
モデルページ: CodeGemma
リソースと技術ドキュメント:
利用規約: 利用規約
作成者: Google
モデル情報
モデルの概要
説明
CodeGemma は、Gemma 上に構築された軽量のオープンコードモデルのファミリーです。CodeGemma モデルは、テキストからテキストとテキストからコードへのデコーダ専用モデルであり、コード補完とコード生成タスクに特化した 70 億個の事前トレーニング済みバリアント、コードチャットと指示実行用の 70 億個のパラメータの指示チューニング済みバリアント、高速コード補完用の 20 億個のパラメータの事前トレーニング済みバリアントとして利用できます。
入力と出力
入力: 事前トレーニング済みモデルのバリエーションの場合: コード接頭辞と、必要に応じてコード補完と生成のシナリオまたは自然言語テキスト/プロンプトの接尾辞。命令でチューニングされたモデル バリアントの場合: 自然言語テキストまたはプロンプト。
出力: 事前トレーニング済みモデルのバリエーションの場合: Fill-In-The-Middle コード補完、コード、自然言語。命令でチューニングされたモデル バリアントの場合: コードと自然言語。
引用
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
モデルデータ
トレーニング データセット
Gemma をベースモデルとして、CodeGemma 2B と 7B のトレーニング済みバリアントは、オープンソースの数学データセットと合成生成コードからなる主に英語のデータの 500 ~ 1, 000 億トークンでさらにトレーニングされます。
トレーニング データの処理
CodeGemma のトレーニングには、次のデータ前処理手法が適用されました。
- FIM - 事前トレーニング済みの CodeGemma モデルは、Fill-In-The-Middle(FIM)タスクに重点を置いています。モデルは、PSM モードと SPM モードの両方で動作するようにトレーニングされています。FIM の設定は、80 ~ 90% の FIM レートで、PSM と SPM が 50% ずつです。
- 依存関係グラフベースのパッキングと単体テストベースの語彙パッキング手法: 実際のアプリケーションとのモデルの整合性を高めるために、各リポジトリ内で最も関連性の高いソースファイルを配置するように、プロジェクト/リポジトリ レベルでトレーニング例を構造化しました。具体的には、依存関係グラフベースのパッキングと単体テストベースの辞書パッキングという 2 つのヒューリスティック手法を使用しました。
- ドキュメントを接頭辞、中間部、接尾辞に分割する新しい手法が開発されました。これにより、接尾辞は純粋にランダムに分散されるのではなく、より構文的に自然な位置で開始されます。
- 安全性: Gemma と同様に、Google はGoogle のポリシーに沿って、個人データのフィルタリング、CSAM フィルタリング、コンテンツの品質と安全性に基づくその他のフィルタリングなど、厳格な安全フィルタリングを導入しました。
実装情報
トレーニング中に使用されるハードウェアとフレームワーク
Gemma と同様に、CodeGemma は、JAX と ML Pathways を使用して、最新世代の Tensor Processing Unit(TPU)ハードウェア(TPUv5e)でトレーニングされています。
評価情報
ベンチマークの結果
評価のアプローチ
- コード補完ベンチマーク: HumanEval(HE)(1 行と複数行の補完)
- コード生成ベンチマーク: HumanEval、MBPP、BabelCode(BC) [C++、C#、Go、Java、JavaScript、Kotlin、Python、Rust]
- Q&A: BoolQ、PIQA、TriviaQA
- 自然言語: ARC-Challenge、HellaSwag、MMLU、WinoGrande
- 数学推論: GSM8K、MATH
コーディング ベンチマークの結果
| ベンチマーク | 20 億 | 2B(1.1) | 70 億人 | 7B-IT | 7B-IT(1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37.8 | 44.5 | 56.1 | 60.4 |
| MBPP | 43.6 | 49.2 | 56.2 | 54.2 | 55.6 |
| HumanEval 1 行 | 78.4 | 79.3 | 76.1 | 68.3 | 77.4 |
| HumanEval 複数行 | 51.4 | 51.0 | 58.4 | 20.1 | 23.7 |
| BC HE C++ | 24.2 | 19.9 | 32.9 | 42.2 | 46.6 |
| BC HE C# | 10.6 | 26.1 | 22.4 | 26.7 | 54.7 |
| BC HE Go | 20.5 | 18.0 | 21.7 | 28.6 | 34.2 |
| BC HE Java | 29.2 | 29.8 | 41.0 | 48.4 | 50.3 |
| BC HE JavaScript | 21.7 | 28.0 | 39.8 | 46.0 | 48.4 |
| BC HE Kotlin | 28.0 | 32.3 | 39.8 | 51.6 | 47.8 |
| BC HE Python | 21.7 | 36.6 | 42.2 | 48.4 | 54.0 |
| BC HE Rust | 26.7 | 24.2 | 34.1 | 36.0 | 37.3 |
| BC MBPP C++ | 47.1 | 38.9 | 53.8 | 56.7 | 63.5 |
| BC MBPP C# | 28.7 | 45.3 | 32.5 | 41.2 | 62.0 |
| BC MBPP Go | 45.6 | 38.9 | 43.3 | 46.2 | 53.2 |
| BC MBPP Java | 41.8 | 49.7 | 50.3 | 57.3 | 62.9 |
| BC MBPP JavaScript | 45.3 | 45.0 | 58.2 | 61.4 | 61.4 |
| BC MBPP Kotlin | 46.8 | 49.7 | 54.7 | 59.9 | 62.6 |
| BC MBPP Python | 38.6 | 52.9 | 59.1 | 62.0 | 60.2 |
| BC MBPP Rust | 45.3 | 47.4 | 52.9 | 53.5 | 52.3 |
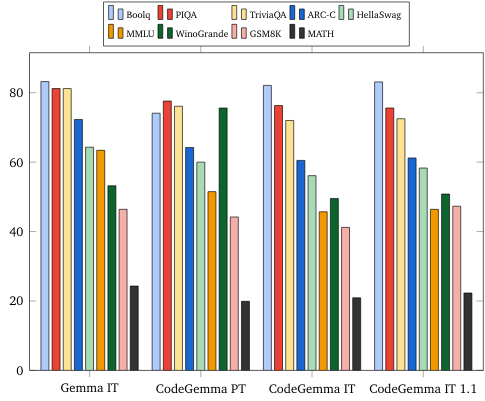
自然言語ベンチマーク(70 億モデル)
倫理と安全
倫理と安全性の評価
評価のアプローチ
Google の評価方法には、構造化評価と、関連するコンテンツ ポリシーの内部レッドチーム テストが含まれます。レッドチームは、それぞれ異なる目標と人間の評価指標を持つ複数のチームによって実施されました。これらのモデルは、倫理と安全に関連する次のようなさまざまなカテゴリで評価されました。
コンテンツの安全性と表現による有害性に関するプロンプトの人間による評価。評価方法の詳細については、Gemma モデルカードをご覧ください。
サイバー攻撃機能の特定のテスト。自律型ハッキング機能のテストと、潜在的な害の制限に重点を置いています。
評価の結果
倫理と安全性の評価の結果が、児童の安全、コンテンツの安全性、表現による有害性、記憶、大規模な有害性などのカテゴリに関する社内ポリシーを満たす許容しきい値内である。詳しくは、Gemma モデルカードをご覧ください。
モデルの使用と制限事項
既知の制限事項
大規模言語モデル(LLM)には、トレーニング データと技術固有の制限に基づく制限があります。LLM の制限事項の詳細については、Gemma モデルカードをご覧ください。
倫理的な考慮事項とリスク
大規模言語モデル(LLM)の開発には、いくつかの倫理的な懸念が伴います。Google は、これらのモデルの開発において、さまざまな側面を慎重に検討しました。
モデルの詳細については、Gemma モデルカードの同じディスカッションをご覧ください。
想定される用途
アプリケーション
コード Gemma モデルは、IT モデルと PT モデルによって異なる幅広いアプリケーションに使用できます。以下のリストは、使用例をすべて網羅しているわけではありません。このリストの目的は、モデル作成者がモデルのトレーニングと開発の一環として検討した可能性のあるユースケースに関するコンテキスト情報を提供することです。
- コード補完: PT モデルを使用して、IDE 拡張機能でコードを補完できます。
- コード生成: IT モデルを使用して、IDE 拡張機能の有無にかかわらずコードを生成できます。
- コード会話: IT モデルは、コードについて話し合う会話インターフェースを強化できます。
- コード教育: IT モデルは、インタラクティブなコード学習体験をサポートし、構文の修正を支援したり、コーディング演習を提供したりします。
利点
リリース時点で、このモデル ファミリーは、同様のサイズのモデルと比較して、責任ある AI 開発のためにゼロから設計された、オープン コード重視の高性能大規模言語モデル実装を提供します。
このドキュメントで説明するコーディング ベンチマーク評価指標を使用すると、これらのモデルは、同規模の他のオープンモデルよりも優れたパフォーマンスを提供することが示されています。