
صفحة النموذج: CodeGemma
المراجع والمستندات الفنية:
بنود الاستخدام: البنود
المؤلفون: Google
معلومات الطراز
ملخّص النموذج
الوصف
CodeGemma هي مجموعة من نماذج الرموز البرمجية الخفيفة والمفتوحة المصدر، والتي تم إنشاؤها استنادًا إلى Gemma. نماذج CodeGemma هي نماذج لفك الترميز فقط من النص إلى النص ومن النص إلى الرمز، وهي متوفرة كخيار مُدرَّب مسبقًا يتألف من 7 مليار مَعلمة ويتخصص في إكمال الرمز ومهام إنشاء الرمز، وخيار مُعدّ خصيصًا للتعليمات يتألف من 7 مليار مَعلمة للمحادثات البرمجية واتّباع التعليمات، وخيار مُدرَّب مسبقًا يتألف من مليارَي مَعلمة لإكمال الرمز البرمجي بسرعة.
المدخلات والمخرجات
الإدخال: بالنسبة إلى صيغ النماذج المدربة مسبقًا: بادئة الرمز ولاحقته اختياريًا لسيناريوهات إكمال الرموز البرمجية وإنشائها أو نص/طلب باللغة الطبيعية بالنسبة إلى الصيغة المخصّصة للتعليمات: نص أو طلب بلغة طبيعية.
الناتج: بالنسبة إلى صيغ النماذج المدربة مسبقًا: إكمال الرموز البرمجية التي تتضمّن فراغات، والرموز البرمجية واللغة الطبيعية بالنسبة إلى الصيغة المخصّصة للتعليمات: الرمز البرمجي واللغة الطبيعية
معلومات الكتاب
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
بيانات النماذج
مجموعة بيانات التدريب
باستخدام Gemma كنموذج أساسي، يتم تدريب الصيغتَين المُدرَّبتَين مسبقًا من CodeGemma 2B و7B بشكلٍ إضافي على 500 إلى 1, 000 مليار رمز إضافي من بيانات لغة الإنجليزية في المقام الأول من مجموعات بيانات الرياضيات المتاحة للجميع والرمز الذي تم إنشاؤه بشكل اصطناعي.
معالجة بيانات التدريب
تم تطبيق تقنيات المعالجة المسبقة للبيانات التالية لتدريب CodeGemma:
- FIM: تركّز نماذج CodeGemma المدربة مسبقًا على مهام ملء الفراغات (FIM). تم تدريب النماذج للعمل مع وضعَي PSM وSPM. إعدادات FIM هي معدل FIM من% 80 إلى% 90 مع نسبة 50-50 PSM/SPM.
- تقنيات الحِزم المستندة إلى مخطّط التبعيات والحِزم اللفظية المستندة إلى اختبار الوحدة: لتحسين مواءمة النموذج مع التطبيقات في العالم الواقعي، نظمنا أمثلة التدريب على مستوى المشروع/المستودع لجمع ملفات المصدر الأكثر صلةً في كل مستودع. على وجه التحديد، استخدمنا طريقتَين استقرائيتَين: الحِزم المستندة إلى مخطّط التبعيات والحِزم اللفظية المستندة إلى اختبار الوحدة.
- لقد طوّرنا تقنية جديدة لتقسيم المستندات إلى بادئة ووسط ولاحقة لبدء اللاحقة في نقطة أكثر طبيعية من الناحية النحوية بدلاً من التوزيع العشوائي البحت.
- السلامة: على غرار "جيما"، نفّذنا إجراءات فلترة صارمة للسلامة تشمل فلترة البيانات الشخصية، وفلترة المحتوى الذي يتضمن مواد إباحية للأطفال، وعمليات فلترة أخرى تستند إلى جودة المحتوى وسلامته بما يتوافق مع سياساتنا.
معلومات التنفيذ
الأجهزة وأطر العمل المستخدَمة أثناء التدريب
مثل Gemma، تم تدريب CodeGemma على أحدث جيل من برمجيات وحدة معالجة الموتّرات (TPU) (TPUv5e)، باستخدام JAX وML Pathways.
معلومات التقييم
نتائج قياس الأداء
منهج التقييم
- مقاييس إكمال الرموز البرمجية: HumanEval (HE) (ملء سطر واحد وسطور متعددة)
- مقاييس الأداء لإنشاء الرموز البرمجية: HumanEval وMBPP وBabelCode (BC) [C++ وC# وGo وJava وJavaScript وKotlin وPython وRust]
- سين وجيم: BoolQ وPIQA وTriviaQA
- اللغة الطبيعية: ARC-Challenge وHellaSwag وMMLU وWinoGrande
- الاستدلال الرياضي: GSM8K وMATH
نتائج قياس أداء الترميز
| مقياس الأداء | 2B | 2B (1.1) | 7 مليار | 7B-IT | 7B-IT (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37.8 | 44.5 | 56.1 | 60.4 |
| MBPP | 43.6 | 49.2 | 56.2 | 54.2 | 55.6 |
| سطر واحد في نموذج HumanEval | 78.4 | 79.3 | 76.1 | 68.3 | 77.4 |
| تقييم بشري متعدّد الأسطر | 51.4 | 51.0 | 58.4 | 20.1 | 23.7 |
| BC HE C++ | 24.2 | 19.9 | 32.9 | 42.2 | 46.6 |
| BC HE C# | 10.6 | 26.1 | 22.4 | 26.7 | 54.7 |
| BC HE Go | 20.5 | 18.0 | 21.7 | 28.6 | 34.2 |
| BC HE Java | 29.2 | 29.8 | 41.0 | 48.4 | 50.3 |
| JavaScript في BC HE | 21.7 | 28.0 | 39.8 | 46.0 | 48.4 |
| BC HE Kotlin | 28.0 | 32.3 | 39.8 | 51.6 | 47.8 |
| BC HE Python | 21.7 | 36.6 | 42.2 | 48.4 | 54.0 |
| BC HE Rust | 26.7 | 24.2 | 34.1 | 36.0 | 37.3 |
| BC MBPP C++ | 47.1 | 38.9 | 53.8 | 56.7 | 63.5 |
| BC MBPP C# | 28.7 | 45.3 | 32.5 | 41.2 | 62.0 |
| BC MBPP Go | 45.6 | 38.9 | 43.3 | 46.2 | 53.2 |
| BC MBPP Java | 41.8 | 49.7 | 50.3 | 57.3 | 62.9 |
| JavaScript في "الإعلانات المتجاوبة على شبكة البحث" (BC MBPP) | 45.3 | 45.0 | 58.2 | 61.4 | 61.4 |
| BC MBPP Kotlin | 46.8 | 49.7 | 54.7 | 59.9 | 62.6 |
| BC MBPP Python | 38.6 | 52.9 | 59.1 | 62.0 | 60.2 |
| BC MBPP Rust | 45.3 | 47.4 | 52.9 | 53.5 | 52.3 |
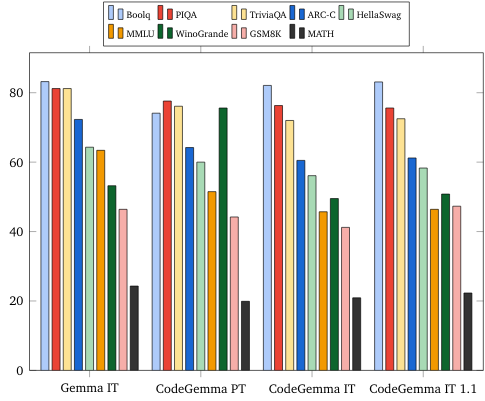
مقاييس اللغة الطبيعية (على طُرز 7B)
الأخلاق والسلامة
تقييمات الأخلاق والسلامة
نهج التقييمات
تشمل طرق التقييم التي نتّبعها تقييمات منظَّمة واختبارات داخلية لفريق الاختراق (Red Team) بشأن سياسات المحتوى ذات الصلة. تم تنفيذ أسلوب "الفريق الأحمر" من قِبل عدد من الفِرق المختلفة، ولكل فريق أهداف ومقاييس تقييم بشرية مختلفة. تم تقييم هذه النماذج وفقًا لعدد من الفئات المختلفة ذات الصلة بالأخلاق والسلامة، بما في ذلك:
تقييم بشري للطلبات التي تتناول سلامة المحتوى والضرر الذي يلحقه المحتوى بالآخرين اطّلِع على بطاقة نموذج Gemma لمزيد من التفاصيل عن نهج التقييم.
اختبار محدد لقدرات الجرائم الإلكترونية، مع التركيز على اختبار قدرات الاختراق التلقائية والحرص على الحد من الأضرار المحتملة
نتائج التقييم
تقع نتائج تقييمات الأخلاق والسلامة ضمن الحدود المقبولة لاستيفاء السياسات الداخلية لفئات مثل سلامة الأطفال وسلامة المحتوى والأضرار الناتجة عن المحتوى المرئي والحفظ والضرر على نطاق واسع. اطّلِع على بطاقة طراز Gemma لمزيد من التفاصيل.
استخدام النماذج والقيود المفروضة عليها
القيود المعروفة
تفرض النماذج اللغوية الكبيرة (LLM) قيودًا استنادًا إلى بيانات التدريب و القيود المتأصلة في التكنولوجيا. اطّلِع على بطاقة نموذج Gemma لمزيد من التفاصيل حول قيود النماذج اللغوية الكبيرة.
الاعتبارات الأخلاقية والمخاطر
يثير تطوير النماذج اللغوية الكبيرة (LLM) العديد من المخاوف الأخلاقية. لقد أخذنا في الاعتبار بعناية جوانب متعدّدة عند تطوير هذه التصاميم.
يُرجى الرجوع إلى المناقشة نفسها في بطاقة طراز Gemma لمعرفة تفاصيل النموذج.
الغرض من الاستخدام
التطبيق
تمتلك نماذج Gemma للترميز مجموعة كبيرة من التطبيقات التي تختلف بين نماذج تكنولوجيا المعلومات و نماذج تكنولوجيات التشغيل. القائمة التالية للاستخدامات المحتملة ليست شاملة. ويهدف هذا القسم إلى تقديم معلومات سياقية حول حالات الاستخدام المحتملة التي أخذها صنّاع النماذج في الاعتبار كجزء من تدريب النماذج و تطويرها.
- إكمال الرموز البرمجية: يمكن استخدام نماذج الذكاء الاصطناعي (PT) لإكمال الرموز البرمجية باستخدام إضافة "بيئة تطوير متكاملة"
- إنشاء الرموز البرمجية: يمكن استخدام نموذج تكنولوجيا المعلومات لإنشاء رموز برمجية باستخدام إضافة IDE أو بدونها.
- محادثة حول الرموز البرمجية: يمكن أن يعزّز نموذج تكنولوجيا المعلومات واجهات المحادثات التي تناقش الرموز البرمجية
- تعليم الترميز: يتيح نموذج تكنولوجيا المعلومات تجارب تعلُّم تفاعلية للترميز، ويساعد في تصحيح البنية النحوية أو يقدّم تدريبات على الترميز.
المزايا
في وقت الإصدار، توفّر هذه المجموعة من النماذج عمليات تنفيذ نماذج لغوية كبيرة مفتوحة ومركزة على الرموز البرمجية ذات الأداء العالي والمصمّمة من الأساس لتطوير الذكاء الاصطناعي المسؤول مقارنةً بالنماذج ذات الحجم المماثل.
باستخدام مقاييس تقييم معايير الترميز الموضّحة في هذا المستند، أظهرت هذه النماذج أنّها تحقّق أداءً أفضل من بدائل النماذج المفتوحة الأخرى المماثلة الحجم.