
صفحه مدل: CodeGemma
منابع و مستندات فنی:
شرایط استفاده: شرایط
نویسندگان: گوگل
اطلاعات مدل
خلاصه مدل
توضیحات
CodeGemma یک خانواده از مدلهای کد باز سبک وزن است که بر روی Gemma ساخته شدهاند. مدلهای CodeGemma فقط مدلهای رمزگشای متن به نوشتار و متن به کد هستند و بهعنوان ۷ میلیارد نسخه از پیش آموزشدیدهشده در دسترس هستند که در تکمیل کد و وظایف تولید کد تخصص دارند، یک نوع تنظیمشده با پارامتر ۷ میلیارد برای چت کد و دستورالعمل. زیر و یک نوع 2 میلیارد پارامتری از پیش آموزش دیده برای تکمیل سریع کد.
ورودی ها و خروجی ها
ورودی: برای انواع مدل های از پیش آموزش دیده: پیشوند کد و پسوند اختیاری برای سناریوهای تکمیل و تولید کد یا متن/اعلان زبان طبیعی. برای نوع مدل تنظیم شده توسط دستورالعمل: متن یا درخواست به زبان طبیعی.
خروجی: برای انواع مدل های از پیش آموزش دیده: تکمیل کد میانی، کد و زبان طبیعی. برای نوع مدل تنظیم شده توسط دستورالعمل: کد و زبان طبیعی.
نقل قول
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
داده های مدل
مجموعه داده های آموزشی
با استفاده از جما بهعنوان مدل پایه، نسخههای پیشآموزششده CodeGemma 2B و 7B بر روی 500 تا 1000 میلیارد توکن اضافی از دادههای عمدتاً زبان انگلیسی از مجموعه دادههای ریاضی منبع باز و کدهای مصنوعی تولید شده، آموزش داده میشوند.
پردازش داده های آموزشی
تکنیک های پیش پردازش داده های زیر برای آموزش CodeGemma استفاده شد:
- FIM - مدل های از پیش آموزش دیده CodeGemma بر وظایف پر کردن وسط (FIM) تمرکز می کنند. این مدل ها برای کار با هر دو حالت PSM و SPM آموزش دیده اند. تنظیمات FIM ما 80٪ تا 90٪ نرخ FIM با 50-50 PSM/SPM است.
- بستهبندی مبتنی بر نمودار وابستگی و تکنیکهای بستهبندی واژگانی مبتنی بر آزمون واحد: برای بهبود همسویی مدل با برنامههای کاربردی دنیای واقعی، نمونههای آموزشی را در سطح پروژه/مخزن ساختیم تا مرتبطترین فایلهای منبع را در هر مخزن قرار دهیم. به طور خاص، ما از دو تکنیک اکتشافی استفاده کردیم: بسته بندی مبتنی بر نمودار وابستگی و بسته بندی واژگانی مبتنی بر آزمون واحد.
- ما یک تکنیک جدید را برای تقسیم اسناد به پیشوند، وسط و پسوند توسعه دادیم تا پسوند در نقطهای طبیعیتر بهجای توزیع تصادفی صرف شروع شود.
- ایمنی: مانند Gemma، فیلترهای ایمنی دقیقی از جمله فیلتر کردن دادههای شخصی، فیلتر CSAM و فیلترهای دیگر بر اساس کیفیت محتوا و ایمنی را در راستای خطمشیهای خود به کار بردیم.
اطلاعات پیاده سازی
سخت افزار و چارچوب های مورد استفاده در طول آموزش
همانند Gemma ، CodeGemma بر روی آخرین نسل سخت افزار واحد پردازش تنسور (TPU) (TPUv5e)، با استفاده از مسیرهای JAX و ML آموزش دیده است.
اطلاعات ارزیابی
نتایج محک
رویکرد ارزشیابی
- معیارهای تکمیل کد: HumanEval (HE) (تک خط و پر کردن چند خط)
- معیارهای تولید کد: HumanEval، MBPP ، BabelCode (BC) [C++، C#، Go، Java، JavaScript، Kotlin، Python، Rust]
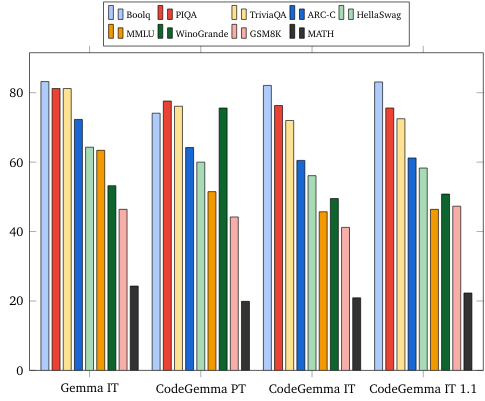
- پرسش و پاسخ: BoolQ ، PIQA ، TriviaQA
- زبان طبیعی: ARC-Challenge ، HellaSwag ، MMLU ، WinoGrande
- استدلال ریاضی: GSM8K ، MATH
نتایج محک کدگذاری
| معیار | 2B | 2B (1.1) | 7B | 7B-IT | 7B-IT (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37.8 | 44.5 | 56.1 | 60.4 |
| MBPP | 43.6 | 49.2 | 56.2 | 54.2 | 55.6 |
| HumanEval Single Line | 78.4 | 79.3 | 76.1 | 68.3 | 77.4 |
| HumanEval Multi Line | 51.4 | 51.0 | 58.4 | 20.1 | 23.7 |
| BC HE C++ | 24.2 | 19.9 | 32.9 | 42.2 | 46.6 |
| BC HE C# | 10.6 | 26.1 | 22.4 | 26.7 | 54.7 |
| BC HE برو | 20.5 | 18.0 | 21.7 | 28.6 | 34.2 |
| BC HE جاوا | 29.2 | 29.8 | 41.0 | 48.4 | 50.3 |
| جاوا اسکریپت BC HE | 21.7 | 28.0 | 39.8 | 46.0 | 48.4 |
| BC HE Kotlin | 28.0 | 32.3 | 39.8 | 51.6 | 47.8 |
| BC HE پایتون | 21.7 | 36.6 | 42.2 | 48.4 | 54.0 |
| BC HE زنگ | 26.7 | 24.2 | 34.1 | 36.0 | 37.3 |
| BC MBPP C++ | 47.1 | 38.9 | 53.8 | 56.7 | 63.5 |
| BC MBPP C# | 28.7 | 45.3 | 32.5 | 41.2 | 62.0 |
| BC MBPP برو | 45.6 | 38.9 | 43.3 | 46.2 | 53.2 |
| BC MBPP جاوا | 41.8 | 49.7 | 50.3 | 57.3 | 62.9 |
| BC MBPP جاوا اسکریپت | 45.3 | 45.0 | 58.2 | 61.4 | 61.4 |
| BC MBPP Kotlin | 46.8 | 49.7 | 54.7 | 59.9 | 62.6 |
| BC MBPP پایتون | 38.6 | 52.9 | 59.1 | 62.0 | 60.2 |
| BC MBPP Rust | 45.3 | 47.4 | 52.9 | 53.5 | 52.3 |
معیارهای زبان طبیعی (در مدلهای 7B)
اخلاق و ایمنی
ارزیابی های اخلاقی و ایمنی
رویکرد ارزیابی ها
روشهای ارزیابی ما شامل ارزیابیهای ساختاریافته و آزمایشهای داخلی قرمز از خطمشیهای محتوای مرتبط است. Red-teaming توسط تعدادی تیم مختلف انجام شد که هر کدام اهداف و معیارهای ارزیابی انسانی متفاوتی داشتند. این مدل ها بر اساس تعدادی از مقوله های مختلف مرتبط با اخلاق و ایمنی مورد ارزیابی قرار گرفتند، از جمله:
ارزیابی انسانی در مورد اطالعات مربوط به ایمنی محتوا و آسیب های بازنمایی برای جزئیات بیشتر در مورد رویکرد ارزیابی، کارت مدل Gemma را ببینید.
آزمایش ویژه قابلیتهای حمله سایبری، تمرکز بر آزمایش قابلیتهای هک مستقل و اطمینان از محدود بودن آسیبهای احتمالی.
نتایج ارزیابی
نتایج ارزیابیهای اخلاقی و ایمنی در آستانههای قابل قبولی برای رعایت سیاستهای داخلی برای مقولههایی مانند ایمنی کودک، ایمنی محتوا، آسیبهای بازنمایی، حفظ کردن، آسیبهای در مقیاس بزرگ قرار دارد. برای جزئیات بیشتر به کارت مدل Gemma مراجعه کنید.
استفاده از مدل و محدودیت ها
محدودیت های شناخته شده
مدلهای زبان بزرگ (LLM) بر اساس دادههای آموزشی و محدودیتهای ذاتی فناوری محدودیتهایی دارند. برای جزئیات بیشتر در مورد محدودیت های LLM به کارت مدل Gemma مراجعه کنید.
ملاحظات و خطرات اخلاقی
توسعه مدلهای زبان بزرگ (LLM) چندین نگرانی اخلاقی را ایجاد میکند. ما جنبه های متعددی را در توسعه این مدل ها به دقت در نظر گرفته ایم.
لطفاً برای جزئیات مدل به همین بحث در کارت مدل Gemma مراجعه کنید.
استفاده مورد نظر
برنامه
مدل های Code Gemma طیف وسیعی از کاربردها را دارند که بین مدل های IT و PT متفاوت است. فهرست زیر از کاربردهای بالقوه جامع نیست. هدف این فهرست ارائه اطلاعات زمینه ای در مورد موارد استفاده احتمالی است که سازندگان مدل به عنوان بخشی از آموزش و توسعه مدل در نظر گرفته اند.
- تکمیل کد: مدل های PT را می توان برای تکمیل کد با پسوند IDE استفاده کرد
- تولید کد: مدل IT را می توان برای تولید کد با یا بدون پسوند IDE استفاده کرد
- مکالمه کد: مدل IT می تواند رابط های مکالمه ای را که کد را مورد بحث قرار می دهند، تقویت کند
- آموزش کد: مدل IT از تجربیات یادگیری کد تعاملی پشتیبانی می کند، به تصحیح نحو کمک می کند یا تمرین کدنویسی را ارائه می دهد.
مزایا
در زمان انتشار، این خانواده از مدلها، پیادهسازیهای مدل زبان بزرگ با تمرکز بر کد باز را با کارایی بالا ارائه میکنند که از ابتدا برای توسعه هوش مصنوعی مسئول در مقایسه با مدلهای با اندازه مشابه طراحی شدهاند.
با استفاده از معیارهای ارزیابی معیار کدگذاری که در این سند توضیح داده شده است، این مدلها نشان دادهاند که عملکرد برتری نسبت به سایر جایگزینهای مدل باز با اندازه قابل مقایسه ارائه میدهند.