The Gemini API enables Retrieval Augmented Generation ("RAG") through the File
Search tool. File Search imports, chunks, and indexes your data to
enable fast retrieval of relevant information based on a provided prompt. This
retrieved information is then used as context for the model, allowing it to
provide more accurate and relevant answers. File search is also able to
provide multimodal capabilities with text embeddings supported by
gemini-embedding-001, and image/multimodal embedding supported by gemini-embedding-2.
File storage and embedding generation at query time is free, and you'll only pay for creating embeddings when you first index your files and the normal Gemini model input / output tokens cost. This new billing paradigm makes the File Search Tool both easier and more cost-effective to build and scale with. See pricing section for details.
Directly upload to File Search store
This example shows how to directly upload a file to the file search store:
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
file_search_store = client.file_search_stores.create(
config={
'display_name': 'your-fileSearchStore-name',
'embedding_model': 'models/gemini-embedding-2'
}
)
operation = client.file_search_stores.upload_to_file_search_store(
file='sample.txt',
file_search_store_name=file_search_store.name,
config={
'display_name' : 'display-file-name',
}
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Can you tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
if content_block.annotations:
print("\nSources:")
for annotation in content_block.annotations:
if annotation.type == "file_citation":
print(f" - {annotation.file_name}: {annotation.source}")
JavaScript
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
async function run() {
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'your-fileSearchStore-name',
embeddingModel: 'models/gemini-embedding-2'
}
});
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
}
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Can you tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
if (contentBlock.annotations) {
console.log("\nSources:");
for (const annotation of contentBlock.annotations) {
if (annotation.type === 'file_citation') {
console.log(` - ${annotation.file_name}: ${annotation.source}`);
}
}
}
}
}
}
}
}
run();
Check the API reference for uploadToFileSearchStore for more information.
Importing files
Alternatively, you can upload an existing file and import it to your file search store:
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
sample_file = client.files.upload(file='sample.txt', config={'display_name': 'display_file_name'})
file_search_store = client.file_search_stores.create(
config={
'display_name': 'your-fileSearchStore-name',
'embedding_model': 'models/gemini-embedding-2'
}
)
operation = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Can you tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
JavaScript
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
async function run() {
const sampleFile = await ai.files.upload({
file: 'sample.txt',
config: { displayName: 'file-name' }
});
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'your-fileSearchStore-name',
embeddingModel: 'models/gemini-embedding-2'
}
});
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation: operation });
}
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Can you tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
}
}
}
}
}
run();
Check the API reference for importFile for more information.
Chunking configuration
When you import a file into a File Search store, it's automatically broken down
into chunks, embedded, indexed, and uploaded to your File Search store. If you
need more control over the chunking strategy, you can specify a
chunking_config setting
to set a maximum number of tokens per chunk and maximum number of overlapping
tokens.
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
operation = client.file_search_stores.upload_to_file_search_store(
file_search_store_name=file_search_store.name,
file='sample.txt',
config={
'chunking_config': {
'white_space_config': {
'max_tokens_per_chunk': 200,
'max_overlap_tokens': 20
}
}
}
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
print("Custom chunking complete.")
JavaScript
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
chunkingConfig: {
whiteSpaceConfig: {
maxTokensPerChunk: 200,
maxOverlapTokens: 20
}
}
}
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
console.log("Custom chunking complete.");
To use your File Search store, pass it as a tool to the interactions.create
method, as shown in the Upload and Import examples.
How it works
File Search uses a technique called semantic search to find information relevant to the user prompt. Unlike standard keyword-based search, semantic search understands the meaning and context of your query.
When you import a file, it's converted into numerical representations called embeddings, which capture the semantic meaning of the uploaded content. These embeddings are stored in a specialized File Search database. When you make a query, it's also converted into an embedding. Then the system performs a File Search to find the most similar and relevant document chunks from the File Search store.
There is no Time To Live (TTL) for embeddings; they persist until manually deleted, or when the model is deprecated. Files, however, are deleted after 48 hours.
Here's a breakdown of the process for using the File Search
uploadToFileSearchStore API:
Create a File Search store: A File Search store contains the processed data from your files. It's the persistent container for the embeddings that the semantic search will operate on.
Upload a file and import into a File Search store: Simultaneously upload a file and import the results into your File Search store. This creates a temporary
Fileobject, which is a reference to your raw document. That data is then chunked, converted into File Search embeddings, and indexed. TheFileobject gets deleted after 48 hours, while the data imported into the File Search store will be stored indefinitely until you choose to delete it.Query with File Search: Finally, you use the
FileSearchtool in agenerateContentcall. In the tool configuration, you specify aFileSearchRetrievalResource, which points to theFileSearchStoreyou want to search. This tells the model to perform a semantic search on that specific File Search store to find relevant information to ground its response.
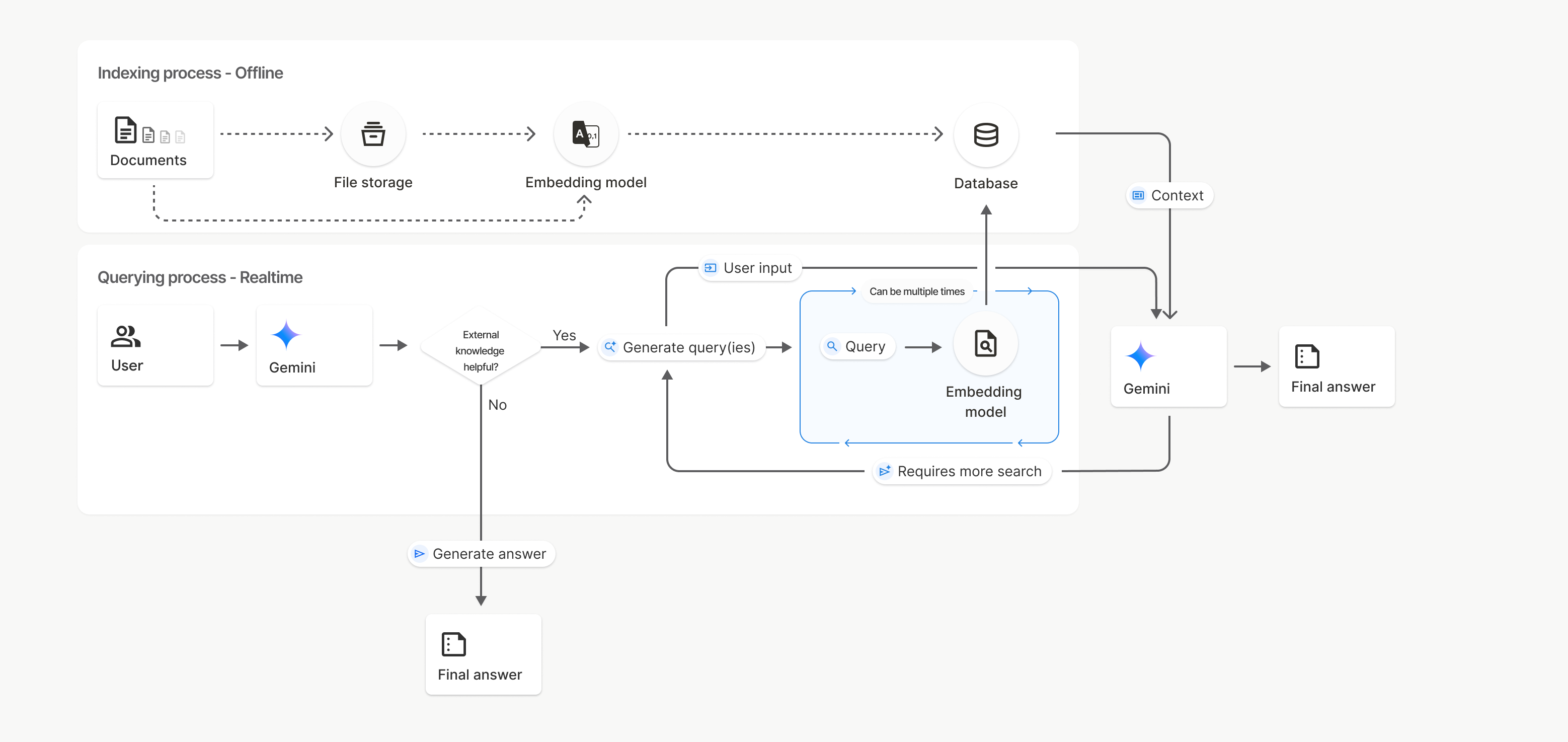
In this diagram, the dotted line from Documents to Embedding model
(using gemini-embedding-001)
represents the uploadToFileSearchStore API (bypassing File storage).
Otherwise, using the Files API to separately create
and then import files moves the indexing process from Documents to
File storage and then to Embedding model.
File Search stores
A File Search store is a container for your document embeddings. While raw files
uploaded through the File API are deleted after 48 hours, the data imported into
a File Search store is stored indefinitely until you manually delete it. You can
create multiple File Search stores to organize your documents. The
FileSearchStore API lets you create, list, get, and delete to manage your file
search stores. File Search store names are globally scoped.
Here are some examples of how to manage your File Search stores:
Python
file_search_store = client.file_search_stores.create(
config={
'display_name': 'my-file_search-store-123',
'embedding_model': 'models/gemini-embedding-2'
}
)
for file_search_store in client.file_search_stores.list():
print(file_search_store)
my_file_search_store = client.file_search_stores.get(name='fileSearchStores/my-file_search-store-123')
client.file_search_stores.delete(name='fileSearchStores/my-file_search-store-123', config={'force': True})
JavaScript
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'my-file_search-store-123',
embeddingModel: 'models/gemini-embedding-2'
}
});
const fileSearchStores = await ai.fileSearchStores.list();
for await (const store of fileSearchStores) {
console.log(store);
}
const myFileSearchStore = await ai.fileSearchStores.get({
name: 'fileSearchStores/my-file_search-store-123'
});
await ai.fileSearchStores.delete({
name: 'fileSearchStores/my-file_search-store-123',
config: { force: true }
});
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}" \
-H "Content-Type: application/json" \
-d '{ "displayName": "My Store", "embedding_model": "models/gemini-embedding-2" }'
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}" \
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123?key=${GEMINI_API_KEY}"
curl -X DELETE "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123?key=${GEMINI_API_KEY}"
File Search documents
You can manage individual documents in your file stores with the
File Search Documents API to list each document
in a file search store, get information about a document, and delete a
document by name.
Python
for document_in_store in client.file_search_stores.documents.list(parent='fileSearchStores/my-file_search-store-123'):
print(document_in_store)
file_search_document = client.file_search_stores.documents.get(name='fileSearchStores/my-file_search-store-123/documents/my_doc')
print(file_search_document)
client.file_search_stores.documents.delete(name='fileSearchStores/my-file_search-store-123/documents/my_doc', config={'force': True})
JavaScript
const documents = await ai.fileSearchStores.documents.list({
parent: 'fileSearchStores/my-file_search-store-123'
});
for await (const doc of documents) {
console.log(doc);
}
const fileSearchDocument = await ai.fileSearchStores.documents.get({
name: 'fileSearchStores/my-file_search-store-123/documents/my_doc'
});
await ai.fileSearchStores.documents.delete({
name: 'fileSearchStores/my-file_search-store-123/documents/my_doc'
});
REST
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents?key=${GEMINI_API_KEY}"
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents/my_doc?key=${GEMINI_API_KEY}"
curl -X DELETE "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents/my_doc?key=${GEMINI_API_KEY}&force=true"
File metadata
You can add custom metadata to your files to help filter them or provide additional context. Metadata is a set of key-value pairs.
Python
op = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name,
config={
'custom_metadata': [
{"key": "author", "string_value": "Robert Graves"},
{"key": "year", "numeric_value": 1934}
]
}
)
JavaScript
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name,
config: {
customMetadata: [
{ key: "author", stringValue: "Robert Graves" },
{ key: "year", numericValue: 1934 }
]
}
});
This is useful when you have multiple documents in a File Search store and want to search only a subset of them.
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Tell me about the book 'I, Claudius'",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name],
"metadata_filter": 'author="Robert Graves"',
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Tell me about the book 'I, Claudius'",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name],
metadata_filter: 'author="Robert Graves"',
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
}
}
}
}
REST
curl "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"model": "gemini-3.5-flash",
"input": [{"type": "text", "text": "Tell me about the book I, Claudius"}],
"tools": [{
"type": "file_search",
"file_search_store_names": ["'$STORE_NAME'"],
"metadata_filter": "author = \"Robert Graves\""
}]
}' 2> /dev/null > response.json
cat response.json
Guidance on implementing list filter syntax for metadata_filter can be found
at google.aip.dev/160
Multimodal File Search
Multimodal File Search lets you to natively embed and search through images, enabling rich, multimodal RAG applications.
Configure the embedding model
When you create a FileSearchStore, you must override the default text-only
embedding model to use a multimodal model. Use models/gemini-embedding-2 to
process both text and images.
Python
store = client.file_search_stores.create(
config={
"display_name": "Multimodal Catalog",
"embedding_model": "models/gemini-embedding-2",
}
)
JavaScript
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: "Multimodal Catalog",
embeddingModel: "models/gemini-embedding-2",
},
});
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=$GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"display_name": "Multimodal Catalog",
"embedding_model": "models/gemini-embedding-2"
}'
Upload images
After you create the store with a multimodal embedding model, you can upload image files directly using the same upload APIs described in Directly upload to File Search store or Importing files.
Image file requirements:
- Image files must be at most 4K x 4K pixels in resolution.
- Supported formats are PNG, JPEG.
Citations
When you use File Search, the model's response may include citations that specify which parts of your uploaded documents were used to generate the answer. This helps with fact-checking and verification.
You can access citation information through the annotations attribute inside the model_output step's content blocks of the response.
Python
for step in interaction.steps:
if step.type == 'model_output':
for content in step.content:
if content.type == 'text' and content.annotations:
print(content.annotations)
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text' && contentBlock.annotations) {
console.log(JSON.stringify(contentBlock.annotations, null, 2));
}
}
}
}
For detailed information on the structure of the citations, see the API reference for Interactions.
Page numbers
When you use File Search with documents that have pages (such as PDFs), the
model's response may include the page number where the information was found.
You can access this information through the page_number attribute of a
file_citation annotation.
Python
for step in interaction.steps:
if step.type == "model_output":
for content in step.content:
if content.type == "text" and content.annotations:
for annotation in content.annotations:
if annotation.type == "file_citation" and annotation.page_number:
print(f"Cited Page: {annotation.page_number}")
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const block of step.content) {
if (block.type === 'text' && block.annotations) {
for (const annotation of block.annotations) {
if (annotation.type === 'file_citation' && annotation.pageNumber) {
console.log(`Cited Page: ${annotation.pageNumber}`);
}
}
}
}
}
}
Media citations
When the model references an image chunk during generation, the API returns an
annotation of type file_citation in the annotations that includes a media_id. You can use this
ID to download the exact image chunk the model referenced. This media_id is
persistent across multiple search calls, which lets you reliably retrieve
the same image or cache it using the ID.
The following snippet is an example REST response step:
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"type": "file_citation",
"file_name": "product_image",
"media_id": "fileSearchStores/my-store-123/media/BlobId-456"
}
]
}
]
}
The following code snippets demonstrate how to retrieve the media_id and
download the media:
Python
for step in interaction.steps:
if step.type == "model_output":
for content in step.content:
if content.type == "text" and content.annotations:
for annotation in content.annotations:
if annotation.type == "file_citation" and annotation.media_id:
print(f"Cited Media ID: {annotation.media_id}")
blob_content = client.file_search_stores.download_media(
media_id=annotation.media_id
)
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const block of step.content) {
if (block.type === 'text' && block.annotations) {
for (const annotation of block.annotations) {
if (annotation.type === 'file_citation' && annotation.mediaId) {
console.log(`Cited Media ID: ${annotation.mediaId}`);
const blobContent = await ai.fileSearchStores.downloadMedia(annotation.mediaId);
}
}
}
}
}
}
REST
curl -X GET "https://generativelanguage.googleapis.com/v1/fileSearchStores/my-store-123/media/BlobId-456" \
-H "x-goog-api-key: $GEMINI_API_KEY"
Custom metadata
If you have added custom metadata to your files, you can access it in the
annotations of the model's response. This is useful for passing
additional context (like URLs, page numbers, or authors) from your source
documents to your application logic. Each citation annotation of type file_citation
contains this custom metadata.
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.annotations:
for annotation in content_block.annotations:
print(annotation)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.annotations) {
contentBlock.annotations.forEach((annotation) => {
console.log(annotation);
});
}
}
}
}
REST
{
"steps": [
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"file_name": "...",
"source": "...",
"custom_metadata": [
{
"key": "author",
"string_value": "Robert Graves"
},
{
"key": "year",
"numeric_value": 1934
}
]
}
]
}
]
}
]
}
Structured output
Starting with Gemini 3 models, you can combine file search tool with structured outputs.
Python
from pydantic import BaseModel, Field
class Money(BaseModel):
amount: str = Field(description="The numerical part of the amount.")
currency: str = Field(description="The currency of amount.")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="What is the minimum hourly wage in Tokyo right now?",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}],
response_format={
"type": "text",
"mime_type": "application/json",
"schema": Money.model_json_schema()
},
)
result = Money.model_validate_json(interaction.output_text)
print(result)
JavaScript
import { z } from "zod";
const moneyJsonSchema = {
type: "object",
properties: {
amount: { type: "string", description: "The numerical part of the amount." },
currency: { type: "string", description: "The currency of amount." }
},
required: ["amount", "currency"]
};
const moneySchema = z.fromJSONSchema(moneyJsonSchema);
async function run() {
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "What is the minimum hourly wage in Tokyo right now?",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name],
}],
response_format: {
type: 'text',
mime_type: 'application/json',
schema: moneyJsonSchema
},
});
const result = moneySchema.parse(JSON.parse(interaction.output_text));
console.log(result);
}
run();
REST
curl "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"model": "gemini-3.5-flash",
"input": "What is the minimum hourly wage in Tokyo right now?",
"tools": [{
"type": "file_search",
"file_search_store_names": ["$FILE_SEARCH_STORE_NAME"]
}],
"response_format": {
"type": "text",
"mime_type": "application/json",
"schema": {
"type": "object",
"properties": {
"amount": {"type": "string", "description": "The numerical part of the amount."},
"currency": {"type": "string", "description": "The currency of amount."}
},
"required": ["amount", "currency"]
}
}
}'
Supported models
The following models support File Search:
| Model | File Search |
|---|---|
| Gemini 3.5 Flash | ✔️ |
| Gemini 3.1 Pro Preview | ✔️ |
| Gemini 3.1 Flash-Lite | ✔️ |
| Gemini 3 Flash Preview | ✔️ |
| Gemini 2.5 Pro | ✔️ |
| Gemini 2.5 Flash-Lite | ✔️ |
Supported tool combinations
Gemini 3 models support combining built-in tools (like File Search) with custom tools (function calling). Learn more on the tool combinations page.
Supported file types
File Search supports a wide range of file formats, listed in the following sections.
Application file types
application/dartapplication/ecmascriptapplication/jsonapplication/ms-javaapplication/mswordapplication/pdfapplication/sqlapplication/typescriptapplication/vnd.curlapplication/vnd.dartapplication/vnd.ibm.secure-containerapplication/vnd.jupyterapplication/vnd.ms-excelapplication/vnd.oasis.opendocument.textapplication/vnd.openxmlformats-officedocument.presentationml.presentationapplication/vnd.openxmlformats-officedocument.spreadsheetml.sheetapplication/vnd.openxmlformats-officedocument.wordprocessingml.documentapplication/vnd.openxmlformats-officedocument.wordprocessingml.templateapplication/x-cshapplication/x-hwpapplication/x-hwp-v5application/x-latexapplication/x-phpapplication/x-powershellapplication/x-shapplication/x-shellscriptapplication/x-texapplication/x-zshapplication/xmlapplication/zip
Text file types
text/1d-interleaved-parityfectext/REDtext/SGMLtext/cache-manifesttext/calendartext/cqltext/cql-extensiontext/cql-identifiertext/csstext/csvtext/csv-schematext/dnstext/encaprtptext/enrichedtext/exampletext/fhirpathtext/flexfectext/fwdredtext/gff3text/grammar-ref-listtext/hl7v2text/htmltext/javascripttext/jcr-cndtext/jsxtext/markdowntext/mizartext/n3text/parameterstext/parityfectext/phptext/plaintext/provenance-notationtext/prs.fallenstein.rsttext/prs.lines.tagtext/prs.prop.logictext/raptorfectext/rfc822-headerstext/rtftext/rtp-enc-aescm128text/rtploopbacktext/rtxtext/sgmltext/shaclctext/shextext/spdxtext/stringstext/t140text/tab-separated-valuestext/texmacstext/trofftext/tsvtext/tsxtext/turtletext/ulpfectext/uri-listtext/vcardtext/vnd.DMClientScripttext/vnd.IPTC.NITFtext/vnd.IPTC.NewsMLtext/vnd.atext/vnd.abctext/vnd.ascii-arttext/vnd.curltext/vnd.debian.copyrighttext/vnd.dvb.subtitletext/vnd.esmertec.theme-descriptortext/vnd.exchangeabletext/vnd.familysearch.gedcomtext/vnd.ficlab.flttext/vnd.flytext/vnd.fmi.flexstortext/vnd.gmltext/vnd.graphviztext/vnd.hanstext/vnd.hgltext/vnd.in3d.3dmltext/vnd.in3d.spottext/vnd.latex-ztext/vnd.motorola.reflextext/vnd.ms-mediapackagetext/vnd.net2phone.commcenter.commandtext/vnd.radisys.msml-basic-layouttext/vnd.senx.warpscripttext/vnd.sositext/vnd.sun.j2me.app-descriptortext/vnd.trolltech.linguisttext/vnd.wap.sitext/vnd.wap.sltext/vnd.wap.wmltext/vnd.wap.wmlscripttext/vtttext/wgsltext/x-asmtext/x-bibtextext/x-bootext/x-ctext/x-c++hdrtext/x-c++srctext/x-cassandratext/x-chdrtext/x-coffeescripttext/x-componenttext/x-cshtext/x-csharptext/x-csrctext/x-cudatext/x-dtext/x-difftext/x-dsrctext/x-emacs-lisptext/x-erlangtext/x-gff3text/x-gotext/x-haskelltext/x-javatext/x-java-propertiestext/x-java-sourcetext/x-kotlintext/x-lilypondtext/x-lisptext/x-literate-haskelltext/x-luatext/x-moctext/x-objcsrctext/x-pascaltext/x-pcs-gcdtext/x-perltext/x-perl-scripttext/x-pythontext/x-python-scripttext/x-r-markdowntext/x-rsrctext/x-rsttext/x-ruby-scripttext/x-rusttext/x-sasstext/x-scalatext/x-schemetext/x-script.pythontext/x-scsstext/x-setexttext/x-sfvtext/x-shtext/x-siestatext/x-sostext/x-sqltext/x-swifttext/x-tcltext/x-textext/x-vbasictext/x-vcalendartext/xmltext/xml-dtdtext/xml-external-parsed-entitytext/yaml
Limitations
- Live API: File Search is not supported in the Live API.
- Tool incompatibility: File Search cannot be combined with other tools like Grounding with Google Search, URL Context, etc. at this time.
Rate limits
The File Search API has the following limits to enforce service stability:
- Maximum file size / per document limit: 100 MB
- Total size of project File Search stores (based on user tier):
- Free: 1 GB
- Tier 1: 10 GB
- Tier 2: 100 GB
- Tier 3: 1 TB
- Recommendation: Limit the size of each File Search store to under 20 GB to ensure optimal retrieval latencies.
Pricing
- You are charged for embeddings at indexing time based on existing embeddings pricing.
- Storage is free of charge.
- Query time embeddings are free of charge.
- Retrieved document tokens are charged as regular context tokens.
What's next
- Visit the API reference for File Search Stores and File Search Documents.