
Using artificial intelligence (AI) technology in a specific spoken language is a critical need for many businesses to be able to use it effectively. The Gemma family of models have some multilingual capabilities, but using it in languages other than English frequently produces less than ideal results.
Fortunately, you don't need to teach Gemma an entire spoken language to be able to complete tasks in that language. What's more, you can tune Gemma models to complete specific tasks in a language with much less data and effort than you might think. Using about 20 examples of requests and expected responses in your target language you can get Gemma to help you solve many different business problems in the language that best serves you and your customers.
For a video overview of the project and how to extend it, including insights from the folks who build it, check out the Spoken Language AI Assistant Build with Google AI video. You can also review the code for this project in the Gemma Cookbook code repository. Otherwise, you can get started extending the project using the following instructions.
Overview
This tutorial walks you through setting up, running, and extending a spoken language task application built with Gemma and Python. The application provides a basic web user interface that you can modify to fit your needs. The application is built to generate replies to customer emails for a fictitious Korean bakery, and all the language input and output is handled entirely in Korean. You can use this application pattern with any language and any business task that uses text input and text output.
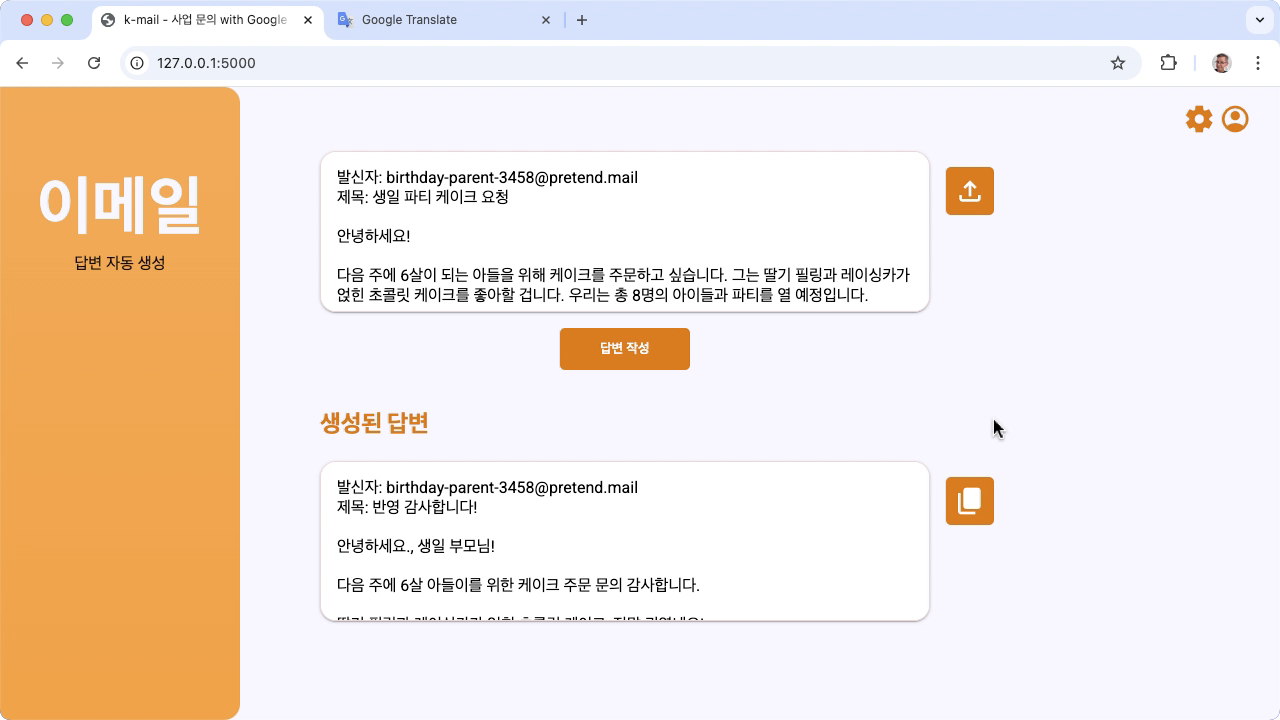
Figure 1. Project user interface, for Korean bakery email inquiries
Hardware requirements
Run this tuning process on a computer with a graphics processing unit (GPU) or a Tensor processing unit (TPU), and sufficient memory to hold the existing model, plus the tuning data. To run the tuning configuration in this project, you need about 16GB of GPU memory, about the same amount of regular RAM, and a minimum of 50GB of disk space.
You can run the Gemma model tuning portion of this tutorial using a Colab environment with a T4 GPU runtime. If you are building this project on a Google Cloud VM instance, configure the instance following these requirements:
- GPU hardware: A NVIDIA T4 is required to run this project, and a NVIDIA L4 or higher is recommended.
- Operating System: Select a Deep Learning on Linux option, specifically the Deep Learning VM with CUDA 12.3 M124 with pre-installed GPU software drivers.
- Boot disk size: Provision at least 50GB of disk space for your data, models, and supporting software.
Project setup
These instructions walk you through getting this project ready for development and testing. The general setup steps include installing prerequisite software, cloning the project from the code repository, setting a few environment variables, installing Python libraries, and testing the web application.
Install and configure
This project uses Python 3 and Virtual Environments (venv) to manage packages
and run the application. The following installation instructions are for a Linux
host machine.
To install the required software:
Install Python 3 and the
venvvirtual environment package for Python.sudo apt update sudo apt install git pip python3-venv
Clone the project
Download the project code to your development computer. You need git source control software to retrieve the project source code.
To download the project code:
Clone the git repository using the following command.
git clone https://github.com/google-gemini/gemma-cookbook.gitOptionally, configure your local git repository to use sparse checkout, so you have only the files for the project.
cd gemma-cookbook/ git sparse-checkout set Demos/spoken-language-tasks/ git sparse-checkout init --cone
Install Python libraries
Install the Python libraries with the venv Python virtual environment
activated to manage Python packages and dependencies. Make sure you activate the
Python virtual environment before installing Python libraries with the pip
installer. For more information about using Python virtual environments, see the
Python venv documentation.
To install the Python libraries:
In a terminal window, navigate to the
spoken-language-tasksdirectory:cd Demos/spoken-language-tasks/Configure and activate Python virtual environment (venv) for this project:
python3 -m venv venv source venv/bin/activateInstall the required Python libraries for this project using the
setup_pythonscript../setup_python.sh
Set environment variables
Set a few environment variables that are required to allow this code project to
run, including a Kaggle username and Kaggle token key. You must have a Kaggle
account and request access to the Gemma models to be able to download them. For
this project, you add your Kaggle Username and Kaggle Token Key to two .env
files, which are read by the web application and the tuning program,
respectively.
To set the environment variables:
- Obtain your Kaggle username and your token key by following the instructions in the Kaggle documentation.
- Get access to the Gemma model by following the Get access to Gemma instructions in the Gemma Setup page.
- Create environment variable files for the project, by creating a
.envtext file at each these locations in your clone of the project:k-mail-replier/k_mail_replier/.env k-gemma-it/.env
After creating the
.envtext files, add the following settings to both files:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
Run and test the application
Once you have completed the installation and configuration of the project, run the web application to confirm that you have configured it correctly. You should do this as a baseline check before editing the project for your own use.
To run and test the project:
In a terminal window, navigate to the
/k_mail_replier/directory:cd spoken-language-tasks/k-mail-replier/Run the application using the
run_flask_app.shscript:./run_flask_app.shAfter starting the web application, the program code lists a URL where you can browse and test. Typically, this address is:
http://127.0.0.1:5000/In the web interface, press the 답변 작성 button below the first input field to generate a response from the model.
The first response from the model after you run the application takes longer since it must complete initialization steps on the first generation run. Subsequent prompt requests and generation on an already-running web application complete in less time.
Extend the application
Once you have the application running, you can extend it by modifying the user interface and business logic to make it work for tasks that are relevant to you or your business. You can also modify the behavior of the Gemma model using the application code by changing the components of the prompt that the app sends to the generative AI model.
The application provides instructions to the model along with the input data from the user a complete prompt of the model. You can modify these instructions to change the behavior of the model, such as specifying that the model should extract information from the request and put it in structured data format, such as JSON. A simpler way to change the behavior of the model is to provide additional instructions or guidance for the model's response, such as specifying that the generated replies should be written in a polite tone.
To modify prompt instructions:
- In the spoken-language-task project, open the
k-mail-replier/k_mail_replier/app.pycode file. In the
app.pycode, add additions instructions to theget_prompt():function:def get_prompt(): return "발신자에게 요청에 대한 감사를 전하고, 곧 자세한 내용을 알려드리겠다고 정중하게 답장해 주세요. 정중하게 답변해 주세요!:\n"
This example adds the phrase "Please write a polite response!" to the instructions in Korean.
Providing additional prompt instruction can strongly influence the generated output, and takes significantly less effort to implement. You should try this method first to see if you can get the behavior you want from the model. However, using prompt instructions to modify a Gemma model's behavior has its limits. In particular, the overall input token limit of the model, which is 8,192 tokens for Gemma 2, requires you to balance detailed prompt instructions with the size of the new data you provide so that you stay under that limit.
Furthermore, when you want Gemma to perform tasks in a language other than English, simply prompting the base model is not likely to produce reliably useful results. Instead, you should tune the model with examples in the target language, and then consider modifying the prompt instructions to make smaller adjustments to the output of the tuned model.
Tune the model
Performing fine-tuning of a Gemma model is the recommended way to get it to respond effectively in a spoken language other than English. However, you don't need to aim for full fluency in your target language for the model to be able to complete tasks in that language. You can achieve basic functionality in your target language for a task with around 20 examples. This section of the tutorial explains how to set up and run fine-tuning on a Gemma model for a specific task, in a specific language.
The following directions explain how to perform the fine-tuning operation on a VM environment, however, you can also perform this tuning operation using the associated Colab noteboook for this project.
Hardware requirements
The compute requirements for fine-tuning are the same as the hardware requirements for rest of the project. You can run the tuning operation in a Colab environment with a T4 GPU runtime if you limit the input tokens to 256 and the batch size to 1.
Prepare data
Before you start tuning a Gemma model, you must prepare data for tuning. When you are tuning a model for a specific task and language, you need a set of request and response examples in that target language. These examples should show the request text, without any instructions, and the expected response text. To start with, you should prepare a dataset with about 20 examples. These examples should represent a full variety of requests and the ideal responses. Make sure that the requests and responses are not repetitive, as that can cause the models responses to be repetitive and not adjust appropriately to variations in requests. The following table shows a few sample records from the dataset of this code example:
| Request | Response |
|---|---|
| 안녕하세요, 2주 뒤에 있을 아이 생일을 위해 3호 케이크 3개를 주문하고 싶은데 가능할까요? | 고객님, 안녕하세요. 2주 뒤 아이 생일을 위한 3호 케이크 2개 주문 문의 감사합니다. 네, 3호 케이크 2개 주문 가능합니다. 아이 생일 케이크인 만큼 더욱 신경 써서 정성껏 준비하겠습니다. 혹시 원하시는 디자인이나 특별한 요청 사항이 있으시면 편하게 말씀해주세요. 픽업 날짜와 시간을 알려주시면 더욱 자세한 안내를 도와드리겠습니다. 다시 한번 문의 감사드리며, 아이 생일 진심으로 축하합니다! [가게 이름] 드림 |
| 안녕하세요, 9월 15일에 있을 아들의 돌잔치를 위해 케이크를 주문하고 싶습니다. - 케이크 종류: 생크림 케이크 - 크기: 2호 - 디자인: 아기자기한 동물 디자인 - 문구: "첫 생일 축하해, 사랑하는 아들!" - 픽업 날짜 및 시간: 9월 14일 오후 3시 가격 및 주문 가능 여부를 알려주시면 감사하겠습니다. 감사합니다. 김민지 드림 | 안녕하세요, 김민지 님, 9월 15일 아드님의 돌잔치를 위한 케이크 주문 문의 감사합니다. - 생크림 케이크 2호, 아기자기한 동물 디자인, "첫 생일 축하해, 사랑하는 아들!" 문구, 9월 14일 오후 3시 픽업 모두 가능합니다. - 가격은 5만원입니다. 주문을 원하시면 연락 주세요 감사합니다. [가게 이름] 드림 |
Table 1. Partial listing of the tuning dataset for the Korean bakery email responder.
Data format and loading
You can store your tuning data in any format that is convenient, including
database records, JSON files, CSV, or plain text files, as long as you have the
means to retrieve the records with Python code. For convenience, the example
tuning program gets the records from an
online repository.
In this example turning program, the tuning dataset is loaded in the
k-gemma-it/main.py module using the prepare_tuning_dataset() function:
def prepare_tuning_dataset():
tokenizer = keras_nlp.models.GemmaTokenizer.from_preset(model_id)
# load data from repository (or local directory)
from datasets import load_dataset
ds = load_dataset(
# Dataset : https://huggingface.co/datasets/bebechien/korean_cake_boss
"bebechien/korean_cake_boss",
split="train",
)
...
As mentioned previously, you can store the dataset in a format that's convenient, as long as you can retrieve the requests with the associated responses and assemble them into a text string which is used as a tuning record.
Assemble tuning records
For the actual tuning process, each request and response is assembled into a
single string with the prompt instructions and tags to indicate the content of
the request and the content of the response. This tuning program then tokenizes
the string for consumption by the model. You can see the code for assembling a
tuning record in the k-gemma-it/main.py module prepare_tuning_dataset()
function, as follows:
def prepare_tuning_dataset():
...
prompt_instruction = "다음에 대한 이메일 답장을 작성해줘."
for x in data:
item = f"<start_of_turn>user\n{prompt_instruction}\n\"{x['input']}\"<end_of_turn>\n<start_of_turn>model\n{x['output']}<end_of_turn>"
length = len(tokenizer(item))
# skip data if the token length is longer than our limit
if length < token_limit:
tuning_dataset.append(item)
if(len(tuning_dataset)>=num_data_limit):
break
...
This function reads in the data and formats it by adding start_of_turn and
end_of_turn tags which is the
required format
when providing data for tuning a Gemma model. This code also inserts a
prompt_instruction for each request, which you should edit as appropriate for
your application.
Generate model weights
Once you have the tuning data in place and loading, you can run the tuning program. The tuning process for this example application uses the Keras NLP library to tune the model with a Low Rank Adaptation, or LoRA technique, to generate new model weights. Compared to full precision tuning, using LoRA is significantly more memory efficient because it approximates the changes to the model weights. You can then overlay these approximated weights onto the existing model weights to change the model's behavior.
To perform the tuning run and calculate new weights:
In a terminal window, navigate to the
k-gemma-it/directory.cd spoken-language-tasks/k-gemma-it/Run the tuning process using the
tune_modelscript:./tune_model.sh
The tuning process takes several minutes depending on your available compute
resources. When it completes successfully, the tuning program writes new *.h5
weight files in the k-gemma-it/weights directory with the following format:
gemma2-2b_k-tuned_4_epoch##.lora.h5
Troubleshooting
If the tuning does not complete successfully, there are two likely reasons:
- Out of memory / resources exhausted: These errors occur when the
tuning process requests memory that exceeds the available GPU memory or CPU
memory. Make sure you are not running the web application while the tuning
process is running. If you are tuning on a device with 16GB of GPU memory,
makes sure your have the
token_limitset to 256 and thebatch_sizeset to 1. - GPU drivers not installed or incompatible with JAX: The turning process requires that the compute device has hardware drivers installed which are compatible with the version of the JAX libraries. For more details, see the JAX installation documentation.
Deploy tuned model
The tuning process generates multiple weights based on the tuning data and the total number of epochs set in the tuning application. By default, the tuning program generates 20 model weight files, one for each tuning epoch. Each successive tuning epoch produces weights that more accurately reproduce the results of the tuning data. You can see the accuracy rates for each epoch in the terminal output of the tuning process, as follows:
...
Epoch 14/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 567ms/step - loss: 0.4026 - sparse_categorical_accuracy: 0.8235
Epoch 15/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 569ms/step - loss: 0.3659 - sparse_categorical_accuracy: 0.8382
Epoch 16/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 571ms/step - loss: 0.3314 - sparse_categorical_accuracy: 0.8538
Epoch 17/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 572ms/step - loss: 0.2996 - sparse_categorical_accuracy: 0.8686
Epoch 18/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 574ms/step - loss: 0.2710 - sparse_categorical_accuracy: 0.8801
Epoch 19/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 575ms/step - loss: 0.2451 - sparse_categorical_accuracy: 0.8903
Epoch 20/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 575ms/step - loss: 0.2212 - sparse_categorical_accuracy: 0.9021
While you want the accuracy rate to be relatively high, around 0.80 to 0.90, you do not want the rate to be too high, or very close to 1.00, because that means the weights have come close to overfitting the tuning data. When that happens, the model does not perform well on requests that is significantly different from the tuning examples. By default, the deployment script picks the epoch 17 weights, which typically have an accuracy rate around 0.90.
To deploy the generated weights to the web application:
In a terminal window, navigate to the
k-gemma-it/directory.cd spoken-language-tasks/k-gemma-it/Run the tuning process using the
deploy_weightsscript:./deploy_weights.sh
After running this script, you should see a new *.h5 file in the
k-mail-replier/k_mail_replier/weights/ directory.
Test the new model
Once you have deployed the new weights to the application, it's time to try out the newly tuned model. You can do this by re-running the web application and generating a response.
To run and test the project:
In a terminal window, navigate to the
/k_mail_replier/directory.cd spoken-language-tasks/k-mail-replier/Run the application using the
run_flask_app.shscript:./run_flask_app.shAfter starting the web application, you the program code lists a URL where you can browse and test, typically this address is:
http://127.0.0.1:5000/In the web interface, press the 답변 작성 button below the first input field to generate a response from the model.
You have now tuned and deployed a Gemma model in an application! Experiment with the application and try to determine the limits of the tuned model's generation capability for your task. If you find scenarios where the model does not perform well, consider adding some of those requests to your list of tuning example data by adding the request and providing an ideal response. Then re-run the tuning process, re-deploy the new weights, and test the output.
Additional resources
For more information about this project, see the Gemma Cookbook code repository. If you need help building the application or are looking to collaborate with other developers, check out the Google Developers Community Discord server. For more Build with Google AI projects, check out the video playlist.