
La tarea MediaPipe Gesture Recognizer te permite reconocer gestos con las manos en tiempo real y proporciona los resultados del gesto reconocido y los puntos de referencia de las manos detectadas. En estas instrucciones, se muestra cómo usar Gesture Recognizer para apps web y de JavaScript.
Puedes ver esta tarea en acción en la demostración. Para obtener más información sobre las capacidades, los modelos y las opciones de configuración de esta tarea, consulta la Descripción general.
Ejemplo de código
El código de ejemplo de Gesture Recognizer proporciona una implementación completa de esta tarea en JavaScript para tu referencia. Este código te ayuda a probar esta tarea y a comenzar a compilar tu propia app de reconocimiento de gestos. Puedes ver, ejecutar y editar el ejemplo de Gesture Recognizer con solo tu navegador web.
Configuración
En esta sección, se describen los pasos clave para configurar tu entorno de desarrollo específicamente para usar Gesture Recognizer. Para obtener información general sobre cómo configurar tu entorno de desarrollo web y de JavaScript, incluidos los requisitos de versión de la plataforma, consulta la Guía de configuración para la Web.
Paquetes de JavaScript
El código del Reconocedor de gestos está disponible a través del paquete @mediapipe/tasks-vision de NPM de MediaPipe. Puedes encontrar y descargar estas bibliotecas siguiendo las instrucciones de la guía de configuración de la plataforma.
Puedes instalar los paquetes requeridos a través de NPM con el siguiente comando:
npm install @mediapipe/tasks-vision
Si deseas importar el código de la tarea a través de un servicio de red de distribución de contenido (CDN), agrega el siguiente código en la etiqueta <head> de tu archivo HTML:
<!-- You can replace JSDeliver with another CDN if you prefer to -->
<head>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision/vision_bundle.mjs"
crossorigin="anonymous"></script>
</head>
Modelo
La tarea MediaPipe Gesture Recognizer requiere un modelo entrenado que sea compatible con esta tarea. Para obtener más información sobre los modelos entrenados disponibles para Gesture Recognizer, consulta la sección Modelos del resumen de la tarea.
Selecciona y descarga el modelo, y, luego, guárdalo en el directorio de tu proyecto:
<dev-project-root>/app/shared/models/
Crea la tarea
Usa una de las funciones createFrom...() de Gesture Recognizer para preparar la tarea para ejecutar inferencias. Usa la función createFromModelPath() con una ruta de acceso relativa o absoluta al archivo del modelo entrenado.
Si tu modelo ya está cargado en la memoria, puedes usar el método createFromModelBuffer().
En el siguiente ejemplo de código, se muestra el uso de la función createFromOptions() para configurar la tarea. La función createFromOptions te permite personalizar el reconocedor de gestos con opciones de configuración. Para obtener más información sobre las opciones de configuración, consulta Opciones de configuración.
El siguiente código muestra cómo compilar y configurar la tarea con opciones personalizadas:
// Create task for image file processing:
const vision = await FilesetResolver.forVisionTasks(
// path/to/wasm/root
"https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision@latest/wasm "
);
const gestureRecognizer = await GestureRecognizer.createFromOptions(vision, {
baseOptions: {
modelAssetPath: "https://storage.googleapis.com/mediapipe-tasks/gesture_recognizer/gesture_recognizer.task"
},
numHands: 2
});
Opciones de configuración
Esta tarea tiene las siguientes opciones de configuración para las aplicaciones web:
| Nombre de la opción | Descripción | Rango de valores | Valor predeterminado |
|---|---|---|---|
runningMode |
Establece el modo de ejecución de la tarea. Existen dos modos: IMAGE: Es el modo para las entradas de una sola imagen. VIDEO: Es el modo para los fotogramas decodificados de un video o de una transmisión en vivo de datos de entrada, como los de una cámara. |
{IMAGE, VIDEO} |
IMAGE |
num_hands |
El GestureRecognizer puede detectar una cantidad máxima de manos.
|
Any integer > 0 |
1 |
min_hand_detection_confidence |
Es la puntuación de confianza mínima para que la detección de manos se considere exitosa en el modelo de detección de palmas. | 0.0 - 1.0 |
0.5 |
min_hand_presence_confidence |
Es la puntuación de confianza mínima de la puntuación de presencia de la mano en el modelo de detección de puntos de referencia de la mano. En el modo de video y el modo de transmisión en vivo del Reconocedor de gestos, si la puntuación de confianza de presencia de la mano del modelo de puntos de referencia de la mano está por debajo de este umbral, se activa el modelo de detección de palmas. De lo contrario, se usa un algoritmo de monitoreo de manos ligero para determinar la ubicación de las manos para la detección de puntos de referencia posterior. | 0.0 - 1.0 |
0.5 |
min_tracking_confidence |
Es la puntuación de confianza mínima para que el monitoreo de manos se considere exitoso. Es el umbral de IoU del cuadro delimitador entre las manos en el fotograma actual y el último. En los modos Video y Stream del Reconocedor de gestos, si falla el seguimiento, el Reconocedor de gestos activa la detección de manos. De lo contrario, se omite la detección de manos. | 0.0 - 1.0 |
0.5 |
canned_gestures_classifier_options |
Opciones para configurar el comportamiento del clasificador de gestos predefinidos. Los gestos predeterminados son ["None", "Closed_Fist", "Open_Palm", "Pointing_Up", "Thumb_Down", "Thumb_Up", "Victory", "ILoveYou"]. |
|
|
custom_gestures_classifier_options |
Opciones para configurar el comportamiento del clasificador de gestos personalizados. |
|
|
Preparar los datos
El Reconocedor de gestos puede reconocer gestos en imágenes en cualquier formato compatible con el navegador host. La tarea también controla el preprocesamiento de la entrada de datos, incluido el cambio de tamaño, la rotación y la normalización de valores. Para reconocer gestos en videos, puedes usar la API para procesar rápidamente un fotograma a la vez, con la marca de tiempo del fotograma para determinar cuándo ocurren los gestos en el video.
Ejecuta la tarea
El Reconocedor de gestos usa los métodos recognize() (con el modo de ejecución 'image') y recognizeForVideo() (con el modo de ejecución 'video') para activar inferencias. La tarea procesa los datos, intenta reconocer los gestos con las manos y, luego, informa los resultados.
En el siguiente código, se muestra cómo ejecutar el procesamiento con el modelo de tareas:
Imagen
const image = document.getElementById("image") as HTMLImageElement; const gestureRecognitionResult = gestureRecognizer.recognize(image);
Video
await gestureRecognizer.setOptions({ runningMode: "video" }); let lastVideoTime = -1; function renderLoop(): void { const video = document.getElementById("video"); if (video.currentTime !== lastVideoTime) { const gestureRecognitionResult = gestureRecognizer.recognizeForVideo(video); processResult(gestureRecognitionResult); lastVideoTime = video.currentTime; } requestAnimationFrame(() => { renderLoop(); }); }
Las llamadas a los métodos recognize() y recognizeForVideo() del Reconocedor de gestos se ejecutan de forma síncrona y bloquean el subproceso de la interfaz de usuario. Si reconoces gestos en los fotogramas de video de la cámara de un dispositivo, cada reconocimiento bloqueará el subproceso principal. Para evitar esto, puedes implementar trabajadores web para ejecutar los métodos recognize() y recognizeForVideo() en otro subproceso.
Para obtener una implementación más completa de la ejecución de una tarea de Gesture Recognizer, consulta el ejemplo.
Cómo controlar y mostrar los resultados
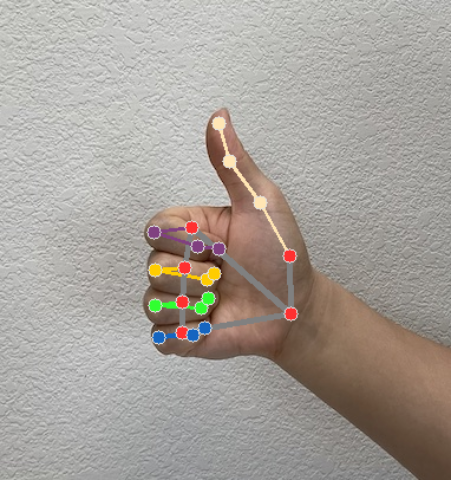
El Reconocedor de gestos genera un objeto de resultado de detección de gestos para cada ejecución de reconocimiento. El objeto de resultado contiene marcas de referencia de la mano en coordenadas de la imagen, marcas de referencia de la mano en coordenadas mundiales, lateralidad(mano izquierda o derecha) y categorías de gestos de la mano de las manos detectadas.
A continuación, se muestra un ejemplo de los datos de resultado de esta tarea:
El GestureRecognizerResult resultante contiene cuatro componentes, y cada componente es un array en el que cada elemento contiene el resultado detectado de una sola mano detectada.
Lateralidad
La lateralidad representa si las manos detectadas son la izquierda o la derecha.
Gestos
Son las categorías de gestos reconocidas de las manos detectadas.
Puntos de referencia
Hay 21 puntos de referencia de la mano, cada uno compuesto por coordenadas
x,yyz. Las coordenadasxyyse normalizan en [0.0, 1.0] según el ancho y la altura de la imagen, respectivamente. La coordenadazrepresenta la profundidad del punto de referencia, y la profundidad en la muñeca es el origen. Cuanto menor sea el valor, más cerca estará el punto de referencia de la cámara. La magnitud dezusa aproximadamente la misma escala quex.Monumentos universales
Los 21 puntos de referencia de la mano también se presentan en coordenadas mundiales. Cada punto de referencia se compone de
x,yyz, que representan coordenadas 3D del mundo real en metros con el origen en el centro geométrico de la mano.
GestureRecognizerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Gestures:
Categories #0:
score : 0.76893
categoryName : Thumb_Up
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
En las siguientes imágenes, se muestra una visualización del resultado de la tarea:
Para obtener una implementación más completa de la creación de una tarea de Gesture Recognizer, consulta el ejemplo.