Model Gemini może jednocześnie przetwarzać różne typy danych wejściowych, w tym tekst, obrazy i dźwięk.
Z tego przewodnika dowiesz się, jak korzystać z plików multimedialnych za pomocą interfejsu Files API. Podstawowe operacje są takie same w przypadku plików audio, obrazów, filmów, dokumentów i innych obsługiwanych typów plików.
Wskazówki dotyczące promptów do plików znajdziesz w sekcji Przewodnik po promptach do plików.
Prześlij plik
Aby przesłać plik multimedialny, możesz użyć interfejsu Files API. Zawsze używaj interfejsu Files API, gdy łączny rozmiar żądania (w tym plików, promptu tekstowego, instrukcji systemowych itp.) przekracza 100 MB. W przypadku plików PDF limit wynosi 50 MB.
Poniższy kod przesyła plik, a następnie używa go w wywołaniu funkcji generateContent.
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file="path/to/sample.mp3")
response = client.models.generate_content(
model="gemini-3-flash-preview", contents=["Describe this audio clip", myfile]
)
print(response.text)
JavaScript
import {
GoogleGenAI,
createUserContent,
createPartFromUri,
} from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mpeg" },
});
const response = await ai.models.generateContent({
model: "gemini-3-flash-preview",
contents: createUserContent([
createPartFromUri(myfile.uri, myfile.mimeType),
"Describe this audio clip",
]),
});
console.log(response.text);
}
await main();
Go
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
defer client.Files.Delete(ctx, file.Name)
resp, err := client.Models.GenerateContent(ctx, "gemini-3-flash-preview", []*genai.Content{
{
Parts: []*genai.Part{
genai.NewPartFromFile(*file),
genai.NewPartFromText("Describe this audio clip"),
},
},
}, nil)
if err != nil {
log.Fatal(err)
}
printResponse(resp)
REST
AUDIO_PATH="path/to/sample.mp3"
MIME_TYPE=$(file -b --mime-type "${AUDIO_PATH}")
NUM_BYTES=$(wc -c < "${AUDIO_PATH}")
DISPLAY_NAME=AUDIO
tmp_header_file=upload-header.tmp
# Initial resumable request defining metadata.
# The upload url is in the response headers dump them to a file.
curl "${BASE_URL}/upload/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-D "${tmp_header_file}" \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Header-Content-Type: ${MIME_TYPE}" \
-H "Content-Type: application/json" \
-d "{'file': {'display_name': '${DISPLAY_NAME}'}}" 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " "${tmp_header_file}" | cut -d" " -f2 | tr -d "\r")
rm "${tmp_header_file}"
# Upload the actual bytes.
curl "${upload_url}" \
-H "Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@${AUDIO_PATH}" 2> /dev/null > file_info.json
file_uri=$(jq ".file.uri" file_info.json)
echo file_uri=$file_uri
# Now generate content using that file
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts":[
{"text": "Describe this audio clip"},
{"file_data":{"mime_type": "${MIME_TYPE}", "file_uri": '$file_uri'}}]
}]
}' 2> /dev/null > response.json
cat response.json
echo
jq ".candidates[].content.parts[].text" response.json
Pobieranie metadanych pliku
Możesz sprawdzić, czy interfejs API zapisał przesłany plik, i pobrać jego metadane, wywołując funkcję files.get.
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file='path/to/sample.mp3')
file_name = myfile.name
myfile = client.files.get(name=file_name)
print(myfile)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mpeg" },
});
const fileName = myfile.name;
const fetchedFile = await ai.files.get({ name: fileName });
console.log(fetchedFile);
}
await main();
Go
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
gotFile, err := client.Files.Get(ctx, file.Name)
if err != nil {
log.Fatal(err)
}
fmt.Println("Got file:", gotFile.Name)
REST
# file_info.json was created in the upload example
name=$(jq ".file.name" file_info.json)
# Get the file of interest to check state
curl https://generativelanguage.googleapis.com/v1beta/files/$name \
-H "x-goog-api-key: $GEMINI_API_KEY" > file_info.json
# Print some information about the file you got
name=$(jq ".file.name" file_info.json)
echo name=$name
file_uri=$(jq ".file.uri" file_info.json)
echo file_uri=$file_uri
Wyświetlanie przesłanych plików
Poniższy kod pobiera listę wszystkich przesłanych plików:
Python
from google import genai
client = genai.Client()
print('My files:')
for f in client.files.list():
print(' ', f.name)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const listResponse = await ai.files.list({ config: { pageSize: 10 } });
for await (const file of listResponse) {
console.log(file.name);
}
}
await main();
Go
for file, err := range client.Files.All(ctx) {
if err != nil {
log.Fatal(err)
}
fmt.Println(file.Name)
}
REST
echo "My files: "
curl "https://generativelanguage.googleapis.com/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY"
Usuwanie przesłanych plików
Pliki są automatycznie usuwane po 48 godzinach. Możesz też ręcznie usunąć przesłany plik:
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file='path/to/sample.mp3')
client.files.delete(name=myfile.name)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mpeg" },
});
const fileName = myfile.name;
await ai.files.delete({ name: fileName });
}
await main();
Go
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
client.Files.Delete(ctx, file.Name)
REST
curl --request "DELETE" https://generativelanguage.googleapis.com/v1beta/files/$name \
-H "x-goog-api-key: $GEMINI_API_KEY"
Informacje o użytkowaniu
Za pomocą interfejsu Files API możesz przesyłać pliki multimedialne i z nimi wchodzić w interakcje. Interfejs Files API umożliwia przechowywanie do 20 GB plików w projekcie, przy czym maksymalny rozmiar pojedynczego pliku to 2 GB. Pliki są przechowywane przez 48 godzin. W tym czasie możesz używać interfejsu API do pobierania metadanych plików, ale nie możesz ich pobierać. Interfejs Files API jest dostępny bezpłatnie we wszystkich regionach, w których dostępny jest interfejs Gemini API.
Strategie dotyczące promptów w plikach
W tej sekcji znajdziesz wskazówki i sprawdzone metody dotyczące używania plików multimedialnych z promptami w interfejsie Gemini API.
Możliwość używania w promptach różnych typów danych zapewnia większą elastyczność w zakresie zadań, które możesz wykonywać za pomocą interfejsu Gemini API. Możesz na przykład wysłać modelowi zdjęcie pysznego posiłku i poprosić go o napisanie krótkiego bloga na jego temat.
| Prompt | Odpowiedź |
|
Napisz krótki, interesujący post na bloga na podstawie tego zdjęcia. Powinien zawierać opis posiłku na zdjęciu i opowiadać o mojej przygodzie z przygotowywaniem posiłków. 
|
Przygotowywanie posiłków z wyprzedzeniem to świetny sposób na oszczędzanie czasu i pieniędzy, a także na zdrowsze odżywianie. Ten posiłek to świetny przykład zdrowego i pysznego dania, które można łatwo przygotować z wyprzedzeniem. Posiłek składa się z brązowego ryżu, pieczonych warzyw i kurczaka teriyaki. Brązowy ryż to zdrowe i złożone węglowodany, które zapewnią Ci stały dopływ energii. Pieczone warzywa to świetny sposób na dostarczenie organizmowi codziennej dawki witamin i minerałów, a kurczak teriyaki to pyszna i bogata w białko opcja. To danie jest też bardzo łatwe w przygotowaniu. Wystarczy ugotować brązowy ryż, upiec warzywa i przygotować kurczaka teriyaki. Gdy wszystko będzie gotowe, podziel potrawę na porcje i umieść w pojemnikach, a następnie przechowuj w lodówce. W zajęte poranki możesz po prostu wziąć pojemnik i wyjść z domu. Jeśli szukasz zdrowego i pysznego posiłku, który można łatwo przygotować z wyprzedzeniem, to świetna opcja. Jest pełna składników odżywczych i smaku, a do tego zaspokaja głód. Życzymy smacznego i zdrowego przygotowywania posiłków! |
Jeśli masz problem z uzyskaniem oczekiwanych wyników z promptów, które wykorzystują pliki multimedialne, możesz zastosować kilka strategii, które pomogą Ci osiągnąć zamierzone rezultaty. W kolejnych sekcjach znajdziesz wskazówki dotyczące projektowania i rozwiązywania problemów, które pomogą Ci ulepszyć prompty korzystające z danych wejściowych multimodalnych.
Aby ulepszyć prompty multimodalne, postępuj zgodnie z tymi sprawdzonymi metodami:
-
Podstawy projektowania promptów
- Podawaj konkretne instrukcje: twórz jasne i zwięzłe instrukcje, które pozostawiają jak najmniej miejsca na błędną interpretację.
- Dodaj do promptu kilka przykładów: użyj realistycznych przykładów, aby zilustrować, co chcesz osiągnąć.
- Podziel zadanie na mniejsze części: podziel złożone zadania na mniejsze podcele, aby poprowadzić model przez cały proces.
- Określ format wyjściowy: w prompcie poproś o wygenerowanie danych wyjściowych w wybranym formacie, np. Markdown, JSON, HTML itp.
- W przypadku promptów z jednym obrazem umieść go na pierwszym miejscu: Gemini może przetwarzać dane wejściowe w postaci obrazów i tekstu w dowolnej kolejności, ale w przypadku promptów zawierających jeden obraz może działać lepiej, jeśli ten obraz (lub film) zostanie umieszczony przed promptem tekstowym. W przypadku promptów, które wymagają, aby obrazy były ściśle powiązane z tekstami, użyj dowolnej kolejności, która jest najbardziej naturalna.
-
Rozwiązywanie problemów z promptem multimodalnym
- Jeśli model nie pobiera informacji z odpowiedniej części obrazu: podaj wskazówki dotyczące aspektów obrazu, z których prompt ma pobierać informacje.
- Jeśli odpowiedź modelu jest zbyt ogólna (niedostosowana do obrazu lub filmu): na początku prompta poproś model o opisanie obrazów lub filmu przed podaniem instrukcji zadania albo poproś model o odniesienie się do tego, co znajduje się na obrazie.
- Aby sprawdzić, która część zawiodła: poproś model o opisanie obrazu lub wyjaśnienie jego rozumowania, aby ocenić wstępne zrozumienie modelu.
- Jeśli prompt spowoduje wygenerowanie halucynacji: spróbuj zmniejszyć ustawienie temperatury lub poproś model o krótsze opisy, aby zmniejszyć prawdopodobieństwo ekstrapolacji dodatkowych szczegółów.
- Dostrajanie parametrów próbkowania: eksperymentuj z różnymi ustawieniami temperatury i wyborami górnego k, aby dostosować kreatywność modelu.
Podawaj szczegółowe instrukcje
Prompty są najbardziej skuteczne, gdy są jasne i szczegółowe. Jeśli masz na myśli konkretny wynik, lepiej uwzględnić to wymaganie w prompcie, aby mieć pewność, że uzyskasz oczekiwany rezultat.
W przypadku tego zdjęcia tablicy na lotnisku poproszenie modelu o „opisanie tego obrazu” może wygenerować ogólny opis. Jeśli chcesz, aby model przeanalizował czas i miasto na obrazie, możesz uwzględnić to żądanie bezpośrednio w prompcie.
| Prompt | Odpowiedź modelu |
|---|---|

Opisz ten obraz. |
Obraz przedstawia tablicę przylotów i odlotów na lotnisku. |
| Zaktualizowany prompt | Ulepszona odpowiedź |
|---|---|
Przeanalizuj czas i miasto z tablicy lotniska widocznej na tym obrazie i utwórz z nich listę. |
Dodaj kilka przykładów
Model Gemini może akceptować wiele danych wejściowych, których może używać jako przykładów, aby zrozumieć, jakie dane wyjściowe chcesz uzyskać. Dodanie tych przykładów może pomóc modelowi w rozpoznawaniu wzorców i zastosowaniu relacji między podanymi obrazami a odpowiedziami do nowego przykładu. Jest to tzw. uczenie „few-shot”.
W poniższym przykładzie początkowy wynik jest zapisany w formie zdania i zawiera też nazwę kraju (Brazylia). Załóżmy, że chcesz uzyskać dane wyjściowe w innym formacie lub stylu i potrzebujesz tylko nazwy miasta, a nie kraju. Dodanie do promptu przykładów typu „few-shot” może sprawić, że model będzie odpowiadać w odpowiedni sposób.
| Prompt | Odpowiedź modelu |
|---|---|
 Określ miasto wraz z punktem orientacyjnym. |
Jest to statua Chrystusa Zbawiciela w Rio de Janeiro w Brazylii. |
| Zaktualizowany prompt | Ulepszona odpowiedź |
|---|---|
|
Określ miasto wraz z punktem orientacyjnym. 
|
miasto: Rzym, punkt orientacyjny: Koloseum. |

|
miasto: Pekin, punkt orientacyjny: Zakazane Miasto |
|
|
miasto: Rio de Janeiro, punkt orientacyjny: Statua Chrystusa Zbawiciela |
Szczegółowe instrukcje
W przypadku złożonych zadań, takich jak te, które wymagają zarówno zrozumienia wizualnego, jak i rozumowania, warto podzielić zadanie na mniejsze, prostsze etapy. Możesz też poprosić model, aby „myślał krok po kroku”.
| Prompt | Odpowiedź modelu |
|---|---|

Kiedy skończy mi się papier toaletowy? |
Wkrótce zostaną Ci tylko 3 rolki. |
| Zaktualizowany prompt | Ulepszona odpowiedź |
|---|---|
|
|
Zadania matematyczne i inne zadania tekstowe to świetne przykłady problemów, w przypadku których warto poprosić model o rozwiązanie krok po kroku.
| Prompt | Odpowiedź |
|---|---|
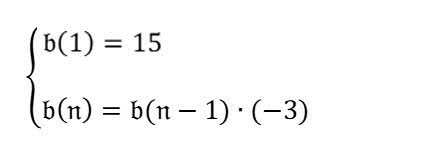
Jaki jest czwarty wyraz ciągu? |
-135 |
Odpowiedź modelu jest nieprawidłowa. Aby to poprawić, możesz poprosić model o przeanalizowanie problemu przed udzieleniem odpowiedzi na prompt.
| Prompt | Odpowiedź |
|---|---|
Najpierw przeanalizuj formułę na obrazie. Następnie na podstawie wzoru odpowiedz na pytanie „Jaki jest czwarty wyraz w ciągu?”. |
Kliknij, aby rozwinąć wynik$$ b(n) = b(n-1) * (-3) $$ $$ b(1) = 15 $$
$$ b(4) = b(4-1) * (-3) $$ $$ b(4) = b(3) * (-3) $$ $$ b(3) = b(3-1) * (-3) $$ $$ b(3) = b(2) * (-3) $$ $$ b(2) = b(2-1) * (-3) $$ $$ b(2) = b(1) * (-3) $$ $$ b(2) = 15 * (-3) $$ $$ b(2) = -45 $$ $$ b(3) = b(2) * (-3) $$ $$ b(3) = -45 * (-3) $$ $$ b(3) = 135 $$ $$ b(4) = b(3) * (-3) $$ $$ b(4) = 135 * (-3) $$ $$ b(4) = -405 $$ Czwarty wyraz ciągu to zatem -405. |
Odpowiedź modelu jest prawidłowa. Aby ją jeszcze bardziej usprawnić, możesz poprosić model o przeanalizowanie jej krok po kroku.
| Zaktualizowany prompt | Ulepszona odpowiedź |
|---|---|
|
Jaki jest czwarty wyraz ciągu? Myśl krok po kroku. |
Pierwszy wyraz to 15. Drugi wyraz to b(1) * (-3) = 15 * (-3) = -45. Trzeci wyraz to b(2) * (-3) = -45 * (-3) = 135. Czwarty wyraz to b(3) * (-3) = 135 * (-3) = -405. |
Określanie formatu wyjściowego
Częstym problemem jest konieczność generowania danych wyjściowych modelu w określonym formacie (np. Markdown, JSON, HTML), zwłaszcza jeśli dane wyjściowe modelu mają być wykorzystywane w dalszych zadaniach. Możesz spróbować uzyskać dane wyjściowe w tym formacie, instruując model w prompcie. Oto 2 przykłady:
| Prompt | Odpowiedź modelu |
|---|---|
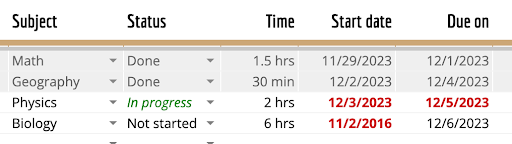
Przekształć tabelę na tym obrazie w format Markdown |
| Temat | Stan | Czas | Data rozpoczęcia | Termin | | ------- | ------ | ---- | ---------- | ------ | | Matematyka | Gotowe | 1,5 godz. | 29.11.2023 r. | 1.12.2023 r. | | Geografia | Gotowe | 30 min | 2.12.2023 r. | 4.12.2023 r. | | Fizyka | W toku | 2 godz. | 3.12.2023 r. | 5.12.2023 r. | | Biologia | Nie rozpoczęto | 6 godz. | 2.11.2016 r. | 6.12.2023 r. | |
| Prompt | Odpowiedź modelu |
|---|---|

Podaj listę wszystkich tych atrybutów: składniki, rodzaj kuchni, czy danie jest wegetariańskie, w formacie JSON. |
|
W przypadku promptów z pojedynczym obrazem umieść obraz na pierwszym miejscu
Gemini może interpretować obraz i tekst w dowolnej kolejności w prompcie, ale umieszczenie pojedynczego obrazu przed promptem tekstowym może przynieść lepsze wyniki. W poniższych przykładach obraz jest zawsze podany przed tekstem w każdym promcie.
Rozwiązywanie problemów z promptem multimodalnym
Jeśli nie otrzymujesz pomocnych odpowiedzi, może być konieczne rozwiązanie problemu z promptem. Oto kilka strategii, które możesz wypróbować.
Jeśli model nie pobiera informacji z odpowiedniej części obrazu
Aby uzyskać bardziej szczegółową odpowiedź, możesz wskazać, z których aspektów obrazu ma czerpać informacje prompt, aby na ich podstawie udzielić odpowiedzi.
| Prompt | Odpowiedź modelu |
|---|---|

Na ile dni wystarczą te pieluszki dla dziecka? |
Pieluchy wystarczą na 198 dni. |
| Zaktualizowany prompt | Ulepszona odpowiedź |
|---|---|
|
Na jak długo wystarczą mi te pieluchy? Na podstawie wagi podanej na opakowaniu określ wiek dziecka, a następnie podaj łączną liczbę pieluszek w opakowaniu. Podziel łączną liczbę pieluch przez liczbę pieluch zużywanych przez dziecko w ciągu dnia. |
Pudełko zawiera 198 pieluszek. Na opakowaniu jest napisane, że pieluszki są przeznaczone dla dziecka o wadze 10–17 kg. Średnie dziecko w tym przedziale wagowym ma prawdopodobnie od 1 do 2 lat. 2-letnie dziecko zużywa zwykle 6 pieluszek dziennie, więc wystarczą one na około 33 dni (198/6). |
Jeśli dane wyjściowe modelu są zbyt ogólne i niedostosowane do danych wejściowych w postaci obrazu.
Aby pomóc modelowi dostosować odpowiedź do obrazów, poproś go o ich opisanie przed wykonaniem zadania związanego z rozumowaniem.
| Prompt | Odpowiedź modelu |
|---|---|



Co łączy te obrazy? |
Wszystkie 4 obrazy to przykłady fotografii krajobrazowej. |
| Zaktualizowany prompt | Ulepszona odpowiedź |
|---|---|
|
Najpierw szczegółowo opisz, co znajduje się na każdym obrazie. Co łączy te obrazy? |
Pierwszy obraz przedstawia osobę pakującą walizkę. Drugi obraz przedstawia pusty korytarz w centrum handlowym. Trzeci obraz przedstawia rolkę papieru toaletowego. Czwarty obraz przedstawia ciemne i sztormowe morze. Wspólną cechą tych obrazów jest to, że wszystkie przedstawiają przestrzenie liminalne. Przestrzenie liminalne to miejsca lub sytuacje, które znajdują się pomiędzy dwoma innymi miejscami lub sytuacjami. Często charakteryzują się poczuciem niepewności lub niejednoznaczności. Pierwszy obraz przedstawia osobę, która jest w domu i w podróży. Drugi obraz przedstawia korytarz między dwoma sklepami. Trzeci obraz przedstawia papier toaletowy, który może symbolizować łazienkę. Łazienka to przestrzeń przejściowa między strefą prywatną a publiczną. To miejsce, w którym przygotowujemy się do wejścia do świata zewnętrznego lub wyjścia z niego. Na czwartym zdjęciu widać morze w stanie pośrednim między spokojnym a sztormowym. Przestrzenie liminalne mogą być zarówno ekscytujące, jak i niepokojące. Mogą być miejscem nowego początku lub zakończenia. Mogą być miejscem refleksji lub miejscem działania. |
Możesz też wyraźnie poprosić model o odniesienie się do tego, co znajduje się na obrazie.
| Zaktualizowany prompt | Ulepszona odpowiedź |
|---|---|
|
Co łączy te obrazy? Odwołuj się do tego, co znajduje się na obrazach. |
Wszystkie obrazy są związane z podróżami. Pierwsze zdjęcie przedstawia osobę pakującą walizkę, drugie – pusty korytarz w centrum handlowym, trzecie – stos papieru toaletowego, a czwarte – ciemne i sztormowe morze. Wszystkie te obrazy są związane z podróżami, ponieważ przedstawiają rzeczy, których ludzie potrzebują lub używają podczas podróży. Pierwszy obraz przedstawia osobę pakującą walizkę, co robią ludzie, gdy wybierają się w podróż. Drugi obrazek przedstawia pusty korytarz w centrum handlowym, czyli miejscu, do którego ludzie często chodzą, aby kupić rzeczy na wyjazdy. Trzeci obraz przedstawia stos papieru toaletowego, który jest czymś, czego ludzie często używają podczas podróży. Czwarty obraz przedstawia ciemne i sztormowe morze, które często można spotkać podczas podróży. |
Te same wskazówki dotyczą wyników kreatywnych generowanych na podstawie obrazów. W tym przykładzie z królikiem wyraźne poproszenie modelu o uwzględnienie aspektów z obrazu może poprawić wynik.
| Prompt | Odpowiedź modelu |
|---|---|

Czy możesz napisać wiersz o tym obrazie? |
Mały króliczek, miękki i brązowy, Podgryzasz trawę, taką zieloną i słodką, |
| Zaktualizowany prompt | Ulepszona odpowiedź |
|---|---|
|
Napisz opisowy i dramatyczny wiersz o tym obrazie. Podaj też lokalizację. |
Mały króliczek na zielonej łące, Czy to oceaniczny błękit Króliczku, powiedz mi, Może to ogrom wszystkiego, Mały króliczku, ciekawe, o czym śnisz, Niezależnie od tego, co to jest, mały króliczku, |
Rozwiązywanie problemów z nieudaną częścią prompta
Trudno stwierdzić, czy prompt nie zadziałał, ponieważ model nie zrozumiał obrazu, czy też zrozumiał obraz, ale nie wykonał prawidłowych kroków rozumowania. Aby odróżnić te powody, poproś model o opisanie, co znajduje się na obrazie.
Jeśli na przykład model zaproponuje przekąskę, która wydaje się zaskakująca w połączeniu z herbatą (np. popcorn), możesz najpierw sprawdzić, czy model prawidłowo rozpoznał, że na obrazie jest herbata.
| Prompt | Prompt do rozwiązywania problemów |
|---|---|

Jaką przekąskę mogę przygotować w minutę, która będzie do tego pasować? |
Opisz, co jest na tym obrazie. |
Inną strategią jest poproszenie modelu o wyjaśnienie jego rozumowania. Może to pomóc w określeniu, która część rozumowania zawiodła, jeśli w ogóle.
| Prompt | Prompt do rozwiązywania problemów |
|---|---|
|
Jaką przekąskę mogę przygotować w minutę, która będzie do tego pasować? |
Jaką przekąskę mogę przygotować w minutę, która będzie do tego pasować? W jaki sposób? |
Co dalej?
- Spróbuj tworzyć własne prompty multimodalne w Google AI Studio.
- Informacje o korzystaniu z interfejsu Gemini Files API do przesyłania plików multimedialnych i dołączania ich do promptów znajdziesz w przewodnikach dotyczących Vision, audio i przetwarzania dokumentów.
- Więcej wskazówek dotyczących projektowania promptów, np. dostrajania parametrów próbkowania, znajdziesz na stronie Strategie tworzenia promptów.