
Strona modelu: CodeGemma
Materiały i dokumentacja techniczna:
Warunki korzystania z usługi: Warunki
Autorzy: Google
Informacje o modelu
Podsumowanie modelu
Opis
CodeGemma to rodzina lekkich modeli kodu open source opartych na Gemma. Modele CodeGemma to modele dekodujące tekst na tekst i tekst na kod. Są dostępne w wersji wstępnie wytrenowanej z 7 mld parametrów, która specjalizuje się w zadaniach związanych z uzupełnianiem i generowaniem kodu, w wersji z 7 mld parametrów dostosowanych do instrukcji, która służy do tworzenia czatu z kodem i wykonywania instrukcji, oraz w wersji wstępnie wytrenowanej z 2 mld parametrów, która służy do szybkiego uzupełniania kodu.
Wejścia i wyjścia
Dane wejściowe: w przypadku wstępnie wytrenowanych wariantów modelu: prefiks kodu i opcjonalnie sufiks do scenariuszy uzupełniania i generowania kodu lub tekst/prompt w języku naturalnym. W przypadku wariantu modelu dostosowanego do instrukcji: tekst w języku naturalnym lub prompt.
Wyjście: w przypadku zaimplementowanych wstępnie wersji modelu: uzupełnianie kodu w środku, kod i język naturalny. W przypadku wariantu modelu dostosowanego do instrukcji: kod i język naturalny.
Cytat
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
Dane modelu
Zbiór danych treningowych
Na podstawie modelu podstawowego Gemma zdefiniowano warianty CodeGemma 2B i 7B, które zostały dodatkowo wytrenowane na dodatkowych 500–1000 mld tokenów danych głównie w języku angielskim z otwartych zbiorów danych matematycznych i kodu wygenerowanego syntetycznie.
Przetwarzanie danych treningowych
W celu przeszkolenia CodeGemma zastosowaliśmy te techniki wstępnego przetwarzania danych:
- FIM – wytrenowane wstępnie modele CodeGemma skupiają się na zadaniach typu fill-in-the-middle (FIM). Modele są trenowane pod kątem działania w trybach PSM i SPM. Ustawienia FIM to: 80–90% współczynnik FIM z 50–50% PSM/SPM.
- Techniki pakowania według grafu zależności i pakowania leksykalnego na podstawie testów jednostkowych: aby poprawić dopasowanie modelu do zastosowań w rzeczywistych warunkach, uporządkowaliśmy przykłady treningowe na poziomie projektu lub repozytorium, aby umieszczać w każdym repozytorium najbardziej odpowiednie pliki źródłowe. W szczególności zastosowaliśmy 2 techniki heurystyczne: pakowanie na podstawie grafu zależności i pakowanie leksykalne na podstawie testów jednostkowych.
- Opracowaliśmy nowatorską metodę dzielenia dokumentów na prefiks, środkową część i sufiks, aby sufiks zaczynał się w miejscu bardziej naturalnym pod względem składni niż w przypadku rozkładu losowego.
- Bezpieczeństwo: podobnie jak w przypadku Gemma wdrożyliśmy rygorystyczne filtrowanie bezpieczeństwa, w tym filtrowanie danych osobowych, filtrowanie CSAM i inne filtrowanie na podstawie jakości i bezpieczeństwa treści zgodnie z naszymi zasadami.
Informacje o wdrożeniu
Sprzęt i ramy używane podczas szkolenia
Podobnie jak Gemma, CodeGemma została wytrenowana na sprzęcie Tensor Processing Unit (TPU) najnowszej generacji (TPUv5e) przy użyciu JAX i ML Pathways.
Informacje o ocenie
Wyniki testu porównawczego
Metoda oceny
- Wyniki testów porównawczych uzupełniania kodu: HumanEval (HE) (wypełnianie jedno- i wielowierszowe).
- Benchmarki generowania kodu: HumanEval, MBPP, BabelCode (BC) [C++, C#, Go, Java, JavaScript, Kotlin, Python, Rust]
- Pytania i odpowiedzi: BoolQ, PIQA, TriviaQA
- Język naturalny: ARC-Challenge, HellaSwag, MMLU, WinoGrande
- Rozumowanie matematyczne: GSM8K, MATH
Wyniki testu porównawczego kodowania
| Test porównawczy | 2B | 2 MLD (1.1) | 7B | 7B-IT | 7B-IT (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37,8 | 44,5 | 56.1 | 60,4 |
| MBPP | 43,6 | 49,2 | 56,2 | 54,2 | 55,6 |
| HumanEval Single Line | 78,4 | 79,3 | 76,1 | 68,3 | 77,4 |
| HumanEval Multi Line | 51,4 | 51,0 | 58,4 | 20.1 | 23,7 |
| BC HE C++ | 24.2 | 19,9 | 32,9 | 42,2 | 46,6 |
| BC HE C# | 10.6 | 26.1 | 22,4 | 26,7 | 54,7 |
| BC HE Go | 20,5 | 18,0 | 21,7 | 28,6 | 34,2 |
| BC HE Java | 29,2 | 29,8 | 41,0 | 48,4 | 50,3 |
| BC HE JavaScript | 21,7 | 28.0 | 39,8 | 46,0 | 48,4 |
| BC HE Kotlin | 28,0 | 32,3 | 39,8 | 51,6 | 47,8 |
| BC HE Python | 21,7 | 36,6 | 42,2 | 48,4 | 54,0 |
| BC HE Rust | 26,7 | 24.2 | 34.1 | 36,0 | 37,3 |
| BC MBPP C++ | 47.1 | 38,9 | 53,8 | 56,7 | 63,5 |
| BC MBPP C# | 28,7 | 45,3 | 32,5 | 41,2 | 62,0 |
| BC MBPP Go | 45,6 | 38,9 | 43,3 | 46,2 | 53,2 |
| BC MBPP Java | 41,8 | 49,7 | 50,3 | 57,3 | 62,9 |
| BC MBPP JavaScript | 45,3 | 45,0 | 58,2 | 61,4 | 61,4 |
| BC MBPP Kotlin | 46,8 | 49,7 | 54,7 | 59,9 | 62,6 |
| BC MBPP Python | 38,6 | 52,9 | 59.1 | 62,0 | 60,2 |
| BC MBPP Rust | 45,3 | 47,4 | 52,9 | 53,5 | 52,3 |
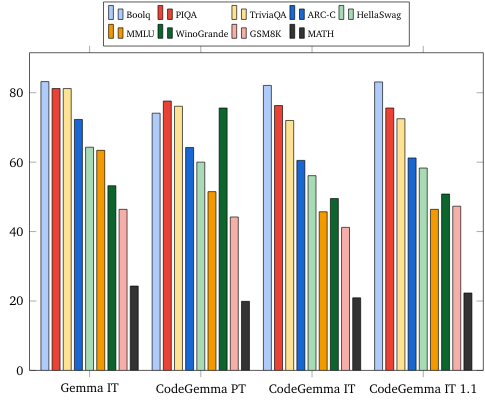
Benchmarki dotyczące języka naturalnego (w przypadku modeli 7B)
Etyka i bezpieczeństwo
Oceny etyczne i oceny bezpieczeństwa
Podejście do oceny
Nasze metody oceny obejmują oceny strukturalne i testy wewnętrznego zespołu ds. bezpieczeństwa dotyczące odpowiednich zasad dotyczących treści. W ramach red-teamingu przeprowadzono testy przez kilka różnych zespołów, z różnymi celami i wskaźnikami oceny. Modele te zostały ocenione pod kątem różnych kategorii związanych z etycznymi i bezpiecznymi rozwiązaniami, w tym:
weryfikacja manualna dotycząca promptów obejmujących bezpieczeństwo treści i reprezentację szkodliwych treści; Więcej informacji o sposobie oceny znajdziesz na karcie modelu Gemma.
Specyficzne testowanie możliwości cyberprzestępstw, ze szczególnym uwzględnieniem testowania autonomicznych możliwości hakowania i ograniczania potencjalnych szkód.
Wyniki oceny
Wyniki oceny etyki i bezpieczeństwa mieszczą się w akceptowalnych granicach w przypadku zasad wewnętrznych dotyczących takich kategorii, jak bezpieczeństwo dzieci, bezpieczeństwo treści, szkody wynikające z reprezentowania, zapamiętywanie oraz szkody na dużą skalę. Więcej informacji znajdziesz na karcie modelu Gemma.
Korzystanie z modelu i ograniczenia
Znane ograniczenia
Duże modele językowe (LLM) mają ograniczenia wynikające z danych treningowych i właściwości tej technologii. Więcej informacji o ograniczeniach modeli LLM znajdziesz na karcie modelu Gemma.
Uwagi i zagrożenia etyczne
Rozwój dużych modeli językowych (LLM) budzi pewne wątpliwości etyczne. Podczas tworzenia tych modeli wzięliśmy pod uwagę wiele różnych aspektów.
Szczegóły dotyczące modelu znajdziesz na tej samej karcie.
Przeznaczenie
Aplikacja
Modele Code Gemma mają szerokie zastosowanie, które różni się w przypadku modeli IT i PT. Poniższa lista potencjalnych zastosowań nie jest wyczerpująca. Celem tej listy jest dostarczenie informacji kontekstowych na temat możliwych zastosowań, które twórcy modelu wzięli pod uwagę w ramach trenowania i rozwijania modelu.
- Uzupełnianie kodu: modele PT można wykorzystać do uzupełniania kodu za pomocą rozszerzenia IDE
- Generowanie kodu: model IT może służyć do generowania kodu z rozszerzeniem IDE lub bez niego.
- Rozmowa o kodzie: model IT może obsługiwać interfejsy konwersacyjne, które omawiają kod
- Edukacja dotycząca kodowania: model IT umożliwia interaktywne naukę kodowania, pomaga w poprawianiu błędów w kodzie lub umożliwia ćwiczenie kodowania.
Zalety
W momencie wydania ta rodzina modeli zapewnia wydajne, otwarte implementacje dużych modeli językowych (LLM) zorientowanych na kod, które zostały zaprojektowane od podstaw z myślą o odpowiedzialnym rozwoju AI w porównaniu z modelami o podobnych rozmiarach.
Na podstawie danych o testach porównawczych kodowania opisanych w tym dokumencie okazało się, że te modele zapewniają lepszą skuteczność niż inne alternatywne otwarte modele o porównywalnej wielkości.