Imagen es el modelo de generación de imágenes de alta fidelidad de Google, capaz de generar imágenes realistas y de alta calidad a partir de instrucciones de texto. Todas las imágenes generadas incluyen una marca de agua de SynthID. Para obtener más información sobre las variantes de modelos de Imagen disponibles, consulta la sección Versiones de modelos.
Genera imágenes con los modelos de Imagen
En este ejemplo, se muestra cómo generar imágenes con un modelo de Imagen:
Python
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
response = client.models.generate_images(
model='imagen-4.0-generate-001',
prompt='Robot holding a red skateboard',
config=types.GenerateImagesConfig(
number_of_images= 4,
)
)
for generated_image in response.generated_images:
generated_image.image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const response = await ai.models.generateImages({
model: 'imagen-4.0-generate-001',
prompt: 'Robot holding a red skateboard',
config: {
numberOfImages: 4,
},
});
let idx = 1;
for (const generatedImage of response.generatedImages) {
let imgBytes = generatedImage.image.imageBytes;
const buffer = Buffer.from(imgBytes, "base64");
fs.writeFileSync(`imagen-${idx}.png`, buffer);
idx++;
}
}
main();
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateImagesConfig{
NumberOfImages: 4,
}
response, _ := client.Models.GenerateImages(
ctx,
"imagen-4.0-generate-001",
"Robot holding a red skateboard",
config,
)
for n, image := range response.GeneratedImages {
fname := fmt.Sprintf("imagen-%d.png", n)
_ = os.WriteFile(fname, image.Image.ImageBytes, 0644)
}
}
REST
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/imagen-4.0-generate-001:predict" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"instances": [
{
"prompt": "Robot holding a red skateboard"
}
],
"parameters": {
"sampleCount": 4
}
}'

Configuración de Imagen
Por el momento, Imagen solo admite instrucciones en inglés y los siguientes parámetros:
numberOfImages: Es la cantidad de imágenes que se generarán, de 1 a 4 (inclusive). El valor predeterminado es 4.imageSize: Es el tamaño de la imagen generada. Esto solo se admite en los modelos Estándar y Ultra. Los valores admitidos son1Ky2K. El valor predeterminado es1K.aspectRatio: Cambia la relación de aspecto de la imagen generada. Los valores admitidos son"1:1","3:4","4:3","9:16"y"16:9". El valor predeterminado es"1:1".personGeneration: Permite que el modelo genere imágenes de personas. Se admiten los siguientes valores:"dont_allow": Bloquea la generación de imágenes de personas."allow_adult": Genera imágenes de adultos, pero no de niños. Es el valor predeterminado."allow_all": Genera imágenes que incluyan adultos y niños.
Guía de instrucciones de Imagen
En esta sección de la guía de Imagen, se muestra cómo modificar un mensaje de texto a imagen puede producir resultados diferentes, junto con ejemplos de imágenes que puedes crear.
Conceptos básicos de la escritura de instrucciones
Una buena instrucción es descriptiva y clara, y utiliza palabras clave y modificadores significativos. Comienza por pensar en el asunto, el contexto y el estilo.

Asunto: Lo primero que debes pensar en cualquier mensaje es el asunto: el objeto, la persona, el animal o el paisaje del que deseas una imagen.
Contexto y fondo: igual de importante es el segundo plano o el contexto en el que se colocará el asunto. Intenta ubicar al asunto en diferentes fondos. Por ejemplo, un estudio con un fondo blanco, exterior o entornos interiores.
Estilo: Por último, agrega el estilo de imagen que desees. Los estilos pueden ser generales (pintura, fotografías, esbozos) o muy específicos (pintura al pastel, carbón, 3D isométrico). También puedes combinar estilos.
Después de escribir una primera versión de tu instrucción, agrega más detalles hasta que obtengas la imagen que deseas. La iteración es importante. Comienza por establecer tu idea principal y, luego, refínala y expándela hasta que la imagen generada se acerque a tu visión.

|

|

|
Los modelos de Imagen pueden transformar tus ideas en imágenes detalladas, ya sean tus instrucciones cortas o largas y detalladas. Define mejor tu visión a través de instrucciones iterativas, agregando detalles hasta lograr el resultado perfecto.
|
Las instrucciones breves te permiten generar una imagen rápidamente. 
|
Las instrucciones más largas te permiten agregar detalles específicos y crear tu imagen. 
|
Sugerencias adicionales para escribir instrucciones de Imagen:
- Usa un lenguaje descriptivo: Emplea adjetivos y adverbios detallados para pintar una imagen clara para Imagen.
- Proporciona contexto: Si es necesario, incluye información general para ayudar a la IA a comprender mejor.
- Haz referencia a artistas o estilos específicos: Si tienes una estética particular en mente, puede ser útil hacer referencia a artistas o movimientos artísticos específicos.
- Usa herramientas de ingeniería de instrucciones: Considera explorar herramientas o recursos de ingeniería de instrucciones para ayudarte a definir mejor tus instrucciones y lograr resultados óptimos.
- Mejora los detalles faciales en tus imágenes personales y grupales: Especifica los detalles faciales como el enfoque de la foto (por ejemplo, usa la palabra "retrato" en la instrucción).
Genera texto en imágenes
Los modelos de Imagen pueden agregar texto a las imágenes, lo que abre más posibilidades creativas de generación de imágenes. Sigue las siguientes instrucciones para aprovechar al máximo esta función:
- Itera con confianza: Es posible que debas volver a generar imágenes hasta lograr el aspecto que deseas. La integración de texto de Imagen aún está en desarrollo, y, a veces, varios intentos producen los mejores resultados.
- Sé breve: Limita el texto a 25 caracteres o menos para una generación óptima.
Varias frases: Experimenta con dos o tres frases distintas para proporcionar información adicional. Evita superar las tres frases para lograr composiciones más claras.

Instrucción: Un póster con el texto "Summerland" en negrita como título. Debajo de este texto, se encuentra el lema "El verano nunca se sintió tan bien". Posicionamiento de la guía: Si bien Imagen puede intentar posicionar el texto según las indicaciones, es posible que haya variaciones ocasionales. Esta función mejora continuamente.
Inspire font style: Especifica un estilo de fuente general para influir sutilmente en las elecciones de Imagen. No esperes una replicación precisa de la fuente, sino interpretaciones creativas.
Tamaño de fuente: Especifica un tamaño de fuente o una indicación general del tamaño (por ejemplo, pequeño, mediano, grande) para influir en la generación del tamaño de fuente.
Parametrización de instrucciones
Para controlar mejor los resultados, puede ser útil parametrizar las entradas en Imagen. Por ejemplo, supongamos que quieres que tus clientes puedan generar logotipos para su empresa y quieres asegurarte de que los logotipos siempre se generen sobre un fondo de color sólido. También puedes limitar las opciones que el cliente puede seleccionar en un menú.
En este ejemplo, puedes crear una instrucción parametrizada similar a la siguiente:
A {logo_style} logo for a {company_area} company on a solid color background. Include the text {company_name}.En tu interfaz de usuario personalizada, el cliente puede ingresar los parámetros a través de un menú, y el valor que elija completará la instrucción que recibe Imagen.
Por ejemplo:
Instrucción:
A minimalist logo for a health care company on a solid color background. Include the text Journey.
Instrucción:
A modern logo for a software company on a solid color background. Include the text Silo.
Instrucción:
A traditional logo for a baking company on a solid color background. Include the text Seed.
Técnicas avanzadas de escritura de mensajes
Usa los siguientes ejemplos para crear mensajes más específicos basados en atributos como descriptores de fotografía, formas y materiales, movimientos históricos de arte y modificadores de calidad de imagen.
Fotografía
- El mensaje contiene: "Una foto de…"
Para usar este estilo, comienza por usar palabras clave que indiquen con claridad a Imagen que buscas una fotografía. Comienza el mensaje con “Una foto de. . ". Por ejemplo:

|

|

|
Fuente de la imagen: Cada imagen se generó con su mensaje de texto correspondiente con el modelo de Imagen 4.
Modificadores de fotografía
En los siguientes ejemplos, puedes ver varios modificadores y parámetros específicos de la fotografía. Puedes combinar varios modificadores para obtener un control más preciso.
Proximidad de la cámara: Acercamiento, tomado desde lejos

Mensaje: Una foto en primer plano de granos de café 
Mensaje: Una foto con alejamiento de una bolsa pequeña de
granos de café en una cocina desordenadaPosición de la cámara: aérea, desde abajo

Instrucción: Foto aérea de una ciudad urbana con edificios 
Mensaje: Una foto de un dosel arbóreo con cielo azul desde abajo Iluminación: natural, drástica, cálida, fría

Mensaje: Foto de estudio de una silla moderna, iluminación natural 
Mensaje: Foto de estudio de una silla moderna, iluminación dramática Configuración de la cámara - desenfoque de movimiento, enfoque suave, bokeh, vertical

Instrucción: Foto de una ciudad con edificios desde el interior de un automóvil con desenfoque de movimiento 
Instrucción: Foto con enfoque suave de un puente en una ciudad urbana por la noche Tipos de lentes: 35 mm, 50 mm, ojo de pez, gran angular, macro

Mensaje: Foto de una hoja, lente macro 
Mensaje: fotografía de una calle, ciudad de Nueva York, lente de ojo de pez Tipos de película: blanco y negro, polaroid

Instrucción: Un retrato polaroid de un perro con lentes de sol 
Mensaje: Foto en blanco y negro de un perro que usa lentes de sol
Fuente de la imagen: Cada imagen se generó con su mensaje de texto correspondiente con el modelo de Imagen 4.
Ilustración y arte
- El mensaje incluye: “Un painting de…” “Un sketch de…”
Los estilos de arte varían desde estilos monocromáticos como esbozos de lápiz hasta arte digital hiperrealista. Por ejemplo, las siguientes imágenes usan el mismo mensaje con diferentes estilos:
“Un [art style or creation technique] de un sedán eléctrico deportivo angular con rascacielos en el fondo”

|

|

|

|

|

|
Fuente de la imagen: Cada imagen se generó con su instrucción de texto correspondiente con el modelo Imagen 2.
Formas y materiales
- El mensaje incluye: “…hecho de…”, “…en forma de…”
Una de las fortalezas de esta tecnología es que puedes crear imágenes que, de otro modo, serían difíciles o imposibles. Por ejemplo, puedes recrear el logotipo de tu empresa en diferentes materiales y texturas.

|

|

|
Fuente de la imagen: Cada imagen se generó con su mensaje de texto correspondiente con el modelo de Imagen 4.
Referencias al arte histórico
- El mensaje incluye: "…en el estilo de…"
Algunos estilos se han convertido en íconos con el tiempo. A continuación, se presentan algunas ideas de estilos históricos de pintura o arte que puedes probar.
“Genera una imagen al estilo de [art period or movement] : una granja eólica”

|

|

|
Fuente de la imagen: Cada imagen se generó con su mensaje de texto correspondiente con el modelo de Imagen 4.
Modificadores de calidad de la imagen
Ciertas palabras clave pueden informarle al modelo que buscas un recurso de alta calidad. Algunos ejemplos de modificadores de calidad son los siguientes:
- Modificadores generales: Alta calidad, hermosa, estilizado
- Fotos: 4K, HDR, foto de estudio
- Ilustración y arte: de un profesional, detallada
A continuación, se muestran algunos ejemplos de mensajes sin modificadores de calidad y el mismo mensaje con modificadores de calidad.

|

de un tallo de maíz tomada por un fotógrafo profesional |
Fuente de la imagen: Cada imagen se generó con su mensaje de texto correspondiente con el modelo de Imagen 4.
Relaciones de aspecto
La generación de imágenes de Imagen te permite establecer cinco relaciones de aspecto de imagen distintas.
- Cuadrada (1:1, predeterminada): es una foto cuadrada estándar. Los usos comunes de esta relación de aspecto incluyen las publicaciones en redes sociales.
Pantalla completa (4:3): esta relación de aspecto se suele usar en el contenido multimedia o las películas. También tienen las dimensiones de la mayoría de las TVs antiguas (no de pantalla ancha) y las cámaras de formato medio. Captura una mayor parte de la escena horizontal (en comparación con una imagen 1:1), por lo que se trata de una relación de aspecto preferida para la fotografía.

Mensaje: primer plano de los dedos de un músico tocando el piano, una película en blanco y negro, vintage (relación de aspecto de 4:3) 
Mensaje: Una foto de estudio profesional de papas fritas para un restaurante de alta gama, al estilo de una revista gastronómica (relación de aspecto de 4:3) Pantalla completa vertical (3:4): esta es la relación de aspecto de la pantalla completa rotada 90 grados. Esto permite capturar más imágenes de la escena de manera vertical en comparación con la relación de aspecto de 1:1.

Mensaje: una mujer haciendo senderismo, cerca de sus botas reflejadas en un charco, grandes montañas en el fondo, al estilo de un anuncio, ángulos drásticos (relación de aspecto de 3:4) 
Mensaje: Toma aérea de un río que fluye por un valle místico (relación de aspecto de 3:4) Pantalla ancha (16:9): esta proporción reemplazó a 4:3 y ahora es la relación de aspecto más común para TVs, monitores y pantallas de teléfonos celulares (horizontal). Usa esta relación de aspecto cuando quieras capturar más del fondo (por ejemplo, paisajes panorámicos).

Mensaje: Un hombre con ropa blanca sentado en la playa, en primer plano, con la iluminación de la hora dorada (relación de aspecto de 16:9) Vertical (9:16): esta proporción es para la pantalla ancha, pero rotada. Esta es una relación de aspecto relativamente nueva que se popularizó en las apps de video de formato corto (por ejemplo, YouTube Shorts). Úsala para objetos altos con orientaciones verticales sólidas, como edificios, árboles, cascadas y otros objetos similares.

Mensaje: una renderización digital de un rascacielos enorme, moderno, grande, épico con una hermosa puesta de sol en el fondo (relación de aspecto de 9:16)
Imágenes fotorrealistas
Diferentes versiones del modelo de generación de imágenes pueden ofrecer una combinación de resultados artísticos y fotorrealistas. Usa las siguientes palabras en los mensajes para generar un resultado más fotorrealista, según el asunto que quieras generar.
| Caso de uso | Tipo de lente | Longitudes focales | Detalles adicionales |
|---|---|---|---|
| Personas (retratos) | Prime, zoom | De 24 a 35 mm | película en blanco y negro, película noir, profundidad de campo, doble tono (mencionar dos colores) |
| Alimentos, insectos, plantas (objetos, naturaleza muerta) | Macro | De 60 a105 mm | Iluminación controlada, enfoque preciso y de gran detalle |
| Deportes y fauna (movimiento) | Acercar el teleobjetivo | De 100 a 400 mm | Velocidad rápida del obturador, acción o seguimiento de movimiento |
| Astrómico, horizontal (gran angular) | Gran angular | De 10 a 24 mm | Tiempos de exposición largos, enfoque nítido, exposición larga, agua o nubes fluidas |
Retrato
| Caso de uso | Tipo de lente | Longitudes focales | Detalles adicionales |
|---|---|---|---|
| Personas (retratos) | Prime, zoom | De 24 a 35 mm | película en blanco y negro, película noir, profundidad de campo, doble tono (mencionar dos colores) |
Con varias palabras clave de la tabla, Imagen puede generar los siguientes retratos:

|

|

|

|
Mensaje: Una mujer, retrato de 35 mm, tonos duales azules y grises
Modelo: imagen-4.0-generate-001

|

|

|

|
Mensaje: Una mujer, retrato de 35 mm, modelo de cine
Modelo: imagen-4.0-generate-001
Objetos
| Caso de uso | Tipo de lente | Longitudes focales | Detalles adicionales |
|---|---|---|---|
| Alimentos, insectos, plantas (objetos, naturaleza muerta) | Macro | De 60 a105 mm | Iluminación controlada, enfoque preciso y de gran detalle |
Con varias palabras clave de la tabla, Imagen puede generar las siguientes imágenes de objeto:

|

|

|

|
Mensaje: hoja de una planta de oración, lente macro, 60 mm
Modelo: imagen-4.0-generate-001

|

|

|

|
Mensaje: un plato de pasta, 100 mm con lente macro
Modelo: imagen-4.0-generate-001
Movimiento
| Caso de uso | Tipo de lente | Longitudes focales | Detalles adicionales |
|---|---|---|---|
| Deportes y fauna (movimiento) | Acercar el teleobjetivo | De 100 a 400 mm | Velocidad rápida del obturador, acción o seguimiento de movimiento |
Con varias palabras clave de la tabla, Imagen puede generar las siguientes imágenes en movimiento:

|

|
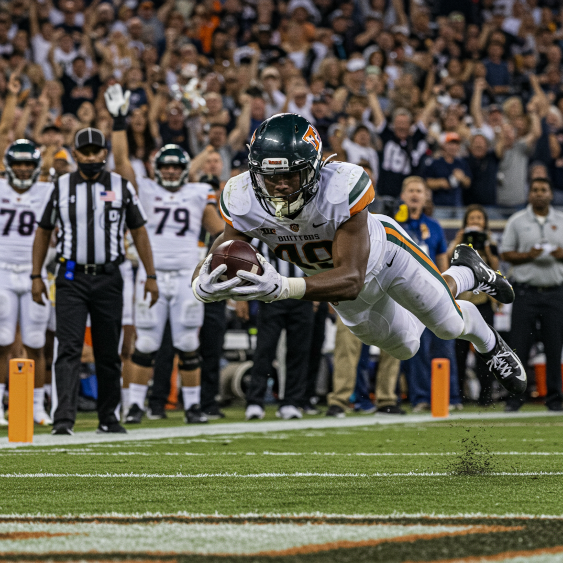
|

|
Mensaje: una anotación ganadora, velocidad de obturador rápida y seguimiento del movimiento
Modelo: imagen-4.0-generate-001

|

|

|

|
Mensaje: Un ciervo corriendo en el bosque, velocidad rápida del obturador, seguimiento del movimiento
Modelo: imagen-4.0-generate-001
Gran angular
| Caso de uso | Tipo de lente | Longitudes focales | Detalles adicionales |
|---|---|---|---|
| Astrómico, horizontal (gran angular) | Gran angular | De 10 a 24 mm | Tiempos de exposición largos, enfoque nítido, exposición larga, agua o nubes fluidas |
Con varias palabras clave de la tabla, Imagen puede generar las siguientes imágenes con gran angular:

|

|

|

|
Mensaje: una porción extensa de montaña, gran angular horizontal de 10 mm
Modelo: imagen-4.0-generate-001

|

|

|

|
Mensaje: una foto de la luna, fotografía astronómica, gran angular de 10 mm
Modelo: imagen-4.0-generate-001
Versiones del modelo
Imagen 4
| Propiedad | Descripción |
|---|---|
| Código del modelo |
API de Gemini
|
| Tipos de datos admitidos |
Entrada Texto Resultado Imágenes |
| Límites de tokens[*] |
Límite de tokens de entrada 480 tokens (texto) Imágenes de salida De 1 a 4 (Ultra/Estándar/Rápido) |
| Última actualización | Junio de 2025 |
Imagen 3
Se cerró el modelo de Imagen 3.