Gemini API는 파일 검색 도구를 통해 검색 증강 생성 ('RAG')을 지원합니다. 파일 검색은 제공된 프롬프트를 기반으로 관련 정보를 빠르게 검색할 수 있도록 데이터를 가져오고, 청크로 나누고, 색인을 생성합니다. 이렇게 검색된 정보는 모델의 컨텍스트로 사용되어 더 정확하고 관련성 있는 대답을 제공할 수 있습니다. 파일 검색은 gemini-embedding-001에서 지원하는 텍스트 임베딩과 gemini-embedding-2에서 지원하는 이미지/멀티모달 임베딩을 통해 멀티모달 기능을 제공할 수도 있습니다.
쿼리 시 파일 저장 및 임베딩 생성은 무료이며, 파일을 처음 색인화할 때 임베딩 생성 비용과 일반 Gemini 모델 입력 / 출력 토큰 비용만 지불하면 됩니다. 이 새로운 청구 패러다임 덕분에 파일 검색 도구를 더 쉽고 비용 효율적으로 빌드하고 확장할 수 있습니다. 자세한 내용은 가격 책정 섹션을 참고하세요.
파일 검색 스토어에 직접 업로드
이 예시에서는 파일 검색 스토어에 파일을 직접 업로드하는 방법을 보여줍니다.
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
file_search_store = client.file_search_stores.create(
config={
'display_name': 'your-fileSearchStore-name',
'embedding_model': 'models/gemini-embedding-2'
}
)
operation = client.file_search_stores.upload_to_file_search_store(
file='sample.txt',
file_search_store_name=file_search_store.name,
config={
'display_name' : 'display-file-name',
}
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Can you tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
if content_block.annotations:
print("\nSources:")
for annotation in content_block.annotations:
if annotation.type == "file_citation":
print(f" - {annotation.file_name}: {annotation.source}")
자바스크립트
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
async function run() {
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'your-fileSearchStore-name',
embeddingModel: 'models/gemini-embedding-2'
}
});
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
}
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Can you tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
if (contentBlock.annotations) {
console.log("\nSources:");
for (const annotation of contentBlock.annotations) {
if (annotation.type === 'file_citation') {
console.log(` - ${annotation.file_name}: ${annotation.source}`);
}
}
}
}
}
}
}
}
run();
자세한 내용은 uploadToFileSearchStore API 참조를 확인하세요.
파일 가져오기
또는 기존 파일을 업로드하고 파일 검색 저장소로 가져올 수 있습니다.
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
sample_file = client.files.upload(file='sample.txt', config={'display_name': 'display_file_name'})
file_search_store = client.file_search_stores.create(
config={
'display_name': 'your-fileSearchStore-name',
'embedding_model': 'models/gemini-embedding-2'
}
)
operation = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Can you tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
자바스크립트
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
async function run() {
const sampleFile = await ai.files.upload({
file: 'sample.txt',
config: { displayName: 'file-name' }
});
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'your-fileSearchStore-name',
embeddingModel: 'models/gemini-embedding-2'
}
});
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation: operation });
}
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Can you tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
}
}
}
}
}
run();
자세한 내용은 importFile API 참조를 확인하세요.
청크 구성
파일을 파일 검색 스토어로 가져오면 파일이 자동으로 청크로 분할되고, 삽입되고, 색인이 생성되고, 파일 검색 스토어로 업로드됩니다. 청크 전략을 더 세부적으로 관리해야 하는 경우 chunking_config 설정을 지정하여 청크당 최대 토큰 수와 중복되는 최대 토큰 수를 설정할 수 있습니다.
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
operation = client.file_search_stores.upload_to_file_search_store(
file_search_store_name=file_search_store.name,
file='sample.txt',
config={
'chunking_config': {
'white_space_config': {
'max_tokens_per_chunk': 200,
'max_overlap_tokens': 20
}
}
}
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
print("Custom chunking complete.")
자바스크립트
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
chunkingConfig: {
whiteSpaceConfig: {
maxTokensPerChunk: 200,
maxOverlapTokens: 20
}
}
}
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
console.log("Custom chunking complete.");
파일 검색 저장소를 사용하려면 업로드 및 가져오기 예에 표시된 대로 interactions.create 메서드에 도구로 전달하세요.
작동 방식
파일 검색은 시맨틱 검색이라는 기법을 사용하여 사용자 프롬프트와 관련된 정보를 찾습니다. 표준 키워드 기반 검색과 달리 시맨틱 검색은 질문의 의미와 컨텍스트를 이해합니다.
파일을 가져오면 업로드된 콘텐츠의 시맨틱 의미를 포착하는 임베딩이라는 숫자 표현으로 변환됩니다. 이러한 임베딩은 특수 파일 검색 데이터베이스에 저장됩니다. 쿼리를 입력하면 쿼리도 임베딩으로 변환됩니다. 그런 다음 시스템은 파일 검색을 실행하여 파일 검색 저장소에서 가장 유사하고 관련성 높은 문서 청크를 찾습니다.
삽입에는 TTL (수명)이 없습니다. 수동으로 삭제하거나 모델이 지원 중단될 때까지 유지됩니다. 파일은 48시간 후에 삭제됩니다.
파일 검색 uploadToFileSearchStore API를 사용하는 과정은 다음과 같습니다.
파일 검색 스토어 만들기: 파일 검색 스토어에는 파일에서 처리된 데이터가 포함됩니다. 시맨틱 검색이 작동하는 임베딩의 영구 컨테이너입니다.
파일을 업로드하고 파일 검색 스토어로 가져오기: 파일을 업로드하고 결과를 파일 검색 스토어로 가져옵니다. 이렇게 하면 원시 문서를 참조하는 임시
File객체가 생성됩니다. 그런 다음 데이터가 청크로 분할되고, 파일 검색 임베딩으로 변환되고, 색인이 생성됩니다.File객체는 48시간 후에 삭제되지만 파일 검색 스토어로 가져온 데이터는 삭제할 때까지 무기한 저장됩니다.파일 검색으로 쿼리: 마지막으로
generateContent호출에서FileSearch도구를 사용합니다. 도구 구성에서 검색할FileSearchStore를 가리키는FileSearchRetrievalResource를 지정합니다. 이렇게 하면 모델이 해당 특정 파일 검색 스토어에서 시맨틱 검색을 실행하여 대답의 근거가 될 관련 정보를 찾습니다.
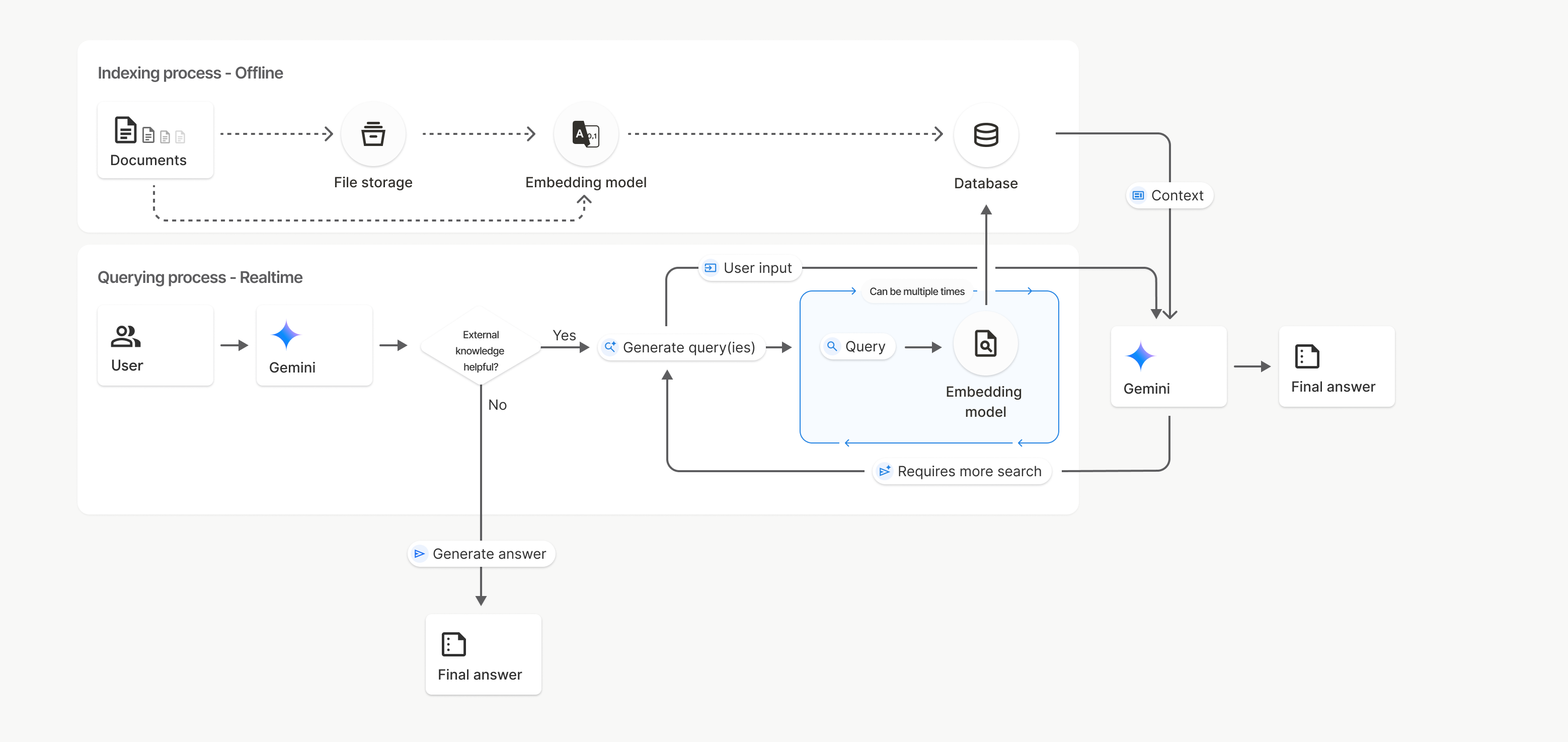
이 다이어그램에서 문서에서 임베딩 모델(gemini-embedding-001 사용)로 연결되는 점선은 uploadToFileSearchStore API (파일 스토리지 우회)를 나타냅니다.
그렇지 않으면 Files API를 사용하여 파일을 별도로 만든 후 가져오면 색인 생성 프로세스가 Documents에서 File storage로 이동한 후 Embedding model로 이동합니다.
파일 검색 스토어
파일 검색 저장소는 문서 임베딩의 컨테이너입니다. 파일 API를 통해 업로드된 원시 파일은 48시간 후에 삭제되지만 파일 검색 스토어로 가져온 데이터는 수동으로 삭제할 때까지 무기한 저장됩니다. 문서를 정리하기 위해 여러 파일 검색 저장소를 만들 수 있습니다. FileSearchStore API를 사용하면 파일 검색 저장소를 생성, 나열, 가져오기, 삭제하여 관리할 수 있습니다. 파일 검색 스토어 이름은 전역 범위입니다.
파일 검색 저장소를 관리하는 방법의 몇 가지 예는 다음과 같습니다.
Python
file_search_store = client.file_search_stores.create(
config={
'display_name': 'my-file_search-store-123',
'embedding_model': 'models/gemini-embedding-2'
}
)
for file_search_store in client.file_search_stores.list():
print(file_search_store)
my_file_search_store = client.file_search_stores.get(name='fileSearchStores/my-file_search-store-123')
client.file_search_stores.delete(name='fileSearchStores/my-file_search-store-123', config={'force': True})
자바스크립트
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'my-file_search-store-123',
embeddingModel: 'models/gemini-embedding-2'
}
});
const fileSearchStores = await ai.fileSearchStores.list();
for await (const store of fileSearchStores) {
console.log(store);
}
const myFileSearchStore = await ai.fileSearchStores.get({
name: 'fileSearchStores/my-file_search-store-123'
});
await ai.fileSearchStores.delete({
name: 'fileSearchStores/my-file_search-store-123',
config: { force: true }
});
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}" \
-H "Content-Type: application/json" \
-d '{ "displayName": "My Store", "embedding_model": "models/gemini-embedding-2" }'
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}" \
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123?key=${GEMINI_API_KEY}"
curl -X DELETE "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123?key=${GEMINI_API_KEY}"
파일 검색 문서
파일 검색 문서 API를 사용하여 파일 검색 저장소에서 각 문서를 list하고, 문서에 관한 정보를 get하고, 이름으로 문서를 delete하여 파일 저장소의 개별 문서를 관리할 수 있습니다.
Python
for document_in_store in client.file_search_stores.documents.list(parent='fileSearchStores/my-file_search-store-123'):
print(document_in_store)
file_search_document = client.file_search_stores.documents.get(name='fileSearchStores/my-file_search-store-123/documents/my_doc')
print(file_search_document)
client.file_search_stores.documents.delete(name='fileSearchStores/my-file_search-store-123/documents/my_doc', config={'force': True})
자바스크립트
const documents = await ai.fileSearchStores.documents.list({
parent: 'fileSearchStores/my-file_search-store-123'
});
for await (const doc of documents) {
console.log(doc);
}
const fileSearchDocument = await ai.fileSearchStores.documents.get({
name: 'fileSearchStores/my-file_search-store-123/documents/my_doc'
});
await ai.fileSearchStores.documents.delete({
name: 'fileSearchStores/my-file_search-store-123/documents/my_doc'
});
REST
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents?key=${GEMINI_API_KEY}"
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents/my_doc?key=${GEMINI_API_KEY}"
curl -X DELETE "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents/my_doc?key=${GEMINI_API_KEY}&force=true"
파일 메타데이터
파일을 필터링하거나 추가 컨텍스트를 제공하기 위해 파일에 맞춤 메타데이터를 추가할 수 있습니다. 메타데이터는 키-값 쌍의 집합입니다.
Python
op = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name,
config={
'custom_metadata': [
{"key": "author", "string_value": "Robert Graves"},
{"key": "year", "numeric_value": 1934}
]
}
)
자바스크립트
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name,
config: {
customMetadata: [
{ key: "author", stringValue: "Robert Graves" },
{ key: "year", numericValue: 1934 }
]
}
});
이 기능은 파일 검색 스토어에 여러 문서가 있고 그중 일부만 검색하려는 경우에 유용합니다.
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Tell me about the book 'I, Claudius'",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name],
"metadata_filter": 'author="Robert Graves"',
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
자바스크립트
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Tell me about the book 'I, Claudius'",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name],
metadata_filter: 'author="Robert Graves"',
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
}
}
}
}
REST
curl "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"model": "gemini-3.5-flash",
"input": [{"type": "text", "text": "Tell me about the book I, Claudius"}],
"tools": [{
"type": "file_search",
"file_search_store_names": ["'$STORE_NAME'"],
"metadata_filter": "author = \"Robert Graves\""
}]
}' 2> /dev/null > response.json
cat response.json
metadata_filter의 목록 필터 문법 구현에 관한 안내는 google.aip.dev/160에서 확인할 수 있습니다.
멀티모달 파일 검색
멀티모달 파일 검색을 사용하면 이미지를 기본적으로 삽입하고 검색하여 풍부한 멀티모달 RAG 애플리케이션을 사용할 수 있습니다.
임베딩 모델 구성
FileSearchStore을 만들 때 멀티모달 모델을 사용하려면 기본 텍스트 전용 임베딩 모델을 재정의해야 합니다. models/gemini-embedding-2를 사용하여 텍스트와 이미지를 모두 처리합니다.
Python
store = client.file_search_stores.create(
config={
"display_name": "Multimodal Catalog",
"embedding_model": "models/gemini-embedding-2",
}
)
자바스크립트
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: "Multimodal Catalog",
embeddingModel: "models/gemini-embedding-2",
},
});
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=$GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"display_name": "Multimodal Catalog",
"embedding_model": "models/gemini-embedding-2"
}'
이미지 업로드
멀티모달 임베딩 모델로 스토어를 만든 후 파일 검색 스토어에 직접 업로드 또는 파일 가져오기에 설명된 것과 동일한 업로드 API를 사용하여 이미지 파일을 직접 업로드할 수 있습니다.
이미지 파일 요구사항:
- 이미지 파일의 해상도는 4K x 4K 픽셀 이하여야 합니다.
- 지원되는 형식은 PNG, JPEG입니다.
인용
파일 검색을 사용하면 모델의 대답에 업로드된 문서의 어떤 부분이 대답을 생성하는 데 사용되었는지 지정하는 인용이 포함될 수 있습니다. 이는 사실 확인 및 검증에 도움이 됩니다.
대답의 model_output 단계 content 블록 내에 있는 annotations 속성을 통해 인용 정보에 액세스할 수 있습니다.
Python
for step in interaction.steps:
if step.type == 'model_output':
for content in step.content:
if content.type == 'text' and content.annotations:
print(content.annotations)
자바스크립트
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text' && contentBlock.annotations) {
console.log(JSON.stringify(contentBlock.annotations, null, 2));
}
}
}
}
인용 구조에 관한 자세한 내용은 상호작용 API 참조를 참고하세요.
페이지 번호
페이지가 있는 문서 (예: PDF)로 파일 검색을 사용하면 정보가 발견된 페이지 번호가 모델의 대답에 포함될 수 있습니다.
이 정보는 file_citation 주석의 page_number 속성을 통해 액세스할 수 있습니다.
Python
for step in interaction.steps:
if step.type == "model_output":
for content in step.content:
if content.type == "text" and content.annotations:
for annotation in content.annotations:
if annotation.type == "file_citation" and annotation.page_number:
print(f"Cited Page: {annotation.page_number}")
자바스크립트
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const block of step.content) {
if (block.type === 'text' && block.annotations) {
for (const annotation of block.annotations) {
if (annotation.type === 'file_citation' && annotation.pageNumber) {
console.log(`Cited Page: ${annotation.pageNumber}`);
}
}
}
}
}
}
미디어 인용
모델이 생성 중에 이미지 청크를 참조하면 API는 media_id를 포함하는 주석에 file_citation 유형의 주석을 반환합니다. 이 ID를 사용하여 모델이 참조한 정확한 이미지 청크를 다운로드할 수 있습니다. 이 media_id는 여러 검색 호출에서 지속되므로 ID를 사용하여 동일한 이미지를 안정적으로 가져오거나 캐시할 수 있습니다.
다음 스니펫은 REST 응답 단계의 예입니다.
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"type": "file_citation",
"file_name": "product_image",
"media_id": "fileSearchStores/my-store-123/media/BlobId-456"
}
]
}
]
}
다음 코드 스니펫은 media_id를 가져오고 미디어를 다운로드하는 방법을 보여줍니다.
Python
for step in interaction.steps:
if step.type == "model_output":
for content in step.content:
if content.type == "text" and content.annotations:
for annotation in content.annotations:
if annotation.type == "file_citation" and annotation.media_id:
print(f"Cited Media ID: {annotation.media_id}")
blob_content = client.file_search_stores.download_media(
media_id=annotation.media_id
)
자바스크립트
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const block of step.content) {
if (block.type === 'text' && block.annotations) {
for (const annotation of block.annotations) {
if (annotation.type === 'file_citation' && annotation.mediaId) {
console.log(`Cited Media ID: ${annotation.mediaId}`);
const blobContent = await ai.fileSearchStores.downloadMedia(annotation.mediaId);
}
}
}
}
}
}
REST
curl -X GET "https://generativelanguage.googleapis.com/v1/fileSearchStores/my-store-123/media/BlobId-456" \
-H "x-goog-api-key: $GEMINI_API_KEY"
커스텀 메타데이터
파일에 맞춤 메타데이터를 추가한 경우 모델 응답의 주석에서 액세스할 수 있습니다. 이는 소스 문서에서 애플리케이션 로직으로 URL, 페이지 번호, 작성자와 같은 추가 컨텍스트를 전달하는 데 유용합니다. file_citation 유형의 각 인용 주석에는 이 맞춤 메타데이터가 포함됩니다.
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.annotations:
for annotation in content_block.annotations:
print(annotation)
자바스크립트
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.annotations) {
contentBlock.annotations.forEach((annotation) => {
console.log(annotation);
});
}
}
}
}
REST
{
"steps": [
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"file_name": "...",
"source": "...",
"custom_metadata": [
{
"key": "author",
"string_value": "Robert Graves"
},
{
"key": "year",
"numeric_value": 1934
}
]
}
]
}
]
}
]
}
구조화된 출력
Gemini 3 모델부터 파일 검색 도구를 구조화된 출력과 결합할 수 있습니다.
Python
from pydantic import BaseModel, Field
class Money(BaseModel):
amount: str = Field(description="The numerical part of the amount.")
currency: str = Field(description="The currency of amount.")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="What is the minimum hourly wage in Tokyo right now?",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}],
response_format={
"type": "text",
"mime_type": "application/json",
"schema": Money.model_json_schema()
},
)
result = Money.model_validate_json(interaction.output_text)
print(result)
자바스크립트
import { z } from "zod";
const moneyJsonSchema = {
type: "object",
properties: {
amount: { type: "string", description: "The numerical part of the amount." },
currency: { type: "string", description: "The currency of amount." }
},
required: ["amount", "currency"]
};
const moneySchema = z.fromJSONSchema(moneyJsonSchema);
async function run() {
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "What is the minimum hourly wage in Tokyo right now?",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name],
}],
response_format: {
type: 'text',
mime_type: 'application/json',
schema: moneyJsonSchema
},
});
const result = moneySchema.parse(JSON.parse(interaction.output_text));
console.log(result);
}
run();
REST
curl "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"model": "gemini-3.5-flash",
"input": "What is the minimum hourly wage in Tokyo right now?",
"tools": [{
"type": "file_search",
"file_search_store_names": ["$FILE_SEARCH_STORE_NAME"]
}],
"response_format": {
"type": "text",
"mime_type": "application/json",
"schema": {
"type": "object",
"properties": {
"amount": {"type": "string", "description": "The numerical part of the amount."},
"currency": {"type": "string", "description": "The currency of amount."}
},
"required": ["amount", "currency"]
}
}
}'
지원되는 모델
다음 모델은 파일 검색을 지원합니다.
| 모델 | 파일 검색 |
|---|---|
| Gemini 3.5 Flash | ✔️ |
| Gemini 3.1 Pro 프리뷰 | ✔️ |
| Gemini 3.1 Flash-Lite | ✔️ |
| Gemini 3 Flash 프리뷰 | ✔️ |
| Gemini 2.5 Pro | ✔️ |
| Gemini 2.5 Flash-Lite | ✔️ |
지원되는 도구 조합
Gemini 3 모델은 기본 제공 도구 (예: 파일 검색)와 맞춤 도구 (함수 호출)의 조합을 지원합니다. 도구 조합 페이지에서 자세히 알아보세요.
지원되는 파일 형식
파일 검색은 다음 섹션에 나열된 다양한 파일 형식을 지원합니다.
애플리케이션 파일 형식
application/dartapplication/ecmascriptapplication/jsonapplication/ms-javaapplication/mswordapplication/pdfapplication/sqlapplication/typescriptapplication/vnd.curlapplication/vnd.dartapplication/vnd.ibm.secure-containerapplication/vnd.jupyterapplication/vnd.ms-excelapplication/vnd.oasis.opendocument.textapplication/vnd.openxmlformats-officedocument.presentationml.presentationapplication/vnd.openxmlformats-officedocument.spreadsheetml.sheetapplication/vnd.openxmlformats-officedocument.wordprocessingml.documentapplication/vnd.openxmlformats-officedocument.wordprocessingml.templateapplication/x-cshapplication/x-hwpapplication/x-hwp-v5application/x-latexapplication/x-phpapplication/x-powershellapplication/x-shapplication/x-shellscriptapplication/x-texapplication/x-zshapplication/xmlapplication/zip
텍스트 파일 형식
text/1d-interleaved-parityfectext/REDtext/SGMLtext/cache-manifesttext/calendartext/cqltext/cql-extensiontext/cql-identifiertext/csstext/csvtext/csv-schematext/dnstext/encaprtptext/enrichedtext/exampletext/fhirpathtext/flexfectext/fwdredtext/gff3text/grammar-ref-listtext/hl7v2text/htmltext/javascripttext/jcr-cndtext/jsxtext/markdowntext/mizartext/n3text/parameterstext/parityfectext/phptext/plaintext/provenance-notationtext/prs.fallenstein.rsttext/prs.lines.tagtext/prs.prop.logictext/raptorfectext/rfc822-headerstext/rtftext/rtp-enc-aescm128text/rtploopbacktext/rtxtext/sgmltext/shaclctext/shextext/spdxtext/stringstext/t140text/tab-separated-valuestext/texmacstext/trofftext/tsvtext/tsxtext/turtletext/ulpfectext/uri-listtext/vcardtext/vnd.DMClientScripttext/vnd.IPTC.NITFtext/vnd.IPTC.NewsMLtext/vnd.atext/vnd.abctext/vnd.ascii-arttext/vnd.curltext/vnd.debian.copyrighttext/vnd.dvb.subtitletext/vnd.esmertec.theme-descriptortext/vnd.exchangeabletext/vnd.familysearch.gedcomtext/vnd.ficlab.flttext/vnd.flytext/vnd.fmi.flexstortext/vnd.gmltext/vnd.graphviztext/vnd.hanstext/vnd.hgltext/vnd.in3d.3dmltext/vnd.in3d.spottext/vnd.latex-ztext/vnd.motorola.reflextext/vnd.ms-mediapackagetext/vnd.net2phone.commcenter.commandtext/vnd.radisys.msml-basic-layouttext/vnd.senx.warpscripttext/vnd.sositext/vnd.sun.j2me.app-descriptortext/vnd.trolltech.linguisttext/vnd.wap.sitext/vnd.wap.sltext/vnd.wap.wmltext/vnd.wap.wmlscripttext/vtttext/wgsltext/x-asmtext/x-bibtextext/x-bootext/x-ctext/x-c++hdrtext/x-c++srctext/x-cassandratext/x-chdrtext/x-coffeescripttext/x-componenttext/x-cshtext/x-csharptext/x-csrctext/x-cudatext/x-dtext/x-difftext/x-dsrctext/x-emacs-lisptext/x-erlangtext/x-gff3text/x-gotext/x-haskelltext/x-javatext/x-java-propertiestext/x-java-sourcetext/x-kotlintext/x-lilypondtext/x-lisptext/x-literate-haskelltext/x-luatext/x-moctext/x-objcsrctext/x-pascaltext/x-pcs-gcdtext/x-perltext/x-perl-scripttext/x-pythontext/x-python-scripttext/x-r-markdowntext/x-rsrctext/x-rsttext/x-ruby-scripttext/x-rusttext/x-sasstext/x-scalatext/x-schemetext/x-script.pythontext/x-scsstext/x-setexttext/x-sfvtext/x-shtext/x-siestatext/x-sostext/x-sqltext/x-swifttext/x-tcltext/x-textext/x-vbasictext/x-vcalendartext/xmltext/xml-dtdtext/xml-external-parsed-entitytext/yaml
제한사항
- Live API: Live API에서는 파일 검색이 지원되지 않습니다.
- 도구 비호환성: 현재 파일 검색은 Google 검색을 사용한 그라운딩, URL 컨텍스트 등의 다른 도구와 함께 사용할 수 없습니다.
비율 제한
File Search API에는 서비스 안정성을 위해 다음과 같은 한도가 적용됩니다.
- 최대 파일 크기 / 문서당 한도: 100MB
- 프로젝트 파일 검색 저장소의 총 크기 (사용자 등급 기준):
- 무료: 1GB
- Tier 1: 10 GB
- Tier 2: 100 GB
- Tier 3: 1 TB
- 권장사항: 최적의 검색 지연 시간을 보장하려면 각 파일 검색 스토어의 크기를 20GB 미만으로 제한하세요.
가격 책정
- 기존 임베딩 가격 책정에 따라 색인 생성 시 임베딩 비용이 청구됩니다.
- 저장 공간은 무료입니다.
- 쿼리 시간 임베딩은 무료입니다.
- 검색된 문서 토큰은 일반 컨텍스트 토큰으로 청구됩니다.