La API de Gemini proporciona parámetros de seguridad que puedes ajustar durante la fase de creación de prototipos para determinar si tu aplicación requiere una configuración de seguridad más o menos restrictiva. Puedes ajustar estos parámetros en cuatro categorías de filtros para restringir o permitir ciertos tipos de contenido.
En esta guía, se explica cómo la API de Gemini controla los parámetros de seguridad y el filtrado, y cómo puedes cambiar los parámetros de seguridad de tu aplicación.
Filtros de seguridad
Los filtros de seguridad ajustables de la API de Gemini abarcan las siguientes categorías:
| Categoría | Descripción |
|---|---|
| Hostigamiento | Comentarios negativos o dañinos dirigidos a la identidad o a los atributos protegidos |
| Incitación al odio o a la violencia | Contenido obsceno, grosero o irrespetuoso. |
| Contenido sexualmente explícito | Referencias a actos sexuales o a otro contenido obsceno. |
| Peligroso | Contenido que promueve, facilita o incita actos dañinos. |
Estas categorías se definen en HarmCategory. Puedes usar estos filtros para ajustar lo que sea apropiado para tu caso de uso. Por ejemplo, si estás creando diálogos de videojuegos, puedes considerar aceptable permitir más contenido clasificado como peligroso debido a la naturaleza del juego.
Además de los filtros de seguridad ajustables, la API de Gemini tiene protecciones integradas contra daños fundamentales, como el contenido que pone en peligro la seguridad de los niños. Estos tipos de daño siempre se bloquean y no se pueden ajustar.
Nivel de filtrado de seguridad del contenido
La API de Gemini categoriza el nivel de probabilidad de que el contenido sea inseguro como HIGH, MEDIUM, LOW o NEGLIGIBLE.
La API de Gemini bloquea el contenido en función de la probabilidad de que el contenido sea inseguro y no la gravedad. Es importante saber esto porque algunos contenidos pueden tener una baja probabilidad de ser inseguros, aunque la gravedad del daño pueda seguir siendo alta. Por ejemplo, comparemos las siguientes oraciones:
- El robot me golpeó.
- El robot me acuchilló.
La primera oración puede tener una mayor probabilidad de que sea contenido no seguro, pero podrías considerar que la segunda oración es de mayor gravedad en términos de violencia. Ahora que entendemos esto, es importante que pruebes y consideres con cuidado cuál es el nivel adecuado de bloqueo necesario para apoyar tus casos de uso clave, para así minimizar al mismo tiempo el daño a los usuarios finales.
Filtrado de seguridad por solicitud
Puedes ajustar los parámetros de seguridad para cada solicitud que realices a la API. Cuando haces una solicitud, el contenido se analiza y se le asigna una calificación de seguridad. La calificación de seguridad incluye la categoría y la probabilidad de la clasificación del daño. Por ejemplo, si el contenido se bloqueó debido a que la categoría de hostigamiento tenía una alta probabilidad, la calificación de seguridad que se muestra tendría una categoría igual a HARASSMENT y la probabilidad de daño establecida en HIGH.
Debido a la seguridad inherente del modelo, los filtros adicionales están desactivados de forma predeterminada. Si eliges habilitarlos, puedes configurar el sistema para que bloquee el contenido en función de su probabilidad de ser inseguro. El comportamiento predeterminado del modelo abarca la mayoría de los casos de uso, por lo que solo debes ajustar estos parámetros si es necesario para tu aplicación.
En la siguiente tabla, se describe la configuración de bloqueo que puedes ajustar para cada categoría. Por ejemplo, si estableces la configuración de bloqueo en Bloquear poco para la categoría de incitación al odio o a la violencia, se bloqueará todo lo que tenga una alta probabilidad de ser contenido de incitación al odio o a la violencia. Pero se permite cualquier cosa con una probabilidad menor.
| Umbral (Google AI Studio) | Umbral (API) | Descripción |
|---|---|---|
| Desactivado | OFF |
Desactiva el filtro de seguridad. |
| No bloquear | BLOCK_NONE |
Mostrar siempre sin importar la probabilidad de que sea contenido no seguro. |
| Bloquear poco | BLOCK_ONLY_HIGH |
Bloquear cuando haya una alta probabilidad de que sea contenido no seguro. |
| Bloquear algunos | BLOCK_MEDIUM_AND_ABOVE |
Bloquear cuando haya una probabilidad media o alta de que sea contenido no seguro. |
| Bloquear la mayoría | BLOCK_LOW_AND_ABOVE |
Bloquear cuando haya una probabilidad baja, media o alta de que sea contenido no seguro. |
| N/A | HARM_BLOCK_THRESHOLD_UNSPECIFIED |
No se especifica el umbral; se bloquea con el umbral predeterminado. |
Si no se establece el umbral, el umbral de bloqueo predeterminado es Desactivado para los modelos Gemini 2.5 y 3.
Puedes establecer estos parámetros para cada solicitud que realices al servicio generativo.
Consulta la referencia de la API de HarmBlockThreshold
para obtener más detalles.
Comentarios de seguridad
generateContent
muestra una
GenerateContentResponse que
incluye comentarios de seguridad.
Los comentarios de los mensajes se incluyen en
promptFeedback. Si se establece promptFeedback.blockReason, se bloqueó el contenido del mensaje.
Los comentarios de los candidatos de respuesta se incluyen en
Candidate.finishReason y
Candidate.safetyRatings. Si se bloqueó el contenido de la respuesta y el finishReason fue SAFETY, puedes inspeccionar safetyRatings para obtener más detalles. No se muestra el contenido que se bloqueó.
Ajusta la configuración de seguridad
En esta sección, se explica cómo ajustar la configuración de seguridad en Google AI Studio y en tu código.
Google AI Studio
Puedes ajustar la configuración de seguridad en Google AI Studio.
Haz clic en Configuración de seguridad en Configuración avanzada en el panel Configuración de la ejecución para abrir el modal Ejecutar configuración de seguridad. En el modal, puedes usar los controles deslizantes para ajustar el nivel de filtrado de contenido por categoría de seguridad:
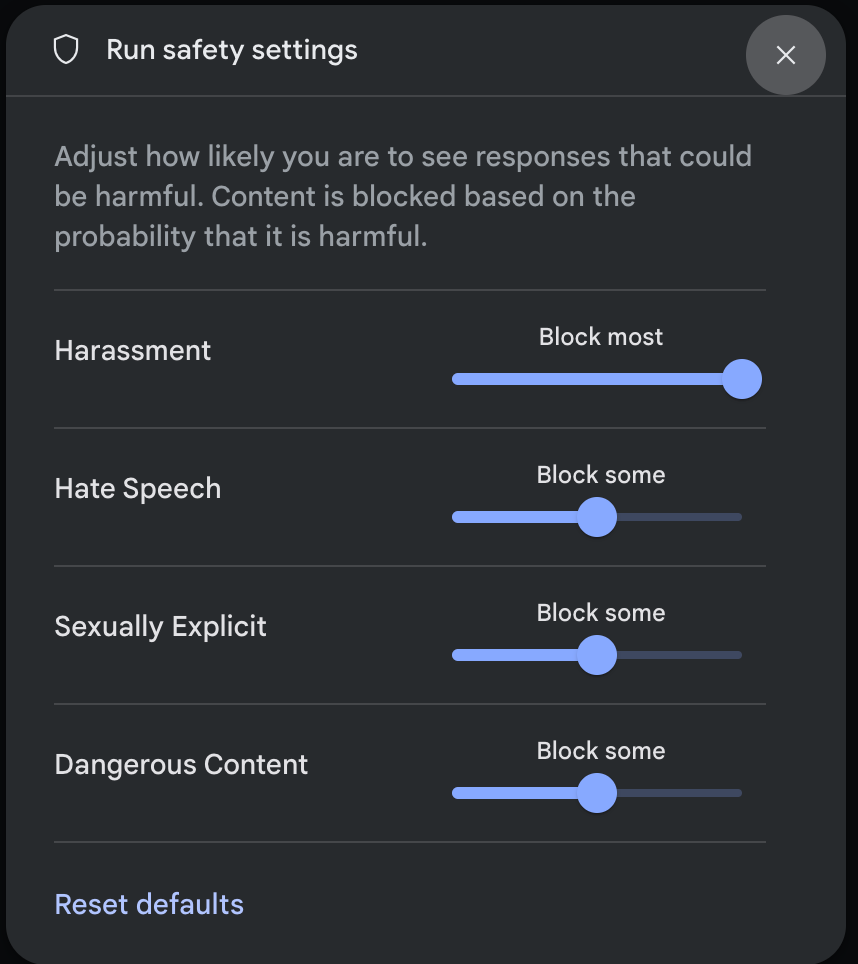
Cuando envías una solicitud (por ejemplo, cuando le haces una pregunta al modelo), aparece un mensaje Contenido bloqueado si se bloquea el contenido de la solicitud. Para ver más detalles, mantén el puntero sobre el texto Contenido bloqueado para ver la categoría y la probabilidad de la clasificación del daño.
Ejemplos de código
En el siguiente fragmento de código, se muestra cómo establecer la configuración de seguridad en tu llamada a GenerateContent. Esto establece el umbral para la categoría de incitación al odio o a la violencia (HARM_CATEGORY_HATE_SPEECH). Si estableces esta categoría en BLOCK_LOW_AND_ABOVE, se bloqueará cualquier contenido que tenga una probabilidad baja o superior de ser incitación al odio o a la violencia. Para comprender la configuración del umbral, consulta Filtrado de seguridad
por solicitud.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
Go
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
Java
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
Próximos pasos
- Consulta la referencia de la API para obtener más información sobre la API completa.
- Revisa la guía de seguridad para obtener una descripción general de las consideraciones de seguridad cuando desarrollas con LLMs.
- Obtén más información sobre la evaluación de la probabilidad en comparación con la gravedad del equipo de Jigsaw team.
- Obtén más información sobre los productos que contribuyen a las soluciones de seguridad, como la API de Perspective. * Puedes usar estos parámetros de seguridad para crear un clasificador de toxicidad. Consulta el ejemplo de clasificación para comenzar.