오디오 이해
Gemini는 오디오 입력을 분석하고 텍스트 응답을 생성할 수 있습니다.
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file="path/to/sample.mp3")
response = client.models.generate_content(
model="gemini-3.5-flash", contents=["Describe this audio clip", myfile]
)
print(response.text)
JavaScript
import {
GoogleGenAI,
createUserContent,
createPartFromUri,
} from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mp3" },
});
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: createUserContent([
createPartFromUri(myfile.uri, myfile.mimeType),
"Describe this audio clip",
]),
});
console.log(response.text);
}
await main();
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
localAudioPath := "/path/to/sample.mp3"
uploadedFile, _ := client.Files.UploadFromPath(
ctx,
localAudioPath,
nil,
)
parts := []*genai.Part{
genai.NewPartFromText("Describe this audio clip"),
genai.NewPartFromURI(uploadedFile.URI, uploadedFile.MIMEType),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
contents,
nil,
)
fmt.Println(result.Text())
}
REST
AUDIO_PATH="path/to/sample.mp3"
MIME_TYPE=$(file -b --mime-type "${AUDIO_PATH}")
NUM_BYTES=$(wc -c < "${AUDIO_PATH}")
DISPLAY_NAME=AUDIO
tmp_header_file=upload-header.tmp
# Initial resumable request defining metadata.
# The upload url is in the response headers dump them to a file.
curl "https://generativelanguage.googleapis.com/upload/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-D upload-header.tmp \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Header-Content-Type: ${MIME_TYPE}" \
-H "Content-Type: application/json" \
-d "{'file': {'display_name': '${DISPLAY_NAME}'}}" 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " "${tmp_header_file}" | cut -d" " -f2 | tr -d "\r")
rm "${tmp_header_file}"
# Upload the actual bytes.
curl "${upload_url}" \
-H "Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@${AUDIO_PATH}" 2> /dev/null > file_info.json
file_uri=$(jq ".file.uri" file_info.json)
echo file_uri=$file_uri
# Now generate content using that file
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts":[
{"text": "Describe this audio clip"},
{"file_data":{"mime_type": "${MIME_TYPE}", "file_uri": '$file_uri'}}]
}]
}' 2> /dev/null > response.json
cat response.json
echo
jq ".candidates[].content.parts[].text" response.json
개요
Gemini는 오디오 입력을 분석하고 이해하여 텍스트 응답을 생성할 수 있으므로 다음과 같은 사용 사례를 지원합니다.
- 오디오 콘텐츠에 관해 설명, 요약 또는 질문에 답변합니다.
- 오디오 (음성을 텍스트로 변환)의 텍스트 변환 및 번역을 제공합니다.
- 음성과 음악에서 감정을 감지합니다.
- 오디오의 특정 세그먼트를 분석하고 타임스탬프를 제공합니다.
현재 Gemini API는 실시간 텍스트 변환 사용 사례를 지원하지 않습니다. 실시간 음성 및 동영상 상호작용은 Live API를 참고하세요. 실시간 텍스트 변환을 지원하는 전용 음성을 텍스트로 변환 모델은 Google Cloud Speech-to-Text API를 사용하세요.
음성을 텍스트로 변환
이 샘플 애플리케이션은 음성을 텍스트로 변환, 번역, 요약하도록 Gemini API에 프롬프트를 표시하는 방법을 보여줍니다. 타임스탬프 및 감정 감지를 포함한 음성을 구조화된 출력을 사용하여 감지합니다.
Python
from google import genai
from google.genai import types
client = genai.Client()
YOUTUBE_URL = "https://www.youtube.com/watch?v=ku-N-eS1lgM"
def main():
prompt = """
Process the audio file and generate a detailed transcription.
Requirements:
1. Provide accurate timestamps for each segment (Format: MM:SS).
2. Detect the primary language of each segment.
3. If the segment is in a language different than English, also provide the English translation.
4. Identify the primary emotion of the speaker in this segment. You MUST choose exactly one of the following: Happy, Sad, Angry, Neutral.
5. Provide a brief summary of the entire audio at the beginning.
"""
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=[
types.Content(
parts=[
types.Part(
file_data=types.FileData(
file_uri=YOUTUBE_URL
)
),
types.Part(
text=prompt
)
]
)
],
config=types.GenerateContentConfig(
response_format={"text": {"mime_type": "application/json"}},
response_schema=types.Schema(
type=types.Type.OBJECT,
properties={
"summary": types.Schema(
type=types.Type.STRING,
description="A concise summary of the audio content.",
),
"segments": types.Schema(
type=types.Type.ARRAY,
description="List of transcribed segments with timestamp.",
items=types.Schema(
type=types.Type.OBJECT,
properties={
"timestamp": types.Schema(type=types.Type.STRING),
"content": types.Schema(type=types.Type.STRING),
"language": types.Schema(type=types.Type.STRING),
"language_code": types.Schema(type=types.Type.STRING),
"translation": types.Schema(type=types.Type.STRING),
"emotion": types.Schema(
type=types.Type.STRING,
enum=["happy", "sad", "angry", "neutral"]
),
},
required=["timestamp", "content", "language", "language_code", "emotion"],
),
),
},
required=["summary", "segments"],
),
),
)
print(response.text)
if __name__ == "__main__":
main()
JavaScript
import {
GoogleGenAI,
Type
} from "@google/genai";
const ai = new GoogleGenAI({});
const YOUTUBE_URL = "https://www.youtube.com/watch?v=ku-N-eS1lgM";
async function main() {
const prompt = `
Process the audio file and generate a detailed transcription.
Requirements:
1. Provide accurate timestamps for each segment (Format: MM:SS).
2. Detect the primary language of each segment.
3. If the segment is in a language different than English, also provide the English translation.
4. Identify the primary emotion of the speaker in this segment. You MUST choose exactly one of the following: Happy, Sad, Angry, Neutral.
5. Provide a brief summary of the entire audio at the beginning.
`;
const Emotion = {
Happy: 'happy',
Sad: 'sad',
Angry: 'angry',
Neutral: 'neutral'
};
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: {
parts: [
{
fileData: {
fileUri: YOUTUBE_URL,
},
},
{
text: prompt,
},
],
},
config: {
responseFormat: { text: { mimeType: "application/json" } },
responseSchema: {
type: Type.OBJECT,
properties: {
summary: {
type: Type.STRING,
description: "A concise summary of the audio content.",
},
segments: {
type: Type.ARRAY,
description: "List of transcribed segments with timestamp.",
items: {
type: Type.OBJECT,
properties: {
timestamp: { type: Type.STRING },
content: { type: Type.STRING },
language: { type: Type.STRING },
language_code: { type: Type.STRING },
translation: { type: Type.STRING },
emotion: {
type: Type.STRING,
enum: Object.values(Emotion)
},
},
required: ["timestamp", "content", "language", "language_code", "emotion"],
},
},
},
required: ["summary", "segments"],
},
},
});
const json = JSON.parse(response.text);
console.log(json);
}
await main();
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [
{
"parts": [
{
"file_data": {
"file_uri": "https://www.youtube.com/watch?v=ku-N-eS1lgM",
"mime_type": "video/mp4"
}
},
{
"text": "Process the audio file and generate a detailed transcription.\n\nRequirements:\n1. Provide accurate timestamps for each segment (Format: MM:SS).\n2. Detect the primary language of each segment.\n3. If the segment is in a language different than English, also provide the English translation.\n4. Identify the primary emotion of the speaker in this segment. You MUST choose exactly one of the following: Happy, Sad, Angry, Neutral.\n5. Provide a brief summary of the entire audio at the beginning."
}
]
}
],
"generation_config": {
"response_format": {"text": {"mime_type": "application/json"}},
"response_schema": {
"type": "OBJECT",
"properties": {
"summary": {
"type": "STRING",
"description": "A concise summary of the audio content."
},
"segments": {
"type": "ARRAY",
"description": "List of transcribed segments with timestamp.",
"items": {
"type": "OBJECT",
"properties": {
"timestamp": { "type": "STRING" },
"content": { "type": "STRING" },
"language": { "type": "STRING" },
"language_code": { "type": "STRING" },
"translation": { "type": "STRING" },
"emotion": {
"type": "STRING",
"enum": ["happy", "sad", "angry", "neutral"]
}
},
"required": ["timestamp", "content", "language", "language_code", "emotion"]
}
}
},
"required": ["summary", "segments"]
}
}
}' 2> /dev/null > response.json
cat response.json
echo
jq ".candidates[].content.parts[].text" response.json
버튼 클릭 한 번으로 이 예시 텍스트 변환 앱과 같은 앱을 만들도록 AI Studio 빌드에 프롬프트를 표시할 수 있습니다.
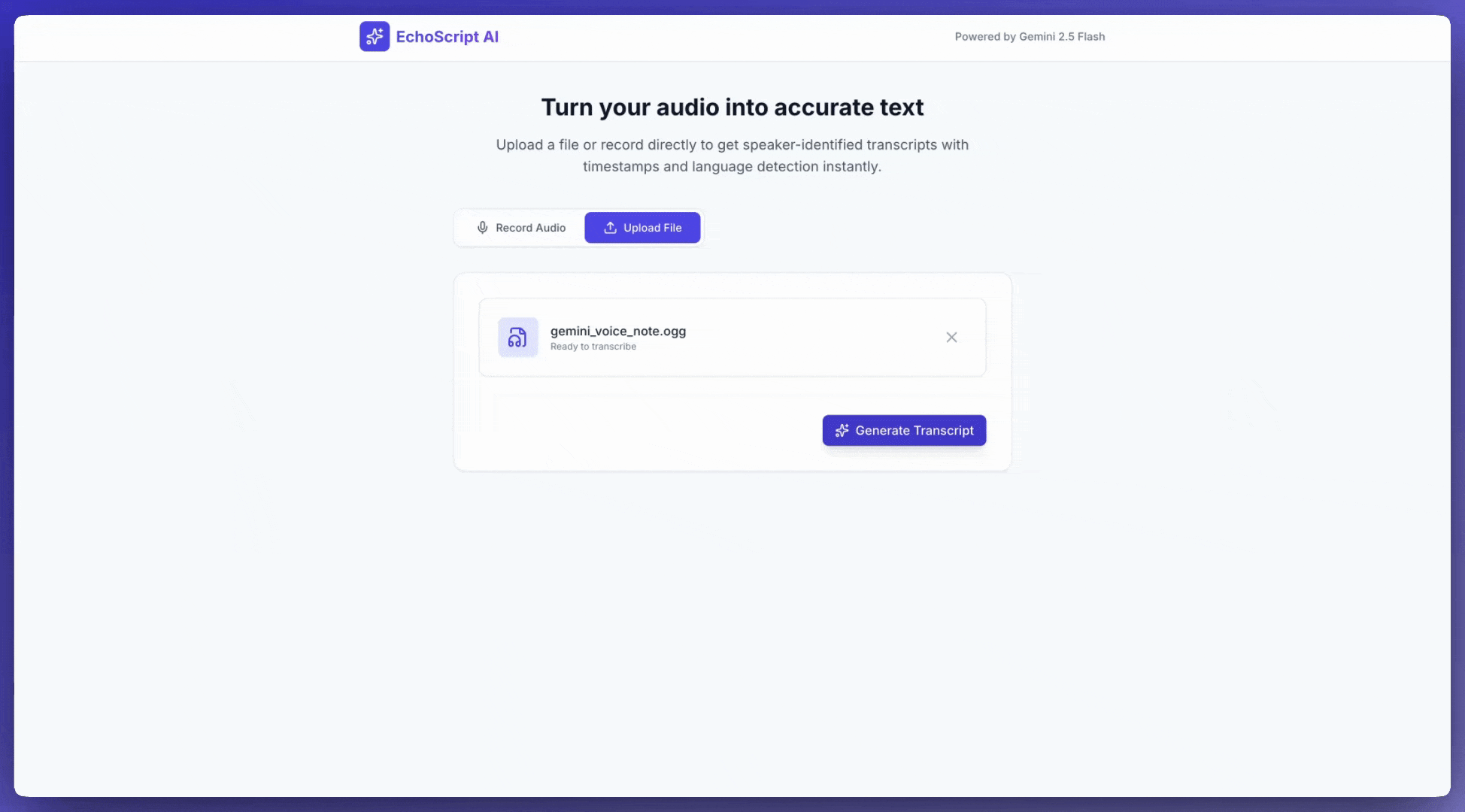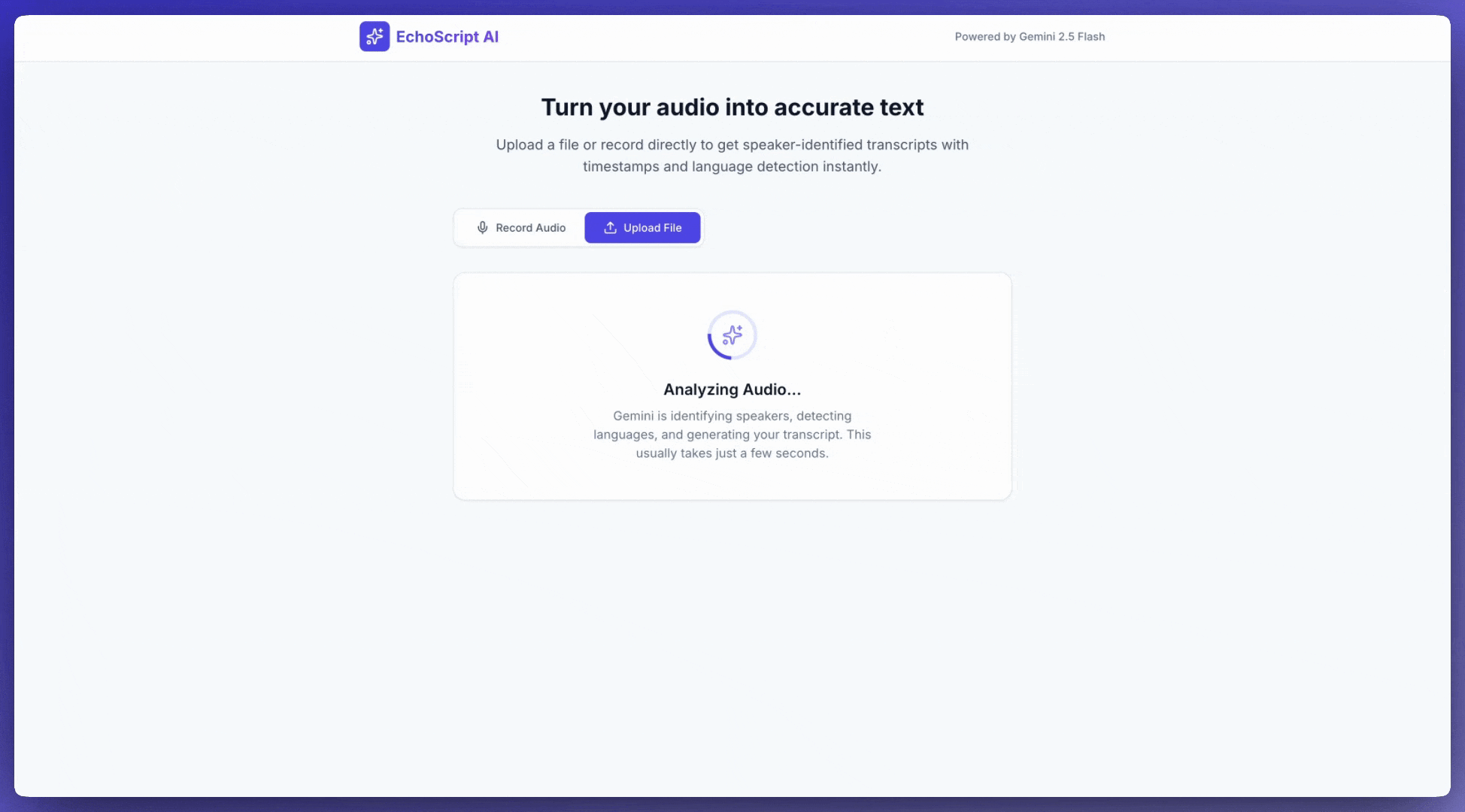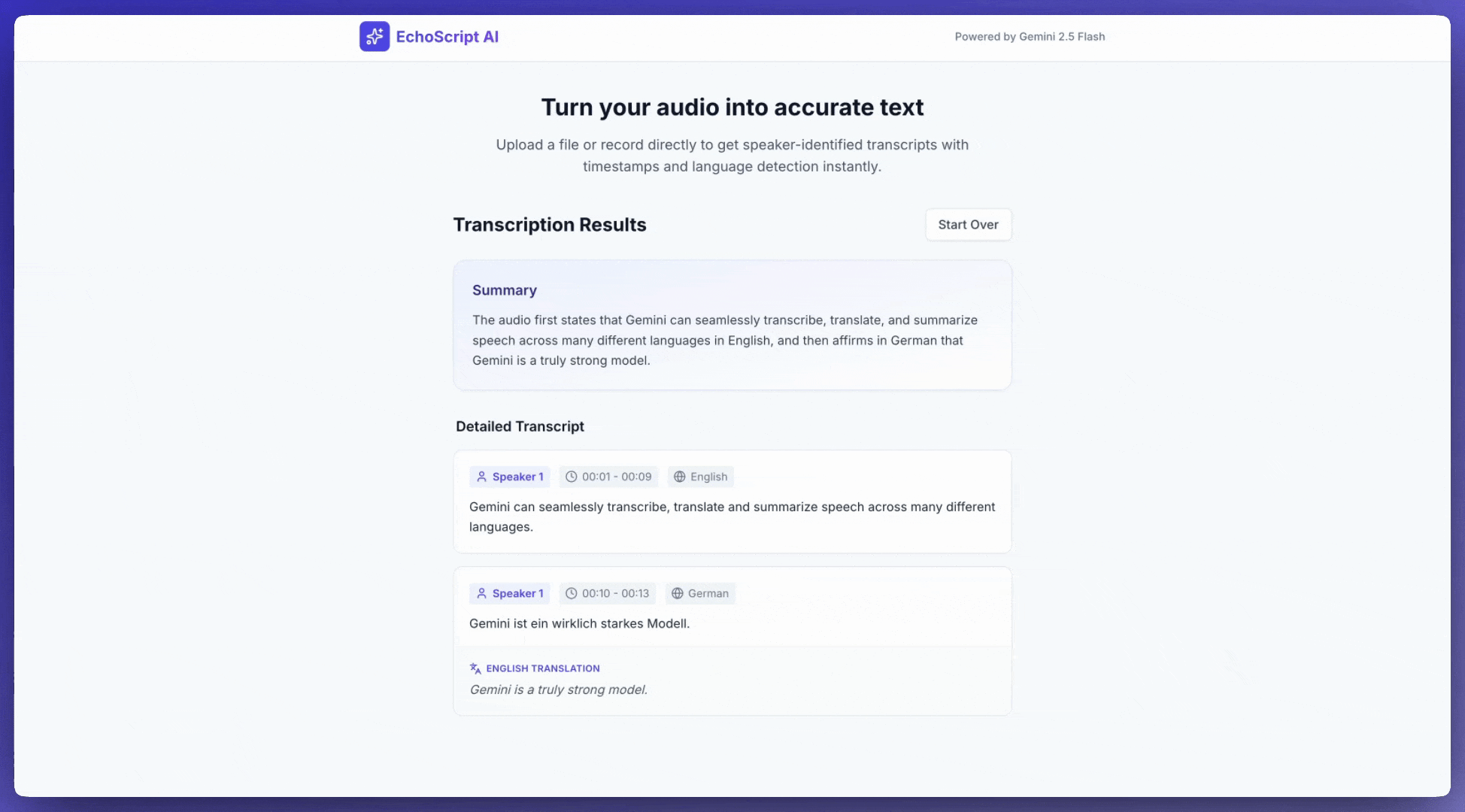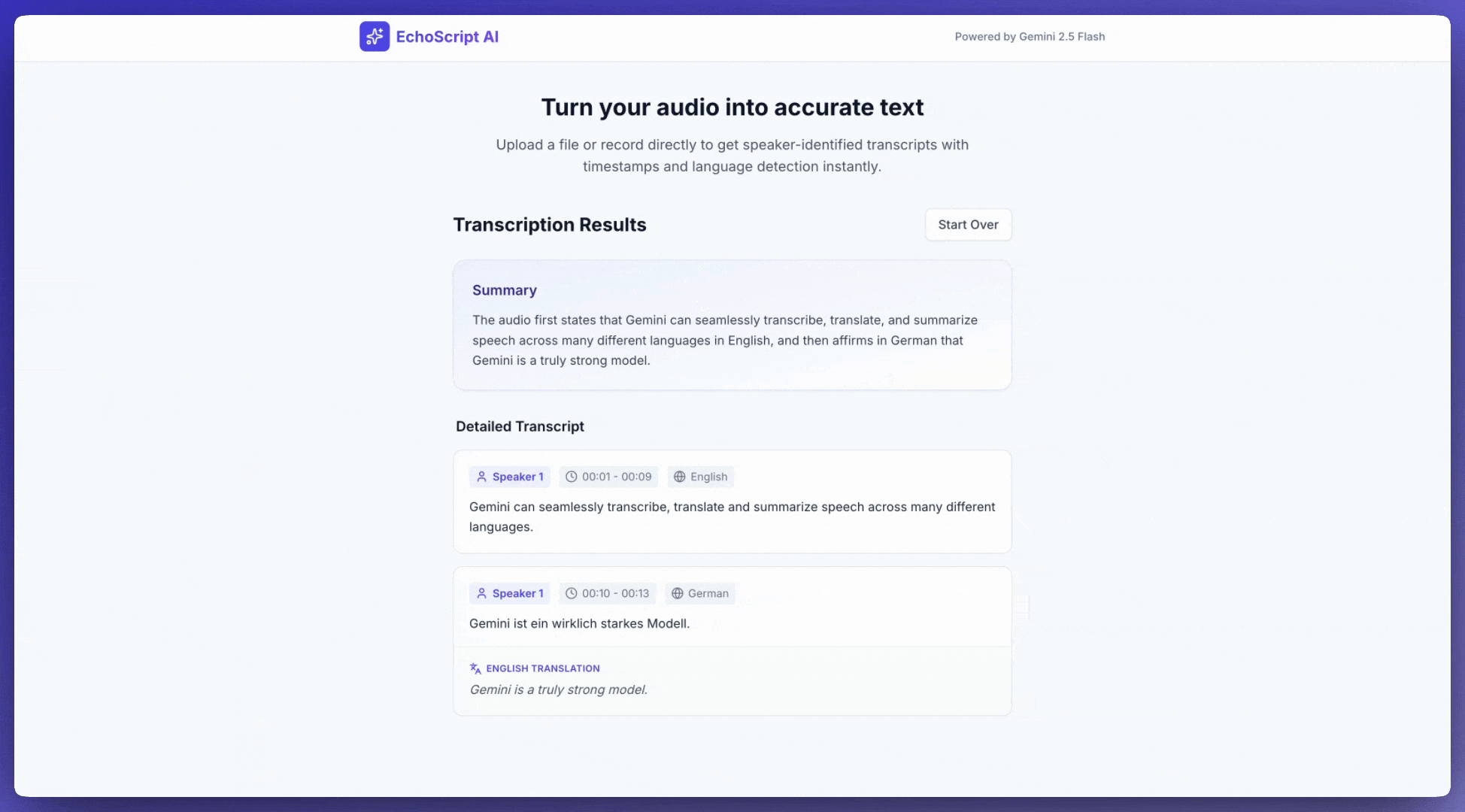
입력 오디오
다음과 같은 방법으로 Gemini에 오디오 데이터를 제공할 수 있습니다.
- 오디오 파일을
generateContent에 요청하기 전에 업로드합니다. - 인라인 오디오 데이터를
generateContent에 대한 요청과 함께 전달합니다.
다른 파일 입력 방법에 관해 알아보려면 파일 입력 방법 가이드를 참고하세요.
오디오 파일 업로드
Files API를 사용하여 오디오 파일을 업로드할 수 있습니다. 파일, 텍스트 프롬프트, 시스템 안내 등을 포함한 총 요청 크기가 20MB보다 큰 경우 항상 Files API를 사용하세요.
다음 코드는 오디오 파일을 업로드한 후 generateContent 호출에서 파일을 사용합니다.
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file="path/to/sample.mp3")
response = client.models.generate_content(
model="gemini-3.5-flash", contents=["Describe this audio clip", myfile]
)
print(response.text)
JavaScript
import {
GoogleGenAI,
createUserContent,
createPartFromUri,
} from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mp3" },
});
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: createUserContent([
createPartFromUri(myfile.uri, myfile.mimeType),
"Describe this audio clip",
]),
});
console.log(response.text);
}
await main();
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
localAudioPath := "/path/to/sample.mp3"
uploadedFile, _ := client.Files.UploadFromPath(
ctx,
localAudioPath,
nil,
)
parts := []*genai.Part{
genai.NewPartFromText("Describe this audio clip"),
genai.NewPartFromURI(uploadedFile.URI, uploadedFile.MIMEType),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
contents,
nil,
)
fmt.Println(result.Text())
}
REST
AUDIO_PATH="path/to/sample.mp3"
MIME_TYPE=$(file -b --mime-type "${AUDIO_PATH}")
NUM_BYTES=$(wc -c < "${AUDIO_PATH}")
DISPLAY_NAME=AUDIO
tmp_header_file=upload-header.tmp
# Initial resumable request defining metadata.
# The upload url is in the response headers dump them to a file.
curl "https://generativelanguage.googleapis.com/upload/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-D upload-header.tmp \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Header-Content-Type: ${MIME_TYPE}" \
-H "Content-Type: application/json" \
-d "{'file': {'display_name': '${DISPLAY_NAME}'}}" 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " "${tmp_header_file}" | cut -d" " -f2 | tr -d "\r")
rm "${tmp_header_file}"
# Upload the actual bytes.
curl "${upload_url}" \
-H "Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@${AUDIO_PATH}" 2> /dev/null > file_info.json
file_uri=$(jq ".file.uri" file_info.json)
echo file_uri=$file_uri
# Now generate content using that file
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts":[
{"text": "Describe this audio clip"},
{"file_data":{"mime_type": "${MIME_TYPE}", "file_uri": '$file_uri'}}]
}]
}' 2> /dev/null > response.json
cat response.json
echo
jq ".candidates[].content.parts[].text" response.json
미디어 파일 작업에 관해 자세히 알아보려면 Files API를 참고하세요.
인라인으로 오디오 데이터 전달
오디오 파일을 업로드하는 대신 generateContent에 대한 요청에서 인라인 오디오 데이터를 전달할 수 있습니다.
Python
from google import genai
from google.genai import types
with open('path/to/small-sample.mp3', 'rb') as f:
audio_bytes = f.read()
client = genai.Client()
response = client.models.generate_content(
model='gemini-3.5-flash',
contents=[
'Describe this audio clip',
types.Part.from_bytes(
data=audio_bytes,
mime_type='audio/mp3',
)
]
)
print(response.text)
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
const ai = new GoogleGenAI({});
const base64AudioFile = fs.readFileSync("path/to/small-sample.mp3", {
encoding: "base64",
});
const contents = [
{ text: "Please summarize the audio." },
{
inlineData: {
mimeType: "audio/mp3",
data: base64AudioFile,
},
},
];
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: contents,
});
console.log(response.text);
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
audioBytes, _ := os.ReadFile("/path/to/small-sample.mp3")
parts := []*genai.Part{
genai.NewPartFromText("Describe this audio clip"),
&genai.Part{
InlineData: &genai.Blob{
MIMEType: "audio/mp3",
Data: audioBytes,
},
},
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
contents,
nil,
)
fmt.Println(result.Text())
}
인라인 오디오 데이터에 관해 몇 가지 알아두어야 할 사항은 다음과 같습니다.
- 최대 요청 크기는 20MB이며, 여기에는 텍스트 프롬프트, 시스템 안내, 인라인으로 제공되는 파일이 포함됩니다. 파일 크기로 인해 총 요청 크기가 20MB를 초과하는 경우 Files API를 사용하여 요청에 사용할 오디오 파일을 업로드하세요.
- 오디오 샘플을 여러 번 사용하는 경우 오디오 파일을 업로드하는 것이 더 효율적입니다.
스크립트 가져오기
오디오 데이터의 스크립트를 가져오려면 프롬프트에서 요청하기만 하면 됩니다.
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file='path/to/sample.mp3')
prompt = 'Generate a transcript of the speech.'
response = client.models.generate_content(
model='gemini-3.5-flash',
contents=[prompt, myfile]
)
print(response.text)
JavaScript
import {
GoogleGenAI,
createUserContent,
createPartFromUri,
} from "@google/genai";
const ai = new GoogleGenAI({});
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mpeg" },
});
const result = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: createUserContent([
createPartFromUri(myfile.uri, myfile.mimeType),
"Generate a transcript of the speech.",
]),
});
console.log("result.text=", result.text);
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
localAudioPath := "/path/to/sample.mp3"
uploadedFile, _ := client.Files.UploadFromPath(
ctx,
localAudioPath,
nil,
)
parts := []*genai.Part{
genai.NewPartFromText("Generate a transcript of the speech."),
genai.NewPartFromURI(uploadedFile.URI, uploadedFile.MIMEType),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
contents,
nil,
)
fmt.Println(result.Text())
}
타임스탬프 참조
MM:SS 형식의 타임스탬프를 사용하여 오디오 파일의 특정 섹션을 참조할 수 있습니다. 예를 들어 다음 프롬프트는
- 파일 시작 부분에서 2분 30초에 시작합니다.
파일 시작 부분에서 3분 29초에 종료합니다.
Python
# Create a prompt containing timestamps.
prompt = "Provide a transcript of the speech from 02:30 to 03:29."
JavaScript
// Create a prompt containing timestamps.
const prompt = "Provide a transcript of the speech from 02:30 to 03:29."
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
localAudioPath := "/path/to/sample.mp3"
uploadedFile, _ := client.Files.UploadFromPath(
ctx,
localAudioPath,
nil,
)
parts := []*genai.Part{
genai.NewPartFromText("Provide a transcript of the speech " +
"between the timestamps 02:30 and 03:29."),
genai.NewPartFromURI(uploadedFile.URI, uploadedFile.MIMEType),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
contents,
nil,
)
fmt.Println(result.Text())
}
토큰 집계
countTokens 메서드를 호출하여 오디오 파일의 토큰 수를 가져옵니다. 예를 들면 다음과 같습니다.
Python
from google import genai
client = genai.Client()
response = client.models.count_tokens(
model='gemini-3.5-flash',
contents=[myfile]
)
print(response)
JavaScript
import {
GoogleGenAI,
createUserContent,
createPartFromUri,
} from "@google/genai";
const ai = new GoogleGenAI({});
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mpeg" },
});
const countTokensResponse = await ai.models.countTokens({
model: "gemini-3.5-flash",
contents: createUserContent([
createPartFromUri(myfile.uri, myfile.mimeType),
]),
});
console.log(countTokensResponse.totalTokens);
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
localAudioPath := "/path/to/sample.mp3"
uploadedFile, _ := client.Files.UploadFromPath(
ctx,
localAudioPath,
nil,
)
parts := []*genai.Part{
genai.NewPartFromURI(uploadedFile.URI, uploadedFile.MIMEType),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
tokens, _ := client.Models.CountTokens(
ctx,
"gemini-3.5-flash",
contents,
nil,
)
fmt.Printf("File %s is %d tokens\n", localAudioPath, tokens.TotalTokens)
}
지원되는 오디오 형식
Gemini는 다음과 같은 오디오 형식 MIME 유형을 지원합니다.
- WAV -
audio/wav - MP3 -
audio/mp3 - AIFF -
audio/aiff - AAC -
audio/aac - OGG Vorbis -
audio/ogg - FLAC -
audio/flac
오디오에 관한 기술 세부정보
- Gemini는 오디오의 각 초를 32개의 토큰으로 나타냅니다. 예를 들어 1분 오디오는 1,920개의 토큰으로 나타냅니다.
- Gemini는 새소리나 사이렌과 같은 음성이 아닌 구성요소를 '이해'할 수 있습니다.
- 단일 프롬프트에서 지원되는 최대 오디오 데이터 길이는 9.5시간입니다. Gemini는 단일 프롬프트의 오디오 파일 수 를 제한하지 않습니다. 하지만 단일 프롬프트에 있는 모든 오디오 파일의 총 결합 길이는 9.5시간을 초과할 수 없습니다.
- Gemini는 오디오 파일을 16Kbps 데이터 해상도로 다운샘플링합니다.
- 오디오 소스에 여러 채널이 포함된 경우 Gemini는 이러한 채널을 단일 채널로 결합합니다.
다음 단계
이 가이드에서는 오디오 데이터에 대한 응답으로 텍스트를 생성하는 방법을 보여줍니다. 자세한 내용은 다음 리소스를 참고하세요.
- 파일 프롬프트 전략: Gemini API는 멀티모달 프롬프트라고도 하는 텍스트, 이미지, 오디오, 동영상 데이터로 프롬프트를 표시하는 것을 지원합니다.
- 시스템 안내: 시스템 안내를 사용하면 특정 요구사항 및 사용 사례에 따라 모델의 동작을 조정할 수 있습니다.
- 안전 가이드: 생성형 AI 모델은 때때로 부정확하거나 편향되거나 불쾌감을 주는 등 예상치 못한 출력을 생성합니다. 이러한 출력으로 인한 피해 위험을 제한하려면 후처리 및 인간 평가가 필수적입니다.