
模型頁面: CodeGemma
資源和技術文件:
使用條款: 條款
作者:Google
款式資訊
模型摘要
說明
CodeGemma 是一系列以 Gemma 為基礎的輕量級開放式程式碼模型。CodeGemma 模型是文字轉文字和文字轉程式碼的解碼器專用模型,可提供 70 億個參數的預先訓練變化版本,專門用於程式碼補全和程式碼生成工作;70 億個參數的訓練指令變化版本,可用於程式碼對話和遵循指令;以及 20 億個參數的預先訓練變化版本,可用於快速完成程式碼。
輸入和輸出
輸入內容:針對預先訓練的模型變化版本:程式碼前置字元和選用的後置字元,用於程式碼完成和產生情境或自然語言文字/提示。針對以指令微調的模型變化版本:自然語言文字或提示。
輸出內容:針對預先訓練的模型變化版本:填入中間程式碼、程式碼和自然語言。針對指令微調模型變化版本:程式碼和自然語言。
引用內容
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
模型資料
訓練資料集
使用 Gemma 做為基礎模型,CodeGemma 2B 和 7B 預先訓練的變化版本會進一步訓練開放原始碼數學資料集和合成產生的程式碼,其中的符記主要為英文語言資料,數量介於 500 至 10000 億之間。
訓練資料處理
我們使用下列資料預先處理技術訓練 CodeGemma:
- FIM - 預先訓練的 CodeGemma 模型著重於填空題 (FIM) 工作。這些模型經過訓練,可同時支援 PSM 和 SPM 模式。我們的 FIM 設定為 80% 至 90% FIM 費率,以及 50-50 的 PSM/SPM。
- 依據依附元件圖表進行封裝,以及依據單元測試進行字彙封裝的技術:為了讓模型與實際應用程式保持一致,我們在專案/存放區層級建立訓練範例,以便在每個存放區內放置最相關的來源檔案。具體來說,我們採用了兩種啟發式技術:依據依附元件圖表進行封裝,以及依據單元測試進行字彙封裝。
- 我們開發了一種新技術,可將文件分割成前置字串、中間字串和後置字串,讓後置字串從語法上更自然的點開始,而非完全隨機分布。
- 安全性:與 Gemma 類似,我們也採用嚴格的安全篩選機制,包括篩除個人資料、篩除兒少性剝削內容,以及根據內容品質和安全性篩選其他內容,以符合我們的政策。
實作資訊
訓練期間使用的硬體和架構
如同 Gemma,CodeGemma 也是使用 JAX 和 ML Pathways,在最新一代 Tensor Processing Unit (TPU) 硬體 (TPUv5e) 上進行訓練。
評估作業資訊
基準測試結果
評估方法
- 程式碼完成基準:HumanEval (HE) (單行和多行填入)
- 程式碼產生基準:HumanEval、MBPP、BabelCode (BC) [C++、C#、Go、Java、JavaScript、Kotlin、Python、Rust]
- 問答:BoolQ、PIQA、TriviaQA
- 自然語言:ARC-Challenge、HellaSwag、MMLU、WinoGrande
- 數學推理:GSM8K、MATH
程式設計基準測試結果
| 基準 | 20 億 | 2B (1.1) | 7B | 7B-IT | 7B-IT (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37.8 | 44.5 | 56.1 | 60.4 |
| MBPP | 43.6 | 49.2 | 56.2 | 54.2 | 55.6 |
| HumanEval Single Line | 78.4 | 79.3 | 76.1 | 68.3 | 77.4 |
| HumanEval Multi Line | 51.4 | 51.0 | 58.4 | 20.1 | 23.7 |
| BC HE C++ | 24.2 | 19.9 | 32.9 | 42.2 | 46.6 |
| BC HE C# | 10.6 | 26.1 | 22.4 | 26.7 | 54.7 |
| BC HE Go | 20.5 | 18.0 | 21.7 | 28.6 | 34.2 |
| BC HE Java | 29.2 | 29.8 | 41.0 | 48.4 | 50.3 |
| BC HE JavaScript | 21.7 | 28.0 | 39.8 | 46.0 | 48.4 |
| BC HE Kotlin | 28.0 | 32.3 | 39.8 | 51.6 | 47.8 |
| BC HE Python | 21.7 | 36.6 | 42.2 | 48.4 | 54.0 |
| BC HE Rust | 26.7 | 24.2 | 34.1 | 36.0 | 37.3 |
| BC MBPP C++ | 47.1 | 38.9 | 53.8 | 56.7 | 63.5 |
| BC MBPP C# | 28.7 | 45.3 | 32.5 | 41.2 | 62.0 |
| BC MBPP Go | 45.6 | 38.9 | 43.3 | 46.2 | 53.2 |
| BC MBPP Java | 41.8 | 49.7 | 50.3 | 57.3 | 62.9 |
| BC MBPP JavaScript | 45.3 | 45.0 | 58.2 | 61.4 | 61.4 |
| BC MBPP Kotlin | 46.8 | 49.7 | 54.7 | 59.9 | 62.6 |
| BC MBPP Python | 38.6 | 52.9 | 59.1 | 62.0 | 60.2 |
| BC MBPP Rust | 45.3 | 47.4 | 52.9 | 53.5 | 52.3 |
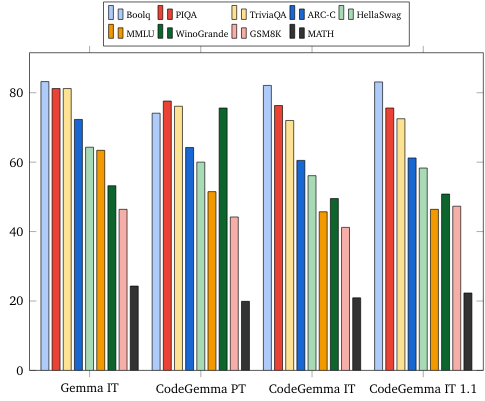
自然語言基準 (使用 7B 模型)
道德與安全
倫理和安全性評估
評估方法
我們的評估方法包括結構化評估,以及針對相關內容政策進行內部紅隊測試。紅隊評估是由多個不同團隊進行,每個團隊都有不同的目標和人工評估指標。這些模型是根據與倫理和安全相關的多個類別進行評估,包括:
針對涵蓋內容安全性和表徵性危害的提示進行人工評估。如要進一步瞭解評估方法,請參閱 Gemma 模型資訊卡。
針對網路攻擊功能進行特定測試,著重於測試自動駭客功能,並確保潛在的危害受到限制。
評估結果
倫理和安全性評估結果符合兒童安全、內容安全性、表徵性危害、記憶、大規模危害等類別的內部政策可接受門檻。詳情請參閱 Gemma 模型資訊卡。
模型使用方式和限制
已知限制
大型語言模型 (LLM) 會受到訓練資料和技術本身的限制。如要進一步瞭解 LLM 的限制,請參閱 Gemma 模型資訊卡。
倫理考量和風險
開發大型語言模型 (LLM) 時,會產生一些倫理問題。我們在開發這些模型時,已仔細考量多項因素。
如需模型詳細資訊,請參閱 Gemma 模型資訊卡中的相同討論內容。
預定用途
應用程式
Code Gemma 模型的應用範圍廣泛,IT 和 PT 模型各有不同。以下列出部分可能用途,這份清單的目的,是提供關於可能用途的背景資訊,這些用途是模型建立者在模型訓練和開發期間考慮過的。
- 程式碼完成功能:可透過 IDE 擴充功能使用 PT 模型完成程式碼
- 程式碼產生:IT 模型可用於產生程式碼,不論是否使用 IDE 擴充功能
- 程式碼對話:IT 模型可支援討論程式碼的對話介面
- 程式碼教育:IT 模型支援互動式程式碼學習體驗,協助修正語法或提供程式設計練習
優點
在發布時,這一系列模型提供高效能、以開放程式碼為重點的大型語言模型實作項目,與同樣大小的模型相比,這些模型是從頭開始設計,以便進行負責任的 AI 開發。
根據本文件所述的程式碼基準評估指標,這些模型的效能優於其他相近大小的開放式模型替代方案。