
Mit der MediaPipe Gesture Recognizer-Aufgabe können Sie Handbewegungen in Echtzeit erkennen. Sie liefert die Ergebnisse der erkannten Handbewegungen und die Hand-Landmarks der erkannten Hände. In dieser Anleitung erfahren Sie, wie Sie den Gesture Recognizer für Web- und JavaScript-Apps verwenden.
In der Demo können Sie sich die Umsetzung dieser Aufgabe ansehen. Weitere Informationen zu den Funktionen, Modellen und Konfigurationsoptionen dieser Aufgabe finden Sie in der Übersicht.
Codebeispiel
Der Beispielcode für Gesture Recognizer enthält eine vollständige Implementierung dieser Aufgabe in JavaScript. Mit diesem Code können Sie diese Aufgabe testen und mit der Entwicklung Ihrer eigenen App zur Gestenerkennung beginnen. Sie können das Beispiel für die Gestenerkennung einfach in Ihrem Webbrowser ansehen, ausführen und bearbeiten.
Einrichtung
In diesem Abschnitt werden die wichtigsten Schritte zum Einrichten Ihrer Entwicklungsumgebung für die Verwendung von Gesture Recognizer beschrieben. Allgemeine Informationen zum Einrichten Ihrer Web- und JavaScript-Entwicklungsumgebung, einschließlich der Anforderungen an die Plattformversion, finden Sie im Einrichtungsleitfaden für das Web.
JavaScript-Pakete
Der Code für die Bewegungserkennung ist über das MediaPipe-@mediapipe/tasks-vision-NPM-Paket verfügbar. Sie können diese Bibliotheken gemäß der Anleitung im Einrichtungsleitfaden der Plattform suchen und herunterladen.
Sie können die erforderlichen Pakete über NPM mit dem folgenden Befehl installieren:
npm install @mediapipe/tasks-vision
Wenn Sie den Aufgaben-Code über einen CDN-Dienst (Content Delivery Network) importieren möchten, fügen Sie den folgenden Code in das <head>-Tag in Ihrer HTML-Datei ein:
<!-- You can replace JSDeliver with another CDN if you prefer to -->
<head>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision/vision_bundle.mjs"
crossorigin="anonymous"></script>
</head>
Modell
Für die MediaPipe Gesture Recognizer-Aufgabe ist ein trainiertes Modell erforderlich, das mit dieser Aufgabe kompatibel ist. Weitere Informationen zu den verfügbaren trainierten Modellen für Gesture Recognizer finden Sie in der Aufgabenübersicht im Abschnitt „Modelle“.
Wählen Sie das Modell aus, laden Sie es herunter und speichern Sie es in Ihrem Projektverzeichnis:
<dev-project-root>/app/shared/models/
Aufgabe erstellen
Verwenden Sie eine der createFrom...()-Funktionen von Gesture Recognizer, um die Aufgabe für die Ausführung von Inferenz zu vorbereiten. Verwenden Sie die createFromModelPath()-Funktion mit einem relativen oder absoluten Pfad zur trainierten Modelldatei.
Wenn Ihr Modell bereits in den Arbeitsspeicher geladen ist, können Sie die Methode createFromModelBuffer() verwenden.
Im folgenden Codebeispiel wird die Verwendung der Funktion createFromOptions() zum Einrichten der Aufgabe veranschaulicht. Mit der Funktion createFromOptions können Sie die Gestenerkennung mit Konfigurationsoptionen anpassen. Weitere Informationen zu Konfigurationsoptionen finden Sie unter Konfigurationsoptionen.
Der folgende Code zeigt, wie Sie die Aufgabe mit benutzerdefinierten Optionen erstellen und konfigurieren:
// Create task for image file processing:
const vision = await FilesetResolver.forVisionTasks(
// path/to/wasm/root
"https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision@latest/wasm "
);
const gestureRecognizer = await GestureRecognizer.createFromOptions(vision, {
baseOptions: {
modelAssetPath: "https://storage.googleapis.com/mediapipe-tasks/gesture_recognizer/gesture_recognizer.task"
},
numHands: 2
});
Konfigurationsoptionen
Für diese Aufgabe sind die folgenden Konfigurationsoptionen für Webanwendungen verfügbar:
| Option | Beschreibung | Wertebereich | Standardwert |
|---|---|---|---|
runningMode |
Legt den Ausführungsmodus für die Aufgabe fest. Es gibt zwei Modi: IMAGE: Der Modus für einzelne Bildeingaben. VIDEO: Der Modus für decodierte Frames eines Videos oder eines Livestreams von Eingabedaten, z. B. von einer Kamera. |
{IMAGE, VIDEO} |
IMAGE |
num_hands |
Die maximale Anzahl der Hände, die von GestureRecognizer erkannt werden können.
|
Any integer > 0 |
1 |
min_hand_detection_confidence |
Der Mindestkonfidenzwert für die erfolgreiche Erkennung einer Hand im Modell zur Handflächenerkennung. | 0.0 - 1.0 |
0.5 |
min_hand_presence_confidence |
Der minimale Konfidenzwert für den Hand-Präsenz-Wert im Modell zur Erkennung von Hand-Landmarks. Im Videomodus und im Livestream-Modus von Gesture Recognizer wird das Handflächenerkennungsmodell ausgelöst, wenn der Konfidenzwert für die Handpräsenz des Hand-Landmark-Modells unter diesem Schwellenwert liegt. Andernfalls wird ein einfacher Handtracking-Algorithmus verwendet, um die Position der Hand(e) für die anschließende Landmark-Erkennung zu bestimmen. | 0.0 - 1.0 |
0.5 |
min_tracking_confidence |
Der Mindestkonfidenzwert, damit das Handtracking als erfolgreich gilt. Dies ist der IoU-Grenzwert für den Begrenzungsrahmen zwischen Händen im aktuellen Frame und im letzten Frame. Wenn im Videomodus und im Streammodus des Gesture Recognizer das Tracking fehlschlägt, wird die Handerkennung ausgelöst. Andernfalls wird die Handerkennung übersprungen. | 0.0 - 1.0 |
0.5 |
canned_gestures_classifier_options |
Optionen zum Konfigurieren des Verhaltens des Klassifikators für vordefinierte Gesten. Die vordefinierten Gesten sind ["None", "Closed_Fist", "Open_Palm", "Pointing_Up", "Thumb_Down", "Thumb_Up", "Victory", "ILoveYou"]. |
|
|
custom_gestures_classifier_options |
Optionen zum Konfigurieren des Verhaltens des benutzerdefinierten Klassifikators für Gesten. |
|
|
Daten vorbereiten
Der Gesture Recognizer kann Gesten in Bildern in jedem Format erkennen, das vom Hostbrowser unterstützt wird. Die Aufgabe übernimmt auch die Vorverarbeitung der Dateneingabe, einschließlich Größenanpassung, Drehung und Wertnormalisierung. Wenn Sie Gesten in Videos erkennen möchten, können Sie die API verwenden, um jeweils ein Frame schnell zu verarbeiten. Anhand des Zeitstempels des Frames lässt sich ermitteln, wann die Gesten im Video auftreten.
Aufgabe ausführen
Der Gesture Recognizer verwendet die Methoden recognize() (mit dem Ausführungsmodus 'image') und recognizeForVideo() (mit dem Ausführungsmodus 'video'), um Inferenzvorgänge auszulösen. Die Aufgabe verarbeitet die Daten, versucht, Handbewegungen zu erkennen, und meldet dann die Ergebnisse.
Der folgende Code zeigt, wie die Verarbeitung mit dem Aufgabenmodell ausgeführt wird:
Bild
const image = document.getElementById("image") as HTMLImageElement; const gestureRecognitionResult = gestureRecognizer.recognize(image);
Video
await gestureRecognizer.setOptions({ runningMode: "video" }); let lastVideoTime = -1; function renderLoop(): void { const video = document.getElementById("video"); if (video.currentTime !== lastVideoTime) { const gestureRecognitionResult = gestureRecognizer.recognizeForVideo(video); processResult(gestureRecognitionResult); lastVideoTime = video.currentTime; } requestAnimationFrame(() => { renderLoop(); }); }
Aufrufe der Methoden recognize() und recognizeForVideo() des Gesture Recognizer werden synchron ausgeführt und blockieren den Thread der Benutzeroberfläche. Wenn Sie Gesten in Videoframes von der Kamera eines Geräts erkennen, wird der Haupt-Thread bei jeder Erkennung blockiert. Sie können dies verhindern, indem Sie Web Workers implementieren, um die Methoden recognize() und recognizeForVideo() in einem anderen Thread auszuführen.
Eine vollständigere Implementierung zum Ausführen einer Gesture Recognizer-Aufgabe finden Sie im Beispiel.
Ergebnisse verarbeiten und anzeigen
Der Gesture Recognizer generiert für jeden Erkennungslauf ein Ergebnisobjekt für die Gestenerkennung. Das Ergebnisobjekt enthält Hand-Landmarks in Bildkoordinaten, Hand-Landmarks in Weltkoordinaten, die Händigkeit(linke/rechte Hand) und Handgestenkategorien der erkannten Hände.
Im Folgenden sehen Sie ein Beispiel für die Ausgabedaten dieser Aufgabe:
Das resultierende GestureRecognizerResult enthält vier Komponenten. Jede Komponente ist ein Array, in dem jedes Element das erkannte Ergebnis einer einzelnen erkannten Hand enthält.
Links-/Rechtshänder
Die Händigkeit gibt an, ob die erkannten Hände links oder rechts sind.
Touch-Gesten
Die erkannten Gestenkategorien der erkannten Hände.
Landmarken
Es gibt 21 Hand-Landmarks, die jeweils aus
x-,y- undz-Koordinaten bestehen. Die Koordinatenxundywerden durch die Bildbreite bzw. -höhe auf [0,0, 1,0] normalisiert. Diez-Koordinate stellt die Tiefe des Orientierungspunkts dar. Der Ursprung ist die Tiefe am Handgelenk. Je kleiner der Wert ist, desto näher ist das Landmark an der Kamera. Die Größenordnung vonzentspricht in etwa der vonx.Sehenswürdigkeiten weltweit
Die 21 Hand-Landmarks werden auch in Weltkoordinaten dargestellt. Jedes Landmark besteht aus
x,yundz, die 3D-Koordinaten in Metern in der realen Welt mit dem Ursprung im geometrischen Mittelpunkt der Hand darstellen.
GestureRecognizerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Gestures:
Categories #0:
score : 0.76893
categoryName : Thumb_Up
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
Die folgenden Bilder zeigen eine Visualisierung der Aufgabenausgabe:
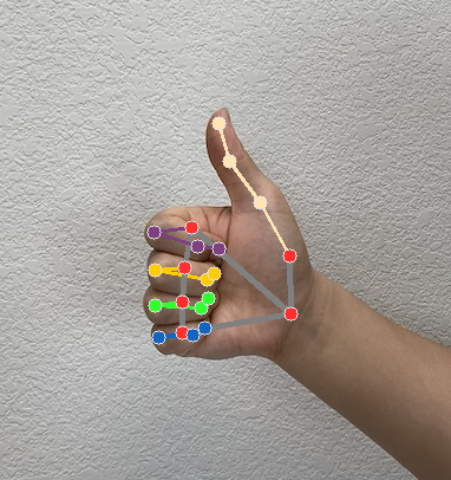
Eine vollständigere Implementierung zum Erstellen einer Gesture Recognizer-Aufgabe finden Sie im Beispiel.