Gemini API には、プロトタイピングの段階で調整できる安全性の設定が用意されています。これにより、アプリケーションに対してより厳しいまたは緩い安全性の構成が必要かどうかを判断できます。これらの設定は、4 つのフィルタ カテゴリにわたって調整し、特定の種類のコンテンツを制限または許可できます。
このガイドでは、Gemini API で安全性の設定とフィルタリングがどのように処理されるか、アプリケーションの安全性の設定を変更する方法について説明します。
安全フィルタ
Gemini API の調整可能な安全フィルタは、次のカテゴリを対象としています。
| カテゴリ | 説明 |
|---|---|
| 嫌がらせ | アイデンティティや保護対象属性をターゲットとする否定的または有害なコメント。 |
| ヘイトスピーチ | 失礼、無礼、または不敬なコンテンツ。 |
| 露骨な性表現 | 性行為やわいせつな内容に関する情報が含まれるコンテンツ。 |
| 危険 | 有害な行為を促進、助長、または推奨するコンテンツ。 |
これらのカテゴリは HarmCategory で定義されています。これらのフィルタを使用して、ユースケースに適切なコンテンツとなるように調整できます。たとえば、ゲームの会話を作成する場合、ゲームの性質上、「危険」として評価されたコンテンツをより多く許容することを問題ないとみなす場合があります。
Gemini API には、調整可能な安全フィルタに加えて、児童を危険にさらすようなコンテンツなど、重大な有害性に対する保護機能が組み込まれています。 このような種類の有害性は常にブロックされ、調整することはできません。
コンテンツの安全フィルタリング レベル
Gemini API は、コンテンツが安全でない確率レベルを HIGH、MEDIUM、LOW、NEGLIGIBLE に分類します。
Gemini API は、重大度ではなく、コンテンツが安全でない確率に基づいてコンテンツをブロックします。コンテンツによっては、危害の重大度が高くても、安全でない確率が低くなるものもあるため、この点を考慮することが重要です。たとえば、次の文を比較します。
- ロボットが私をパンチした。
- ロボットが私を切り付けた。
最初の文は安全でない確率が高くなる可能性がありますが、2 つめの文は暴力の観点で重大度が高いとみなすことができます。 したがって、エンドユーザーへの悪影響を最小限に抑えながら主要なユースケースをサポートするために必要となる、適切なレベルのブロックを慎重にテストし、検討することが重要です。
リクエストごとの安全フィルタリング
API に対するリクエストごとに安全性の設定を調整できます。リクエストを行うと、コンテンツが分析され、安全性評価が割り当てられます。安全性評価には、カテゴリと有害として分類される確率が含まれます。たとえば、「嫌がらせ」カテゴリに対して高い確率で安全でなかったためにコンテンツがブロックされた場合、返される安全性評価のカテゴリは HARASSMENT、有害である確率は HIGH に設定されます。
モデルには固有の安全性があるため、追加のフィルタはデフォルトでオフ になっています。 有効にする場合は、安全でない確率に基づいてコンテンツをブロックするようにシステムを構成できます。デフォルトのモデルの動作はほとんどのユースケースに対応しているため、アプリケーションで一貫して必要とされる場合にのみ、これらの設定を調整してください。
次の表に、カテゴリごとに調整できるブロック設定を示します。たとえば、「ヘイトスピーチ 」カテゴリのブロック設定を [少量をブロック] に設定した場合、ヘイトスピーチ コンテンツである確率が高いものはすべてブロックされますが、 確率が低いものは許可されます。
| しきい値(Google AI Studio) | しきい値(API) | 説明 |
|---|---|---|
| オフ | OFF |
安全フィルタをオフにする |
| ブロックなし | BLOCK_NONE |
安全でないコンテンツである確率に関係なく常に表示する |
| 少量をブロック | BLOCK_ONLY_HIGH |
安全でないコンテンツである確率が高い場合にブロックする |
| 一部をブロック | BLOCK_MEDIUM_AND_ABOVE |
安全でないコンテンツである確率が中程度または高い場合にブロックする |
| ほとんどをブロック | BLOCK_LOW_AND_ABOVE |
安全でないコンテンツである確率が低い場合、中程度の場合、高い場合にブロックする |
| なし | HARM_BLOCK_THRESHOLD_UNSPECIFIED |
しきい値が指定されていません。デフォルトのしきい値を使用してブロックする |
しきい値が設定されていない場合、Gemini 2.5 モデルと 3 モデルのデフォルトのブロックしきい値はオフ です。
これらの設定は、生成サービスに対するリクエストごとに設定できます。
詳細については、HarmBlockThreshold API
リファレンスをご覧ください。
安全性のフィードバック
generateContent
は、
GenerateContentResponse安全性のフィードバックを含む
を返します。
プロンプトのフィードバックは
promptFeedbackに含まれています。promptFeedback.blockReason が設定されている場合、プロンプトのコンテンツはブロックされました。
レスポンス候補のフィードバックは
Candidate.finishReason と
Candidate.safetyRatings に含まれています。レスポンス コンテンツがブロックされ、finishReason が SAFETY の場合は、safetyRatings で詳細を確認できます。ブロックされたコンテンツは返されません。
安全性の設定を調整する
このセクションでは、Google AI Studio とコードの両方で安全性の設定を調整する方法について説明します。
Google AI Studio
Google AI Studio で安全性の設定を調整できます。
[実行設定] パネルの [詳細設定] で [安全性の設定] をクリックして、[実行の安全性の設定] モーダルを開きます。このモーダルでは、スライダーを使用して、安全カテゴリごとにコンテンツ フィルタリング レベルを調整できます。
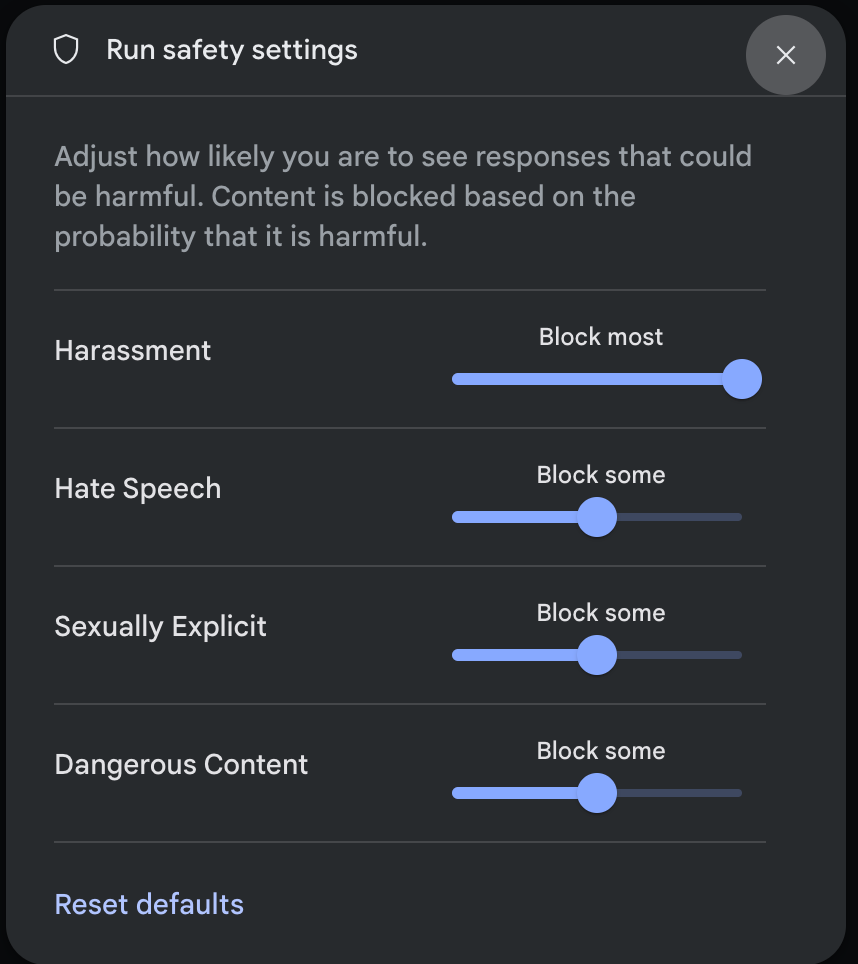
リクエストを送信すると(モデルに質問するなど)、リクエストのコンテンツがブロックされた場合、 [Content blocked] というメッセージが表示されます。詳細を確認するには、[コンテンツがブロックされました] というテキストにポインタを合わせると、カテゴリと有害として分類される確率が表示されます。
コードの例
次のコード スニペットは、GenerateContent 呼び出しで安全性の設定を行う方法を示しています。これにより、ヘイトスピーチ(HARM_CATEGORY_HATE_SPEECH)カテゴリのしきい値が設定されます。このカテゴリを BLOCK_LOW_AND_ABOVE に設定すると、ヘイトスピーチである確率が低い以上のコンテンツがブロックされます。しきい値の設定については、安全フィルタリング
リクエストごとをご覧ください。
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
Go
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
Java
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
次のステップ
- API の詳細については、API リファレンスをご覧ください。
- LLM を使用した開発における安全性の考慮事項の概要については、安全性のガイダンスをご覧ください。
- 確率と重大度の評価の詳細については、Jigsaw チームのブログをご覧ください。
- Perspective API などの安全ソリューションに貢献するプロダクトの詳細をご覧ください。* これらの安全性の設定を使用して、有害性 分類子を作成できます。始めるには、分類 の例をご覧ください。