The Gemini API provides safety settings that you can adjust during the prototyping stage to determine if your application requires a more or less restrictive safety configuration. You can adjust these settings across four filter categories to restrict or allow certain types of content.
This guide covers how the Gemini API handles safety settings and filtering and how you can change the safety settings for your application.
Safety filters
The Gemini API's adjustable safety filters cover the following categories:
| Category | Description |
|---|---|
| Harassment | Negative or harmful comments targeting identity and/or protected attributes. |
| Hate speech | Content that is rude, disrespectful, or profane. |
| Sexually explicit | Contains references to sexual acts or other lewd content. |
| Dangerous | Promotes, facilitates, or encourages harmful acts. |
These categories are defined in HarmCategory. You
can use these filters to adjust what's appropriate for your use case. For
example, if you're building video game dialogue, you may deem it acceptable to
allow more content that's rated as Dangerous due to the nature of the game.
In addition to the adjustable safety filters, the Gemini API has built-in protections against core harms, such as content that endangers child safety. These types of harm are always blocked and cannot be adjusted.
Content safety filtering level
The Gemini API categorizes the probability level of content being unsafe as
HIGH, MEDIUM, LOW, or NEGLIGIBLE.
The Gemini API blocks content based on the probability of content being unsafe and not the severity. This is important to consider because some content can have low probability of being unsafe even though the severity of harm could still be high. For example, comparing the sentences:
- The robot punched me.
- The robot slashed me up.
The first sentence might result in a higher probability of being unsafe, but you might consider the second sentence to be a higher severity in terms of violence. Given this, it is important that you carefully test and consider what the appropriate level of blocking is needed to support your key use cases while minimizing harm to end users.
Safety filtering per request
You can adjust the safety settings for each request you make to the API. When
you make a request, the content is analyzed and assigned a safety rating. The
safety rating includes the category and the probability of the harm
classification. For example, if the content was blocked due to the harassment
category having a high probability, the safety rating returned would have
category equal to HARASSMENT and harm probability set to HIGH.
Due to the model's inherent safety, additional filters are Off by default. If you choose to enable them, you can configure the system to block content based on its probability of being unsafe. The default model behavior covers most use cases, so you should only adjust these settings if consistently is required for your application.
The following table describes the block settings you can adjust for each category. For example, if you set the block setting to Block few for the Hate speech category, everything that has a high probability of being hate speech content is blocked. But anything with a lower probability is allowed.
| Threshold (Google AI Studio) | Threshold (API) | Description |
|---|---|---|
| Off | OFF |
Turn off the safety filter |
| Block none | BLOCK_NONE |
Always show regardless of probability of unsafe content |
| Block few | BLOCK_ONLY_HIGH |
Block when high probability of unsafe content |
| Block some | BLOCK_MEDIUM_AND_ABOVE |
Block when medium or high probability of unsafe content |
| Block most | BLOCK_LOW_AND_ABOVE |
Block when low, medium or high probability of unsafe content |
| N/A | HARM_BLOCK_THRESHOLD_UNSPECIFIED |
Threshold is unspecified, block using default threshold |
If the threshold is not set, the default block threshold is Off for Gemini 2.5 and 3 models.
You can set these settings for each request you make to the generative service.
See the HarmBlockThreshold API
reference for details.
Safety feedback
generateContent
returns a
GenerateContentResponse which
includes safety feedback.
Prompt feedback is included in
promptFeedback. If
promptFeedback.blockReason is set, then the content of the prompt was blocked.
Response candidate feedback is included in
Candidate.finishReason and
Candidate.safetyRatings. If response
content was blocked and the finishReason was SAFETY, you can inspect
safetyRatings for more details. The content that was blocked is not returned.
Adjust safety settings
This section covers how to adjust the safety settings in both Google AI Studio and in your code.
Google AI Studio
You can adjust safety settings in Google AI Studio.
Click Safety settings under Advanced settings in the Run settings panel to open the Run safety settings modal. In the modal, you can use the sliders to adjust the content filtering level per safety category:
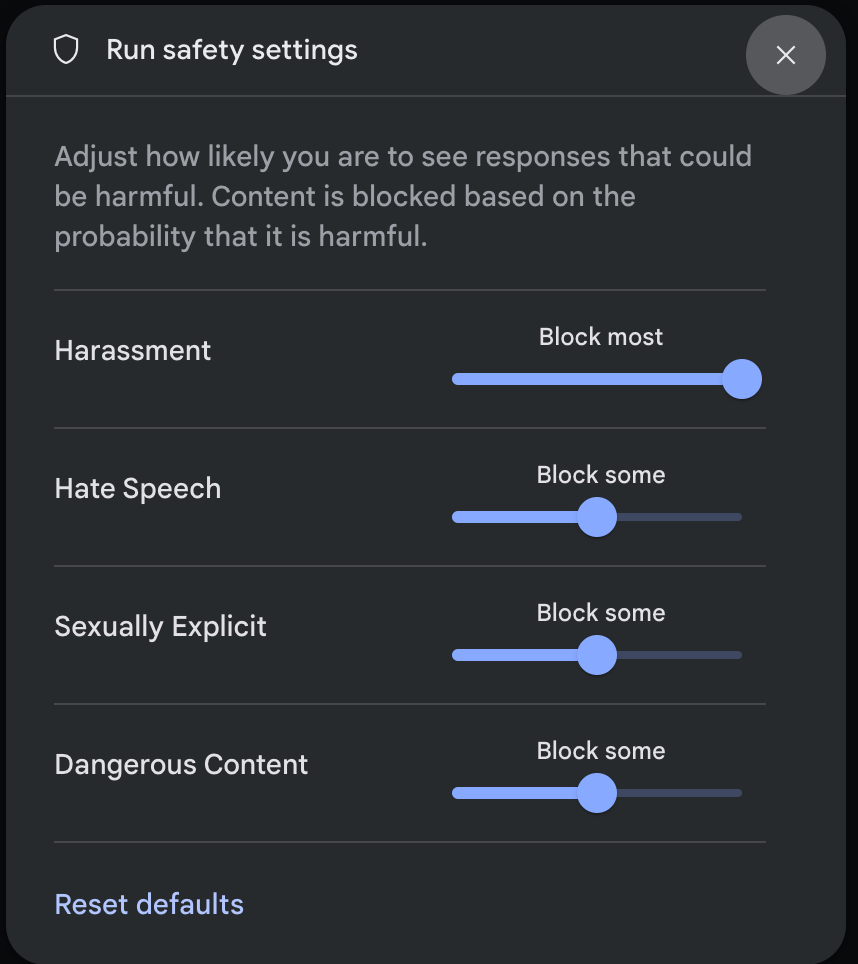
When you send a request (for example, by asking the model a question), a Content blocked message appears if the request's content is blocked. To see more details, hold the pointer over the Content blocked text to see the category and the probability of the harm classification.
Code examples
The following code snippet shows how to set safety settings in your
GenerateContent call. This sets the threshold for the hate speech
(HARM_CATEGORY_HATE_SPEECH) category. Setting this category to
BLOCK_LOW_AND_ABOVE blocks any content that has a low or higher probability of
being hate speech. To understand the threshold settings, see Safety filtering
per request.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
Go
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
Java
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
Next steps
- See the API reference to learn more about the full API.
- Review the safety guidance for a general look at safety considerations when developing with LLMs.
- Learn more about assessing probability versus severity from the Jigsaw team
- Learn more about the products that contribute to safety solutions like the Perspective API. * You can use these safety settings to create a toxicity classifier. See the classification example to get started.