A API Gemini permite a geração aumentada por recuperação (RAG) com a ferramenta de pesquisa de arquivos. A Pesquisa de arquivos importa, divide e indexa seus dados para permitir a recuperação rápida de informações relevantes com base em um comando fornecido. Essas informações recuperadas são usadas como contexto para o modelo, permitindo que ele forneça respostas mais precisas e relevantes. A pesquisa de arquivos também pode oferecer recursos multimodais com embeddings de texto compatíveis com gemini-embedding-001 e embeddings de imagem/multimodais compatíveis com gemini-embedding-2.
O armazenamento de arquivos e a geração de embeddings no momento da consulta são sem custo financeiro. Você só paga pela criação de embeddings quando indexa seus arquivos pela primeira vez e pelo custo normal dos tokens de entrada / saída do modelo do Gemini. Esse novo paradigma de faturamento torna a ferramenta de pesquisa de arquivos mais fácil e econômica de criar e dimensionar. Consulte a seção de preços para detalhes.
Fazer upload diretamente para o repositório da Pesquisa de arquivos
Este exemplo mostra como fazer upload direto de um arquivo para o repositório de pesquisa de arquivos:
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
file_search_store = client.file_search_stores.create(
config={
'display_name': 'your-fileSearchStore-name',
'embedding_model': 'models/gemini-embedding-2'
}
)
operation = client.file_search_stores.upload_to_file_search_store(
file='sample.txt',
file_search_store_name=file_search_store.name,
config={
'display_name' : 'display-file-name',
}
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Can you tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
if content_block.annotations:
print("\nSources:")
for annotation in content_block.annotations:
if annotation.type == "file_citation":
print(f" - {annotation.file_name}: {annotation.source}")
JavaScript
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
async function run() {
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'your-fileSearchStore-name',
embeddingModel: 'models/gemini-embedding-2'
}
});
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
}
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Can you tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
if (contentBlock.annotations) {
console.log("\nSources:");
for (const annotation of contentBlock.annotations) {
if (annotation.type === 'file_citation') {
console.log(` - ${annotation.file_name}: ${annotation.source}`);
}
}
}
}
}
}
}
}
run();
Consulte a referência da API para uploadToFileSearchStore para mais informações.
Como importar arquivos
Como alternativa, você pode fazer upload de um arquivo e importar para o repositório de pesquisa de arquivos:
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
sample_file = client.files.upload(file='sample.txt', config={'display_name': 'display_file_name'})
file_search_store = client.file_search_stores.create(
config={
'display_name': 'your-fileSearchStore-name',
'embedding_model': 'models/gemini-embedding-2'
}
)
operation = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Can you tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
JavaScript
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
async function run() {
const sampleFile = await ai.files.upload({
file: 'sample.txt',
config: { displayName: 'file-name' }
});
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'your-fileSearchStore-name',
embeddingModel: 'models/gemini-embedding-2'
}
});
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation: operation });
}
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Can you tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
}
}
}
}
}
run();
Consulte a referência da API para importFile para mais informações.
Configuração de divisão
Quando você importa um arquivo para um repositório de pesquisa de arquivos, ele é automaticamente dividido em partes, incorporado, indexado e enviado para o repositório de pesquisa de arquivos. Se você precisar de mais controle sobre a estratégia de divisão em partes, especifique uma configuração chunking_config para definir um número máximo de tokens por parte e um número máximo de tokens sobrepostos.
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
operation = client.file_search_stores.upload_to_file_search_store(
file_search_store_name=file_search_store.name,
file='sample.txt',
config={
'chunking_config': {
'white_space_config': {
'max_tokens_per_chunk': 200,
'max_overlap_tokens': 20
}
}
}
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
print("Custom chunking complete.")
JavaScript
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
chunkingConfig: {
whiteSpaceConfig: {
maxTokensPerChunk: 200,
maxOverlapTokens: 20
}
}
}
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
console.log("Custom chunking complete.");
Para usar o armazenamento da Pesquisa de arquivos, transmita-o como uma ferramenta para o método interactions.create, conforme mostrado nos exemplos de Upload e Importação.
Como funciona
A Pesquisa de arquivos usa uma técnica chamada pesquisa semântica para encontrar informações relevantes para o comando do usuário. Ao contrário da pesquisa padrão por palavras-chave, a pesquisa semântica entende o significado e o contexto da sua consulta.
Quando você importa um arquivo, ele é convertido em representações numéricas chamadas embeddings, que capturam o significado semântico do conteúdo enviado. Esses embeddings são armazenados em um banco de dados especializado da Pesquisa de arquivos. Quando você faz uma consulta, ela também é convertida em um embedding. Em seguida, o sistema realiza uma pesquisa de arquivos para encontrar os trechos de documentos mais semelhantes e relevantes no repositório de pesquisa de arquivos.
Não há um Time To Live (TTL) para incorporações. Elas persistem até serem excluídas manualmente ou quando o modelo é descontinuado. No entanto, os arquivos são excluídos após 48 horas.
Confira um detalhamento do processo para usar a API File Search
uploadToFileSearchStore:
Criar um repositório de pesquisa de arquivos: um repositório de pesquisa de arquivos contém os dados processados dos seus arquivos. É o contêiner persistente para os embeddings em que a pesquisa semântica vai operar.
Fazer upload de um arquivo e importar para um repositório da Pesquisa de arquivos: faça upload de um arquivo e importe os resultados para o repositório da Pesquisa de arquivos ao mesmo tempo. Isso cria um objeto
Filetemporário, que é uma referência ao seu documento bruto. Esses dados são divididos em partes, convertidos em embeddings da pesquisa de arquivos e indexados. O objetoFileé excluído após 48 horas, enquanto os dados importados para o repositório da Pesquisa de arquivos são armazenados indefinidamente até que você os exclua.Consulta com a Pesquisa de arquivos: por fim, use a ferramenta
FileSearchem uma chamadagenerateContent. Na configuração da ferramenta, especifique umFileSearchRetrievalResource, que aponta para oFileSearchStoreque você quer pesquisar. Isso instrui o modelo a realizar uma pesquisa semântica no repositório específico da Pesquisa de arquivos para encontrar informações relevantes e embasar a resposta.
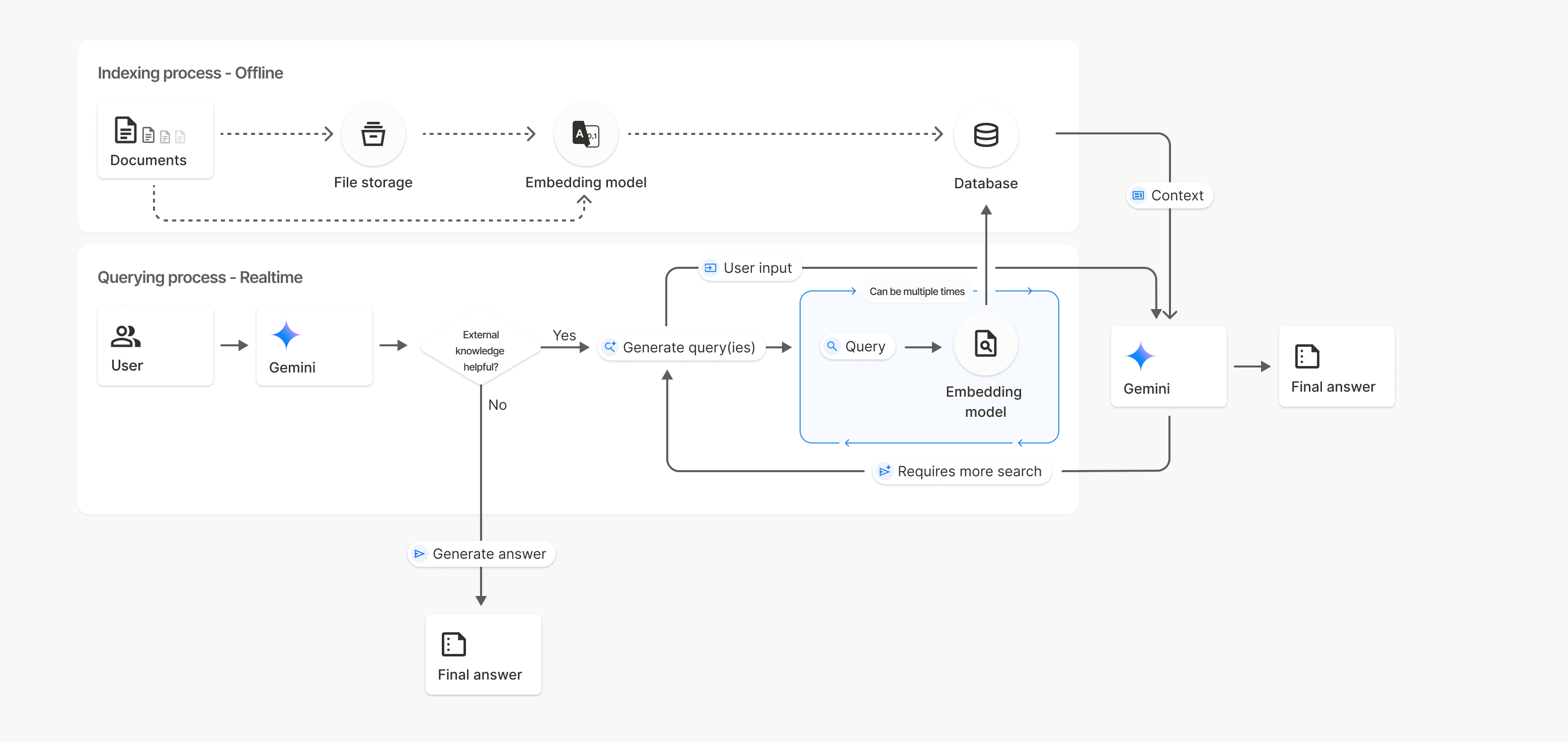
Neste diagrama, a linha pontilhada de Documentos para Modelo de incorporação
(usando gemini-embedding-001)
representa a API uploadToFileSearchStore (ignorando o Armazenamento de arquivos).
Caso contrário, usar a API Files para criar e importar arquivos separadamente move o processo de indexação de Documentos para Armazenamento de arquivos e, em seguida, para Modelo de incorporação.
Armazenamentos da Pesquisa de arquivos
Um repositório de pesquisa de arquivos é um contêiner para os embeddings de documentos. Os arquivos brutos enviados pela API File são excluídos após 48 horas, mas os dados importados para um repositório da Pesquisa de arquivos são armazenados indefinidamente até que você os exclua manualmente. Você pode criar várias lojas da Pesquisa de arquivos para organizar seus documentos. A API
FileSearchStore permite criar, listar, receber e excluir para gerenciar seus armazenamentos de
pesquisa de arquivos. Os nomes de armazenamento da Pesquisa de arquivos têm escopo global.
Confira alguns exemplos de como gerenciar suas lojas de pesquisa de arquivos:
Python
file_search_store = client.file_search_stores.create(
config={
'display_name': 'my-file_search-store-123',
'embedding_model': 'models/gemini-embedding-2'
}
)
for file_search_store in client.file_search_stores.list():
print(file_search_store)
my_file_search_store = client.file_search_stores.get(name='fileSearchStores/my-file_search-store-123')
client.file_search_stores.delete(name='fileSearchStores/my-file_search-store-123', config={'force': True})
JavaScript
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'my-file_search-store-123',
embeddingModel: 'models/gemini-embedding-2'
}
});
const fileSearchStores = await ai.fileSearchStores.list();
for await (const store of fileSearchStores) {
console.log(store);
}
const myFileSearchStore = await ai.fileSearchStores.get({
name: 'fileSearchStores/my-file_search-store-123'
});
await ai.fileSearchStores.delete({
name: 'fileSearchStores/my-file_search-store-123',
config: { force: true }
});
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}" \
-H "Content-Type: application/json" \
-d '{ "displayName": "My Store", "embedding_model": "models/gemini-embedding-2" }'
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}" \
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123?key=${GEMINI_API_KEY}"
curl -X DELETE "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123?key=${GEMINI_API_KEY}"
Documentos da pesquisa de arquivos
É possível gerenciar documentos individuais nos seus repositórios de arquivos com a
API File Search Documents para list cada documento
em um repositório de pesquisa de arquivos, get informações sobre um documento e delete um
documento por nome.
Python
for document_in_store in client.file_search_stores.documents.list(parent='fileSearchStores/my-file_search-store-123'):
print(document_in_store)
file_search_document = client.file_search_stores.documents.get(name='fileSearchStores/my-file_search-store-123/documents/my_doc')
print(file_search_document)
client.file_search_stores.documents.delete(name='fileSearchStores/my-file_search-store-123/documents/my_doc', config={'force': True})
JavaScript
const documents = await ai.fileSearchStores.documents.list({
parent: 'fileSearchStores/my-file_search-store-123'
});
for await (const doc of documents) {
console.log(doc);
}
const fileSearchDocument = await ai.fileSearchStores.documents.get({
name: 'fileSearchStores/my-file_search-store-123/documents/my_doc'
});
await ai.fileSearchStores.documents.delete({
name: 'fileSearchStores/my-file_search-store-123/documents/my_doc'
});
REST
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents?key=${GEMINI_API_KEY}"
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents/my_doc?key=${GEMINI_API_KEY}"
curl -X DELETE "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents/my_doc?key=${GEMINI_API_KEY}&force=true"
Metadados do arquivo
É possível adicionar metadados personalizados aos arquivos para ajudar a filtrá-los ou fornecer mais contexto. Os metadados são um conjunto de pares de chave-valor.
Python
op = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name,
config={
'custom_metadata': [
{"key": "author", "string_value": "Robert Graves"},
{"key": "year", "numeric_value": 1934}
]
}
)
JavaScript
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name,
config: {
customMetadata: [
{ key: "author", stringValue: "Robert Graves" },
{ key: "year", numericValue: 1934 }
]
}
});
Isso é útil quando você tem vários documentos em um repositório da Pesquisa de arquivos e quer pesquisar apenas um subconjunto deles.
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Tell me about the book 'I, Claudius'",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name],
"metadata_filter": 'author="Robert Graves"',
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Tell me about the book 'I, Claudius'",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name],
metadata_filter: 'author="Robert Graves"',
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
}
}
}
}
REST
curl "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"model": "gemini-3.5-flash",
"input": [{"type": "text", "text": "Tell me about the book I, Claudius"}],
"tools": [{
"type": "file_search",
"file_search_store_names": ["'$STORE_NAME'"],
"metadata_filter": "author = \"Robert Graves\""
}]
}' 2> /dev/null > response.json
cat response.json
As orientações sobre a implementação da sintaxe de filtro de lista para metadata_filter podem ser encontradas em google.aip.dev/160.
Pesquisa de arquivos multimodal
Com a pesquisa de arquivos multimodal, é possível incorporar e pesquisar imagens de forma nativa, o que permite aplicativos RAG multimodais avançados.
Configurar o modelo de embedding
Ao criar um FileSearchStore, é necessário substituir o modelo de embedding padrão somente de texto para usar um modelo multimodal. Use models/gemini-embedding-2 para
processar textos e imagens.
Python
store = client.file_search_stores.create(
config={
"display_name": "Multimodal Catalog",
"embedding_model": "models/gemini-embedding-2",
}
)
JavaScript
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: "Multimodal Catalog",
embeddingModel: "models/gemini-embedding-2",
},
});
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=$GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"display_name": "Multimodal Catalog",
"embedding_model": "models/gemini-embedding-2"
}'
Fazer upload de imagens
Depois de criar o repositório com um modelo de incorporação multimodal, você pode fazer upload de arquivos de imagem diretamente usando as mesmas APIs de upload descritas em Fazer upload diretamente para o repositório da Pesquisa de arquivos ou Importar arquivos.
Requisitos de arquivo de imagem:
- Os arquivos de imagem precisam ter resolução de até 4K x 4K pixels.
- Os formatos aceitos são PNG e JPEG.
Citações
Ao usar a Pesquisa de arquivos, a resposta do modelo pode incluir citações que especificam quais partes dos documentos enviados foram usadas para gerar a resposta. Isso ajuda na checagem de fatos e na verificação.
Você pode acessar as informações de citação pelo atributo annotations nos blocos content da etapa model_output da resposta.
Python
for step in interaction.steps:
if step.type == 'model_output':
for content in step.content:
if content.type == 'text' and content.annotations:
print(content.annotations)
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text' && contentBlock.annotations) {
console.log(JSON.stringify(contentBlock.annotations, null, 2));
}
}
}
}
Para informações detalhadas sobre a estrutura das citações, consulte a referência da API Interactions.
Números de página
Quando você usa a Pesquisa de arquivos com documentos que têm páginas (como PDFs), a resposta do modelo pode incluir o número da página em que as informações foram encontradas.
É possível acessar essas informações usando o atributo page_number de uma anotação file_citation.
Python
for step in interaction.steps:
if step.type == "model_output":
for content in step.content:
if content.type == "text" and content.annotations:
for annotation in content.annotations:
if annotation.type == "file_citation" and annotation.page_number:
print(f"Cited Page: {annotation.page_number}")
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const block of step.content) {
if (block.type === 'text' && block.annotations) {
for (const annotation of block.annotations) {
if (annotation.type === 'file_citation' && annotation.pageNumber) {
console.log(`Cited Page: ${annotation.pageNumber}`);
}
}
}
}
}
}
Citações de mídia
Quando o modelo faz referência a um trecho de imagem durante a geração, a API retorna uma
anotação do tipo file_citation nas anotações que incluem um media_id. Use esse ID para baixar o trecho exato da imagem referenciada pelo modelo. Esse media_id é
persistente em várias chamadas de pesquisa, o que permite recuperar de forma confiável
a mesma imagem ou armazená-la em cache usando o ID.
O snippet a seguir é um exemplo de etapa de resposta REST:
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"type": "file_citation",
"file_name": "product_image",
"media_id": "fileSearchStores/my-store-123/media/BlobId-456"
}
]
}
]
}
Os snippets de código a seguir demonstram como recuperar o media_id e
baixar a mídia:
Python
for step in interaction.steps:
if step.type == "model_output":
for content in step.content:
if content.type == "text" and content.annotations:
for annotation in content.annotations:
if annotation.type == "file_citation" and annotation.media_id:
print(f"Cited Media ID: {annotation.media_id}")
blob_content = client.file_search_stores.download_media(
media_id=annotation.media_id
)
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const block of step.content) {
if (block.type === 'text' && block.annotations) {
for (const annotation of block.annotations) {
if (annotation.type === 'file_citation' && annotation.mediaId) {
console.log(`Cited Media ID: ${annotation.mediaId}`);
const blobContent = await ai.fileSearchStores.downloadMedia(annotation.mediaId);
}
}
}
}
}
}
REST
curl -X GET "https://generativelanguage.googleapis.com/v1/fileSearchStores/my-store-123/media/BlobId-456" \
-H "x-goog-api-key: $GEMINI_API_KEY"
Metadados personalizados
Se você adicionou metadados personalizados aos seus arquivos, é possível acessá-los nas anotações da resposta do modelo. Isso é útil para transmitir contexto adicional (como URLs, números de página ou autores) dos documentos de origem para a lógica do aplicativo. Cada anotação de citação do tipo file_citation
contém esses metadados personalizados.
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.annotations:
for annotation in content_block.annotations:
print(annotation)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.annotations) {
contentBlock.annotations.forEach((annotation) => {
console.log(annotation);
});
}
}
}
}
REST
{
"steps": [
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"file_name": "...",
"source": "...",
"custom_metadata": [
{
"key": "author",
"string_value": "Robert Graves"
},
{
"key": "year",
"numeric_value": 1934
}
]
}
]
}
]
}
]
}
Resposta estruturada
A partir dos modelos do Gemini 3, é possível combinar a ferramenta de pesquisa de arquivos com saídas estruturadas.
Python
from pydantic import BaseModel, Field
class Money(BaseModel):
amount: str = Field(description="The numerical part of the amount.")
currency: str = Field(description="The currency of amount.")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="What is the minimum hourly wage in Tokyo right now?",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}],
response_format={
"type": "text",
"mime_type": "application/json",
"schema": Money.model_json_schema()
},
)
result = Money.model_validate_json(interaction.output_text)
print(result)
JavaScript
import { z } from "zod";
const moneyJsonSchema = {
type: "object",
properties: {
amount: { type: "string", description: "The numerical part of the amount." },
currency: { type: "string", description: "The currency of amount." }
},
required: ["amount", "currency"]
};
const moneySchema = z.fromJSONSchema(moneyJsonSchema);
async function run() {
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "What is the minimum hourly wage in Tokyo right now?",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name],
}],
response_format: {
type: 'text',
mime_type: 'application/json',
schema: moneyJsonSchema
},
});
const result = moneySchema.parse(JSON.parse(interaction.output_text));
console.log(result);
}
run();
REST
curl "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"model": "gemini-3.5-flash",
"input": "What is the minimum hourly wage in Tokyo right now?",
"tools": [{
"type": "file_search",
"file_search_store_names": ["$FILE_SEARCH_STORE_NAME"]
}],
"response_format": {
"type": "text",
"mime_type": "application/json",
"schema": {
"type": "object",
"properties": {
"amount": {"type": "string", "description": "The numerical part of the amount."},
"currency": {"type": "string", "description": "The currency of amount."}
},
"required": ["amount", "currency"]
}
}
}'
Modelos compatíveis
Os seguintes modelos são compatíveis com a Pesquisa de arquivos:
| Modelo | Pesquisa de arquivos |
|---|---|
| Gemini 3.5 Flash | ✔️ |
| Pré-lançamento do Gemini 3.1 Pro | ✔️ |
| Gemini 3.1 Flash-Lite | ✔️ |
| Pré-lançamento do Gemini 3 Flash | ✔️ |
| Gemini 2.5 Pro | ✔️ |
| Gemini 2.5 Flash-Lite | ✔️ |
Combinações de ferramentas compatíveis
Os modelos do Gemini 3 permitem combinar ferramentas integradas (como a Pesquisa de arquivos) com ferramentas personalizadas (chamada de função). Saiba mais na página de combinações de ferramentas.
Tipos de arquivo compatíveis
A Pesquisa de arquivos é compatível com vários formatos de arquivo, listados nas seções a seguir.
Tipos de arquivo de aplicativo
application/dartapplication/ecmascriptapplication/jsonapplication/ms-javaapplication/mswordapplication/pdfapplication/sqlapplication/typescriptapplication/vnd.curlapplication/vnd.dartapplication/vnd.ibm.secure-containerapplication/vnd.jupyterapplication/vnd.ms-excelapplication/vnd.oasis.opendocument.textapplication/vnd.openxmlformats-officedocument.presentationml.presentationapplication/vnd.openxmlformats-officedocument.spreadsheetml.sheetapplication/vnd.openxmlformats-officedocument.wordprocessingml.documentapplication/vnd.openxmlformats-officedocument.wordprocessingml.templateapplication/x-cshapplication/x-hwpapplication/x-hwp-v5application/x-latexapplication/x-phpapplication/x-powershellapplication/x-shapplication/x-shellscriptapplication/x-texapplication/x-zshapplication/xmlapplication/zip
Tipos de arquivos de texto
text/1d-interleaved-parityfectext/REDtext/SGMLtext/cache-manifesttext/calendartext/cqltext/cql-extensiontext/cql-identifiertext/csstext/csvtext/csv-schematext/dnstext/encaprtptext/enrichedtext/exampletext/fhirpathtext/flexfectext/fwdredtext/gff3text/grammar-ref-listtext/hl7v2text/htmltext/javascripttext/jcr-cndtext/jsxtext/markdowntext/mizartext/n3text/parameterstext/parityfectext/phptext/plaintext/provenance-notationtext/prs.fallenstein.rsttext/prs.lines.tagtext/prs.prop.logictext/raptorfectext/rfc822-headerstext/rtftext/rtp-enc-aescm128text/rtploopbacktext/rtxtext/sgmltext/shaclctext/shextext/spdxtext/stringstext/t140text/tab-separated-valuestext/texmacstext/trofftext/tsvtext/tsxtext/turtletext/ulpfectext/uri-listtext/vcardtext/vnd.DMClientScripttext/vnd.IPTC.NITFtext/vnd.IPTC.NewsMLtext/vnd.atext/vnd.abctext/vnd.ascii-arttext/vnd.curltext/vnd.debian.copyrighttext/vnd.dvb.subtitletext/vnd.esmertec.theme-descriptortext/vnd.exchangeabletext/vnd.familysearch.gedcomtext/vnd.ficlab.flttext/vnd.flytext/vnd.fmi.flexstortext/vnd.gmltext/vnd.graphviztext/vnd.hanstext/vnd.hgltext/vnd.in3d.3dmltext/vnd.in3d.spottext/vnd.latex-ztext/vnd.motorola.reflextext/vnd.ms-mediapackagetext/vnd.net2phone.commcenter.commandtext/vnd.radisys.msml-basic-layouttext/vnd.senx.warpscripttext/vnd.sositext/vnd.sun.j2me.app-descriptortext/vnd.trolltech.linguisttext/vnd.wap.sitext/vnd.wap.sltext/vnd.wap.wmltext/vnd.wap.wmlscripttext/vtttext/wgsltext/x-asmtext/x-bibtextext/x-bootext/x-ctext/x-c++hdrtext/x-c++srctext/x-cassandratext/x-chdrtext/x-coffeescripttext/x-componenttext/x-cshtext/x-csharptext/x-csrctext/x-cudatext/x-dtext/x-difftext/x-dsrctext/x-emacs-lisptext/x-erlangtext/x-gff3text/x-gotext/x-haskelltext/x-javatext/x-java-propertiestext/x-java-sourcetext/x-kotlintext/x-lilypondtext/x-lisptext/x-literate-haskelltext/x-luatext/x-moctext/x-objcsrctext/x-pascaltext/x-pcs-gcdtext/x-perltext/x-perl-scripttext/x-pythontext/x-python-scripttext/x-r-markdowntext/x-rsrctext/x-rsttext/x-ruby-scripttext/x-rusttext/x-sasstext/x-scalatext/x-schemetext/x-script.pythontext/x-scsstext/x-setexttext/x-sfvtext/x-shtext/x-siestatext/x-sostext/x-sqltext/x-swifttext/x-tcltext/x-textext/x-vbasictext/x-vcalendartext/xmltext/xml-dtdtext/xml-external-parsed-entitytext/yaml
Limitações
- API Live:a Pesquisa de arquivos não é compatível com a API Live.
- Incompatibilidade de ferramentas:a Pesquisa de arquivos não pode ser combinada com outras ferramentas, como Embasamento com a Pesquisa Google, Contexto do URL etc. no momento.
Limites de taxas
A API File Search tem os seguintes limites para garantir a estabilidade do serviço:
- Tamanho máximo do arquivo / limite por documento: 100 MB
- Tamanho total dos armazenamentos da Pesquisa de arquivos do projeto (com base no nível do usuário):
- Sem custo financeiro: 1 GB
- Nível 1: 10 GB
- Nível 2: 100 GB
- Nível 3: 1 TB
- Recomendação: limite o tamanho de cada repositório de pesquisa de arquivos para menos de 20 GB e garanta latências de recuperação ideais.
Preços
- Você recebe uma cobrança por incorporações no momento da indexação com base nos preços de incorporação atuais.
- O armazenamento não tem custo financeiro.
- Os embeddings de tempo de consulta não têm custo financeiro.
- Os tokens de documentos recuperados são cobrados como tokens de contexto normais.
A seguir
- Acesse a referência da API para File Search Stores e Documents da Pesquisa de arquivos.