L'outil Utilisation de l'ordinateur vous permet de créer des agents de contrôle pour navigateur, mobile et ordinateur de bureau qui interagissent avec les tâches et les automatisent. À l'aide de captures d'écran, le modèle peut "voir" un écran d'ordinateur et "agir" en générant des actions d'interface utilisateur spécifiques, comme des clics de souris et des saisies au clavier. Comme pour l'appel de fonction, vous devrez implémenter l'environnement d'exécution côté client pour recevoir et exécuter les actions d'utilisation de l'ordinateur.
Gemini 3.5 Flash est le modèle recommandé pour l'utilisation de l'ordinateur. Il offre plusieurs nouvelles fonctionnalités :
- Compatibilité multi-environnements : créez des agents pour les environnements navigateur, mobile et ordinateur.
- Actions simplifiées avec des intents : les actions incluent un champ
intentqui explique le raisonnement du modèle pour chaque étape. - Règles de sécurité configurables : affinez le comportement de sécurité avec des catégories et des remplacements de règles intégrés.
- Détection de l'injection de prompt : activez l'analyse des captures d'écran pour détecter les instructions adversariales cachées.
Avec l'utilisation de l'ordinateur, vous pouvez créer des agents qui :
- Automatisez la saisie de données répétitives ou le remplissage de formulaires sur les sites Web.
- Effectuer des tests automatisés des applications Web et des parcours utilisateur
- Effectuer des recherches sur différents sites Web (par exemple, recueillir des informations sur les produits, les prix et les avis sur les sites d'e-commerce pour prendre une décision d'achat)
Voici un exemple minimal d'initialisation du client et d'envoi d'un prompt au modèle avec l'outil computer_use activé pour un environnement de navigateur :
Python
from google import genai
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Search for 'Gemini API' on Google.",
tools=[{"type": "computer_use", "environment": "browser"}]
)
print(interaction)
JavaScript
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI();
const interaction = await ai.interactions.create({
model: 'gemini-3.5-flash',
input: "Search for 'Gemini API' on Google.",
tools: [{ type: "computer_use", environment: "browser" }]
});
console.log(interaction);
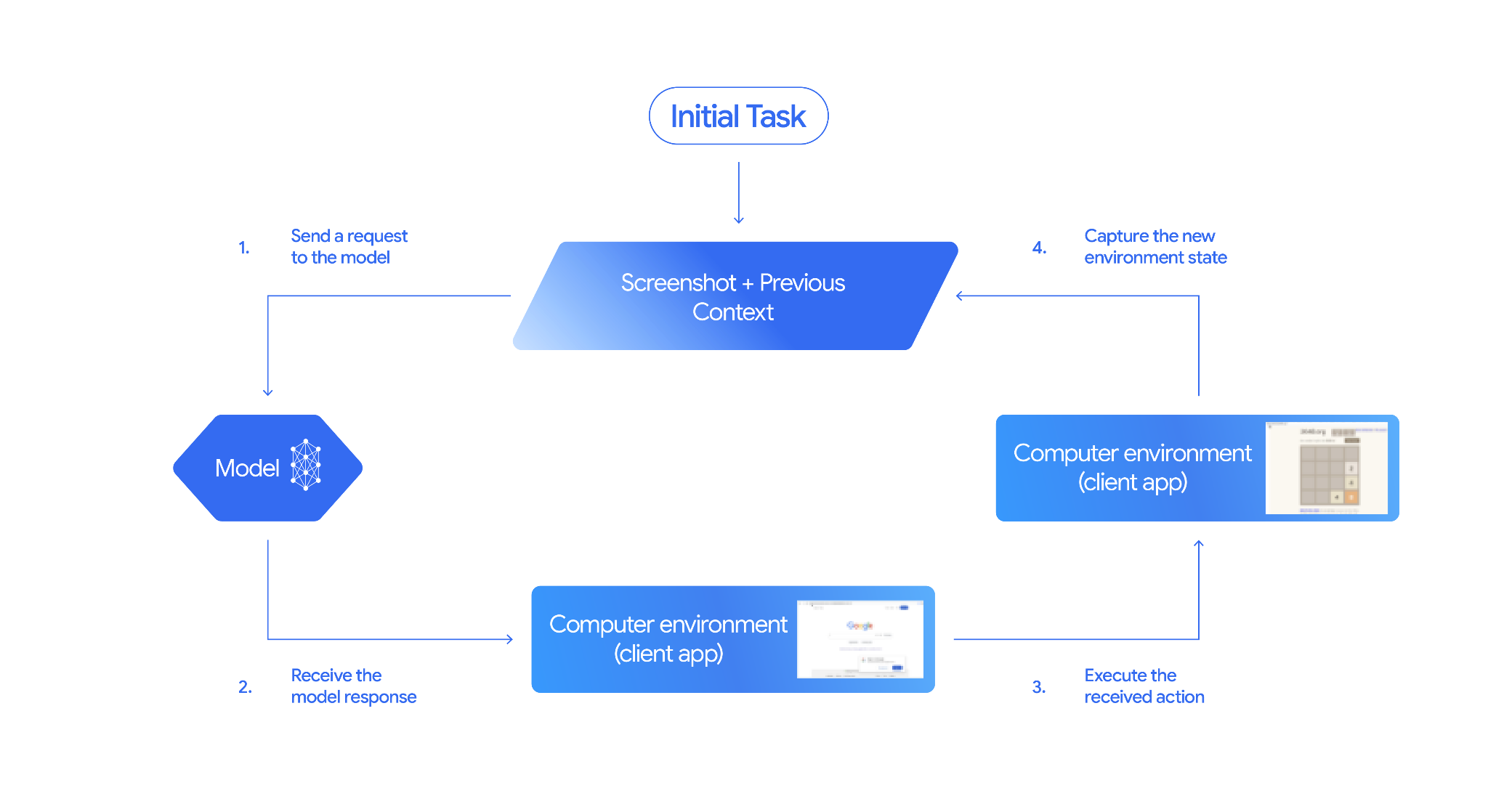
Fonctionnement de l'utilisation d'un ordinateur
Pour créer un agent avec le modèle Computer Use, vous devez configurer une boucle continue entre votre application et l'API. Voici ce que votre code fera à chaque étape :
- Envoyer une requête au modèle
- Votre application envoie une requête API contenant l'outil Utilisation de l'ordinateur, vos paramètres de configuration (comme l'environnement cible), la requête de l'utilisateur et une capture d'écran de l'écran actuel.
- Recevoir la réponse du modèle
- Le modèle analyse l'écran et la requête, puis renvoie une réponse qui inclut une
function_callsuggérée représentant une action d'interface utilisateur (comme un clic, un défilement ou une frappe). - Pour Gemini 3.5 Flash, la réponse inclut également un raisonnement
intentexpliquant pourquoi le modèle a choisi cette action. - Pour les anciens modèles (comme
gemini-2.5-computer-use-preview-10-2025), la réponse peut inclure unsafety_decisionprovenant d'un système de sécurité interne qui classe l'action comme régulière/autorisée,require_confirmation(nécessitant l'approbation de l'utilisateur) ou bloquée.
- Le modèle analyse l'écran et la requête, puis renvoie une réponse qui inclut une
- Exécutez l'action reçue.
- Si l'action est autorisée (ou si l'utilisateur la confirme), votre code côté client analyse le
function_call, met à l'échelle les coordonnées normalisées pour qu'elles correspondent à votre fenêtre d'affichage et exécute l'action dans votre environnement cible à l'aide d'outils d'automatisation (tels que Playwright). Si l'action est bloquée, votre client doit arrêter l'exécution ou gérer l'interruption.
- Si l'action est autorisée (ou si l'utilisateur la confirme), votre code côté client analyse le
- Capturer l'état du nouvel environnement
- Une fois l'action exécutée, votre application capture une nouvelle capture d'écran et la renvoie au modèle dans un
function_resultpour demander la prochaine étape.
- Une fois l'action exécutée, votre application capture une nouvelle capture d'écran et la renvoie au modèle dans un
Ce processus se répète ensuite à partir de l'étape 2, en sollicitant continuellement la prochaine action du modèle jusqu'à ce que la tâche soit terminée ou interrompue.
Implémenter l'utilisation de l'ordinateur
Avant de créer des éléments avec l'outil Utilisation de l'ordinateur, vous devez configurer les éléments suivants :
- Environnement d'exécution sécurisé : exécutez votre agent dans une VM ou un conteneur en bac à sable pour l'isoler de votre système hôte et limiter son impact potentiel. L'implémentation de référence inclut un bac à sable basé sur Docker, prêt à l'emploi, que vous pouvez utiliser comme point de départ.
- Gestionnaire d'actions côté client : implémentez la logique côté client pour exécuter des coordonnées, saisir du texte et prendre des captures d'écran.
Les exemples ci-dessous utilisent un navigateur Web comme environnement d'exécution et Playwright comme gestionnaire côté client.
0. Configurer Playwright
Commencez par installer les packages requis :
pip install google-genai playwright
playwright install chromium
Ensuite, initialisez une instance de navigateur Playwright à utiliser pour l'exécution :
from playwright.sync_api import sync_playwright
# 1. Configure screen dimensions for the target environment
SCREEN_WIDTH = 1440
SCREEN_HEIGHT = 900
# 2. Start the Playwright browser
# In production, utilize a sandboxed environment.
playwright = sync_playwright().start()
# Set headless=False to see the actions performed on your screen
browser = playwright.chromium.launch(headless=False)
# 3. Create a context and page with the specified dimensions
context = browser.new_context(
viewport={"width": SCREEN_WIDTH, "height": SCREEN_HEIGHT}
)
page = context.new_page()
# 4. Navigate to an initial page to start the task
page.goto("https://www.google.com")
# The 'page', 'SCREEN_WIDTH', and 'SCREEN_HEIGHT' variables
# will be used in the steps below.
1. Envoyer une requête au modèle
Initialisez la bibliothèque cliente et configurez l'outil d'utilisation de l'ordinateur. Notez qu'il n'est pas nécessaire de spécifier la taille d'affichage lorsque vous envoyez une requête. Le modèle prédit les coordonnées en pixels mises à l'échelle en fonction de la hauteur et de la largeur de l'écran.
Gemini 3.5 Flash (recommandé)
Python
Utilisez le SDK Python google-genai (version 2.7.0 ou ultérieure) pour configurer une requête ciblant l'environnement du navigateur :
from google import genai
client = genai.Client()
interaction = client.interactions.create(
model='gemini-3.5-flash',
input="Find a flight from SF to Hawaii on Jun 30th, coming back on Jul 6th",
tools=[
{
"type": "computer_use",
"environment": "browser",
"enable_prompt_injection_detection": True
}
]
)
print(interaction)
JavaScript
Utilisez le SDK Node.js @google/genai pour configurer une requête ciblant l'environnement du navigateur :
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI();
const interaction = await ai.interactions.create({
model: 'gemini-3.5-flash',
input: "Find a flight from SF to Hawaii on Jun 30th, coming back on Jul 6th",
tools: [
{
type: "computer_use",
environment: "browser",
enable_prompt_injection_detection: true
}
]
});
console.log(interaction);
REST
Utilisez curl pour envoyer une requête :
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.5-flash",
"input": "Find me a flight from SF to Hawaii on Jun 30th, coming back on Jul 6th. Start by navigating directly to flights.google.com",
"tools": [
{
"type": "computer_use",
"environment": "browser",
"enable_prompt_injection_detection": true
}
]
}'
Gemini 2.5 (ancienne version)
Python
from google import genai
client = genai.Client()
# Specify predefined functions to exclude (optional)
excluded_functions = ["drag_and_drop"]
interaction = client.interactions.create(
model='gemini-2.5-computer-use-preview-10-2025',
input="Search for highly rated smart fridges on Google Shopping.",
tools=[
{
"type": "computer_use",
"environment": "browser",
"excluded_predefined_functions": excluded_functions
}
]
)
print(interaction)
JavaScript
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI();
// Specify predefined functions to exclude (optional)
const excludedFunctions = ["drag_and_drop"];
const interaction = await ai.interactions.create({
model: 'gemini-2.5-computer-use-preview-10-2025',
input: "Search for highly rated smart fridges on Google Shopping.",
tools: [
{
type: "computer_use",
environment: "browser",
excluded_predefined_functions: excludedFunctions
}
]
});
console.log(interaction);
2. Recevoir la réponse du modèle
Le modèle de réponse suggère un appel de fonction. Pour Gemini 3.5 Flash, la réponse contient un intent de raisonnement personnalisé ainsi que des coordonnées. Voici des exemples de ces deux types de réponses :
Gemini 3.5 Flash
{
"steps": [
{
"type": "function_call",
"name": "click",
"arguments": {
"x": 450,
"y": 120,
"intent": "Click the search box to type the destination."
}
}
]
}
Gemini 2.5 (ancienne version)
{
"steps": [
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "I will type the search query into the search bar."
}
]
},
{
"type": "function_call",
"name": "type_text_at",
"arguments": {
"x": 371,
"y": 470,
"text": "highly rated smart fridges",
"press_enter": true
}
}
]
}
3. Exécuter les actions reçues
Votre application doit analyser les coordonnées de la réponse, exécuter l'action et les mettre à l'échelle à partir des coordonnées normalisées 1000x1000.
Le code ci-dessous gère à la fois les anciennes commandes d'outil (click_at, type_text_at) et les commandes simplifiées de Gemini 3.5 Flash (click, type).
Python
from typing import Any, List, Tuple
import time
def denormalize_x(x: int, screen_width: int) -> int:
"""Convert normalized x coordinate (0-1000) to actual pixel coordinate."""
return int(x / 1000 * screen_width)
def denormalize_y(y: int, screen_height: int) -> int:
"""Convert normalized y coordinate (0-1000) to actual pixel coordinate."""
return int(y / 1000 * screen_height)
def execute_function_calls(interaction, page, screen_width, screen_height):
results = []
function_calls = [
step for step in interaction.steps if step.type == "function_call"
]
for function_call in function_calls:
action_result = {}
fname = function_call.name
args = function_call.arguments
print(f" -> Executing: {fname} (Intent: {args.get('intent', 'N/A')})")
try:
if fname in ("open_web_browser", "open_app"):
pass # Handled / already open
elif fname in ("click", "click_at", "double_click", "triple_click", "middle_click", "right_click", "move", "long_press"):
actual_x = denormalize_x(args["x"], screen_width)
actual_y = denormalize_y(args["y"], screen_height)
if fname in ("click", "click_at"):
page.mouse.click(actual_x, actual_y)
elif fname == "double_click":
page.mouse.dblclick(actual_x, actual_y)
elif fname == "right_click":
page.mouse.click(actual_x, actual_y, button="right")
elif fname == "middle_click":
page.mouse.click(actual_x, actual_y, button="middle")
elif fname == "move":
page.mouse.move(actual_x, actual_y)
elif fname in ("type", "type_text_at"):
actual_x = denormalize_x(args["x"], screen_width) if "x" in args else None
actual_y = denormalize_y(args["y"], screen_height) if "y" in args else None
text = args["text"]
press_enter = args.get("press_enter", False)
if actual_x is not None and actual_y is not None:
page.mouse.click(actual_x, actual_y)
# Clear field first
page.keyboard.press("Meta+A")
page.keyboard.press("Backspace")
page.keyboard.type(text)
if press_enter:
page.keyboard.press("Enter")
elif fname == "navigate":
page.goto(args["url"])
elif fname == "go_back":
page.go_back()
elif fname == "go_forward":
page.go_forward()
elif fname == "wait":
time.sleep(args.get("seconds", 1))
else:
print(f"Warning: Custom or unhandled function {fname}")
page.wait_for_load_state(timeout=5000)
time.sleep(1)
except Exception as e:
print(f"Error executing {fname}: {e}")
action_result = {"error": str(e)}
results.append((fname, function_call.id, action_result))
return results
JavaScript
function denormalizeX(x, screenWidth) {
// Convert normalized x coordinate (0-1000) to actual pixel coordinate.
return Math.floor((x / 1000) * screenWidth);
}
function denormalizeY(y, screenHeight) {
// Convert normalized y coordinate (0-1000) to actual pixel coordinate.
return Math.floor((y / 1000) * screenHeight);
}
async function executeFunctionCalls(interaction, page, screenWidth, screenHeight) {
const results = [];
const functionCalls = interaction.steps.filter(step => step.type === "function_call");
for (const functionCall of functionCalls) {
const actionResult = {};
const fname = functionCall.name;
const args = functionCall.arguments;
console.log(` -> Executing: ${fname} (Intent: ${args.intent || 'N/A'})`);
try {
if (fname === "open_web_browser" || fname === "open_app") {
// Handled / already open
} else if (["click", "click_at", "double_click", "triple_click", "middle_click", "right_click", "move", "long_press"].includes(fname)) {
const actualX = denormalizeX(args.x, screenWidth);
const actualY = denormalizeY(args.y, screenHeight);
if (fname === "click" || fname === "click_at") {
await page.mouse.click(actualX, actualY);
} else if (fname === "double_click") {
await page.mouse.dblclick(actualX, actualY);
} else if (fname === "right_click") {
await page.mouse.click(actualX, actualY, { button: "right" });
} else if (fname === "middle_click") {
await page.mouse.click(actualX, actualY, { button: "middle" });
} else if (fname === "move") {
await page.mouse.move(actualX, actualY);
}
} else if (fname === "type" || fname === "type_text_at") {
const actualX = args.x !== undefined ? denormalizeX(args.x, screenWidth) : null;
const actualY = args.y !== undefined ? denormalizeY(args.y, screenHeight) : null;
const text = args.text;
const pressEnter = args.press_enter || false;
if (actualX !== null && actualY !== null) {
await page.mouse.click(actualX, actualY);
}
// Clear field first
await page.keyboard.press("Meta+A");
await page.keyboard.press("Backspace");
await page.keyboard.type(text);
if (pressEnter) {
await page.keyboard.press("Enter");
}
} else if (fname === "navigate") {
await page.goto(args.url);
} else if (fname === "go_back") {
await page.goBack();
} else if (fname === "go_forward") {
await page.goForward();
} else if (fname === "wait") {
await new Promise(resolve => setTimeout(resolve, (args.seconds || 1) * 1000));
} else {
console.log(`Warning: Custom or unhandled function ${fname}`);
}
await page.waitForLoadState('load', { timeout: 5000 }).catch(() => {});
await new Promise(resolve => setTimeout(resolve, 1000));
} catch (e) {
console.log(`Error executing ${fname}: ${e}`);
actionResult.error = e.message;
}
results.push([fname, functionCall.id, actionResult]);
}
return results;
}
4. Comprendre l'état du nouvel environnement
Après avoir exécuté les actions, renvoyez le résultat de l'exécution de la fonction au modèle afin qu'il puisse utiliser ces informations pour générer l'action suivante. Si plusieurs actions (appels parallèles) ont été exécutées, vous devez envoyer un function_result pour chacune d'elles lors du tour de l'utilisateur suivant.
Python
import json
import base64
def get_function_responses(page, results):
screenshot_bytes = page.screenshot(type="png")
current_url = page.url
function_responses = []
for name, call_id, result in results:
function_responses.append({
"type": "function_result",
"name": name,
"call_id": call_id,
"result": [
{
"type": "text",
"text": json.dumps({"url": current_url, **result})
},
{
"type": "image",
"data": base64.b64encode(screenshot_bytes).decode("utf-8"),
"mime_type": "image/png"
}
]
})
return function_responses
JavaScript
async function getFunctionResponses(page, results) {
const screenshotBuffer = await page.screenshot({ type: 'png' });
const screenshotBase64 = screenshotBuffer.toString('base64');
const currentUrl = page.url();
const functionResponses = [];
for (const [name, callId, result] of results) {
functionResponses.push({
type: "function_result",
name: name,
call_id: callId,
result: [
{
type: "text",
text: JSON.stringify({ url: currentUrl, ...result })
},
{
type: "image",
data: screenshotBase64,
mime_type: "image/png"
}
]
});
}
return functionResponses;
}
Une fois que vous avez défini comment capturer et mettre en forme l'état de l'environnement, vous pouvez combiner toutes ces étapes dans une boucle d'exécution continue.
Créer une boucle d'agent
Pour activer les interactions en plusieurs étapes, combinez les quatre étapes de la section Implémenter l'utilisation de l'ordinateur en une seule boucle. Cette boucle continue de demander des actions et de renvoyer les résultats au modèle jusqu'à ce que la tâche soit terminée.
N'oubliez pas de gérer correctement l'historique des conversations en ajoutant les réponses du modèle et les réponses de vos fonctions à l'historique à chaque étape.
Python
import time
from typing import Any, List, Tuple
from playwright.sync_api import sync_playwright
from google import genai
client = genai.Client()
# Constants for screen dimensions
SCREEN_WIDTH = 1440
SCREEN_HEIGHT = 900
# Setup Playwright
print("Initializing browser...")
playwright = sync_playwright().start()
browser = playwright.chromium.launch(headless=False)
context = browser.new_context(viewport={"width": SCREEN_WIDTH, "height": SCREEN_HEIGHT})
page = context.new_page()
# Define helper functions. Copy/paste from steps 3 and 4
# def denormalize_x(...)
# def denormalize_y(...)
# def execute_function_calls(...)
# def get_function_responses(...)
try:
# Go to initial page
page.goto("https://ai.google.dev/gemini-api/docs")
# Take initial screenshot
initial_screenshot = page.screenshot(type="png")
USER_PROMPT = "Go to ai.google.dev/gemini-api/docs and search for pricing."
print(f"Goal: {USER_PROMPT}")
# First interaction
interaction = client.interactions.create(
model='gemini-3.5-flash',
input=[
{"type": "text", "text": USER_PROMPT},
{"type": "image", "data": base64.b64encode(initial_screenshot).decode("utf-8"), "mime_type": "image/png"}
],
tools=[{
"type": "computer_use",
"environment": "browser",
"enable_prompt_injection_detection": True
}]
)
# Agent Loop
turn_limit = 5
for i in range(turn_limit):
print(f"\n--- Turn {i+1} ---")
has_function_calls = any(
step.type == "function_call"
for step in interaction.steps
)
if not has_function_calls:
text_response = " ".join([
content_block.text for step in interaction.steps if step.type == "model_output"
for content_block in step.content if content_block.type == "text"
])
print("Agent finished:", text_response)
break
print("Executing actions...")
results = execute_function_calls(interaction, page, SCREEN_WIDTH, SCREEN_HEIGHT)
print("Capturing state...")
function_responses = get_function_responses(page, results)
# Continue conversation with function responses
interaction = client.interactions.create(
model='gemini-3.5-flash',
previous_interaction_id=interaction.id,
input=function_responses,
tools=[{
"type": "computer_use",
"environment": "browser",
"enable_prompt_injection_detection": True
}]
)
finally:
# Cleanup
print("\nClosing browser...")
browser.close()
playwright.stop()
JavaScript
import { chromium } from 'playwright';
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI();
// Constants for screen dimensions
const SCREEN_WIDTH = 1440;
const SCREEN_HEIGHT = 900;
console.log("Initializing browser...");
const browser = await chromium.launch({ headless: false });
const context = await browser.newContext({
viewport: { width: SCREEN_WIDTH, height: SCREEN_HEIGHT }
});
const page = await context.newPage();
// Define helper functions. Copy/paste from steps 3 and 4:
// function denormalizeX(...)
// function denormalizeY(...)
// async function executeFunctionCalls(...)
// async function getFunctionResponses(...)
try {
// Go to initial page
await page.goto("https://ai.google.dev/gemini-api/docs");
// Take initial screenshot
const initialScreenshotBuffer = await page.screenshot({ type: 'png' });
const initialScreenshotBase64 = initialScreenshotBuffer.toString('base64');
const USER_PROMPT = "Go to ai.google.dev/gemini-api/docs and search for pricing.";
console.log(`Goal: ${USER_PROMPT}`);
// First interaction
let interaction = await ai.interactions.create({
model: 'gemini-3.5-flash',
input: [
{ type: 'text', text: USER_PROMPT },
{ type: 'image', data: initialScreenshotBase64, mime_type: 'image/png' }
],
tools: [{
type: 'computer_use',
environment: 'browser',
enable_prompt_injection_detection: true
}]
});
// Agent Loop
const turnLimit = 5;
for (let i = 0; i < turnLimit; i++) {
console.log(`\n--- Turn ${i + 1} ---`);
const hasFunctionCalls = interaction.steps.some(step => step.type === "function_call");
if (!hasFunctionCalls) {
const textResponses = [];
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content || []) {
if (contentBlock.type === "text") {
textResponses.push(contentBlock.text);
}
}
}
}
console.log("Agent finished:", textResponses.join(" "));
break;
}
console.log("Executing actions...");
const results = await executeFunctionCalls(interaction, page, SCREEN_WIDTH, SCREEN_HEIGHT);
console.log("Capturing state...");
const functionResponses = await getFunctionResponses(page, results);
// Continue conversation with function responses
interaction = await ai.interactions.create({
model: 'gemini-3.5-flash',
previous_interaction_id: interaction.id,
input: functionResponses,
tools: [{
type: 'computer_use',
environment: 'browser',
enable_prompt_injection_detection: true
}]
});
}
} finally {
// Cleanup
console.log("\nClosing browser...");
await browser.close();
}
Environnements compatibles (Gemini 3.5 Flash)
Gemini 3.5 Flash est compatible avec trois environnements spécifiés dans les configurations computer_use :
Environnement de navigateur (ENVIRONMENT_BROWSER)
Actions disponibles dans l'outil de navigateur :
| Nom de la commande | Description | Arguments (dans l'appel de fonction) |
|---|---|---|
| click | Clic gauche aux coordonnées. | y : int (0-999)x : int (0-999)intent : str |
| double_click | Double-cliquez sur la coordonnée. | y : int (0-999)x : int (0-999)intent : str |
| triple_click | Effectue un triple clic aux coordonnées. | y : int (0-999)x : int (0-999)intent : str |
| middle_click | Effectuez un clic du milieu sur les coordonnées. | y : int (0-999)x : int (0-999)intent : str |
| right_click | Clics droits aux coordonnées. | y : int (0-999)x : int (0-999)intent : str |
| mouse_down | Appuie de manière prolongée sur le bouton de la souris aux coordonnées indiquées. | y : int (0-999)x : int (0-999)intent : str |
| mouse_up | Relâche le bouton de la souris aux coordonnées. | y : int (0-999)x : int (0-999)intent : str |
| move | Déplace le curseur à la position spécifiée. | y : int (0-999)x : int (0-999)intent : str |
| type | Saisit du texte. | text : strpress_enter : bool (facultatif, valeur par défaut : false)intent : str |
| drag_and_drop | Fait glisser un élément de la coordonnée de début à la coordonnée de fin. | start_y : int (0-999)start_x : int (0-999)end_y : int (0-999)end_x : int (0-999)intent : str |
| wait | Met en pause l'exécution pendant un nombre de secondes spécifié. | seconds : int (facultatif, 1 par défaut)intent : str |
| press_key | Appuie sur la touche spécifiée et la relâche. | key : strintent : str |
| key_down | Appuie sur la touche spécifiée et la maintient enfoncée. | key : strintent : str |
| key_up | Libère la clé spécifiée. | key : strintent : str |
| Touche d'accès | Appuie sur la combinaison de touches spécifiée. | keys : List[str]intent : str |
| take_screenshot | Renvoie une capture d'écran de l'écran actuel. | intent : str |
| scroll | Fait défiler l'écran vers le haut, le bas, la gauche ou la droite d'une distance en pixels à une coordonnée. | y : int (0-999)x : int (0-999)direction : str ("up", "down", "left", "right")magnitude_in_pixels : int (0-999, facultatif, valeur par défaut : 300)intent : str |
| go_back | Revenez à la page Web précédente de l'historique du navigateur. | intent : str |
| navigate | Accède directement à une URL spécifiée. | url : strintent : str |
| go_forward | Accède à la page Web suivante dans l'historique du navigateur. | intent : str |
Environnement mobile (ENVIRONMENT_MOBILE)
Actions de l'environnement optimisé pour Android :
| Nom de la commande | Description | Arguments (dans l'appel de fonction) |
|---|---|---|
| open_app | Ouvre une application par son nom. | app_name : strintent : str |
| click | Clic gauche aux coordonnées. | y : int (0-999)x : int (0-999)intent : str |
| list_apps | Liste les applications disponibles sur l'appareil, en renvoyant leurs noms et noms de packages. | intent : str |
| wait | Met en pause l'exécution pendant un nombre de secondes spécifié. | seconds : int (facultatif, 1 par défaut)intent : str |
| go_back | Retourne à l'écran ou à la page Web précédents. | intent : str |
| type | Saisit du texte. | text : strpress_enter : bool (facultatif, valeur par défaut : false)intent : str |
| drag_and_drop | Fait glisser un élément de la coordonnée de début à la coordonnée de fin. | start_y : int (0-999)start_x : int (0-999)end_y : int (0-999)end_x : int (0-999)intent : str |
| long_press | Effectue un appui prolongé à une coordonnée sur l'écran. | y : int (0-999)x : int (0-999)seconds : int (facultatif, valeur par défaut : 2)intent : str |
| press_key | Appuie sur la touche spécifiée et la relâche. | key : strintent : str |
| take_screenshot | Renvoie une capture d'écran de l'écran actuel. | intent : str |
Environnement de bureau (ENVIRONMENT_DESKTOP)
Commandes de curseur au niveau de l'OS pour les environnements de bureau :
| Nom de la commande | Description | Arguments (dans l'appel de fonction) |
|---|---|---|
| click | Clic gauche aux coordonnées. | y : int (0-999)x : int (0-999)intent : str |
| double_click | Double-cliquez sur la coordonnée. | y : int (0-999)x : int (0-999)intent : str |
| triple_click | Effectue un triple clic aux coordonnées. | y : int (0-999)x : int (0-999)intent : str |
| middle_click | Effectuez un clic du milieu sur les coordonnées. | y : int (0-999)x : int (0-999)intent : str |
| right_click | Clics droits aux coordonnées. | y : int (0-999)x : int (0-999)intent : str |
| mouse_down | Appuie de manière prolongée sur le bouton de la souris aux coordonnées indiquées. | y : int (0-999)x : int (0-999)intent : str |
| mouse_up | Relâche le bouton de la souris aux coordonnées. | y : int (0-999)x : int (0-999)intent : str |
| move | Déplace le curseur à la position spécifiée. | y : int (0-999)x : int (0-999)intent : str |
| type | Saisit du texte. | text : strpress_enter : bool (facultatif, valeur par défaut : false)intent : str |
| drag_and_drop | Fait glisser un élément de la coordonnée de début à la coordonnée de fin. | start_y : int (0-999)start_x : int (0-999)end_y : int (0-999)end_x : int (0-999)intent : str |
| wait | Met en pause l'exécution pendant un nombre de secondes spécifié. | seconds : int (facultatif, 1 par défaut)intent : str |
| press_key | Appuie sur la touche spécifiée et la relâche. | key : strintent : str |
| key_down | Appuie sur la touche spécifiée et la maintient enfoncée. | key : strintent : str |
| key_up | Libère la clé spécifiée. | key : strintent : str |
| Touche d'accès | Appuie sur la combinaison de touches spécifiée. | keys : List[str]intent : str |
| take_screenshot | Renvoie une capture d'écran de l'écran actuel. | intent : str |
| scroll | Fait défiler l'écran vers le haut, le bas, la gauche ou la droite d'une distance en pixels à une coordonnée. | y : int (0-999)x : int (0-999)direction : str ("up", "down", "left", "right")magnitude_in_pixels : int (0-999, facultatif, valeur par défaut : 300)intent : str |
Anciennes actions d'interface utilisateur compatibles (Gemini 2.5)
Pour les anciens modèles (gemini-2.5-computer-use-preview-10-2025), les actions suivantes sont acceptées :
| Nom de la commande | Description | Arguments (dans l'appel de fonction) | Exemple d'appel de fonction |
|---|---|---|---|
| open_web_browser | Ouvre le navigateur Web. | Aucun | {"name": "open_web_browser", "arguments": {}} |
| wait_5_seconds | Met l'exécution en pause pendant cinq secondes. | Aucun | {"name": "wait_5_seconds", "arguments": {}} |
| go_back | Accède à la page précédente de l'historique. | Aucun | {"name": "go_back", "arguments": {}} |
| go_forward | Accède à la page suivante de l'historique. | Aucun | {"name": "go_forward", "arguments": {}} |
| search | Accède au moteur de recherche par défaut. | Aucun | {"name": "search", "arguments": {}} |
| navigate | Le navigateur accède directement à l'URL spécifiée. | url : str |
{"name": "navigate", "arguments": {"url": "https://www.wikipedia.org"}} |
| click_at | Clics à une coordonnée spécifique. | y : int (0-999), x : int (0-999) |
{"name": "click_at", "arguments": {"y": 300, "x": 500}} |
| hover_at | Pointez sur une coordonnée spécifique. | y : int (0-999), x : int (0-999) |
{"name": "hover_at", "arguments": {"y": 150, "x": 250}} |
| type_text_at | Saisit du texte à une coordonnée. | y : int (0-999), x : int (0-999), text : str, press_enter : bool (facultatif, True par défaut), clear_before_typing : bool (facultatif, True par défaut) |
{"name": "type_text_at", "arguments": {"y": 250, "x": 400, "text": "search", "press_enter": false}} |
| key_combination | Appuyez sur des touches ou des combinaisons de touches. | keys : str |
{"name": "key_combination", "arguments": {"keys": "Control+A"}} |
| scroll_document | Fait défiler l'intégralité de la page Web. | direction : str |
{"name": "scroll_document", "arguments": {"direction": "down"}} |
| scroll_at | Fait défiler la page aux coordonnées (x,y). | y : int, x : int, direction : str, magnitude : int (facultatif, valeur par défaut : 800) |
{"name": "scroll_at", "arguments": {"y": 500, "x": 500, "direction": "down"}} |
| drag_and_drop | Fait glisser l'écran entre deux coordonnées. | y : int, x : int, destination_y : int, destination_x : int |
{"name": "drag_and_drop", "arguments": {"y": 100, "destination_y": 500, "destination_x": 500, "x": 100}} |
Fonctions définies par l'utilisateur personnalisées
Vous pouvez étendre les fonctionnalités du modèle en incluant des fonctions personnalisées définies par l'utilisateur. Par exemple, dans les scénarios human-in-the-loop (HITL), vous pouvez exclure les actions prédéfinies par défaut et enregistrer des actions personnalisées.
Outils personnalisés Gemini 3.5 Flash
Python
Excluez les actions de navigateur prédéfinies standards (telles que click) et enregistrez un outil yield_to_user personnalisé :
from google import genai
client = genai.Client()
yield_to_user_tool = {
"type": "function",
"name": "yield_to_user",
"description": "Yields control back to the user for assistance or verification when an automated action is unsafe or ambiguous.",
"parameters": {
"type": "object",
"properties": {
"reason": {
"type": "string",
"description": "The reason why the agent is yielding control to the human."
}
},
"required": ["reason"]
}
}
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Click the submit button. If you need a second factor authentication code, ask me.",
tools=[
{
"type": "computer_use",
"environment": "mobile",
"excluded_predefined_functions": ["click"]
},
yield_to_user_tool
]
)
JavaScript
Excluez les actions de navigateur prédéfinies standards (telles que click) et enregistrez un outil yield_to_user personnalisé :
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI();
const yieldToUserTool = {
type: "function",
name: "yield_to_user",
description: "Yields control back to the user for assistance or verification when an automated action is unsafe or ambiguous.",
parameters: {
type: "object",
properties: {
reason: {
type: "string",
description: "The reason why the agent is yielding control to the human."
}
},
required: ["reason"]
}
};
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Click the submit button. If you need a second factor authentication code, ask me.",
tools: [
{
type: "computer_use",
environment: "mobile",
excluded_predefined_functions: ["click"]
},
yieldToUserTool
]
});
Outils personnalisés Gemini 2.5 (ancienne version)
Python
from google import genai
client = genai.Client()
# Define custom tools here
custom_functions = [...] # Describe parameters as function declarations
excluded_functions = [
"open_web_browser",
"wait_5_seconds",
"go_back",
"go_forward",
"search",
"navigate",
"hover_at",
"scroll_document",
"key_combination",
"drag_and_drop",
]
interaction = client.interactions.create(
model='gemini-2.5-computer-use-preview-10-2025',
input="Open Chrome, then long-press at 200,400.",
tools=[
{
"type": "computer_use",
"environment": "browser",
"excluded_predefined_functions": excluded_functions
},
*custom_functions
]
)
print(interaction)
JavaScript
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI();
// Define custom tools here
const customFunctions = [...]; // Describe parameters as function declarations
const excludedFunctions = [
"open_web_browser",
"wait_5_seconds",
"go_back",
"go_forward",
"search",
"navigate",
"hover_at",
"scroll_document",
"key_combination",
"drag_and_drop",
];
const interaction = await ai.interactions.create({
model: 'gemini-2.5-computer-use-preview-10-2025',
input: "Open Chrome, then long-press at 200,400.",
tools: [
{
type: "computer_use",
environment: "browser",
excluded_predefined_functions: excludedFunctions
},
...customFunctions
]
});
console.log(interaction);
Gérer les niveaux de réflexion (Gemini 3.5 Flash)
Pour les agents d'utilisation de l'ordinateur, vous pouvez configurer différents niveaux de réflexion pour équilibrer la qualité de l'action et la vitesse d'exécution. Les niveaux de réflexion inférieurs permettent généralement d'atteindre un bon équilibre pour les tâches d'automatisation standards.
Protection et sécurité
Configurer des règles de sécurité (Gemini 3.5 Flash)
Le modèle Gemini 3.5 Flash inclut des catégories de services de sécurité intégrées qui déterminent automatiquement si une confirmation de l'utilisateur est requise.
| Catégorie de règles de sécurité | Description |
|---|---|
FINANCIAL_TRANSACTIONS |
Bloque ou déclenche une confirmation pour les actions impliquant des paiements, des paiements en magasin ou des produits réglementés. |
SENSITIVE_DATA_MODIFICATION |
Protège les dossiers de santé, financiers ou gouvernementaux contre toute modification non autorisée. |
COMMUNICATION_TOOL |
Empêche l'agent d'envoyer des e-mails, des messages de chat ou des brouillons de manière autonome. |
ACCOUNT_CREATION |
Empêche l'agent d'enregistrer de nouveaux comptes de manière autonome sur les sites Web. |
DATA_MODIFICATION |
Réglemente les modifications globales du système de fichiers, le partage de données et la suppression du stockage. |
USER_CONSENT_MANAGEMENT |
Nécessite une prise de contrôle par l'utilisateur pour les bannières de consentement aux cookies et les invites de confidentialité. |
LEGAL_TERMS_AND_AGREEMENTS |
Empêche le modèle d'accepter de manière autonome les conditions d'utilisation ou les contrats juridiquement contraignants. |
Remplacements de sécurité
Vous pouvez remplacer certaines règles en transmettant des remplacements :
Python
from google import genai
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Clean up the local folder by archiving old logs.",
tools=[
{
"type": "computer_use",
"environment": "desktop",
"safety_policy_overrides": [
{"category": "DATA_MODIFICATION"}
]
}
]
)
JavaScript
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI();
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Clean up the local folder by archiving old logs.",
tools: [
{
type: "computer_use",
environment: "desktop",
safety_policy_overrides: [
{ category: "DATA_MODIFICATION" }
]
}
]
});
Détection de l'injection de prompt (Gemini 3.5 Flash)
Mécanisme de sécurité optionnel qui analyse les pixels des captures d'écran pour détecter les instructions de prompt hostile cachées (par exemple, "Ignore les commandes précédentes") et bloque l'exécution lorsqu'elles sont détectées.
Confirmer une décision de sécurité (ancienne version de Gemini 2.5)
Pour les anciens modèles, la réponse peut inclure un paramètre safety_decision :
{
"steps": [
{
"type": "function_call",
"name": "click_at",
"arguments": {
"x": 60,
"y": 100,
"safety_decision": {
"explanation": "Must check check-box",
"decision": "require_confirmation"
}
}
}
]
}
Si safety_decision est défini sur require_confirmation, invitez l'utilisateur final. Si l'utilisateur confirme, définissez safety_acknowledgement dans function_result.
Python
def get_safety_confirmation(safety_decision):
# Prompt user
return "CONTINUE" # Or TERMINATE
# Inside execute_function_calls:
if 'safety_decision' in function_call.arguments:
decision = get_safety_confirmation(function_call.arguments['safety_decision'])
if decision == "TERMINATE":
break
extra_fr_fields["safety_acknowledgement"] = True
Bonnes pratiques concernant la sécurité
L'utilisation de l'ordinateur présente des risques uniques en termes de sécurité et d'opérations, car un modèle agissant au nom d'un utilisateur peut rencontrer du contenu non fiable à l'écran ou commettre des erreurs lors de l'exécution d'actions. Appliquez les bonnes pratiques suivantes pour protéger les données et les systèmes des utilisateurs :
Human-in-the-loop (avec intervention humaine, HITL) :
- Exigez la confirmation de l'utilisateur : lorsque la réponse de sécurité indique
require_confirmation(ou que l'ancienne décision de sécurité l'exige), demandez l'approbation de l'utilisateur. Fournissez des instructions de sécurité personnalisées : implémentez une instruction système personnalisée pour définir et appliquer vos propres limites de sécurité. Exemple :
Python
from google import genai client = genai.Client() system_instruction = """ ## **RULE 1: Seek User Confirmation (USER_CONFIRMATION)** This is your first and most important check. If the next required action falls into any of the following categories, you MUST stop immediately, and seek the user's explicit permission. **Procedure for Seeking Confirmation:** * **For Consequential Actions:** Perform all preparatory steps (e.g., navigating, filling out forms, typing a message). You will ask for confirmation **AFTER** all necessary information is entered on the screen, but **BEFORE** you perform the final, irreversible action (e.g., before clicking "Send", "Submit", "Confirm Purchase", "Share"). * **For Prohibited Actions:** If the action is strictly forbidden (e.g., accepting legal terms, solving a CAPTCHA), you must first inform the user about the required action and ask for their confirmation to proceed. **USER_CONFIRMATION Categories:** * **Consent and Agreements:** You are FORBIDDEN from accepting, selecting, or agreeing to any of the following on the user's behalf. You must ask the user to confirm before performing these actions. * Terms of Service * Privacy Policies * Cookie consent banners * End User License Agreements (EULAs) * Any other legally significant contracts or agreements. * **Robot Detection:** You MUST NEVER attempt to solve or bypass the following. You must ask the user to confirm before performing these actions. * CAPTCHAs (of any kind) * Any other anti-robot or human-verification mechanisms, even if you are capable. * **Financial Transactions:** * Completing any purchase. * Managing or moving money (e.g., transfers, payments). * Purchasing regulated goods or participating in gambling. * **Sending Communications:** * Sending emails. * Sending messages on any platform (e.g., social media, chat apps). * Posting content on social media or forums. * **Accessing or Modifying Sensitive Information:** * Health, financial, or government records (e.g., medical history, tax forms, passport status). * Revealing or modifying sensitive personal identifiers (e.g., SSN, bank account number, credit card number). * **User Data Management:** * Accessing, downloading, or saving files from the web. * Sharing or sending files/data to any third party. * Transferring user data between systems. * **Browser Data Usage:** * Accessing or managing Chrome browsing history, bookmarks, autofill data, or saved passwords. * **Security and Identity:** * Logging into any user account. * Any action that involves misrepresentation or impersonation (e.g., creating a fan account, posting as someone else). * **Insurmountable Obstacles:** If you are technically unable to interact with a user interface element or are stuck in a loop you cannot resolve, ask the user to take over. --- ## **RULE 2: Default Behavior (ACTUATE)** If an action does **NOT** fall under the conditions for `USER_CONFIRMATION`, your default behavior is to **Actuate**. **Actuation Means:** You MUST proactively perform all necessary steps to move the user's request forward. Continue to actuate until you either complete the non-consequential task or encounter a condition defined in Rule 1. * **Example 1:** If asked to send money, you will navigate to the payment portal, enter the recipient's details, and enter the amount. You will then **STOP** as per Rule 1 and ask for confirmation before clicking the final "Send" button. * **Example 2:** If asked to post a message, you will navigate to the site, open the post composition window, and write the full message. You will then **STOP** as per Rule 1 and ask for confirmation before clicking the final "Post" button. After the user has confirmed, remember to get the user's latest screen before continuing to perform actions. # Final Response Guidelines: Write final response to the user in the following cases: - User confirmation - When the task is complete or you have enough information to respond to the user """ interaction = client.interactions.create( model="gemini-3.5-flash", system_instruction=system_instruction, input="Prepare a draft but do not send.", tools=[{ "type": "computer_use", "environment": "browser" }] )JavaScript
import { GoogleGenAI } from '@google/genai'; const ai = new GoogleGenAI(); const systemInstruction = ` ## **RULE 1: Seek User Confirmation (USER_CONFIRMATION)** This is your first and most important check. If the next required action falls into any of the following categories, you MUST stop immediately, and seek the user's explicit permission. **Procedure for Seeking Confirmation:** * **For Consequential Actions:** Perform all preparatory steps (e.g., navigating, filling out forms, typing a message). You will ask for confirmation **AFTER** all necessary information is entered on the screen, but **BEFORE** you perform the final, irreversible action (e.g., before clicking "Send", "Submit", "Confirm Purchase", "Share"). * **For Prohibited Actions:** If the action is strictly forbidden (e.g., accepting legal terms, solving a CAPTCHA), you must first inform the user about the required action and ask for their confirmation to proceed. **USER_CONFIRMATION Categories:** * **Consent and Agreements:** You are FORBIDDEN from accepting, selecting, or agreeing to any of the following on the user's behalf. You must ask the user to confirm before performing these actions. * Terms of Service * Privacy Policies * Cookie consent banners * End User License Agreements (EULAs) * Any other legally significant contracts or agreements. * **Robot Detection:** You MUST NEVER attempt to solve or bypass the following. You must ask the user to confirm before performing these actions. * CAPTCHAs (of any kind) * Any other anti-robot or human-verification mechanisms, even if you are capable. * **Financial Transactions:** * Completing any purchase. * Managing or moving money (e.g., transfers, payments). * Purchasing regulated goods or participating in gambling. * **Sending Communications:** * Sending emails. * Sending messages on any platform (e.g., social media, chat apps). * Posting content on social media or forums. * **Accessing or Modifying Sensitive Information:** * Health, financial, or government records (e.g., medical history, tax forms, passport status). * Revealing or modifying sensitive personal identifiers (e.g., SSN, bank account number, credit card number). * **User Data Management:** * Accessing, downloading, or saving files from the web. * Sharing or sending files/data to any third party. * Transferring user data between systems. * **Browser Data Usage:** * Accessing or managing Chrome browsing history, bookmarks, autofill data, or saved passwords. * **Security and Identity:** * Logging into any user account. * Any action that involves misrepresentation or impersonation (e.g., creating a fan account, posting as someone else). * **Insurmountable Obstacles:** If you are technically unable to interact with a user interface element or are stuck in a loop you cannot resolve, ask the user to take over. --- ## **RULE 2: Default Behavior (ACTUATE)** If an action does **NOT** fall under the conditions for `USER_CONFIRMATION`, your default behavior is to **Actuate**. **Actuation Means:** You MUST proactively perform all necessary steps to move the user's request forward. Continue to actuate until you either complete the non-consequential task or encounter a condition defined in Rule 1. * **Example 1:** If asked to send money, you will navigate to the payment portal, enter the recipient's details, and enter the amount. You will then **STOP** as per Rule 1 and ask for confirmation before clicking the final "Send" button. * **Example 2:** If asked to post a message, you will navigate to the site, open the post composition window, and write the full message. You will then **STOP** as per Rule 1 and ask for confirmation before clicking the final "Post" button. After the user has confirmed, remember to get the user's latest screen before continuing to perform actions. # Final Response Guidelines: Write final response to the user in the following cases: - User confirmation - When the task is complete or you have enough information to respond to the user `; const interaction = await ai.interactions.create({ model: "gemini-3.5-flash", system_instruction: systemInstruction, input: "Prepare a draft but do not send.", tools: [{ type: "computer_use", environment: "browser" }] });
- Exigez la confirmation de l'utilisateur : lorsque la réponse de sécurité indique
Environnement d'exécution sécurisé : exécutez votre agent dans un environnement sécurisé de type bac à sable pour limiter son impact potentiel. Il peut s'agir d'une machine virtuelle (VM) sandboxée, d'un conteneur (par exemple, Docker) ou d'un profil de navigateur dédié avec des autorisations limitées. Consultez l'implémentation de référence GitHub pour obtenir des conseils sur la configuration du bac à sable à l'aide de Docker.
Assainissement des entrées : assainissez tout le texte généré par les utilisateurs dans les prompts pour réduire le risque d'instructions non souhaitées ou d'injection de prompts. Il s'agit d'une couche de sécurité utile, mais elle ne remplace pas un environnement d'exécution sécurisé.
Garde-fous pour le contenu : utilisez des garde-fous et des API de sécurité du contenu pour évaluer la pertinence des entrées utilisateur, des entrées et sorties d'outils, et des réponses de l'agent, ainsi que pour détecter les injections de prompt et les tentatives de jailbreak.
Listes d'autorisation et de blocage : implémentez des mécanismes de filtrage pour contrôler les sites que le modèle peut consulter et les actions qu'il peut effectuer. Une liste de blocage des sites Web interdits constitue un bon point de départ, tandis qu'une liste d'autorisation plus restrictive est encore plus sécurisée.
Observabilité et journalisation : conservez des journaux détaillés pour le débogage, l'audit et la réponse aux incidents. Votre client doit consigner les requêtes, les captures d'écran, les actions suggérées par le modèle (
function_call), les réponses de sécurité et toutes les actions finalement exécutées par le client.Gestion de l'environnement : assurez-vous que l'environnement de l'interface utilisateur graphique est cohérent. Les pop-ups, les notifications ou les modifications de mise en page inattendus peuvent dérouter le modèle. Si possible, commencez chaque nouvelle tâche à partir d'un état propre et connu.
Versions de modèle
Vous pouvez utiliser l'utilisation de l'ordinateur avec les modèles suivants :
- Gemini 3.5 Flash (
gemini-3.5-flash) : modèle recommandé pour l'utilisation sur ordinateur, avec des actions simplifiées avec des intentions, la compatibilité avec les environnements de navigateur, mobile et de bureau, des règles de sécurité configurables et la détection de l'injection d'invite. - Preview Gemini 3 Flash (
gemini-3-flash-preview) : modèle en preview compatible avec l'utilisation d'un ordinateur. - Gemini 2.5 (preview ancienne) (
gemini-2.5-computer-use-preview-10-2025) : modèle de preview ancienne optimisé pour une utilisation sur ordinateur dans un navigateur.
Étape suivante
- Testez l'utilisation de l'ordinateur dans l'environnement de démonstration Browserbase.
- Consultez l'implémentation de référence pour obtenir un exemple de code.
- Découvrez d'autres outils de l'API Gemini :