
هر رویکرد مسئولانه ای برای به کارگیری هوش مصنوعی (AI) باید شامل سیاست های ایمنی ، مصنوعات شفافیت و پادمان ها باشد، اما مسئولیت پذیری با هوش مصنوعی بیش از دنبال کردن چک لیست ها است.
محصولات GenAI نسبتاً جدید هستند و رفتارهای یک برنامه کاربردی می تواند بیشتر از نرم افزارهای قبلی متفاوت باشد. به همین دلیل، باید مدلهایی را که برای بررسی نمونههایی از رفتار مدل استفاده میشوند، بررسی کنید و شگفتیها را بررسی کنید.
Prompting رابط همه جا برای تعامل با GenAI است و مهندسی آن اعلان ها به همان اندازه که علم است هنر است. با این حال، ابزارهایی وجود دارند که میتوانند به شما در بهبود تجربی اعلانهای LLM کمک کنند، مانند ابزار تفسیرپذیری یادگیری (LIT). LIT یک ابزار منبع باز برای درک بصری و اشکال زدایی مدل های هوش مصنوعی است که می تواند به عنوان یک اشکال زدا برای کارهای مهندسی سریع استفاده شود. با استفاده از Colab یا Codelab آموزش ارائه شده را همراهی کنید.
مدل های جما را با LIT تجزیه و تحلیل کنید
| | |
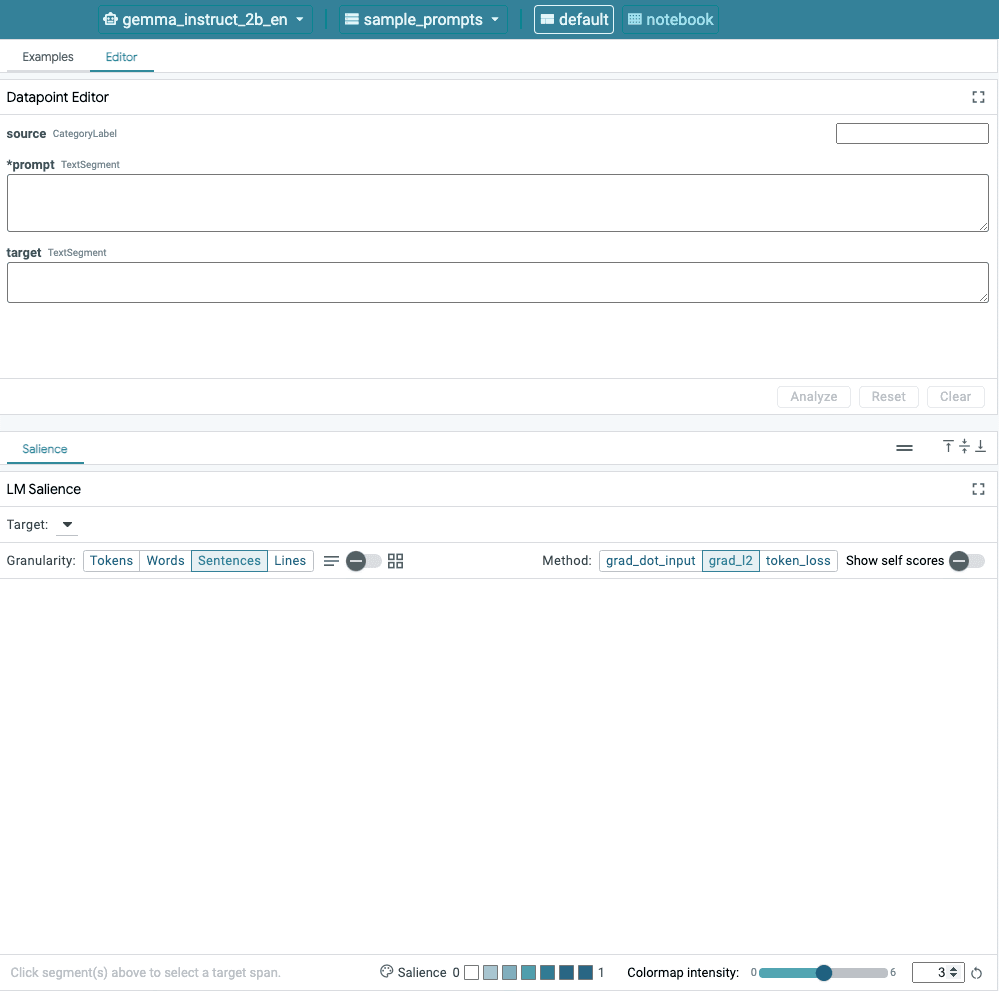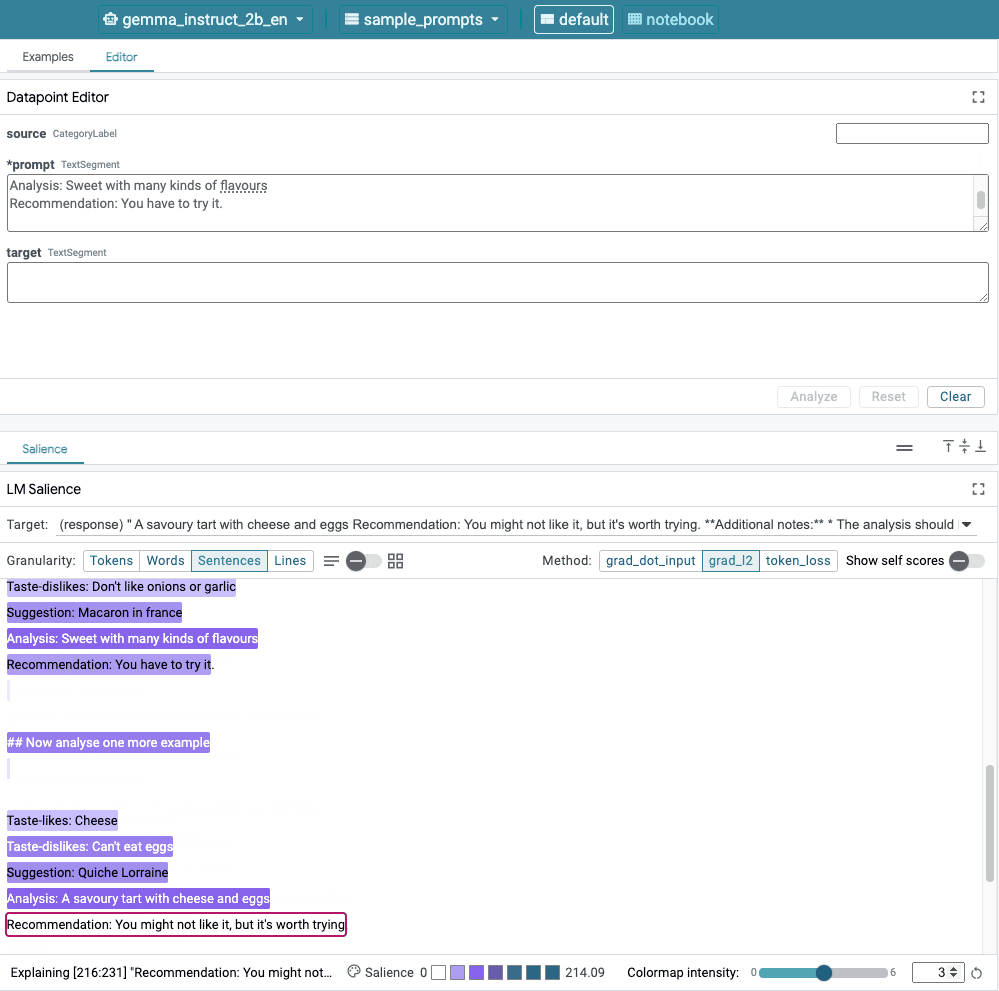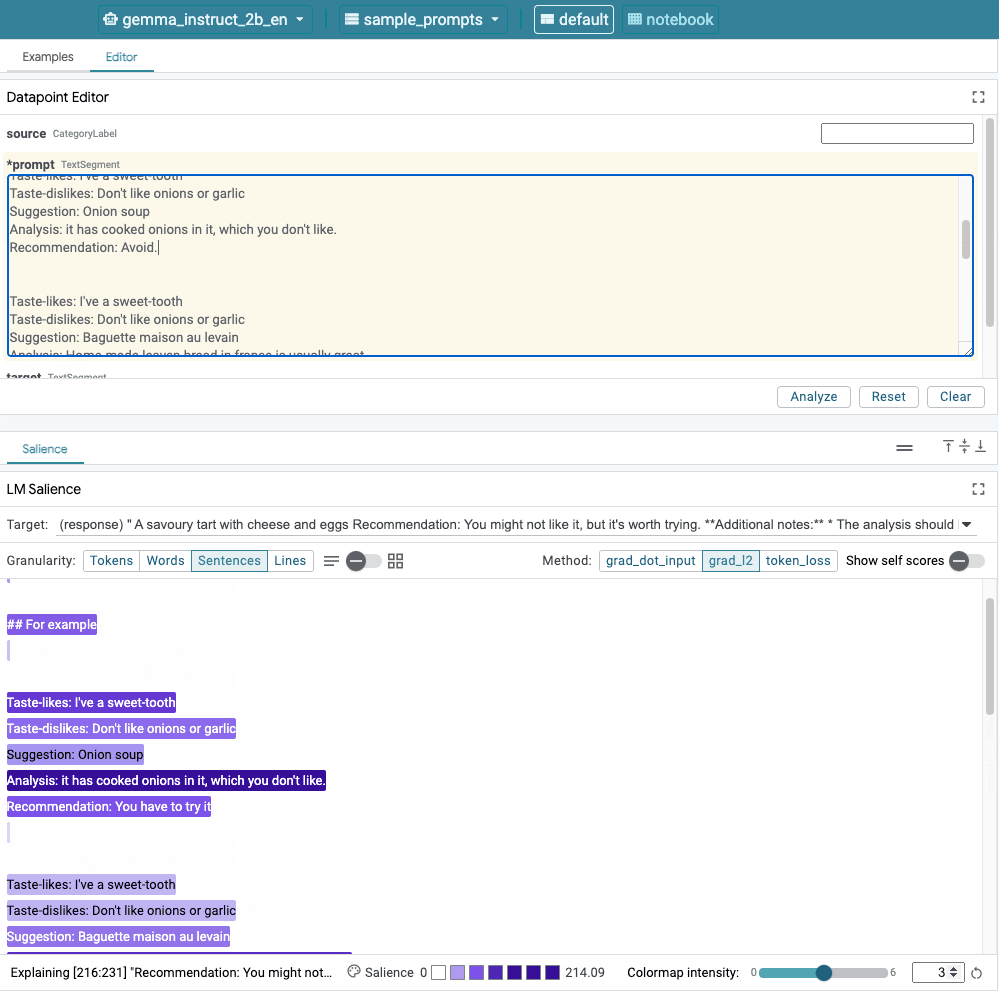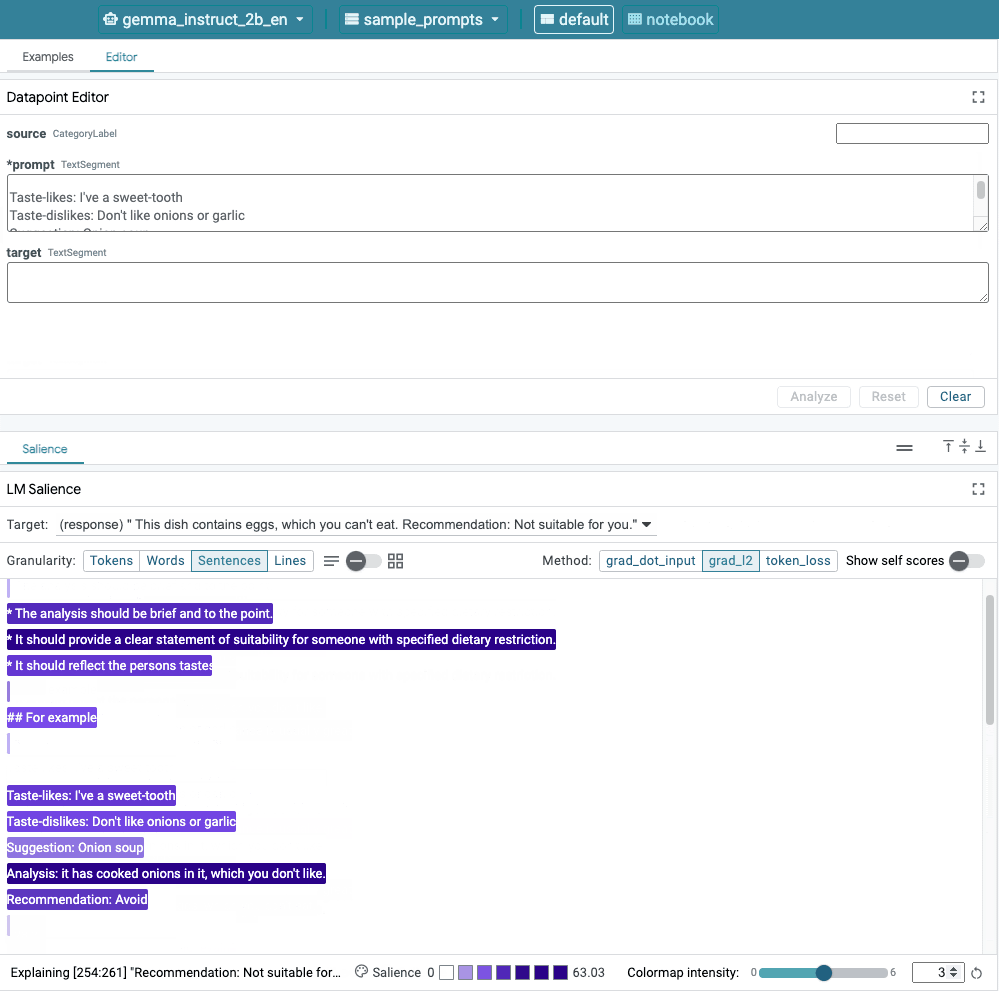
شکل 1. رابط کاربری LIT: ویرایشگر Datapoint در بالا به کاربران اجازه می دهد تا درخواست های خود را ویرایش کنند. در پایین، ماژول LM Salience به آنها اجازه می دهد تا نتایج برجسته را بررسی کنند.
می توانید از LIT در دستگاه محلی خود، در Colab یا در Google Cloud استفاده کنید.
شامل تیم های غیر فنی در کاوش و اکتشاف مدل
تفسیرپذیری به معنای تلاش گروهی است که تخصص را در سیاست، حقوق و موارد دیگر در بر می گیرد. رسانه بصری و توانایی تعاملی LIT برای بررسی ویژگیهای برجسته و کاوش نمونهها میتواند به سهامداران مختلف کمک کند تا یافتهها را به اشتراک بگذارند و ارتباط برقرار کنند. این رویکرد می تواند تنوع چشم انداز بیشتری را در کاوش مدل، کاوش و اشکال زدایی امکان پذیر کند. قرار دادن هم تیمی های خود با این روش های فنی می تواند درک آنها را از نحوه عملکرد مدل ها افزایش دهد. علاوه بر این، مجموعهای از تخصصهای متنوعتر در آزمایشهای اولیه مدل نیز میتواند به کشف نتایج نامطلوب که قابل بهبود هستند کمک کند.