توفّر Gemini API إعدادات أمان يمكنك تعديلها خلال مرحلة إنشاء النموذج الأولي لتحديد ما إذا كان تطبيقك يتطلّب إعدادات أمان أكثر أو أقل تقييدًا. يمكنك تعديل هذه الإعدادات في أربع فئات فلاتر لحظر أنواع معيّنة من المحتوى أو السماح بها.
يشرح هذا الدليل كيفية تعامل Gemini API مع إعدادات الأمان والفلترة، وكيف يمكنك تغيير إعدادات الأمان لتطبيقك.
فلاتر الأمان
تغطّي فلاتر الأمان القابلة للضبط في Gemini API الفئات التالية:
| الفئة | الوصف |
|---|---|
| التحرش | تعليقات سلبية أو ضارة تستهدف الهوية و/أو السمات المحمية |
| الكلام الذي يحضّ على الكراهية | محتوى وقح أو غير محترم أو بذيء |
| محتوى جنسي فاضح | محتوى يشير إلى أفعال جنسية أو محتوى فاحش آخر |
| الفئات الخطيرة | محتوى يروّج لأفعال ضارة أو يسهّلها أو يشجّع عليها |
يتم تحديد هذه الفئات في HarmCategory. يمكنك استخدام هذه الفلاتر لتعديل المحتوى المناسب لحالة الاستخدام. على سبيل المثال، إذا كنت تنشئ حوارًا للعبة فيديو، قد تعتبر أنّه من المقبول السماح بمزيد من المحتوى الذي تم تقييمه على أنّه خطير بسبب طبيعة اللعبة.
بالإضافة إلى فلاتر الأمان القابلة للضبط، تتضمّن Gemini API وسائل حماية مضمّنة ضد الأضرار الأساسية، مثل المحتوى الذي يعرّض سلامة الأطفال للخطر. يتم حظر هذه الأنواع من الأضرار دائمًا ولا يمكن تعديلها.
مستوى فلترة المحتوى من حيث الأمان
تصنّف Gemini API مستوى احتمالية أن يكون المحتوى غير آمن على أنّه HIGH أو MEDIUM أو LOW أو NEGLIGIBLE.
تحظر Gemini API المحتوى استنادًا إلى احتمالية أن يكون المحتوى غير آمن وليس استنادًا إلى مدى خطورته. من المهم أخذ ذلك في الاعتبار لأنّ بعض المحتوى قد يكون لديه احتمالية منخفضة بأن يكون غير آمن على الرغم من أنّ مدى الضرر قد يظل مرتفعًا. على سبيل المثال، عند مقارنة الجملتين:
- ضربني الروبوت.
- قطعني الروبوت.
قد تؤدي الجملة الأولى إلى احتمالية أعلى بأن تكون غير آمنة، ولكن قد تعتبر الجملة الثانية أكثر خطورة من حيث العنف. في ضوء ذلك، من المهم إجراء اختبار دقيق وتحديد مستوى الحظر المناسب المطلوب لدعم حالات الاستخدام الرئيسية مع تقليل الضرر الذي يلحق بالمستخدمين النهائيين.
فلترة الأمان لكل طلب
يمكنك تعديل إعدادات الأمان لكل طلب ترسله إلى واجهة برمجة التطبيقات. عند إرسال طلب، يتم تحليل المحتوى وتعيين تقييم أمان له. يتضمّن تقييم الأمان الفئة واحتمالية تصنيف الضرر. على سبيل المثال، إذا تم حظر المحتوى بسبب احتمالية عالية لفئة التحرش، سيكون تقييم الأمان الذي يتم عرضه من الفئة HARASSMENT، وسيتم ضبط احتمالية الضرر على HIGH.
بسبب الأمان المتأصّل في النموذج، تكون الفلاتر الإضافية غير مفعّلة تلقائيًا. إذا اخترت تفعيلها، يمكنك ضبط النظام لحظر المحتوى استنادًا إلى احتمالية أن يكون غير آمن. يغطّي السلوك التلقائي للنموذج معظم حالات الاستخدام، لذا عليك تعديل هذه الإعدادات فقط إذا كان ذلك مطلوبًا باستمرار لتطبيقك.
يصف الجدول التالي إعدادات الحظر التي يمكنك تعديلها لكل فئة. على سبيل المثال، إذا ضبطت إعداد الحظر على حظر القليل لفئة الكلام الذي يحضّ على الكراهية، يتم حظر كل المحتوى الذي لديه احتمالية عالية بأن يكون كلامًا يحضّ على الكراهية. ولكن يُسمح بأي محتوى لديه احتمالية أقل.
| الحدّ (Google AI Studio) | الحدّ (واجهة برمجة التطبيقات) | الوصف |
|---|---|---|
| إيقاف | OFF |
إيقاف فلتر الأمان |
| بدون حظر | BLOCK_NONE |
العرض دائمًا بغض النظر عن احتمالية أن يكون المحتوى غير آمن |
| حظر القليل | BLOCK_ONLY_HIGH |
الحظر عند وجود احتمالية عالية بأن يكون المحتوى غير آمن |
| حظر بعض المحتوى | BLOCK_MEDIUM_AND_ABOVE |
الحظر عند وجود احتمالية متوسطة أو عالية بأن يكون المحتوى غير آمن |
| حظر معظم المحتوى | BLOCK_LOW_AND_ABOVE |
الحظر عند وجود احتمالية منخفضة أو متوسطة أو عالية بأن يكون المحتوى غير آمن |
| لا ينطبق | HARM_BLOCK_THRESHOLD_UNSPECIFIED |
لم يتم تحديد الحدّ، ويتم الحظر باستخدام الحدّ التلقائي |
إذا لم يتم ضبط الحدّ، يكون الحدّ التلقائي للحظر إيقاف لطرازَي Gemini 2.5 و3.
يمكنك ضبط هذه الإعدادات لكل طلب ترسله إلى الخدمة التوليدية.
لمزيد من التفاصيل، يُرجى الاطّلاع على مرجع واجهة برمجة التطبيقات HarmBlockThreshold.
ملاحظات الأمان
generateContent
تعرض الدالة
GenerateContentResponse يتضمّن ملاحظات الأمان.
يتم تضمين ملاحظات الطلب في
promptFeedback. إذا تم ضبط promptFeedback.blockReason، يعني ذلك أنّه تم حظر محتوى الطلب.
يتم تضمين ملاحظات المرشّح للردّ في
Candidate.finishReason و
Candidate.safetyRatings. إذا تم حظر محتوى الردّ وكان finishReason هو SAFETY، يمكنك فحص safetyRatings للحصول على مزيد من التفاصيل. لا يتم عرض المحتوى الذي تم حظره.
تعديل إعدادات الأمان
يشرح هذا القسم كيفية تعديل إعدادات الأمان في كل من Google AI Studio وفي الرمز البرمجي.
Google AI Studio
يمكنك تعديل إعدادات الأمان في Google AI Studio.
انقر على إعدادات الأمان ضمن الإعدادات المتقدّمة في لوحة إعدادات التشغيل لفتح النافذة المنبثقة تشغيل إعدادات الأمان. في النافذة المنبثقة، يمكنك استخدام أشرطة التمرير لتعديل مستوى فلترة المحتوى لكل فئة أمان:
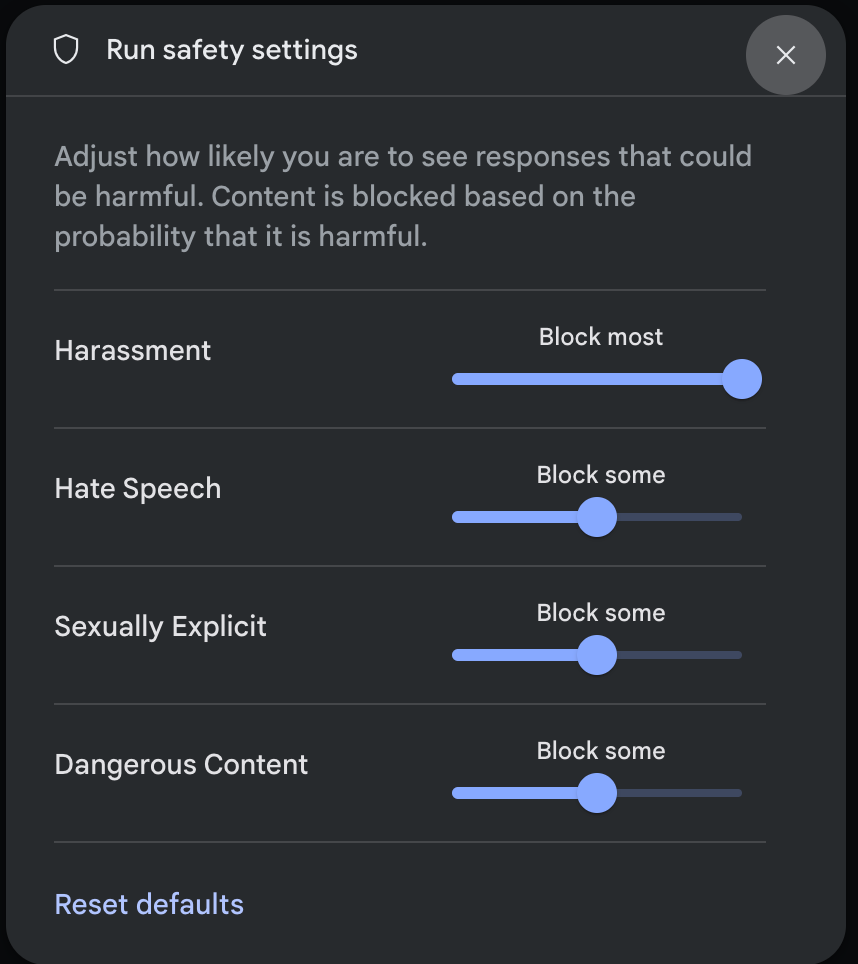
عند إرسال طلب (على سبيل المثال، من خلال طرح سؤال على النموذج)، تظهر رسالة تم حظر المحتوى إذا تم حظر محتوى الطلب. للاطّلاع على مزيد من التفاصيل، مرِّر المؤشر فوق النص تم حظر المحتوى للاطّلاع على الفئة واحتمالية تصنيف الضرر.
أمثلة للرموز البرمجية
يوضّح مقتطف الرمز البرمجي التالي كيفية ضبط إعدادات الأمان في طلب GenerateContent. يضبط هذا الرمز الحدّ لفئة الكلام الذي يحضّ على الكراهية (HARM_CATEGORY_HATE_SPEECH). يؤدي ضبط هذه الفئة على BLOCK_LOW_AND_ABOVE إلى حظر أي محتوى لديه احتمالية منخفضة أو أعلى بأن يكون كلامًا يحضّ على الكراهية. لفهم إعدادات الحدّ، يُرجى الاطّلاع على فلترة الأمان
لكل طلب.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
انتقال
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
جافا
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
الخطوات التالية
- يمكنك الاطّلاع على مرجع واجهة برمجة التطبيقات لمعرفة المزيد عن واجهة برمجة التطبيقات الكاملة.
- يمكنك مراجعة إرشادات الأمان للحصول على نظرة عامة على اعتبارات الأمان عند التطوير باستخدام النماذج اللغوية الكبيرة.
- يمكنك التعرّف أكثر على تقييم الاحتمالية مقابل مدى الخطورة من فريق Jigsaw
- يمكنك التعرّف أكثر على المنتجات التي تساهم في حلول الأمان، مثل الـ Perspective API. * يمكنك استخدام إعدادات الأمان هذه لإنشاء مصنِّف للمحتوى السام. للبدء، يُرجى الاطّلاع على مثال التصنيف.