
Trang mô hình: CodeGemma
Tài nguyên và tài liệu kỹ thuật:
Điều khoản sử dụng: Điều khoản
Tác giả: Google
Thông tin mẫu
Tóm tắt mô hình
Mô tả
CodeGemma là một nhóm các mô hình mã nguồn mở gọn nhẹ được xây dựng dựa trên Gemma. Mô hình CodeGemma là các mô hình chỉ giải mã văn bản sang văn bản và văn bản sang mã, đồng thời có sẵn dưới dạng biến thể được huấn luyện trước 7 tỷ, chuyên về các nhiệm vụ hoàn thành mã và tạo mã, biến thể được điều chỉnh theo hướng dẫn 7 tỷ tham số để trò chuyện bằng mã và làm theo hướng dẫn, cũng như biến thể được huấn luyện trước 2 tỷ tham số để hoàn thành mã nhanh chóng.
Đầu vào và đầu ra
Dữ liệu đầu vào: Đối với các biến thể mô hình được huấn luyện trước: tiền tố mã và hậu tố tuỳ chọn cho các tình huống hoàn thành và tạo mã hoặc văn bản/lời nhắc bằng ngôn ngữ tự nhiên. Đối với biến thể mô hình được điều chỉnh theo hướng dẫn: văn bản hoặc lời nhắc bằng ngôn ngữ tự nhiên.
Kết quả: Đối với các biến thể mô hình được huấn luyện trước: hoàn thành mã điền vào giữa, mã và ngôn ngữ tự nhiên. Đối với biến thể mô hình được điều chỉnh theo hướng dẫn: mã và ngôn ngữ tự nhiên.
Trích dẫn
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
Dữ liệu mô hình
Tập dữ liệu huấn luyện
Sử dụng Gemma làm mô hình cơ sở, các biến thể được huấn luyện trước của CodeGemma 2B và 7B được huấn luyện thêm trên 500 đến 1.000 tỷ mã thông báo chủ yếu là dữ liệu ngôn ngữ tiếng Anh từ các tập dữ liệu toán học nguồn mở và mã được tạo tổng hợp.
Xử lý dữ liệu huấn luyện
Các kỹ thuật xử lý trước dữ liệu sau đây đã được áp dụng để huấn luyện CodeGemma:
- FIM – Các mô hình CodeGemma được huấn luyện trước tập trung vào các nhiệm vụ điền vào chỗ trống (FIM). Các mô hình được huấn luyện để hoạt động với cả chế độ PSM và SPM. Chế độ cài đặt FIM của chúng tôi là tỷ lệ FIM từ 80% đến 90% với PSM/SPM 50-50.
- Các kỹ thuật đóng gói dựa trên biểu đồ phần phụ thuộc và đóng gói từ vựng dựa trên kiểm thử đơn vị: Để cải thiện khả năng điều chỉnh mô hình với các ứng dụng thực tế, chúng tôi đã sắp xếp các ví dụ đào tạo ở cấp dự án/kho lưu trữ để đặt cùng các tệp nguồn liên quan nhất trong mỗi kho lưu trữ. Cụ thể, chúng tôi đã sử dụng hai kỹ thuật phỏng đoán: đóng gói dựa trên biểu đồ phần phụ thuộc và đóng gói từ vựng dựa trên kiểm thử đơn vị.
- Chúng tôi đã phát triển một kỹ thuật mới để phân tách tài liệu thành tiền tố, phần giữa và hậu tố để hậu tố bắt đầu ở một điểm tự nhiên hơn về cú pháp thay vì phân phối hoàn toàn ngẫu nhiên.
- An toàn: Tương tự như Gemma, chúng tôi đã triển khai quy trình lọc nghiêm ngặt để đảm bảo an toàn, bao gồm cả việc lọc dữ liệu cá nhân, lọc nội dung CSAM và lọc nội dung khác dựa trên chất lượng và mức độ an toàn của nội dung theo chính sách của chúng tôi.
Thông tin triển khai
Phần cứng và khung được sử dụng trong quá trình huấn luyện
Giống như Gemma, CodeGemma được huấn luyện trên phần cứng Bộ xử lý tensor (TPU) thế hệ mới nhất (TPUv5e), sử dụng JAX và Lối đi máy học.
Thông tin đánh giá
Kết quả đo điểm chuẩn
Phương pháp đánh giá
- Điểm chuẩn hoàn thành mã: HumanEval (HE) (Điền một dòng và nhiều dòng)
- Điểm chuẩn tạo mã: HumanEval, MBPP, BabelCode (BC) [C++, C#, Go, Java, JavaScript, Kotlin, Python, Rust]
- Hỏi và đáp: BoolQ, PIQA, TriviaQA
- Ngôn ngữ tự nhiên: ARC-Challenge, HellaSwag, MMLU, WinoGrande
- Suy luận toán học: GSM8K, MATH
Kết quả đo điểm chuẩn về lập trình
| Benchmark (Điểm chuẩn) | 2 TỶ | 2B (1.1) | 7 tỷ | 7B-IT | 7B-IT (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37,8 | 44,5 | 56,1 | 60,4 |
| MBPP | 43,6 | 49,2 | 56,2 | 54,2 | 55,6 |
| HumanEval Dòng đơn | 78,4 | 79,3 | 76,1 | 68,3 | 77,4 |
| HumanEval nhiều dòng | 51,4 | 51 | 58,4 | 20.1 | 23,7 |
| BC HE C++ | 24,2 | 19,9 | 32,9 | 42,2 | 46,6 |
| BC HE C# | 10.6 | 26.1 | 22,4 | 26,7 | 54,7 |
| BC HE Go | 20,5 | 18.0 | 21,7 | 28,6 | 34,2 |
| BC HE Java | 29,2 | 29,8 | 41,0 | 48,4 | 50,3 |
| JavaScript BC HE | 21,7 | 28 | 39,8 | 46,0 | 48,4 |
| BC HE Kotlin | 28 | 32.3 | 39,8 | 51,6 | 47,8 |
| BC HE Python | 21,7 | 36,6 | 42,2 | 48,4 | 54,0 |
| BC HE Rust | 26,7 | 24,2 | 34.1 | 36 | 37,3 |
| BC MBPP C++ | 47,1 | 38,9 | 53,8 | 56,7 | 63,5 |
| BC MBPP C# | 28,7 | 45,3 | 32,5 | 41,2 | 62,0 |
| BC MBPP Go | 45,6 | 38,9 | 43,3 | 46,2 | 53,2 |
| BC MBPP Java | 41,8 | 49,7 | 50,3 | 57,3 | 62,9 |
| JavaScript BC MBPP | 45,3 | 45,0 | 58.2 | 61,4 | 61,4 |
| BC MBPP Kotlin | 46,8 | 49,7 | 54,7 | 59,9 | 62,6 |
| BC MBPP Python | 38,6 | 52,9 | 59,1 | 62,0 | 60.2 |
| BC MBPP Rust | 45,3 | 47,4 | 52,9 | 53,5 | 52,3 |
Điểm chuẩn ngôn ngữ tự nhiên (trên các mô hình 7B)
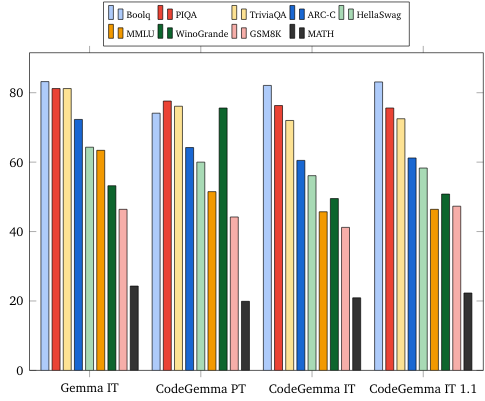
Đạo đức và sự an toàn
Đánh giá về đạo đức và sự an toàn
Phương pháp đánh giá
Các phương pháp đánh giá của chúng tôi bao gồm đánh giá có cấu trúc và kiểm thử nội bộ theo nhóm đối thủ về các chính sách nội dung có liên quan. Một số nhóm đã tiến hành hoạt động tấn công giả lập, mỗi nhóm có các mục tiêu và chỉ số đánh giá con người khác nhau. Các mô hình này được đánh giá theo một số danh mục liên quan đến đạo đức và an toàn, bao gồm:
Đánh giá thủ công về các câu lệnh liên quan đến tính an toàn của nội dung và nội dung gây hại. Hãy xem thẻ mô hình Gemma để biết thêm thông tin chi tiết về phương pháp đánh giá.
Kiểm thử cụ thể các khả năng tấn công mạng, tập trung vào việc kiểm thử các khả năng xâm nhập tự động và đảm bảo hạn chế các tác hại tiềm ẩn.
Kết quả đánh giá
Kết quả đánh giá về đạo đức và sự an toàn nằm trong ngưỡng chấp nhận được để đáp ứng chính sách nội bộ đối với các danh mục như an toàn cho trẻ em, an toàn nội dung, nội dung gây hại, nội dung ghi nhớ, nội dung gây hại trên quy mô lớn. Hãy xem thẻ mô hình Gemma để biết thêm thông tin chi tiết.
Giới hạn và cách sử dụng mô hình
Các hạn chế đã biết
Mô hình ngôn ngữ lớn (LLM) có những hạn chế dựa trên dữ liệu huấn luyện và các hạn chế vốn có của công nghệ. Hãy xem thẻ mô hình Gemma để biết thêm thông tin chi tiết về các giới hạn của LLM.
Những điều cần cân nhắc và rủi ro về mặt đạo đức
Việc phát triển các mô hình ngôn ngữ lớn (LLM) làm nảy sinh một số mối lo ngại về mặt đạo đức. Chúng tôi đã cân nhắc kỹ lưỡng nhiều khía cạnh trong quá trình phát triển các mô hình này.
Vui lòng tham khảo cùng một nội dung thảo luận trong thẻ mô hình Gemma để biết thông tin chi tiết về mô hình.
Mục đích sử dụng
Ứng dụng
Mô hình Gemma mã có nhiều ứng dụng, khác nhau giữa mô hình CNTT và mô hình PT. Danh sách sau đây về các trường hợp sử dụng tiềm năng chưa đầy đủ. Mục đích của danh sách này là cung cấp thông tin theo ngữ cảnh về các trường hợp sử dụng có thể xảy ra mà nhà tạo mô hình đã xem xét trong quá trình huấn luyện và phát triển mô hình.
- Hoàn thành mã: Bạn có thể sử dụng mô hình PT để hoàn thành mã bằng tiện ích IDE
- Tạo mã: Bạn có thể sử dụng mô hình CNTT để tạo mã có hoặc không có tiện ích IDE
- Cuộc trò chuyện về mã: Mô hình CNTT có thể hỗ trợ các giao diện trò chuyện thảo luận về mã
- Giáo dục lập trình: Mô hình CNTT hỗ trợ trải nghiệm học tập lập trình tương tác, hỗ trợ chỉnh sửa cú pháp hoặc cung cấp bài tập lập trình
Lợi ích
Tại thời điểm phát hành, nhóm mô hình này cung cấp các phương thức triển khai mô hình ngôn ngữ lớn tập trung vào mã nguồn mở có hiệu suất cao, được thiết kế từ đầu cho việc phát triển AI có trách nhiệm so với các mô hình có kích thước tương tự.
Khi sử dụng các chỉ số đánh giá điểm chuẩn lập trình được mô tả trong tài liệu này, các mô hình này đã cho thấy hiệu suất vượt trội so với các mô hình mở thay thế có kích thước tương đương khác.