Gemini dapat menangani berbagai jenis data input, termasuk teks, gambar, dan audio, secara bersamaan.
Panduan ini menunjukkan cara menggunakan file media menggunakan Files API. Operasi dasar sama untuk file audio, gambar, video, dokumen, dan jenis file lain yang didukung.
Untuk panduan perintah file, lihat bagian Panduan perintah file.
Upload file
Anda dapat menggunakan Files API untuk mengupload file media. Selalu gunakan Files API jika total ukuran permintaan (termasuk file, perintah teks, petunjuk sistem, dll.) lebih besar dari 100 MB. Untuk file PDF, batasnya adalah 50 MB.
Kode berikut mengupload file, lalu menggunakan file tersebut dalam panggilan ke
interactions.create.
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file="path/to/sample.mp3")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Describe this audio clip"},
{"type": "audio", "uri": myfile.uri, "mime_type": myfile.mime_type}
]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
async function main() {
const myfile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mime_type: "audio/mpeg" },
});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{ type: "text", text: "Describe this audio clip" },
{ type: "audio", uri: myfile.uri, mime_type: myfile.mimeType }
]
});
console.log(interaction.output_text);
}
await main();
Go
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
defer client.Files.Delete(ctx, file.Name)
interaction, err := client.Interactions.Create(ctx, "gemini-3.5-flash", &genai.InteractionRequest{
Input: []interface{}{
genai.NewPartFromFile(*file),
genai.NewPartFromText("Describe this audio clip"),
},
}, nil)
if err != nil {
log.Fatal(err)
}
// Print the model's text response
for _, step := range interaction.Steps {
if step.Type == "model_output" {
for _, part := range step.Content {
if part.Type == "text" {
fmt.Println(part.Text)
}
}
}
}
REST
AUDIO_PATH="path/to/sample.mp3"
MIME_TYPE=$(file -b --mime-type "${AUDIO_PATH}")
NUM_BYTES=$(wc -c < "${AUDIO_PATH}")
DISPLAY_NAME=AUDIO
tmp_header_file=upload-header.tmp
# Initial resumable request defining metadata.
# The upload url is in the response headers dump them to a file.
curl "${BASE_URL}/upload/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-D "${tmp_header_file}" \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Header-Content-Type: ${MIME_TYPE}" \
-H "Content-Type: application/json" \
-d "{'file': {'display_name': '${DISPLAY_NAME}'}}" 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " "${tmp_header_file}" | cut -d" " -f2 | tr -d "\r")
rm "${tmp_header_file}"
# Upload the actual bytes.
curl "${upload_url}" \
-H "Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@${AUDIO_PATH}" 2> /dev/null > file_info.json
file_uri=$(jq ".file.uri" file_info.json)
echo file_uri=$file_uri
# Now create an interaction using the Interactions API
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{"type": "text", "text": "Describe this audio clip"},
{"type": "audio", "uri": '$file_uri', "mime_type": "'${MIME_TYPE}'"}
]
}' 2> /dev/null > response.json
cat response.json
echo
jq ".outputs[] | select(.type == \"text\") | .text" response.json
Mendapatkan metadata untuk file
Anda dapat memverifikasi bahwa API berhasil menyimpan file yang diupload dan mendapatkan
metadatanya dengan memanggil files.get.
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file='path/to/sample.mp3')
file_name = myfile.name
myfile = client.files.get(name=file_name)
print(myfile)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const client = new GoogleGenAI({});
async function main() {
const myfile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mime_type: "audio/mpeg" },
});
const fileName = myfile.name;
const fetchedFile = await client.files.get({ name: fileName });
console.log(fetchedFile);
}
await main();
Go
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
gotFile, err := client.Files.Get(ctx, file.Name)
if err != nil {
log.Fatal(err)
}
fmt.Println("Got file:", gotFile.Name)
REST
# file_info.json was created in the upload example
name=$(jq -r ".file.name" file_info.json)
# Get the file of interest to check state
curl https://generativelanguage.googleapis.com/v1beta/$name \
-H "x-goog-api-key: $GEMINI_API_KEY" > file_info.json
# Print some information about the file you got
name=$(jq -r ".name" file_info.json)
echo name=$name
file_uri=$(jq -r ".uri" file_info.json)
echo file_uri=$file_uri
Mencantumkan file yang diupload
Kode berikut akan mendapatkan daftar semua file yang diupload:
Python
from google import genai
client = genai.Client()
print('My files:')
for f in client.files.list():
print(' ', f.name)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const client = new GoogleGenAI({});
async function main() {
const listResponse = await client.files.list({ config: { pageSize: 10 } });
for await (const file of listResponse) {
console.log(file.name);
}
}
await main();
Go
for file, err := range client.Files.All(ctx) {
if err != nil {
log.Fatal(err)
}
fmt.Println(file.Name)
}
REST
echo "My files: "
curl "https://generativelanguage.googleapis.com/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY"
Menghapus file yang diupload
File akan otomatis dihapus setelah 48 jam. Anda juga dapat menghapus file yang diupload secara manual:
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file='path/to/sample.mp3')
client.files.delete(name=myfile.name)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const client = new GoogleGenAI({});
async function main() {
const myfile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mime_type: "audio/mpeg" },
});
const fileName = myfile.name;
await client.files.delete({ name: fileName });
}
await main();
Go
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
client.Files.Delete(ctx, file.Name)
REST
curl --request "DELETE" https://generativelanguage.googleapis.com/v1beta/$name \
-H "x-goog-api-key: $GEMINI_API_KEY"
Info penggunaan
Anda dapat menggunakan Files API untuk mengupload dan berinteraksi dengan file media. Files API memungkinkan Anda menyimpan hingga 20 GB file per project, dengan ukuran maksimum per file sebesar 2 GB. File disimpan selama 48 jam. Selama waktu tersebut, Anda dapat menggunakan API untuk mendapatkan metadata tentang file, tetapi Anda tidak dapat mendownload file. Files API tersedia tanpa biaya di semua wilayah tempat Gemini API tersedia.
Strategi pembuatan perintah file
Bagian ini memberikan panduan dan praktik terbaik untuk menggunakan file media dengan perintah untuk Gemini API.
Kemampuan untuk menggunakan berbagai jenis data dalam perintah memberi Anda lebih banyak fleksibilitas dalam hal tugas yang dapat Anda selesaikan dengan Gemini API. Misalnya, Anda dapat mengirimkan foto hidangan lezat ke model dan memintanya untuk menulis blog singkat tentang hidangan tersebut.
| Perintah | Respons |
|
Tulis postingan blog singkat yang menarik berdasarkan gambar ini. Postingan tersebut harus menyertakan deskripsi makanan dalam foto dan menceritakan perjalanan saya dalam menyiapkan makanan. 
|
Menyiapkan makanan adalah cara yang bagus untuk menghemat waktu dan uang, serta dapat membantu Anda makan lebih sehat. Hidangan ini adalah contoh yang bagus dari hidangan sehat dan lezat yang dapat disiapkan sebelumnya. Makanan ini terdiri dari nasi merah, sayuran panggang, dan ayam teriyaki. Nasi merah adalah karbohidrat kompleks yang sehat dan akan memberi Anda energi yang berkelanjutan. Sayuran panggang adalah cara yang bagus untuk mendapatkan dosis vitamin dan mineral harian Anda, dan ayam teriyaki adalah pilihan yang lezat dan kaya protein. Makanan ini juga mudah disiapkan. Cukup masak nasi merah, panggang sayuran, dan masak ayam teriyaki. Setelah semuanya matang, bagi menjadi beberapa porsi dan simpan di dalam wadah persiapan makanan di dalam kulkas. Kemudian, Anda dapat mengambil wadah dan pergi di pagi yang sibuk. Jika Anda mencari makanan sehat dan lezat yang dapat disiapkan sebelumnya, makanan ini adalah pilihan yang tepat. Makanan ini penuh dengan nutrisi dan rasa, serta pasti membuat Anda merasa kenyang dan puas. Selamat menikmati persiapan makanan yang sehat dan lezat! |
Jika Anda mengalami kesulitan mendapatkan output yang diinginkan dari perintah yang menggunakan file media, ada beberapa strategi yang dapat membantu Anda mendapatkan hasil yang diinginkan. Bagian berikut memberikan pendekatan desain dan tips pemecahan masalah untuk meningkatkan kualitas perintah yang menggunakan input multimodal.
Anda dapat meningkatkan kualitas perintah multimodal dengan mengikuti praktik terbaik berikut:
-
Dasar-dasar desain perintah
- Berikan petunjuk yang spesifik: Buat petunjuk yang jelas dan ringkas yang hanya menyisakan sedikit ruang untuk salah penafsiran.
- Tambahkan beberapa contoh ke perintah Anda: Gunakan contoh few-shot yang realistis untuk menggambarkan apa yang ingin Anda capai.
- Uraikan langkah demi langkah: Bagi tugas yang kompleks menjadi sub-tujuan yang mudah dikelola, dengan memandu model melalui prosesnya.
- Tentukan format output: Dalam perintah Anda, minta output dalam format yang Anda inginkan, seperti Markdown, JSON, HTML, dan lainnya.
- Mendahulukan gambar untuk perintah satu gambar: Meskipun Gemini dapat menangani input gambar dan teks dalam urutan apa pun, untuk perintah yang berisi satu gambar, performanya mungkin lebih baik jika gambar (atau video) tersebut ditempatkan sebelum perintah teks. Namun, untuk perintah yang memerlukan gambar diselingi dengan teks agar dapat dipahami, gunakan urutan apa pun yang paling alami.
-
Memecahkan masalah perintah multimodal
- Jika model tidak mengambil informasi dari bagian gambar yang relevan: Berikan petunjuk tentang aspek gambar yang ingin Anda gunakan sebagai sumber informasi untuk perintah.
- Jika output model terlalu umum (tidak cukup disesuaikan dengan input gambar/video): Di awal perintah, coba minta model untuk mendeskripsikan gambar atau video sebelum memberikan petunjuk tugas, atau coba minta model untuk merujuk pada apa yang ada dalam gambar.
- Untuk memecahkan masalah bagian mana yang gagal: Minta model untuk mendeskripsikan gambar, atau minta model untuk menjelaskan penalarannya, guna mengukur pemahaman awal model.
- Jika perintah Anda menghasilkan konten halusinasi: Coba kurangi setelan suhu atau minta model untuk memberikan deskripsi yang lebih singkat sehingga model cenderung tidak mengekstrapolasi detail tambahan.
- Menyesuaikan parameter sampling: Bereksperimenlah dengan berbagai setelan suhu dan pilihan top-k untuk menyesuaikan kreativitas model.
Berikan petunjuk yang spesifik
Perintah akan memberikan hasil terbaik jika jelas dan mendetail. Jika Anda memiliki output tertentu yang diinginkan, sebaiknya sertakan persyaratan tersebut dalam perintah untuk memastikan Anda mendapatkan output yang diinginkan.
Untuk gambar papan informasi bandara ini, meminta model untuk "mendeskripsikan gambar ini" saja dapat menghasilkan deskripsi umum. Jika Anda ingin model mengurai waktu dan kota dari gambar, Anda dapat menyertakan permintaan tersebut langsung dalam perintah Anda.
| Perintah | Respons model |
|---|---|

Jelaskan gambar ini. |
Gambar menampilkan papan kedatangan dan keberangkatan bandara. |
| Perintah yang diperbarui | Respons yang lebih baik |
|---|---|
Parse waktu dan kota dari papan bandara yang ditampilkan dalam gambar ini ke dalam daftar. |
Tambahkan beberapa contoh
Model Gemini dapat menerima beberapa input yang dapat digunakan sebagai contoh untuk memahami output yang Anda inginkan. Menambahkan contoh ini dapat membantu model mengidentifikasi pola dan menerapkan hubungan antara gambar dan respons yang diberikan ke contoh baru. Hal ini juga disebut pembelajaran "few-shot".
Dalam contoh berikut, output awal ditulis dalam bentuk kalimat, dan juga berisi negara (Brasil). Misalnya, Anda menginginkan output dalam format atau gaya yang berbeda, dan Anda hanya menginginkan kota, bukan negara. Menambahkan contoh few-shot ke prompt dapat mengarahkan model untuk merespons dengan cara yang Anda inginkan.
| Perintah | Respons model |
|---|---|
 Tentukan kota beserta tempat terkenalnya. |
Landmark tersebut adalah patung Kristus Penebus di Rio de Janeiro, Brasil. |
| Perintah yang diperbarui | Respons yang lebih baik |
|---|---|
|
Tentukan kota beserta tempat terkenalnya. 
|
kota: Roma, landmark: Colosseum. |

|
kota: Beijing, landmark: Kota Terlarang |
|
|
kota: Rio de Janeiro, landmark: patung Kristus Penebus |
Uraikan langkah demi langkah
Untuk tugas kompleks seperti yang memerlukan pemahaman dan penalaran visual, sebaiknya pecah tugas menjadi langkah-langkah yang lebih kecil dan lebih sederhana. Atau, Anda juga dapat meminta model secara langsung untuk "berpikir secara berurutan" dalam perintah Anda.
| Perintah | Respons model |
|---|---|

Kapan tisu toilet saya akan habis? |
Segera, Anda hanya memiliki 3 putaran tersisa. |
| Perintah yang diperbarui | Respons yang lebih baik |
|---|---|
|
|
Soal matematika atau jenis soal cerita lainnya adalah kandidat yang tepat untuk meminta model berpikir langkah demi langkah.
| Perintah | Respons |
|---|---|
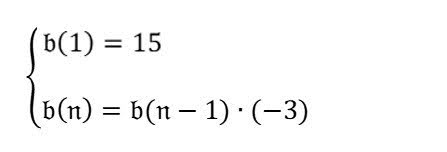
Berapa suku ke-4 dalam deret tersebut? |
-135 |
Respons dari model salah. Beberapa cara untuk meningkatkan kualitas respons adalah dengan meminta model mengurai masalah sebelum menjawab perintah.
| Perintah | Respons |
|---|---|
|
Parse formula dalam gambar terlebih dahulu. Kemudian, berdasarkan formula tersebut, jawab pertanyaan "apa suku ke-4 dalam deret tersebut?". |
Klik untuk meluaskan hasil$$ b(n) = b(n-1) * (-3) $$ $$ b(1) = 15 $$
Oleh karena itu, suku ke-4 dalam deret tersebut adalah -405. |
Respons model ini benar - sekarang untuk membuat respons menjadi lebih efisien, Anda dapat meminta model untuk berpikir langkah demi langkah.
| Perintah yang diperbarui | Respons yang lebih baik |
|---|---|
|
Berapa suku ke-4 dalam deret tersebut? Berpikirlah secara berurutan. |
Istilah pertama adalah 15. Istilah kedua adalah b(1) * (-3) = 15 * (-3) = -45. Suku ketiga adalah b(2) * (-3) = -45 * (-3) = 135. Suku keempat adalah b(3) * (-3) = 135 * (-3) = -405. |
Menentukan format output
Masalah umum adalah kebutuhan output model dalam format tertentu (misalnya Markdown, JSON, HTML), terutama jika output model perlu diproses oleh tugas downstream. Anda dapat mencoba menghasilkan output dalam format tersebut dengan menginstruksikan model untuk melakukannya dalam perintah. Berikut adalah dua contohnya:
| Perintah | Respons model |
|---|---|
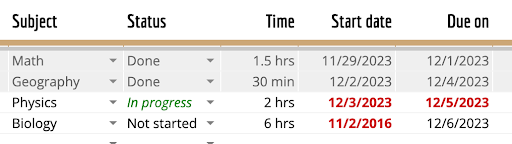
Parse tabel dalam gambar ini ke dalam format Markdown |
```none | Subjek | Status | Waktu | Tanggal mulai | Jatuh tempo pada | | ------- | ------ | ---- | ---------- | ------ | | Matematika | Selesai | 1,5 jam | 29/11/2023 | 1/12/2023 | | Geografi | Selesai | 30 menit | 2/12/2023 | 4/12/2023 | | Fisika | Dalam proses | 2 jam | 3/12/2023 | 5/12/2023 | | Biologi | Belum dimulai | 6 jam | 2/11/2016 | 6/12/2023 | ``` |
| Perintah | Respons model |
|---|---|

Berikan daftar semua atribut berikut: bahan, jenis masakan, vegetarian atau tidak, dalam format JSON |
```json { "ingredients": [ "rice", "shrimp", "clams", "mussels", "peas", "tomatoes", "onions", "garlic", "olive oil", "paprika", "salt", "pepper" ], "type of cuisine": "Spanish", "vegetarian": false } ``` |
Menempatkan gambar Anda di urutan pertama untuk perintah gambar tunggal
Meskipun Gemini dapat menafsirkan gambar dan teks dalam urutan apa pun dalam perintah, menempatkan satu gambar sebelum perintah teks dapat memberikan hasil yang lebih baik. Dalam contoh berikut, Anda akan melihat gambar muncul terlebih dahulu sebelum teks di setiap perintah.
Memecahkan masalah prompt multimodal
Anda mungkin perlu memecahkan masalah perintah jika tidak mendapatkan respons yang bermanfaat. Berikut beberapa strategi yang dapat Anda coba.
Jika model tidak mengambil informasi dari bagian gambar yang relevan
Untuk mendapatkan respons yang lebih spesifik, Anda dapat menunjukkan aspek gambar yang ingin Anda gunakan sebagai sumber informasi untuk menghasilkan respons perintah.
| Perintah | Respons model |
|---|---|

Berapa hari popok ini akan bertahan untuk bayi? |
Popok akan bertahan selama 198 hari sebelum habis. |
| Perintah yang diperbarui | Respons yang lebih baik |
|---|---|
|
Berapa lama popok ini akan bertahan sebelum habis? Gunakan berat yang tertera di kotak untuk menentukan usia anak, dan gunakan jumlah total popok dalam kotak. Bagi jumlah total dengan jumlah popok yang digunakan anak per hari. |
Kotak berisi 198 popok. Kotak tersebut menyatakan bahwa popok ditujukan untuk anak dengan berat 10-17 kg. Rata-rata anak dalam rentang berat ini kemungkinan berusia antara 1 dan 2 tahun. Anak berusia 2 tahun biasanya menggunakan 6 popok per hari, sehingga popok akan bertahan sekitar 33 hari (198/6). |
Jika output model terlalu umum dan tidak cukup disesuaikan dengan input gambar
Untuk membantu model menyesuaikan responsnya dengan gambar, coba minta model untuk mendeskripsikan gambar sebelum melakukan tugas penalarannya.
| Perintah | Respons model |
|---|---|



Apa kesamaan antara gambar-gambar ini? |
Keempat gambar tersebut adalah contoh fotografi lanskap. |
| Perintah yang diperbarui | Respons yang lebih baik |
|---|---|
|
Pertama, jelaskan secara mendetail apa yang ada di setiap gambar. Apa kesamaan antara gambar-gambar ini? |
Gambar pertama menunjukkan seseorang sedang mengemas koper. Gambar kedua menampilkan lorong kosong di pusat perbelanjaan. Gambar ketiga menampilkan gulungan tisu toilet. Gambar keempat menampilkan laut yang gelap dan berbadai. Kesamaan antara gambar-gambar ini adalah bahwa semuanya merupakan contoh ruang liminal. Ruang liminal adalah tempat atau situasi yang berada di antara dua tempat atau situasi lainnya. Hal ini sering kali ditandai dengan rasa tidak pasti atau ambigu. Gambar pertama menunjukkan orang yang berada di antara rumah dan sedang dalam perjalanan. Gambar kedua menunjukkan lorong di antara dua toko. Gambar ketiga adalah tisu toilet, yang dapat mewakili kamar mandi. Kamar mandi adalah ruang transisi antara ranah pribadi dan publik. Ini adalah tempat di mana kita mempersiapkan diri untuk masuk atau keluar dari dunia luar. Gambar keempat menunjukkan laut di antara kedua sisi yang tenang dan berbadai. Ruang liminal bisa terasa menarik dan mengganggu. Tempat tersebut bisa menjadi tempat awal yang baru atau tempat akhir. Tempat tersebut dapat menjadi tempat untuk merenung atau tempat untuk bertindak. |
Anda juga dapat mencoba meminta model secara eksplisit untuk merujuk pada objek yang ada dalam gambar.
| Perintah yang diperbarui | Respons yang lebih baik |
|---|---|
|
Apa kesamaan antara gambar-gambar ini? Rujuk isi gambar dalam respons Anda. |
Semua gambar terkait dengan perjalanan. Gambar pertama menunjukkan seseorang sedang mengemas koper, gambar kedua menunjukkan lorong kosong di pusat perbelanjaan, gambar ketiga menunjukkan tumpukan tisu toilet, dan gambar keempat menunjukkan laut yang gelap dan badai. Semua gambar ini terkait dengan perjalanan karena semuanya adalah hal-hal yang dibutuhkan atau digunakan orang saat mereka bepergian. Gambar pertama menunjukkan seseorang sedang mengemas koper, yang merupakan sesuatu yang dilakukan orang saat mereka akan bepergian. Gambar kedua menampilkan lorong kosong di pusat perbelanjaan, yang merupakan tempat yang sering dikunjungi orang untuk membeli perlengkapan perjalanan mereka. Gambar ketiga menampilkan tumpukan tisu toilet, yang sering digunakan orang saat mereka bepergian. Gambar keempat menunjukkan laut yang gelap dan badai, yang sering dialami orang saat bepergian. |
Tips yang sama berlaku untuk output kreatif dari gambar. Dalam contoh berikut dengan kelinci, meminta model secara eksplisit untuk menyertakan aspek dari gambar dapat meningkatkan kualitas output.
| Perintah | Respons model |
|---|---|

Dapatkah Anda menulis puisi tentang gambar ini untuk saya? |
Kelinci kecil, begitu lembut dan cokelat, Kamu mengunyah rumput, begitu hijau dan manis, |
| Perintah yang diperbarui | Respons yang lebih baik |
|---|---|
|
Dapatkah Anda menulis puisi deskriptif dan dramatis tentang gambar ini dan menyertakan lokasinya? |
Kelinci kecil di padang rumput hijau, Apakah biru laut, Kelinci kecil, katakan yang sebenarnya, Mungkin karena luasnya semua ini, Kelinci kecil, aku ingin tahu apa yang kamu impikan, Apa pun itu, kelinci kecil, |
Memecahkan masalah bagian perintah yang gagal
Mungkin sulit untuk mengetahui apakah perintah gagal karena model tidak memahami gambar sejak awal, atau jika model memahami gambar tetapi tidak melakukan langkah-langkah penalaran yang benar setelahnya. Untuk membedakan alasan tersebut, minta model mendeskripsikan isi gambar.
Dalam contoh berikut, jika model merespons dengan camilan yang tampaknya mengejutkan jika dipadukan dengan teh (misalnya, popcorn), Anda dapat memecahkan masalah terlebih dahulu untuk menentukan apakah model dengan benar mengenali bahwa gambar tersebut berisi teh.
| Perintah | Perintah untuk pemecahan masalah |
|---|---|

Apa camilan yang bisa saya buat dalam 1 menit yang cocok dengan ini? |
Jelaskan apa yang ada dalam gambar ini. |
Strategi lainnya adalah meminta model untuk menjelaskan penalarannya. Hal ini dapat membantu Anda mempersempit bagian penalaran yang salah, jika ada.
| Perintah | Perintah untuk pemecahan masalah |
|---|---|
|
Apa camilan yang bisa saya buat dalam 1 menit yang cocok dengan ini? |
Apa camilan yang bisa saya buat dalam 1 menit yang cocok dengan ini? Harap jelaskan alasannya. |
Langkah berikutnya
- Coba tulis perintah multimodal Anda sendiri menggunakan Google AI Studio.
- Untuk mengetahui informasi tentang cara menggunakan Gemini Files API untuk mengupload file media dan menyertakannya dalam perintah Anda, lihat panduan Vision, Audio, dan Pemrosesan dokumen.
- Untuk panduan selengkapnya tentang desain perintah, seperti menyesuaikan parameter pengambilan sampel, lihat halaman Strategi perintah.