Detyra MediaPipe Pose Landmarker ju lejon të zbuloni pika referimi të trupave njerëzorë në një imazh ose video. Ju mund ta përdorni këtë detyrë për të identifikuar vendndodhjet kryesore të trupit, për të analizuar qëndrimin dhe për të kategorizuar lëvizjet. Kjo detyrë përdor modele të mësimit të makinerive (ML) që funksionojnë me imazhe ose video të vetme. Detyra nxjerr pikat referuese të pozës së trupit në koordinatat e imazhit dhe në koordinatat botërore 3-dimensionale.
Filloni
Filloni ta përdorni këtë detyrë duke ndjekur udhëzuesin e zbatimit për platformën tuaj të synuar. Këta udhëzues specifikë të platformës ju përcjellin një zbatim bazë të kësaj detyre, duke përfshirë një model të rekomanduar dhe shembull kodi me opsionet e rekomanduara të konfigurimit:
- Android - Shembull kodi - Udhëzues
- Python - Shembull Kodi - Udhëzues
- Web - Shembull Kodi - Udhëzues
Detajet e detyrës
Ky seksion përshkruan aftësitë, hyrjet, daljet dhe opsionet e konfigurimit të kësaj detyre.
Veçoritë
- Përpunimi i imazhit në hyrje - Përpunimi përfshin rrotullimin e imazhit, ndryshimin e madhësisë, normalizimin dhe konvertimin e hapësirës së ngjyrave.
- Pragu i rezultatit - Filtro rezultatet bazuar në rezultatet e parashikimit.
| Hyrjet e detyrave | Rezultatet e detyrave |
|---|---|
Shënuesi i pozicionit pranon një hyrje të një prej llojeve të mëposhtme të të dhënave:
| Pose Landmarker nxjerr rezultatet e mëposhtme:
|
Opsionet e konfigurimeve
Kjo detyrë ka opsionet e mëposhtme të konfigurimit:
| Emri i opsionit | Përshkrimi | Gama e vlerave | Vlera e paracaktuar |
|---|---|---|---|
running_mode | Vendos modalitetin e ekzekutimit për detyrën. Ekzistojnë tre mënyra: IMAGE: Modaliteti për hyrjet e një imazhi të vetëm. VIDEO: Modaliteti për kornizat e dekoduara të një videoje. LIVE_STREAM: Modaliteti për një transmetim të drejtpërdrejtë të të dhënave hyrëse, si p.sh. nga një aparat fotografik. Në këtë modalitet, resultListener duhet të thirret për të vendosur një dëgjues për të marrë rezultatet në mënyrë asinkrone. | { IMAGE, VIDEO, LIVE_STREAM } | IMAGE |
num_poses | Numri maksimal i pozave që mund të zbulohet nga Shënuesi i Pozës. | Integer > 0 | 1 |
min_pose_detection_confidence | Rezultati minimal i besimit për zbulimin e pozës që të konsiderohet i suksesshëm. | Float [0.0,1.0] | 0.5 |
min_pose_presence_confidence | Rezultati minimal i besimit të rezultatit të pranisë së pozës në zbulimin e pikës referuese të pozës. | Float [0.0,1.0] | 0.5 |
min_tracking_confidence | Rezultati minimal i besimit për ndjekjen e pozës që të konsiderohet i suksesshëm. | Float [0.0,1.0] | 0.5 |
output_segmentation_masks | Nëse Pose Landmarker nxjerr një maskë segmentimi për pozën e zbuluar. | Boolean | False |
result_callback | Vendos dëgjuesin e rezultateve që të marrë rezultatet e pikë referimit në mënyrë asinkrone kur Pose Landmarker është në modalitetin e transmetimit të drejtpërdrejtë. Mund të përdoret vetëm kur modaliteti i ekzekutimit është caktuar në LIVE_STREAM | ResultListener | N/A |
Modelet
Pose Landmarker përdor një seri modelesh për të parashikuar pikat referuese të pozës. Modeli i parë zbulon praninë e trupave të njeriut brenda një kornize imazhi, dhe modeli i dytë lokalizon pikat referuese në trupa.
Modelet e mëposhtme janë paketuar së bashku në një paketë modelesh të shkarkueshme:
- Modeli i zbulimit të pozës : zbulon praninë e trupave me disa pika kryesore të pozave.
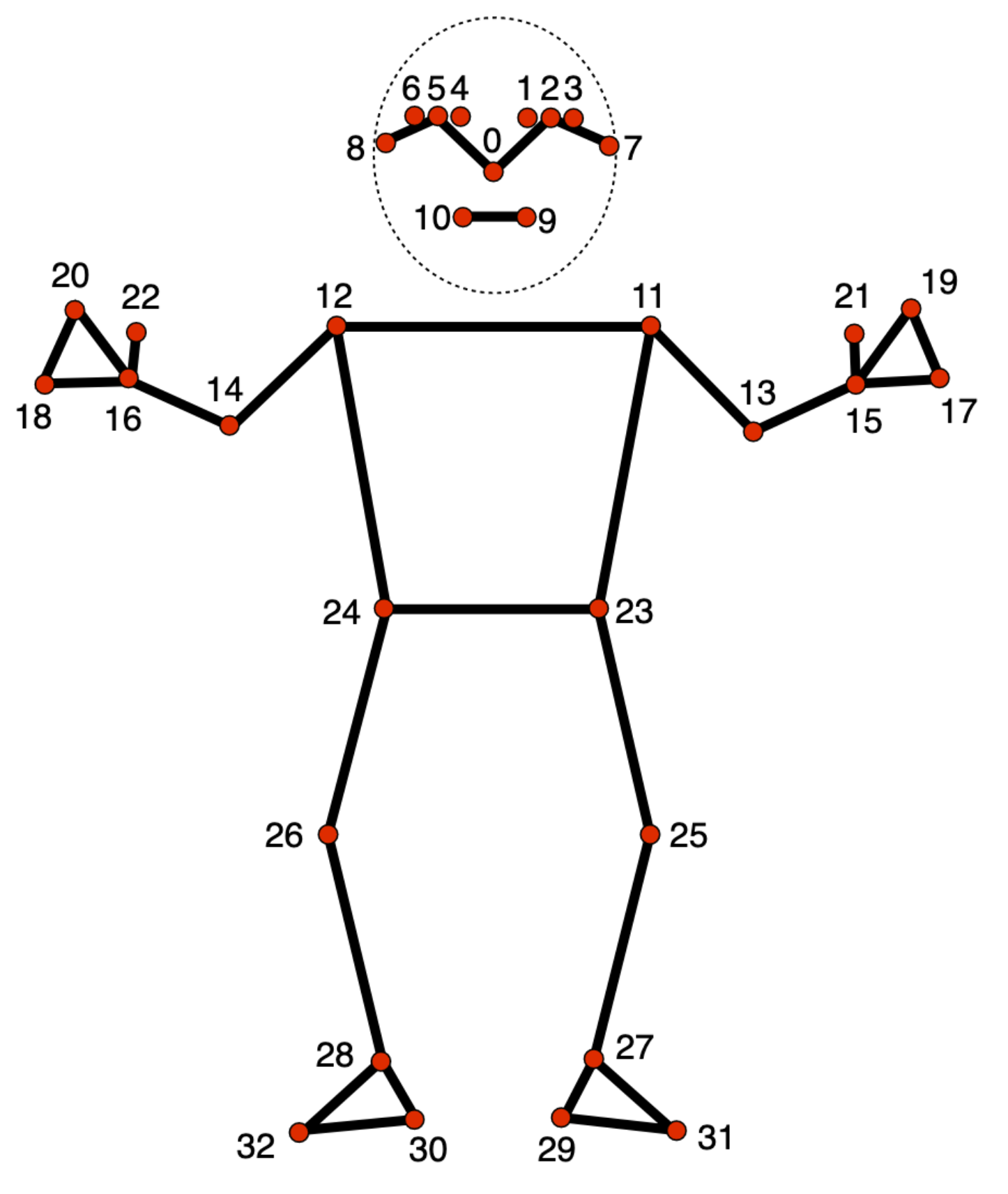
- Modeli i shënjuesit të pozës : shton një hartë të plotë të pozës. Modeli nxjerr një vlerësim prej 33 pikë referimi 3-dimensionale.
Kjo paketë përdor një rrjet nervor konvolucionist të ngjashëm me MobileNetV2 dhe është optimizuar për aplikacione fitnesi në pajisje, në kohë reale. Ky variant i modelit BlazePose përdor GHUM , një tubacion modelimi i formës njerëzore 3D, për të vlerësuar pozën e plotë të trupit 3D të një individi në imazhe ose video.
| Paketa e modelit | Forma e hyrjes | Lloji i të dhënave | Kartat Model | Versionet |
|---|---|---|---|---|
| Shënues i pozës (lite) | Detektor pozash: 224 x 224 x 3 Shënuesi i pozës: 256 x 256 x 3 | noton 16 | informacion | E fundit |
| Shënuesi i pozës (e plotë) | Detektor pozash: 224 x 224 x 3 Shënuesi i pozës: 256 x 256 x 3 | noton 16 | informacion | E fundit |
| Pozë pikë referimi (e rëndë) | Detektor pozash: 224 x 224 x 3 Shënuesi i pozës: 256 x 256 x 3 | noton 16 | informacion | E fundit |