
Model sayfası: CodeGemma
Kaynaklar ve teknik dokümanlar:
Kullanım Şartları: Şartlar
Yazarlar: Google
Model bilgileri
Model özeti
Açıklama
CodeGemma, Gemma'nın üzerine inşa edilmiş hafif açık kod modelleri ailesidir. CodeGemma modelleri, metinden metne ve metinden koda kod çözücü modellerdir. Kod tamamlama ve kod oluşturma görevlerinde uzmanlaşmış 7 milyar önceden eğitilmiş varyant, kod sohbeti ve talimatları takip etme için 7 milyar parametre talimat ayarlı varyant ve hızlı kod tamamlama için 2 milyar parametre önceden eğitilmiş varyant olarak kullanılabilir.
Girdiler ve çıktılar
Giriş: Önceden eğitilmiş model varyantları için: kod tamamlama ve oluşturma senaryoları ya da doğal dil metni/istemi için kod ön eki ve isteğe bağlı olarak son eki. Talimatla ayarlanmış model varyantı için: doğal dil metni veya istem.
Çıktı: Önceden eğitilmiş model varyantları için: boşluk doldurma kod tamamlama, kod ve doğal dil. Talimat ayarlı model varyantı için: kod ve doğal dil.
Alıntı
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
Model verileri
Eğitim veri kümesi
Temel model olarak Gemma'nın kullanıldığı CodeGemma 2B ve 7B önceden eğitilmiş varyantları, açık kaynak matematik veri kümelerinden ve sentetik olarak oluşturulmuş koddan elde edilen, ağırlıklı olarak İngilizce dil verilerinden oluşan ek 500 ila 1.000 milyar jeton üzerinde daha da eğitilir.
Eğitim verileri işleme
CodeGemma'yı eğitmek için aşağıdaki veri ön işleme teknikleri uygulandı:
- FIM: Önceden eğitilmiş CodeGemma modelleri, boşluk doldurma (FIM) görevlerine odaklanır. Modeller hem PSM hem de SPM modlarıyla çalışacak şekilde eğitilir. FIM ayarlarımız, 50-50 PSM/SPM ile% 80 ila% 90 FIM oranıdır.
- Bağımlılık Grafiği Tabanlı Paketleme ve Birim Testi Tabanlı Sözlüksel Paketleme teknikleri: Modelin gerçek dünya uygulamalarıyla uyumunu iyileştirmek için, her depodaki en alakalı kaynak dosyaların birlikte yerleştirilmesi amacıyla eğitim örneklerini proje/depo düzeyinde yapılandırdık. Özellikle, iki sezgisel teknik kullandık: bağımlılık grafiğine dayalı paketleme ve birim testi tabanlı söz dizimi paketleme.
- Son eki tamamen rastgele dağıtım yerine sentaktik olarak daha doğal bir noktada başlatmak için dokümanları ön ek, orta ve son ek olarak bölmeyle ilgili yeni bir teknik geliştirdik.
- Güvenlik: Gemma'ya benzer şekilde, kişisel verilerin filtrelenmesi, CSAM filtrelemesi ve içerik kalitesine ve güvenliğine dayalı diğer filtrelemeler dahil olmak üzere politikalarımıza uygun sıkı güvenlik filtrelemesi uyguladık.
Uygulama bilgileri
Eğitim sırasında kullanılan donanım ve çerçeveler
Gemma gibi CodeGemma da JAX ve ML Pathways kullanılarak en yeni nesil Tensor İşleme Birimi (TPU) donanımı (TPUv5e) üzerinde eğitildi.
Değerlendirme bilgileri
Karşılaştırma sonuçları
Değerlendirme yaklaşımı
- Kod tamamlama karşılaştırmaları: HumanEval (HE) (Tek Satır ve Çok Satır Doldurma)
- Kod oluşturma karşılaştırmaları: HumanEval, MBPP, BabelCode (BC) [C++, C#, Go, Java, JavaScript, Kotlin, Python, Rust]
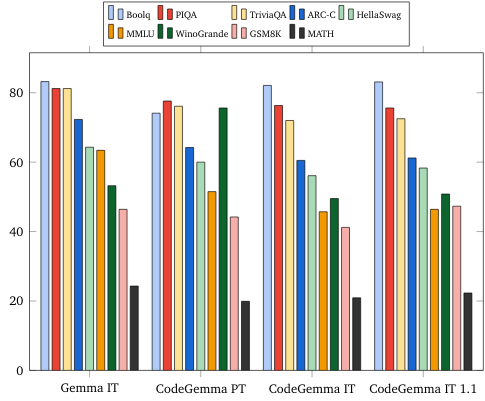
- Soru-cevap: BoolQ, PIQA, TriviaQA
- Doğal Dil: ARC-Challenge, HellaSwag, MMLU, WinoGrande
- Matematiksel Muhakeme: GSM8K, MATH
Kodlama karşılaştırma sonuçları
| Karşılaştırma | 2B | 2B (1.1) | 7 milyar | 7B-IT | 7B-IT (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37,8 | 44,5 | 56,1 | 60,4 |
| MBPP | 43,6 | 49,2 | 56,2 | 54.2 | 55,6 |
| HumanEval Tek Satır | 78,4 | 79,3 | 76,1 | 68,3 | 77,4 |
| HumanEval Çok Satırlı | 51,4 | 51,0 | 58,4 | 20.1 | 23,7 |
| BC HE C++ | 24,2 | 19,9 | 32,9 | 42,2 | 46,6 |
| BC HE C# | 10.6 | 26,1 | 22,4 | 26,7 | 54,7 |
| BC HE Go | 20,5 | 18,0 | 21,7 | 28,6 | 34,2 |
| BC HE Java | 29,2 | 29,8 | 41,0 | 48,4 | 50,3 |
| BC HE JavaScript | 21,7 | 28,0 | 39,8 | 46,0 | 48,4 |
| BC HE Kotlin | 28,0 | 32,3 | 39,8 | 51,6 | 47,8 |
| BC HE Python | 21,7 | 36,6 | 42,2 | 48,4 | 54,0 |
| BC HE Rust | 26,7 | 24,2 | 34,1 | 36,0 | 37,3 |
| BC MBPP C++ | 47,1 | 38,9 | 53,8 | 56,7 | 63,5 |
| BC MBPP C# | 28,7 | 45,3 | 32,5 | 41,2 | 62,0 |
| BC MBPP Go | 45,6 | 38,9 | 43,3 | 46,2 | 53,2 |
| BC MBPP Java | 41,8 | 49,7 | 50,3 | 57,3 | 62,9 |
| BC MBPP JavaScript | 45,3 | 45,0 | 58,2 | 61,4 | 61,4 |
| BC MBPP Kotlin | 46,8 | 49,7 | 54,7 | 59,9 | 62,6 |
| BC MBPP Python | 38,6 | 52,9 | 59,1 | 62,0 | 60,2 |
| BC MBPP Rust | 45,3 | 47,4 | 52,9 | 53,5 | 52,3 |
Doğal dil karşılaştırmaları (7 milyar modelde)
Etik ve güvenlik
Etik ve güvenlik değerlendirmeleri
Değerlendirme yaklaşımı
Değerlendirme yöntemlerimiz arasında yapılandırılmış değerlendirmeler ve ilgili içerik politikalarının şirket içinde yapılan testleri yer alır. Kırmızı takım çalışması, her biri farklı hedeflere ve insan değerlendirme metriklerini kullanan çeşitli ekipler tarafından yürütüldü. Bu modeller, etik ve güvenlikle ilgili çeşitli kategorilere göre değerlendirildi. Örneğin:
İçerik güvenliğini ve temsili zararları kapsayan istemler için gerçek kişiler tarafından yapılan değerlendirme. Değerlendirme yaklaşımı hakkında daha fazla bilgi için Gemma model kartına bakın.
Otonom bilgisayar korsanlığı özelliklerini test etmeye ve olası zararların sınırlı olmasını sağlamaya odaklanan siber saldırı özelliklerinin özel testi.
Değerlendirme sonuçları
Etik ve güvenlik değerlendirmelerinin sonuçları, çocuk güvenliği, içerik güvenliği, temsili zararlar, ezberleme, geniş ölçekli zararlar gibi kategorilerde şirket içi politikalara uygunluk için kabul edilebilir eşikler dahilindedir. Daha fazla bilgi için Gemma model kartına göz atın.
Model kullanımı ve sınırlamaları
Bilinen sınırlamalar
Büyük dil modelleri (LLM'ler), eğitim verilerine ve teknolojinin doğasında var olan sınırlamalara bağlı olarak sınırlamalara sahiptir. LLM'lerin sınırlamaları hakkında daha fazla bilgi için Gemma model kartına bakın.
Etik hususlar ve riskler
Büyük dil modellerinin (LLM'ler) geliştirilmesi, çeşitli etik endişelere yol açar. Bu modellerin geliştirilmesinde birçok unsuru dikkate aldık.
Model ayrıntıları için lütfen Gemma model kartındaki aynı tartışmaya bakın.
Kullanım amacı
Başvuru
Code Gemma modelleri, BT ve PT modelleri arasında değişen çok çeşitli uygulamalara sahiptir. Aşağıdaki olası kullanımlar listesi kapsamlı değildir. Bu listenin amacı, model oluşturucuların model eğitimi ve geliştirme kapsamında değerlendirdiği olası kullanım alanları hakkında bağlamsal bilgi sağlamaktır.
- Kod tamamlama: PT modelleri, IDE uzantısıyla kodu tamamlamak için kullanılabilir
- Kod Oluşturma: BT modeli, IDE uzantısı olsun veya olmasın kod oluşturmak için kullanılabilir
- Kod Konuşması: BT modeli, kod hakkında konuşan sohbet arayüzlerini destekleyebilir
- Kod Eğitimi: BT modeli, etkileşimli kod öğrenme deneyimlerini destekler, söz dizimi düzeltmesine yardımcı olur veya kodlama alıştırması sağlar
Avantajları
Bu model ailesi, kullanıma sunulduğunda benzer büyüklükteki modellere kıyasla Sorumlu Yapay Zeka geliştirmesi için sıfırdan tasarlanmış, yüksek performanslı, açık kod odaklı büyük dil modeli uygulamaları sunar.
Bu dokümanda açıklanan kodlama karşılaştırma değerlendirme metriklerini kullanan bu modellerin, benzer boyutta diğer açık model alternatiflerine kıyasla üstün performans sağladığı gösterilmiştir.