L'API Gemini fournit des paramètres de sécurité que vous pouvez ajuster lors de la phase de prototypage pour déterminer si votre application nécessite une configuration de sécurité plus ou moins restrictive. Vous pouvez ajuster ces paramètres dans quatre catégories de filtres pour restreindre ou autoriser certains types de contenus.
Ce guide explique comment l'API Gemini gère les paramètres de sécurité et le filtrage, et comment vous pouvez modifier les paramètres de sécurité de votre application.
Filtres de sécurité
Les filtres de sécurité ajustables de l'API Gemini couvrent les catégories suivantes :
| Catégorie | Description |
|---|---|
| Harcèlement | Commentaires négatifs ou offensants ciblant l'identité et/ou les attributs protégés. |
| Incitation à la haine | Contenu offensant, irrespectueux ou grossier. |
| Caractère sexuel explicite | Contient des références à des actes sexuels ou à d'autres contenus obscènes. |
| Dangereux | Promeut, facilite ou encourage des actes dangereux. |
Ces catégories sont définies dans HarmCategory. Ces filtres couvrent plusieurs catégories et vous permettent d'ajuster les paramètres selon les besoins de votre cas d'utilisation. Par exemple, si vous créez des dialogues pour un jeu vidéo, vous pouvez juger acceptable d'autoriser davantage de contenus classés comme dangereux en raison de la nature du jeu.
En plus des filtres de sécurité réglables, l'API Gemini dispose de protections intégrées contre les principaux préjudices, comme les contenus qui mettent en danger la sécurité des enfants. Ces types de préjudices sont toujours bloqués et ne peuvent pas être ajustés.
Niveau de filtrage de sécurité du contenu
L'API Gemini classe le niveau de probabilité qu'un contenu soit dangereux comme HIGH, MEDIUM, LOW ou NEGLIGIBLE.
L'API Gemini bloque le contenu en fonction de la probabilité qu'il soit dangereux, et non de la gravité. Cela est important, car certains contenus peuvent présenter une faible probabilité d'être non sécurisés, même si la gravité des dommages est toujours élevée. Par exemple, pour comparer les phrases :
- Le robot m'a frappé.
- Le robot m'a tranché.
La première phrase peut entraîner une probabilité de dangerosité plus élevée, mais vous pouvez considérer que la deuxième phrase a un niveau de gravité supérieur en termes de violence. Compte tenu de cela, il est important que vous effectuiez soigneusement les tests et de déterminer le niveau de blocage approprié pour prendre en charge vos cas d'utilisation clés tout en minimisant les dommages aux utilisateurs finaux.
Filtrage de sécurité par requête
Vous pouvez ajuster les paramètres de sécurité de chaque requête envoyée à l'API. Lorsque vous envoyez une requête, le contenu est analysé et obtient un score de sécurité. L'évaluation de sécurité inclut la catégorie et la probabilité de la classification des préjudices. Par exemple, si le contenu a été bloqué, car la catégorie "Harcèlement" présentait une probabilité élevée, l'évaluation de sécurité renvoyée aurait une catégorie égale à HARASSMENT et une probabilité de préjudice définie sur HIGH.
En raison de la sécurité inhérente au modèle, les filtres supplémentaires sont désactivés par défaut. Si vous choisissez de les activer, vous pouvez configurer le système pour qu'il bloque le contenu en fonction de la probabilité qu'il soit dangereux. Le comportement par défaut du modèle couvre la plupart des cas d'utilisation. Vous ne devez donc ajuster ces paramètres que si cela est nécessaire pour votre application.
Le tableau suivant décrit les paramètres de blocage que vous pouvez ajuster pour chaque catégorie. Par exemple, si vous définissez le paramètre de blocage sur Bloquer peu pour la catégorie Incitation à la haine, tous les éléments ayant une haute probabilité d'être des contenus incitant à la haine sont bloqués. Cependant, toute valeur plus faible est autorisée.
| Seuil (Google AI Studio) | Seuil (API) | Description |
|---|---|---|
| Désactivé | OFF |
Désactiver le filtre de sécurité |
| Ne rien bloquer | BLOCK_NONE |
Toujours afficher, quelle que soit la probabilité de présence de contenu non sécurisé |
| Bloquer quelques éléments | BLOCK_ONLY_HIGH |
Bloquer lorsque la probabilité d'un contenu non sécurisé est élevée |
| Bloquer certains éléments | BLOCK_MEDIUM_AND_ABOVE |
Bloquer lorsque la probabilité moyenne ou élevée de contenu non sécurisé est présente |
| Bloquer la plupart des éléments | BLOCK_LOW_AND_ABOVE |
Bloquer lorsque la probabilité de contenu non sécurisé est faible, moyenne ou élevée |
| N/A | HARM_BLOCK_THRESHOLD_UNSPECIFIED |
Le seuil n'est pas spécifié. Le blocage est effectué selon le seuil par défaut. |
Si le seuil n'est pas défini, le seuil de blocage par défaut est Désactivé pour les modèles Gemini 2.5 et 3.
Vous pouvez définir ces paramètres pour chaque requête envoyée au service de génération.
Pour en savoir plus, consultez la documentation de référence de l'API HarmBlockThreshold.
Commentaires sur la sécurité
generateContent renvoie un GenerateContentResponse qui inclut des commentaires sur la sécurité.
Les commentaires sur les requêtes sont inclus dans promptFeedback. Si promptFeedback.blockReason est défini, le contenu de la requête a été bloqué.
Les commentaires sur les candidats à la réponse sont inclus dans Candidate.finishReason et Candidate.safetyRatings. Si le contenu de la réponse a été bloqué et que finishReason était SAFETY, vous pouvez inspecter safetyRatings pour en savoir plus. Le contenu bloqué n'est pas renvoyé.
Ajuster les paramètres de sécurité
Cette section explique comment ajuster les paramètres de sécurité dans Google AI Studio et dans votre code.
Google AI Studio
Vous pouvez ajuster les paramètres de sécurité dans Google AI Studio.
Cliquez sur Paramètres de sécurité sous Paramètres avancés dans le panneau Paramètres d'exécution pour ouvrir la fenêtre modale Paramètres de sécurité d'exécution. Dans la fenêtre modale, vous pouvez utiliser les curseurs pour ajuster le niveau de filtrage du contenu par catégorie de sécurité :
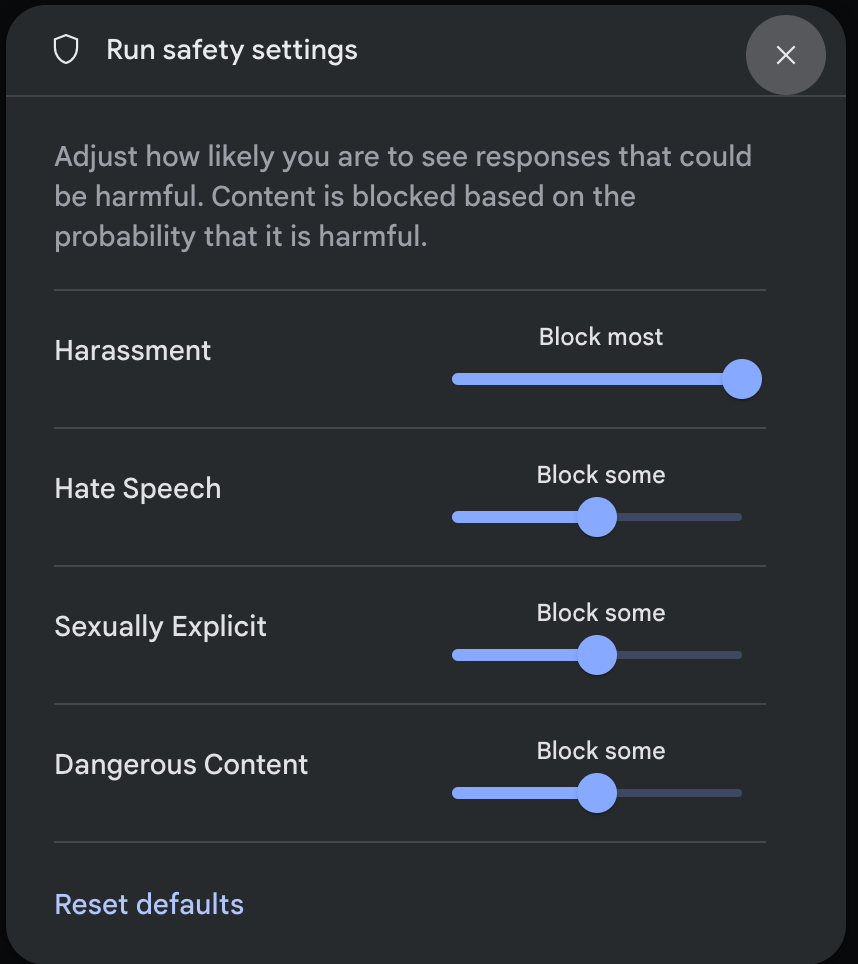
Lorsque vous envoyez une requête (par exemple, en posant une question au modèle), un message Contenu bloqué s'affiche si le contenu de la requête est bloqué. Pour en savoir plus, pointez sur le texte Contenu bloqué pour afficher la catégorie et la probabilité de la classification des préjudices.
Exemples de code
L'extrait de code suivant montre comment définir les paramètres de sécurité dans votre appel GenerateContent. Cela définit le seuil pour la catégorie Incitation à la haine (HARM_CATEGORY_HATE_SPEECH). Si vous définissez cette catégorie sur BLOCK_LOW_AND_ABOVE, tout contenu ayant une probabilité faible ou supérieure d'être de l'incitation à la haine sera bloqué. Pour comprendre les paramètres de seuil, consultez Filtrage de sécurité par requête.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
Go
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
Java
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
Étapes suivantes
- Pour en savoir plus sur l'intégralité de l'API, consultez la documentation de référence de l'API.
- Consultez les consignes de sécurité pour obtenir un aperçu général des considérations de sécurité lors du développement avec des LLM.
- En savoir plus sur l'évaluation de la probabilité par rapport à la gravité par l'équipe Jigsaw
- En savoir plus sur les produits qui contribuent aux solutions de sécurité, comme l'API Perspective * Vous pouvez utiliser ces paramètres de sécurité pour créer un classificateur de toxicité. Pour commencer, consultez l'exemple de classification.