

MediaPipe Pose Landmarker 작업을 사용하면 이미지 또는 동영상에서 사람의 신체 랜드마크를 감지할 수 있습니다. 이 태스크를 사용하여 주요 신체 부위를 식별하고, 자세를 분석하고, 움직임을 분류할 수 있습니다. 이 태스크에서는 단일 이미지 또는 동영상으로 작동하는 머신러닝 (ML) 모델을 사용합니다. 이 태스크는 신체 자세 랜드마크를 이미지 좌표와 3차원 실제 좌표로 출력합니다.
시작하기
대상 플랫폼의 구현 가이드를 따라 이 작업을 시작합니다. 다음 플랫폼별 가이드에서는 권장 모델, 권장 구성 옵션이 포함된 코드 예시 등 이 작업의 기본 구현을 안내합니다.
태스크 세부정보
이 섹션에서는 이 태스크의 기능, 입력, 출력, 구성 옵션을 설명합니다.
기능
- 입력 이미지 처리 - 처리에는 이미지 회전, 크기 조절, 정규화, 색상 공간 변환이 포함됩니다.
- 점수 기준점: 예측 점수를 기준으로 결과를 필터링합니다.
| 태스크 입력 | 태스크 출력 |
|---|---|
Pose Landmarker는 다음 데이터 유형 중 하나를 입력으로 받습니다.
|
Pose Landmarker는 다음과 같은 결과를 출력합니다.
|
구성 옵션
이 태스크에는 다음과 같은 구성 옵션이 있습니다.
| 옵션 이름 | 설명 | 값 범위 | 기본값 |
|---|---|---|---|
running_mode |
태스크의 실행 모드를 설정합니다. 모드는 세 가지입니다. IMAGE: 단일 이미지 입력의 모드입니다. 동영상: 동영상의 디코딩된 프레임 모드입니다. LIVE_STREAM: 카메라와 같은 입력 데이터의 라이브 스트림 모드입니다. 이 모드에서는 결과를 비동기식으로 수신할 리스너를 설정하려면 resultListener를 호출해야 합니다. |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
num_poses |
포즈 랜드마커에서 감지할 수 있는 최대 포즈 수입니다. | Integer > 0 |
1 |
min_pose_detection_confidence |
포즈 감지가 성공으로 간주되는 최소 신뢰도 점수입니다. | Float [0.0,1.0] |
0.5 |
min_pose_presence_confidence |
포즈 랜드마크 감지에서 포즈 존재 점수의 최소 신뢰도 점수입니다. | Float [0.0,1.0] |
0.5 |
min_tracking_confidence |
포즈 추적이 성공으로 간주되는 최소 신뢰도 점수입니다. | Float [0.0,1.0] |
0.5 |
output_segmentation_masks |
포즈 랜드마커가 감지된 포즈의 세분화 마스크를 출력하는지 여부입니다. | Boolean |
False |
result_callback |
포즈 랜드마커가 라이브 스트림 모드일 때 랜드마커 결과를 비동기식으로 수신하도록 결과 리스너를 설정합니다.
실행 모드가 LIVE_STREAM로 설정된 경우에만 사용할 수 있습니다. |
ResultListener |
N/A |
모델
포즈 랜드마커는 일련의 모델을 사용하여 포즈 랜드마크를 예측합니다. 첫 번째 모델은 이미지 프레임 내에서 사람의 신체를 감지하고 두 번째 모델은 신체에서 랜드마크를 찾습니다.
다음 모델은 다운로드 가능한 모델 번들로 함께 패키징됩니다.
- 자세 감지 모델: 몇 가지 주요 자세 랜드마크를 사용하여 신체의 존재를 감지합니다.
- 포즈 랜드마커 모델: 포즈의 전체 매핑을 추가합니다. 모델은 33개의 3차원 자세 랜드마크의 추정치를 출력합니다.
이 번들은 MobileNetV2와 유사한 컨볼루션 신경망을 사용하며 기기 내 실시간 피트니스 애플리케이션에 최적화되어 있습니다. 이 BlazePose 모델의 변형은 3D 인간 신체 모델링 파이프라인인 GHUM을 사용하여 이미지 또는 동영상에서 개인의 전체 3D 신체 자세를 추정합니다.
| 모델 번들 | 입력 셰이프 | 데이터 유형 | 모델 카드 | 버전 |
|---|---|---|---|---|
| 포즈 랜드마커 (lite) | 포즈 감지기: 224x224x3 포즈 랜드마커: 256x256x3 |
부동 소수점 수 16 | 정보 | 최신 |
| 포즈 랜드마커 (전체) | 포즈 감지기: 224x224x3 포즈 랜드마커: 256x256x3 |
부동 소수점 수 16 | 정보 | 최신 |
| 포즈 랜드마커 (무거움) | 포즈 감지기: 224x224x3 포즈 랜드마커: 256x256x3 |
부동 소수점 수 16 | 정보 | 최신 |
포즈 랜드마커 모델
포즈 랜드마커 모델은 다음 신체 부위의 대략적인 위치를 나타내는 33개의 신체 랜드마크 위치를 추적합니다.
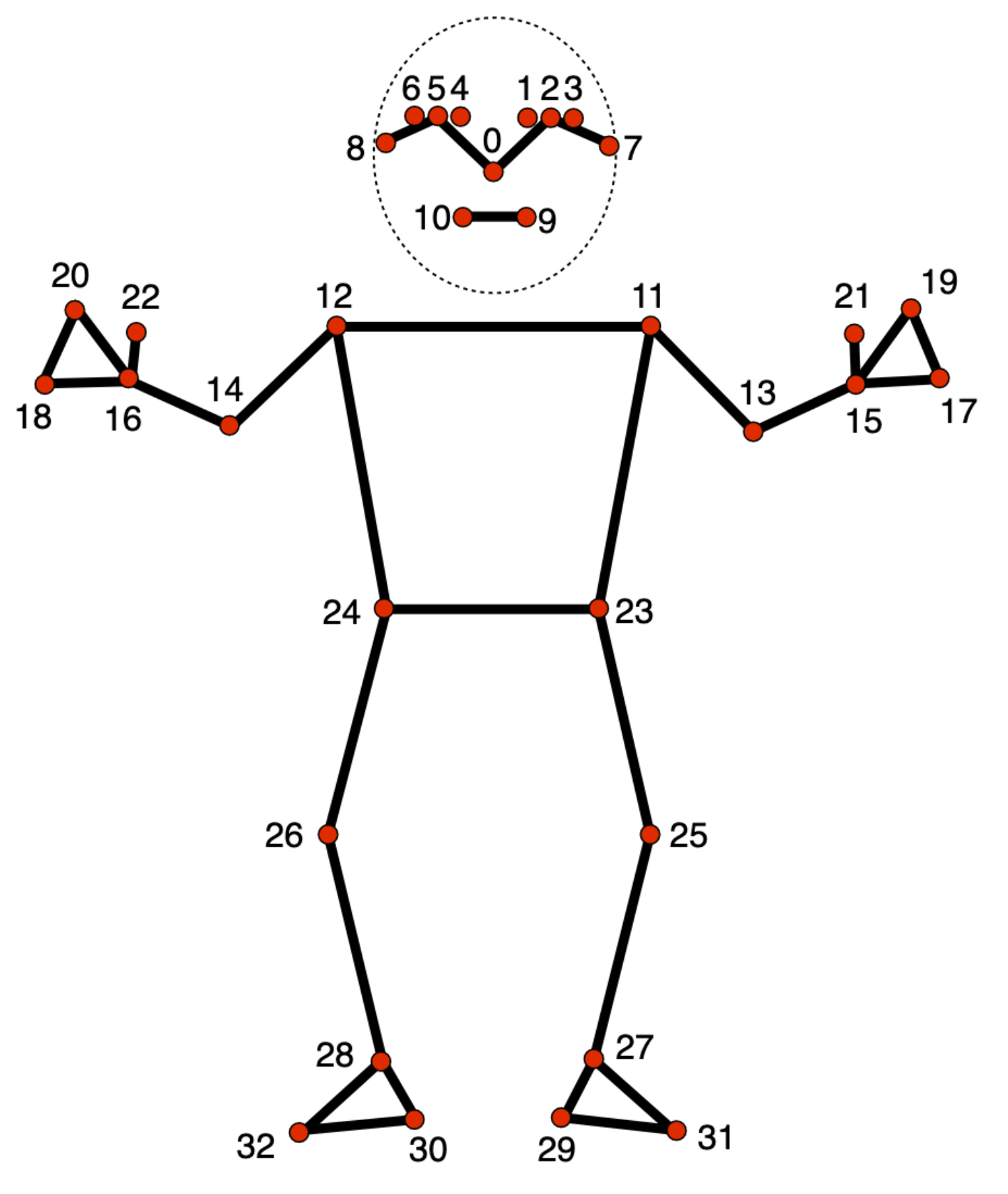
0 - nose
1 - left eye (inner)
2 - left eye
3 - left eye (outer)
4 - right eye (inner)
5 - right eye
6 - right eye (outer)
7 - left ear
8 - right ear
9 - mouth (left)
10 - mouth (right)
11 - left shoulder
12 - right shoulder
13 - left elbow
14 - right elbow
15 - left wrist
16 - right wrist
17 - left pinky
18 - right pinky
19 - left index
20 - right index
21 - left thumb
22 - right thumb
23 - left hip
24 - right hip
25 - left knee
26 - right knee
27 - left ankle
28 - right ankle
29 - left heel
30 - right heel
31 - left foot index
32 - right foot index
모델 출력에는 각 랜드마크의 정규화된 좌표 (Landmarks)와 실제 좌표 (WorldLandmarks)가 모두 포함됩니다.