Gemini Robotics-ER 1.6 是一种视觉语言模型 (VLM),可将 Gemini 的智能体功能引入机器人技术。它专为物理世界中的高级推理而设计,可让机器人解读复杂的视觉数据、执行空间推理,并根据自然语言命令规划行动。
请注意,如果您使用的是 Gemini Robotics-ER 1.5,则可以在 API 调用中将模型名称从 model="gemini-robotics-er-1.5-preview"
替换为 model="gemini-robotics-er-1.6-preview",从而开始使用 1.6
模型。
主要功能和优势:
- 增强的自主性: 机器人可以推理、适应并响应开放式环境中的变化。
- 自然语言互动: 通过使用自然语言执行复杂的任务分配,让机器人更易于使用。
- 任务编排: 将自然语言命令分解为子任务,并与现有的机器人控制器和行为集成,以完成长期任务。
- 多功能: 定位和识别对象、理解对象关系、规划抓取和轨迹,以及解读动态场景。
本文档介绍了模型的功能,并通过几个示例重点介绍了模型的 智能体功能。
如果您想立即开始使用,可以在 Google AI Studio 中试用该模型。
安全
虽然 Gemini Robotics-ER 1.6 在构建时考虑到了安全性,但您有责任维护机器人周围的安全环境。生成式 AI 模型可能会出错,而实体机器人可能会造成损坏。安全是重中之重,在与现实世界中的机器人技术结合使用时,确保生成式 AI 模型的安全性是我们研究的一个积极且至关重要的领域。如需了解详情,请访问 Google DeepMind 机器人技术安全页面。
入门:在场景中查找对象
以下示例演示了一个常见的机器人技术用例。它展示了如何
使用
generateContent
方法将图片和文本提示传递给模型,以获取已识别对象的列表及其对应的 2D 点。
该模型会返回其在图片中识别出的项的点,并返回这些项的标准化 2D 坐标和标签。
您可以将此输出与机器人技术 API 结合使用,也可以调用视觉语言行动 (VLA) 模型或任何其他第三方用户定义的函数,以生成供机器人执行的行动。
Python
from google import genai
from google.genai import types
PROMPT = """
Point to no more than 10 items in the image. The label returned
should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format
normalized to 0-1000.
"""
client = genai.Client()
# Load your image
with open("my-image.png", 'rb') as f:
image_bytes = f.read()
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/png',
),
PROMPT
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
REST
# First, ensure you have the image file locally.
# Encode the image to base64
IMAGE_BASE64=$(base64 -w 0 my-image.png)
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-robotics-er-1.6-preview:generateContent \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{
"parts": [
{
"inlineData": {
"mimeType": "image/png",
"data": "'"${IMAGE_BASE64}"'"
}
},
{
"text": "Point to no more than 10 items in the image. The label returned should be an identifying name for the object detected. The answer should follow the json format: [{\"point\": [y, x], \"label\": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000."
}
]
}
],
"generationConfig": {
"temperature": 0.5,
"thinkingConfig": {
"thinkingBudget": 0
}
}
}'
输出将是一个包含对象的 JSON 数组,每个对象都有一个 point(标准化 [y, x] 坐标)和一个用于标识对象的 label。
JSON
[
{"point": [376, 508], "label": "small banana"},
{"point": [287, 609], "label": "larger banana"},
{"point": [223, 303], "label": "pink starfruit"},
{"point": [435, 172], "label": "paper bag"},
{"point": [270, 786], "label": "green plastic bowl"},
{"point": [488, 775], "label": "metal measuring cup"},
{"point": [673, 580], "label": "dark blue bowl"},
{"point": [471, 353], "label": "light blue bowl"},
{"point": [492, 497], "label": "bread"},
{"point": [525, 429], "label": "lime"}
]
下图展示了如何显示这些点:

运作方式
Gemini Robotics-ER 1.6 可让机器人利用空间理解能力在物理世界中进行情境化和工作。它会接收图片/视频/音频输入和自然语言提示,以执行以下操作:
- 理解对象和场景上下文:识别对象,并推理 对象与场景的关系,包括对象的功能。
- 理解任务说明:解读以自然语言给出的任务,例如“找到香蕉”。
- 进行空间和时间推理:理解行动序列以及对象如何随时间与场景互动。
- 提供结构化输出:返回表示对象位置的坐标(点或边界框)。
这样,机器人就可以通过编程方式“看到”和“理解”其环境。
Gemini Robotics-ER 1.6 还具有智能体功能,这意味着它可以将复杂任务(例如“将苹果放入碗中”)分解为子任务,以编排长期任务:
- 子任务排序:将命令分解为一系列逻辑 步骤。
- 函数调用/代码执行:通过调用现有的 机器人函数/工具或执行生成的代码来执行步骤。
如需详细了解如何使用 Gemini 进行函数调用,请参阅函数调用 页面。
将思考预算与 Gemini Robotics-ER 1.6 结合使用
Gemini Robotics-ER 1.6 具有灵活的思考预算,可让您控制延迟时间与准确率之间的权衡。对于对象检测等空间理解任务,该模型只需少量思考预算即可实现高性能。对于计数和重量估计等更复杂的推理任务,则需要更多的思考预算。这样,您就可以在低延迟响应的需求与更具挑战性的任务的高准确率结果之间取得平衡。
如需详细了解思考预算,请参阅 思考 核心功能页面。
标准空间推理
以下示例演示了使用自然语言提示执行的机器人感知 和空间推理任务,范围从在图片中指向和查找对象到规划轨迹。为简单起见,这些示例中的代码段已缩减,仅显示提示和对 generate_content API 的调用。
如需查看完整的可运行代码以及 更多示例,请参阅 机器人技术实用手册。
指向对象
在图片或视频帧中指向和查找对象是机器人技术中视觉语言模型 (VLM) 的常见用例。以下示例要求模型在图片中查找特定对象并返回其坐标。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
queries = [
"bread",
"starfruit",
"banana",
]
prompt = f"""
Get all points matching the following objects: {', '.join(queries)}. The
label returned should be an identifying name for the object detected.
The answer should follow the json format:
[{{"point": , "label": }}, ...]. The points are in
[y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
输出将与入门示例类似,是一个包含找到的对象的坐标及其标签的 JSON。
[
{"point": [671, 317], "label": "bread"},
{"point": [738, 307], "label": "bread"},
{"point": [702, 237], "label": "bread"},
{"point": [629, 307], "label": "bread"},
{"point": [833, 800], "label": "bread"},
{"point": [609, 663], "label": "banana"},
{"point": [770, 483], "label": "starfruit"}
]

使用以下提示要求模型解读“水果”等抽象类别,而不是特定对象,并在图片中找到所有实例。
Python
prompt = f"""
Get all points for fruit. The label returned should be an identifying
name for the object detected.
""" + """The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...]. The points are in
[y, x] format normalized to 0-1000."""
如需了解 其他图片处理技术,请访问图片理解页面。
跟踪视频中的对象
Gemini Robotics-ER 1.6 还可以分析视频帧,以跟踪对象随时间的变化。如需查看支持的视频格式列表,请参阅视频输入 。
以下是用于在模型分析的每个帧中查找特定对象的基本提示:
Python
# Define the objects to find
queries = [
"pen (on desk)",
"pen (in robot hand)",
"laptop (opened)",
"laptop (closed)",
]
base_prompt = f"""
Point to the following objects in the provided image: {', '.join(queries)}.
The answer should follow the json format:
[{{"point": , "label": }}, ...].
The points are in [y, x] format normalized to 0-1000.
If no objects are found, return an empty JSON list [].
"""
输出显示了在视频帧中跟踪的笔和笔记本电脑。
![]()
如需查看完整的可运行代码,请参阅 机器人技术实用手册。
对象检测和边界框
除了单个点之外,该模型还可以返回 2D 边界框,提供一个包含对象的矩形区域。
此示例请求为桌面上可识别的对象提供 2D 边界框。该模型被指示将输出限制为 25 个对象,并为多个实例指定唯一名称。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return bounding boxes as a JSON array with labels. Never return masks
or code fencing. Limit to 25 objects. Include as many objects as you
can identify on the table.
If an object is present multiple times, name them according to their
unique characteristic (colors, size, position, unique characteristics, etc..).
The format should be as follows: [{"box_2d": [ymin, xmin, ymax, xmax],
"label": <label for the object>}] normalized to 0-1000. The values in
box_2d must only be integers
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
以下显示了模型返回的框。
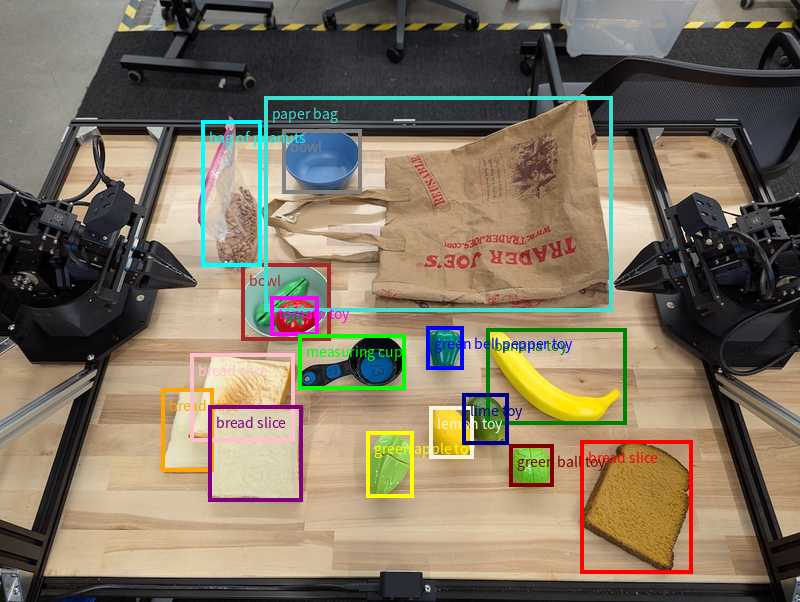
如需查看完整的可运行代码,请参阅机器人技术 实用手册。 图片理解页面还提供了 其他视觉任务示例,例如对象检测和 边界框示例。
轨迹
Gemini Robotics-ER 1.6 可以生成定义轨迹的点序列,这对于引导机器人移动非常有用。
此示例请求生成将红笔移动到收纳盒的轨迹,包括起点和一系列中间点。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
points_data = []
prompt = """
Place a point on the red pen, then 15 points for the trajectory of
moving the red pen to the top of the organizer on the left.
The points should be labeled by order of the trajectory, from '0'
(start point at left hand) to <n> (final point)
The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(image_response.text)
响应是一组坐标,用于描述红笔应遵循的路径轨迹,以完成将其移动到收纳盒上的任务:
[
{"point": [550, 610], "label": "0"},
{"point": [500, 600], "label": "1"},
{"point": [450, 590], "label": "2"},
{"point": [400, 580], "label": "3"},
{"point": [350, 550], "label": "4"},
{"point": [300, 520], "label": "5"},
{"point": [250, 490], "label": "6"},
{"point": [200, 460], "label": "7"},
{"point": [180, 430], "label": "8"},
{"point": [160, 400], "label": "9"},
{"point": [140, 370], "label": "10"},
{"point": [120, 340], "label": "11"},
{"point": [110, 320], "label": "12"},
{"point": [105, 310], "label": "13"},
{"point": [100, 305], "label": "14"},
{"point": [100, 300], "label": "15"}
]

智能体功能
以下示例演示了如何使用模型的智能体功能(特别是代码执行 )进行高级机器人推理 。在这些场景中,模型可以决定编写和执行 Python 代码来处理图片(例如放大、裁剪或旋转),以消除歧义或提高准确率,然后再回答。
对象检测(缩放和裁剪)
以下示例演示了如何在检测对象和返回边界框时使用代码执行来缩放和裁剪图片,以便更清晰地查看。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return JSON in the format {label: val, y: val, x: val, y2: val, x2: val} for
the compostable objects in this scene. Please Zoom and crop the image for a
clearer view. Return an annotated image of the final result with the bounding
boxes drawn on it to the API caller as a part of your process.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
模型输出将类似于以下内容:
[
{"label": "compostable", "y": 256, "x": 482, "y2": 295, "x2": 546},
{"label": "compostable", "y": 317, "x": 478, "y2": 350, "x2": 542},
{"label": "compostable", "y": 586, "x": 556, "y2": 668, "x2": 595},
{"label": "compostable", "y": 463, "x": 669, "y2": 511, "x2": 718},
{"label": "compostable", "y": 178, "x": 565, "y2": 250, "x2": 609}
]
以下显示了模型返回的框。

读取模拟仪表并应用逻辑
以下示例演示了如何使用模型读取模拟仪表并执行时间计算。它使用系统指令来强制执行 JSON 输出。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('clock.jpg', 'rb') as f:
image_bytes = f.read()
q_time = """
Tell me what the value is. Please respond in the following JSON format:\n {\n "hours": X,\n "minutes": Y,\n}. Zoom in or crop as necessary to confirm location of the clock hands.
"""
system_instruction = "Be precise. When JSON is requested, reply with ONLY that JSON (no preface, no code block)."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
system_instruction + " " + q_time
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(response.text)
以下是输入图片示例。

模型输出将类似于以下内容:
Time Response: {
"hours": 12,
"minutes": 44
}
测量容器中的液体
以下示例展示了如何使用代码执行来读取仪表并以百分比形式计算液位。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('meter.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
How full is the meter of liquid?
To read it,
1) Find the points for the top of the sight window, bottom of the sight window and the liquid level, formatted as [y, x] with values ranging from 0-1000;
2) Use math to determine the liquid level as a percentage;
3) Output "Answer: ??" on a separate line, where ?? is a number without % or unit.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
以下是输入的放大图片。

读取电路板上的标记
以下示例演示了如何使用代码执行来读取电路板芯片上的文本,从而让模型根据需要缩放、裁剪和旋转图片。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('circuit_board.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = "What is the number on the ESMT chip? Zoom, crop, and rotate if needed."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
以下是输入的放大图片。

图片注解
以下示例演示了如何使用代码执行来注解图片(例如,绘制箭头以提供处置说明)并返回修改后的图片。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Look at this image and return it as an annotated version using arrows of
different colors to represent which items should go in which bins for
disposal. You must return the final image to the API caller.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
以下是输入图片示例。

模型输出将类似于以下内容:
The annotated image shows the suggested disposal locations for the items on the table:
- **Green bin (Compost/Organic)**: Green chili, red chili, grapes, and cherries.
- **Blue bin (Recycling)**: Yellow crushed can and plastic container.
- **Black bin (Trash)**: Chocolate bar wrapper, Welch's packet, and white tissue.
编排
Gemini Robotics-ER 1.6 可以执行任务规划 和更高级别的空间推理,根据上下文理解来推断行动或识别最佳位置,从而编排长期任务。
为笔记本电脑腾出空间
此示例展示了 Gemini Robotics-ER 如何推理空间。提示要求模型识别需要移动哪个对象才能为另一个项腾出空间。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Point to the object that I need to remove to make room for my laptop
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
响应包含回答用户问题的对象的 2D 坐标,在本例中,该对象应移动以腾出空间放置笔记本电脑。
[
{"point": [672, 301], "label": "The object that I need to remove to make room for my laptop"}
]

打包午餐
该模型还可以为多步骤任务提供说明,并为每个步骤指向相关对象。此示例展示了该模型如何规划一系列步骤来打包午餐袋。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-of-lunch.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Explain how to pack the lunch box and lunch bag. Point to each
object that you refer to. Each point should be in the format:
[{"point": [y, x], "label": }], where the coordinates are
normalized between 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
此提示的响应是一组关于如何根据输入图片打包午餐袋的分步说明。
输入图片

模型输出
Based on the image, here is a plan to pack the lunch box and lunch bag:
1. **Pack the fruit into the lunch box.** Place the [apple](apple), [banana](banana), [red grapes](red grapes), and [green grapes](green grapes) into the [blue lunch box](blue lunch box).
2. **Add the spoon to the lunch box.** Put the [blue spoon](blue spoon) inside the lunch box as well.
3. **Close the lunch box.** Secure the lid on the [blue lunch box](blue lunch box).
4. **Place the lunch box inside the lunch bag.** Put the closed [blue lunch box](blue lunch box) into the [brown lunch bag](brown lunch bag).
5. **Pack the remaining items into the lunch bag.** Place the [blue snack bar](blue snack bar) and the [brown snack bar](brown snack bar) into the [brown lunch bag](brown lunch bag).
Here is the list of objects and their locations:
* [{"point": [899, 440], "label": "apple"}]
* [{"point": [814, 363], "label": "banana"}]
* [{"point": [727, 470], "label": "red grapes"}]
* [{"point": [675, 608], "label": "green grapes"}]
* [{"point": [706, 529], "label": "blue lunch box"}]
* [{"point": [864, 517], "label": "blue spoon"}]
* [{"point": [499, 401], "label": "blue snack bar"}]
* [{"point": [614, 705], "label": "brown snack bar"}]
* [{"point": [448, 501], "label": "brown lunch bag"}]
调用自定义机器人技术 API
此示例演示了如何使用自定义机器人技术 API 进行任务编排。它引入了一个专为拾取和放置操作设计的模拟 API。任务是拾取一个蓝色方块并将其放入橙色碗中:

与本页上的其他示例类似,完整的可运行代码可在 机器人技术实用手册中找到。
第一步是使用以下提示找到这两个项:
Python
prompt = """
Locate and point to the blue block and the orange bowl. The label
returned should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
模型响应包括方块和碗的标准化坐标:
[
{"point": [389, 252], "label": "orange bowl"},
{"point": [727, 659], "label": "blue block"}
]
此示例使用以下模拟机器人技术 API:
Python
def move(x, y, high):
print(f"moving to coordinates: {x}, {y}, {15 if high else 5}")
def setGripperState(opened):
print("Opening gripper" if opened else "Closing gripper")
def returnToOrigin():
print("Returning to origin pose")
下一步是调用一系列 API 函数,其中包含执行操作所需的逻辑。以下提示包含模型在编排此任务时应使用的机器人技术 API 的说明。
Python
prompt = f"""
You are a robotic arm with six degrees-of-freedom. You have the
following functions available to you:
def move(x, y, high):
# moves the arm to the given coordinates. The boolean value 'high' set
to True means the robot arm should be lifted above the scene for
avoiding obstacles during motion. 'high' set to False means the robot
arm should have the gripper placed on the surface for interacting with
objects.
def setGripperState(opened):
# Opens the gripper if opened set to true, otherwise closes the gripper
def returnToOrigin():
# Returns the robot to an initial state. Should be called as a cleanup
operation.
The origin point for calculating the moves is at normalized point
y={robot_origin_y}, x={robot_origin_x}. Use this as the new (0,0) for
calculating moves, allowing x and y to be negative.
Perform a pick and place operation where you pick up the blue block at
normalized coordinates ({block_x}, {block_y}) (relative coordinates:
{block_relative_x}, {block_relative_y}) and place it into the orange
bowl at normalized coordinates ({bowl_x}, {bowl_y})
(relative coordinates: {bowl_relative_x}, {bowl_relative_y}).
Provide the sequence of function calls as a JSON list of objects, where
each object has a "function" key (the function name) and an "args" key
(a list of arguments for the function).
Also, include your reasoning before the JSON output.
For example:
Reasoning: To pick up the block, I will first move the arm to a high
position above the block, open the gripper, move down to the block,
close the gripper, lift the arm, move to a high position above the bowl,
move down to the bowl, open the gripper, and then lift the arm back to
a high position.
"""
以下显示了模型基于提示和模拟机器人技术 API 的可能输出。输出包括模型的思考过程及其规划的任务。它还显示了模型按顺序调用的机器人函数调用的输出。
Reasoning: To perform the pick and place operation, I will first move the
robotic arm to a high position above the blue block to ensure clearance. Then, I
will open the gripper in preparation for grasping. Next, I will lower the arm to
the surface level to position the gripper around the block and close the gripper
to secure it. After picking up the block, I will lift the arm to clear the
surface and move towards the orange bowl, maintaining a high position to avoid
collisions. Once positioned above the bowl, I will lower the arm to place the
block inside. I will then open the gripper to release the block. Finally, I will
lift the arm out of the bowl and call `returnToOrigin` to reset the robot's
state.
[
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
163,
427,
false
]
},
{
"function": "setGripperState",
"args": [
false
]
},
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "move",
"args": [
-247,
90,
false
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "returnToOrigin",
"args": []
}
]
Executing Function Calls:
moving to coordinates: 163, 427, 15
Opening gripper
moving to coordinates: 163, 427, 5
Closing gripper
moving to coordinates: 163, 427, 15
moving to coordinates: -247, 90, 15
moving to coordinates: -247, 90, 5
Opening gripper
moving to coordinates: -247, 90, 15
Returning to origin pose
最佳实践
为了优化机器人技术应用的性能和准确率,了解如何有效地与 Gemini 模型互动至关重要。本部分概述了制定提示、处理视觉数据和构建任务的最佳实践和关键策略,以获得最可靠的结果。
使用清晰简洁的语言。
使用自然语言:Gemini 模型旨在理解 自然的对话语言。以语义清晰的方式构建提示,并模仿人们自然给出说明的方式。
使用日常术语:选择使用常见的日常语言,而不是 技术或专业术语。如果模型对某个特定术语的响应不符合预期,请尝试使用更常见的同义词重新措辞。
优化视觉输入。
放大以查看详细信息:在处理较小或 难以在广角镜头中辨别的对象时,请使用边界框函数来 隔离感兴趣的对象。然后,您可以将图片剪裁为该选择,并将新的聚焦图片发送给模型以进行更详细的分析。
尝试不同的光照和颜色:模型感知可能会受到 具有挑战性的光照条件和较差的颜色对比度的影响。
将复杂问题分解为较小的步骤。通过单独处理每个较小的步骤,您可以引导模型获得更准确、更成功的结果。
通过共识提高准确率。对于需要高准确率的任务,您可以使用相同的提示多次查询模型。通过对返回的结果取平均值,您可以得出通常更准确、更可靠的“共识”。
限制
使用 Gemini Robotics-ER 1.6 进行开发时,请考虑以下限制:
- 预览版状态: 该模型目前处于预览版 阶段。API 和功能可能会发生变化,未经全面测试可能不适合对生产至关重要的应用。
- 延迟时间: 复杂的查询、高分辨率输入或大量的
thinking_budget可能会导致处理时间增加。 - 幻觉: 与所有大型语言模型一样,Gemini Robotics-ER 1.6 有时可能会“产生幻觉”或提供不正确的信息,尤其是在提示不明确或输入超出分布范围时。
- 依赖于提示质量: 模型输出的质量高度依赖于输入提示的清晰度和具体性。模糊或结构不佳的提示可能会导致结果不理想。
- 计算费用: 运行模型(尤其是使用视频输入或大量
thinking_budget)会消耗计算资源并产生费用。 如需了解详情,请参阅思考页面。 - 输入类型: 如需详细了解每种模式的限制,请参阅以下主题。
隐私权声明
您承认,本文档中提及的模型(“机器人技术模型”)会利用视频和音频数据,以便根据您的说明操作和移动您的硬件。因此,您可能会以这种方式操作机器人技术模型,以便机器人技术模型收集可识别个人的数据,例如语音、图像和肖像数据(“个人数据”)。如果您选择以收集 个人数据的方式操作机器人技术模型,则表示您同意,除非且直到可识别个人已充分了解并同意其个人数据可能会按照 Gemini API 附加服务条款(网址为 https://ai.google.dev/gemini-api/terms ,简称“条款”)中的规定提供给 Google 并由 Google 使用(包括按照标题为“Google 如何使用您的数据”的部分中的规定),否则您不会允许任何可识别个人与机器人技术模型互动或出现在机器人技术模型周围的区域。您将确保此类通知允许按照条款中的规定收集和使用个人数据,并且您将尽商业上合理的努力,通过使用面部模糊等技术以及在不包含可识别个人的区域操作机器人技术模型(在切实可行的情况下),尽可能减少个人数据的收集和分发。
价格
如需详细了解价格和可用区域,请参阅 价格页面。
模型版本
Robotics-ER 1.6 预览版
| 属性 | 说明 |
|---|---|
| 模型代码 | gemini-robotics-er-1.6-preview |
| 支持的数据类型 |
输入 文本、图片、视频、音频 输出 文本 |
| Token 限制[*] |
输入 token 限制 131,072 输出 token 限制 65,536 |
| 功能 | 不支持 支持 支持 支持 支持 支持 支持 不支持 不支持 支持 支持 支持 支持 |
| 消耗选项 |
支持 支持 支持 |
| 版本 |
|
| 上次更新时间 | 2025 年 12 月 |
| 知识截点 | 2025 年 1 月 |
后续步骤
- 探索其他功能,并继续尝试不同的提示和输入,以发现 Gemini Robotics-ER 1.6 的更多应用。 如需查看更多示例,请参阅机器人技术入门 Colab 。
- 了解 Gemini Robotics 模型在构建时如何考虑安全性,请访问 Google DeepMind 机器人技术安全 页面。
- 如需了解 Gemini Robotics 模型的最新更新,请参阅 Gemini Robotics 着陆页。