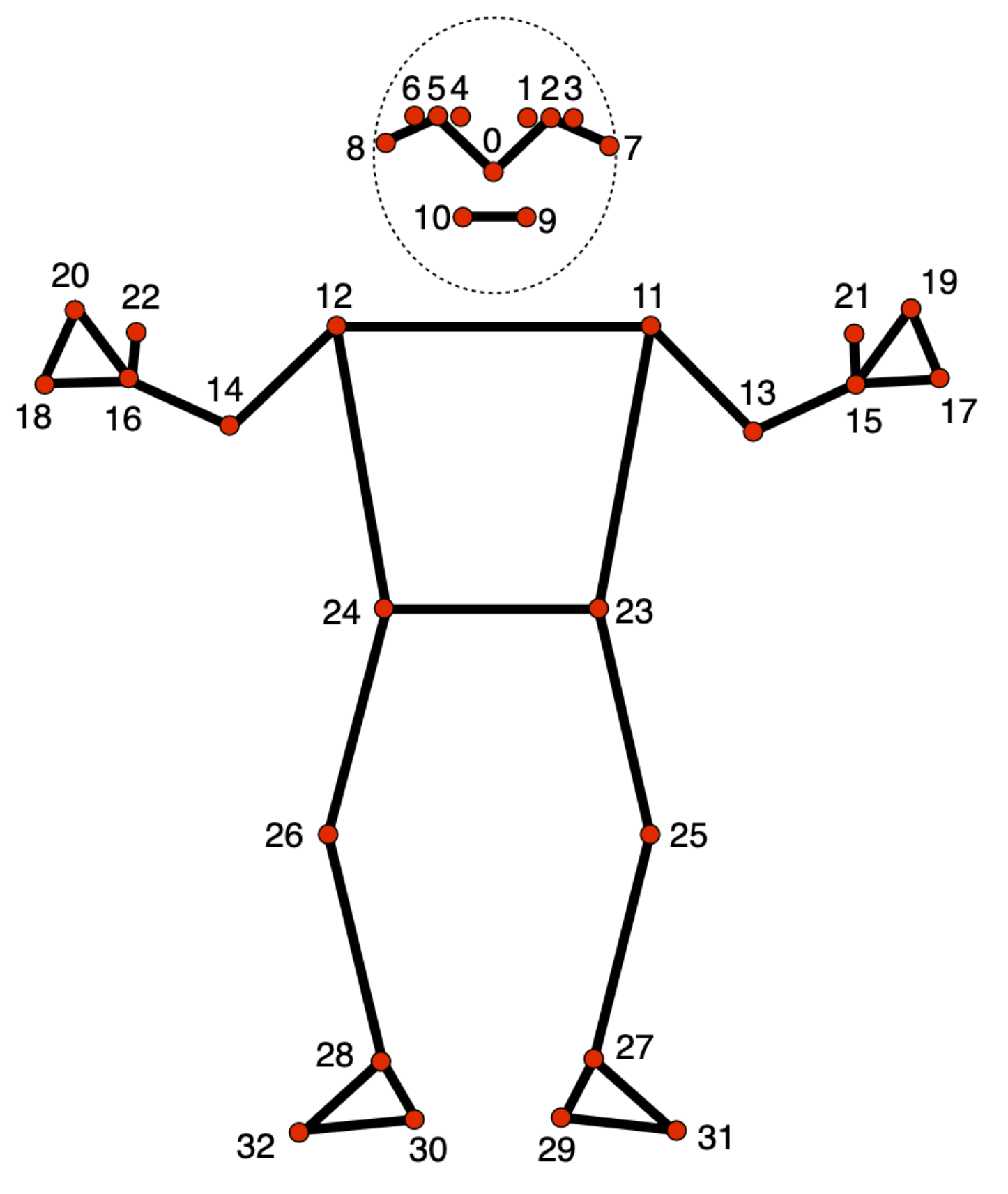
0 - nose
1 - left eye (inner)
2 - left eye
3 - left eye (outer)
4 - right eye (inner)
5 - right eye
6 - right eye (outer)
7 - left ear
8 - right ear
9 - mouth (left)
10 - mouth (right)
11 - left shoulder
12 - right shoulder
13 - left elbow
14 - right elbow
15 - left wrist
16 - right wrist
17 - left pinky
18 - right pinky
19 - left index
20 - right index
21 - left thumb
22 - right thumb
23 - left hip
24 - right hip
25 - left knee
26 - right knee
27 - left ankle
28 - right ankle
29 - left heel
30 - right heel
31 - left foot index
32 - right foot index
モデルの出力には、各ランドマークの正規化された座標(Landmarks)とワールド座標(WorldLandmarks)の両方が含まれます。