
मॉडल पेज: CodeGemma
संसाधन और तकनीकी दस्तावेज़:
इस्तेमाल की शर्तें: शर्तें
लेखक: Google
मॉडल की जानकारी
मॉडल की खास जानकारी
ब्यौरा
CodeGemma, Gemma के आधार पर बनाए गए लाइटवेट ओपन कोड मॉडल का फ़ैमिली है. CodeGemma मॉडल, टेक्स्ट से टेक्स्ट और टेक्स्ट से कोड में बदलने वाले सिर्फ़ डिकोडर मॉडल हैं. ये मॉडल, पहले से ट्रेन किए गए सात अरब वैरिएंट के तौर पर उपलब्ध हैं. ये कोड पूरा करने और कोड जनरेट करने के टास्क में माहिर हैं. साथ ही, कोड चैट और निर्देशों का पालन करने के लिए, सात अरब पैरामीटर वाले निर्देश-ट्यून किए गए वैरिएंट के तौर पर उपलब्ध हैं. इसके अलावा, तेज़ी से कोड पूरा करने के लिए, दो अरब पैरामीटर वाले पहले से ट्रेन किए गए वैरिएंट के तौर पर उपलब्ध हैं.
इनपुट और आउटपुट
इनपुट: पहले से ट्रेन किए गए मॉडल के वैरिएंट के लिए: कोड के लिए प्रीफ़िक्स और वैकल्पिक रूप से सफ़िक्स, कोड पूरा करने और जनरेट करने की स्थितियों या नैचुरल लैंग्वेज टेक्स्ट/प्रॉम्प्ट के लिए. निर्देश के हिसाब से बनाए गए मॉडल के वैरिएंट के लिए: सामान्य भाषा का टेक्स्ट या प्रॉम्प्ट.
आउटपुट: पहले से ट्रेन किए गए मॉडल के वैरिएंट के लिए: बीच में कोड भरने की सुविधा, कोड, और नैचुरल लैंग्वेज. निर्देश के हिसाब से बनाए गए मॉडल के वैरिएंट के लिए: कोड और सामान्य भाषा.
उद्धरण
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
मॉडल का डेटा
ट्रेनिंग डेटासेट
Gemma को बेस मॉडल के तौर पर इस्तेमाल करके, CodeGemma 2B और 7B के पहले से ट्रेन किए गए वैरिएंट को, मुख्य रूप से अंग्रेज़ी भाषा के डेटा के 500 से 1,000 अरब टोकन पर और ट्रेन किया जाता है. यह डेटा, ओपन सोर्स के मैथमैटिक्स डेटासेट और सिंथेटिक तरीके से जनरेट किए गए कोड से लिया जाता है.
ट्रेनिंग के लिए डेटा प्रोसेसिंग
CodeGemma को ट्रेन करने के लिए, डेटा को पहले से प्रोसेस करने की ये तकनीकें इस्तेमाल की गईं:
- एफ़आईएम - पहले से ट्रेन किए गए CodeGemma मॉडल, बीच में जानकारी भरने (एफ़आईएम) वाले टास्क पर फ़ोकस करते हैं. इन मॉडल को PSM और SPM, दोनों मोड के साथ काम करने के लिए ट्रेन किया जाता है. हमारी एफ़आईएम सेटिंग, 50-50 पीएसएम/एसपीएम के साथ 80% से 90% एफ़आईएम रेट पर सेट होती हैं.
- डिपेंडेंसी ग्राफ़ पर आधारित पैकिंग और यूनिट टेस्ट पर आधारित लेक्सिकल पैकिंग तकनीकें: असल दुनिया के ऐप्लिकेशन के साथ मॉडल के अलाइनमेंट को बेहतर बनाने के लिए, हमने प्रोजेक्ट/रिपॉज़िटरी लेवल पर ट्रेनिंग के उदाहरणों को व्यवस्थित किया है. इससे हर रिपॉज़िटरी में सबसे काम की सोर्स फ़ाइलों को एक साथ रखा जा सकता है. खास तौर पर, हमने दो हेयुरिस्टिक्स (अनुमान लगाने वाली) तरीकों का इस्तेमाल किया: डिपेंडेंसी ग्राफ़ पर आधारित पैकिंग और यूनिट टेस्ट पर आधारित लेक्सिकल पैकिंग.
- हमने दस्तावेज़ों को प्रीफ़िक्स, मध्य, और सफ़िक्स में बांटने के लिए एक नई तकनीक विकसित की है. इससे सफ़िक्स, पूरी तरह से रैंडम डिस्ट्रिब्यूशन के बजाय, सिंटैक्टिकली नैचुरल पॉइंट से शुरू होता है.
- सुरक्षा: Gemma की तरह ही, हमने सुरक्षा से जुड़ी कड़ी फ़िल्टरिंग की सुविधा लागू की है. इसमें निजी डेटा, सीएसएएम, और कॉन्टेंट की क्वालिटी और सुरक्षा के आधार पर अन्य फ़िल्टरिंग शामिल है. यह सुविधा, हमारी नीतियों के मुताबिक है.
लागू करने से जुड़ी जानकारी
ट्रेनिंग के दौरान इस्तेमाल किए गए हार्डवेयर और फ़्रेमवर्क
Gemma की तरह ही, CodeGemma को JAX और ML Pathways का इस्तेमाल करके, टेंसर प्रोसेसिंग यूनिट (TPU) हार्डवेयर (TPUv5e) की नई जनरेशन पर ट्रेन किया गया था.
इवैलुएशन की जानकारी
बेंचमार्क के नतीजे
आकलन का तरीका
- कोड पूरा करने के मानदंड: HumanEval (HE) (एक लाइन और एक से ज़्यादा लाइन में इनफ़िल करने की सुविधा)
- कोड जनरेशन के मानदंड: HumanEval, MBPP, BabelCode (BC) [C++, C#, Go, Java, JavaScript, Kotlin, Python, Rust]
- सवाल और जवाब: BoolQ, PIQA, TriviaQA
- सामान्य भाषा: ARC-Challenge, HellaSwag, MMLU, WinoGrande
- गणित के बारे में सोच-विचार: GSM8K, MATH
कोडिंग बेंचमार्क के नतीजे
| मानदंड | 2B | 2B (1.1) | 7B | 7B-IT | 7B-IT (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37.8 | 44.5 | 56.1 | 60.4 |
| MBPP | 43.6 | 49.2 | 56.2 | 54.2 | 55.6 |
| HumanEval की एक लाइन | 78.4 | 79.3 | 76.1 | 68.3 | 77.4 |
| HumanEval मल्टी लाइन | 51.4 | 51.0 | 58.4 | 20.1 | 23.7 |
| BC HE C++ | 24.2 | 19.9 | 32.9 | 42.2 | 46.6 |
| BC HE C# | 10.6 | 26.1 | 22.4 | 26.7 | 54.7 |
| BC HE Go | 20.5 | 18.0 | 21.7 | 28.6 | 34.2 |
| BC HE Java | 29.2 | 29.8 | 41.0 | 48.4 | 50.3 |
| BC HE JavaScript | 21.7 | 28.0 | 39.8 | 46.0 | 48.4 |
| BC HE Kotlin | 28.0 | 32.3 | 39.8 | 51.6 | 47.8 |
| BC HE Python | 21.7 | 36.6 | 42.2 | 48.4 | 54.0 |
| BC HE Rust | 26.7 | 24.2 | 34.1 | 36.0 | 37.3 |
| BC MBPP C++ | 47.1 | 38.9 | 53.8 | 56.7 | 63.5 |
| BC MBPP C# | 28.7 | 45.3 | 32.5 | 41.2 | 62.0 |
| BC MBPP Go | 45.6 | 38.9 | 43.3 | 46.2 | 53.2 |
| BC MBPP Java | 41.8 | 49.7 | 50.3 | 57.3 | 62.9 |
| BC MBPP JavaScript | 45.3 | 45.0 | 58.2 | 61.4 | 61.4 |
| BC MBPP Kotlin | 46.8 | 49.7 | 54.7 | 59.9 | 62.6 |
| BC MBPP Python | 38.6 | 52.9 | 59.1 | 62.0 | 60.2 |
| BC MBPP Rust | 45.3 | 47.4 | 52.9 | 53.5 | 52.3 |
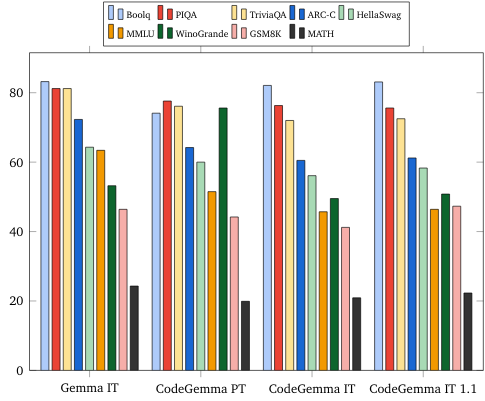
नैचुरल लैंग्वेज के मानदंड (7B मॉडल पर)
नैतिकता और सुरक्षा
नैतिकता और सुरक्षा से जुड़े आकलन
जांच का तरीका
हमारे आकलन के तरीकों में, कॉन्टेंट से जुड़ी नीतियों के लिए स्ट्रक्चर्ड आकलन और इंटरनल रेड-टीमिंग जांच शामिल है. रेड-टीमिंग की प्रोसेस कई अलग-अलग टीमों ने पूरी की. हर टीम के अलग-अलग लक्ष्य और मानवीय आकलन की मेट्रिक थीं. इन मॉडल का आकलन, नैतिकता और सुरक्षा से जुड़ी कई अलग-अलग कैटगरी के हिसाब से किया गया. इनमें ये शामिल हैं:
कॉन्टेंट की सुरक्षा और नुकसान पहुंचाने वाले कॉन्टेंट से जुड़े प्रॉम्प्ट पर, किसी व्यक्ति की ओर से किया गया आकलन. आकलन के तरीके के बारे में ज़्यादा जानकारी के लिए, Gemma मॉडल कार्ड देखें.
साइबर अपराध की क्षमताओं की खास जांच, जिसमें अपने-आप हैक करने की क्षमताओं की जांच पर फ़ोकस किया जाता है. साथ ही, यह पक्का किया जाता है कि संभावित नुकसान सीमित हों.
जांच के नतीजे
नैतिकता और सुरक्षा से जुड़े आकलन के नतीजे, बच्चों की सुरक्षा, कॉन्टेंट की सुरक्षा, नुकसान पहुंचाने वाले कॉन्टेंट, याद रखने की सुविधा, बड़े पैमाने पर नुकसान पहुंचाने वाले कॉन्टेंट जैसी कैटगरी के लिए बनी इंटरनल नीतियों के मुताबिक हैं. ज़्यादा जानकारी के लिए, Gemma मॉडल कार्ड देखें.
मॉडल का इस्तेमाल और सीमाएं
सीमाएं
लार्ज लैंग्वेज मॉडल (एलएलएम) की सीमाएं, उनके ट्रेनिंग डेटा और टेक्नोलॉजी की इन-हेरिटेड सीमाओं पर निर्भर करती हैं. एलएलएम की सीमाओं के बारे में ज़्यादा जानने के लिए, Gemma मॉडल कार्ड देखें.
नैतिकता से जुड़ी बातें और जोखिम
लार्ज लैंग्वेज मॉडल (एलएलएम) बनाने से, नैतिकता से जुड़ी कई समस्याएं आती हैं. इन मॉडल को तैयार करते समय, हमने कई बातों का ध्यान रखा है.
मॉडल की जानकारी के लिए, कृपया Gemma मॉडल कार्ड में उसी चर्चा को देखें.
इस्तेमाल का मकसद
ऐप्लिकेशन
Code Gemma मॉडल के कई तरह के ऐप्लिकेशन हैं, जो आईटी और पीटी मॉडल के बीच अलग-अलग होते हैं. यहां दिए गए संभावित इस्तेमाल की सूची में सभी काम नहीं बताए गए हैं. इस सूची का मकसद, संभावित इस्तेमाल के उन उदाहरणों के बारे में जानकारी देना है जिन्हें मॉडल बनाने वाले लोगों ने मॉडल को ट्रेनिंग देने और डेवलप करने के दौरान ध्यान में रखा था.
- कोड पूरा करने की सुविधा: IDE एक्सटेंशन की मदद से कोड पूरा करने के लिए, PT मॉडल का इस्तेमाल किया जा सकता है
- कोड जनरेशन: आईटी मॉडल का इस्तेमाल, IDE एक्सटेंशन के साथ या उसके बिना कोड जनरेट करने के लिए किया जा सकता है
- कोड से जुड़ी बातचीत: आईटी मॉडल, बातचीत वाले इंटरफ़ेस को बेहतर बना सकता है, जो कोड के बारे में बताते हैं
- कोड शिक्षा: आईटी मॉडल, कोड सीखने के इंटरैक्टिव तरीकों के साथ काम करता है. साथ ही, सिंटैक्स में सुधार करने या कोडिंग का अभ्यास करने में मदद करता है
फ़ायदे
रिलीज़ के समय, मॉडल की इस फ़ैमिली में, बेहतर परफ़ॉर्मेंस वाले ओपन कोड पर फ़ोकस करने वाले लार्ज लैंग्वेज मॉडल लागू किए जाते हैं. इन्हें इसी तरह के साइज़ वाले मॉडल की तुलना में, एआई के सही इस्तेमाल के लिए शुरू से ही डिज़ाइन किया गया है.
इस दस्तावेज़ में बताई गई कोडिंग बेंचमार्क की मेट्रिक का इस्तेमाल करके, इन मॉडल की परफ़ॉर्मेंस, तुलना के हिसाब से साइज़ वाले अन्य ओपन मॉडल के विकल्पों से बेहतर रही है.