
ইমেল সহ গ্রাহকদের জিজ্ঞাসাগুলি পরিচালনা করা অনেক ব্যবসা পরিচালনার একটি প্রয়োজনীয় অংশ, তবে এটি দ্রুত অপ্রতিরোধ্য হয়ে উঠতে পারে। একটু প্রচেষ্টার মাধ্যমে, জেমার মতো কৃত্রিম বুদ্ধিমত্তা (এআই) মডেলগুলি এই কাজটিকে আরও সহজ করতে সাহায্য করতে পারে।
প্রতিটি ব্যবসা ইমেলের মতো অনুসন্ধানগুলি একটু ভিন্নভাবে পরিচালনা করে, তাই আপনার ব্যবসার চাহিদার সাথে জেনারেটিভ এআই-এর মতো প্রযুক্তিগুলিকে খাপ খাইয়ে নিতে সক্ষম হওয়া গুরুত্বপূর্ণ। এই প্রকল্পটি বেকারির ইমেল থেকে স্ট্রাকচার্ড ডেটাতে অর্ডার তথ্য বের করার নির্দিষ্ট সমস্যাটি মোকাবেলা করে, যাতে এটি দ্রুত একটি অর্ডার হ্যান্ডলিং সিস্টেমে যুক্ত করা যায়। অনুসন্ধানের 10 থেকে 20 টি উদাহরণ এবং আপনার পছন্দসই আউটপুট ব্যবহার করে, আপনি আপনার গ্রাহকদের কাছ থেকে ইমেলগুলি প্রক্রিয়া করতে, দ্রুত প্রতিক্রিয়া জানাতে এবং আপনার বিদ্যমান ব্যবসায়িক সিস্টেমের সাথে একীভূত করতে একটি জেমা মডেল টিউন করতে পারেন। এই প্রকল্পটি একটি এআই অ্যাপ্লিকেশন প্যাটার্ন হিসাবে তৈরি করা হয়েছে যা আপনি আপনার ব্যবসার জন্য জেমা মডেলগুলি থেকে মূল্য পেতে প্রসারিত এবং অভিযোজিত করতে পারেন।
প্রকল্পটির ভিডিও ওভারভিউ এবং এটি কীভাবে সম্প্রসারিত করা যায়, যার মধ্যে এটি তৈরি করা ব্যক্তিদের কাছ থেকে অন্তর্দৃষ্টি অন্তর্ভুক্ত, গুগলের সাথে ব্যবসায়িক ইমেল এআই সহকারী বিল্ড ভিডিওটি দেখুন। আপনি জেমা কুকবুক কোড রিপোজিটরিতে এই প্রকল্পের কোডটি পর্যালোচনা করতে পারেন। অন্যথায়, আপনি নিম্নলিখিত নির্দেশাবলী ব্যবহার করে প্রকল্পটি সম্প্রসারিত করা শুরু করতে পারেন।
সংক্ষিপ্ত বিবরণ
এই টিউটোরিয়ালটি আপনাকে Gemma, Python এবং Flask দিয়ে তৈরি একটি ব্যবসায়িক ইমেল সহকারী অ্যাপ্লিকেশন সেট আপ, পরিচালনা এবং সম্প্রসারণের বিষয়ে নির্দেশনা দেবে। এই প্রকল্পটি একটি মৌলিক ওয়েব ব্যবহারকারী ইন্টারফেস প্রদান করে যা আপনি আপনার প্রয়োজন অনুসারে পরিবর্তন করতে পারেন। অ্যাপ্লিকেশনটি গ্রাহকের ইমেল থেকে ডেটা একটি কাল্পনিক বেকারির কাঠামোতে বের করার জন্য তৈরি করা হয়েছে। আপনি টেক্সট ইনপুট এবং টেক্সট আউটপুট ব্যবহার করে এমন যেকোনো ব্যবসায়িক কাজের জন্য এই অ্যাপ্লিকেশন প্যাটার্নটি ব্যবহার করতে পারেন।
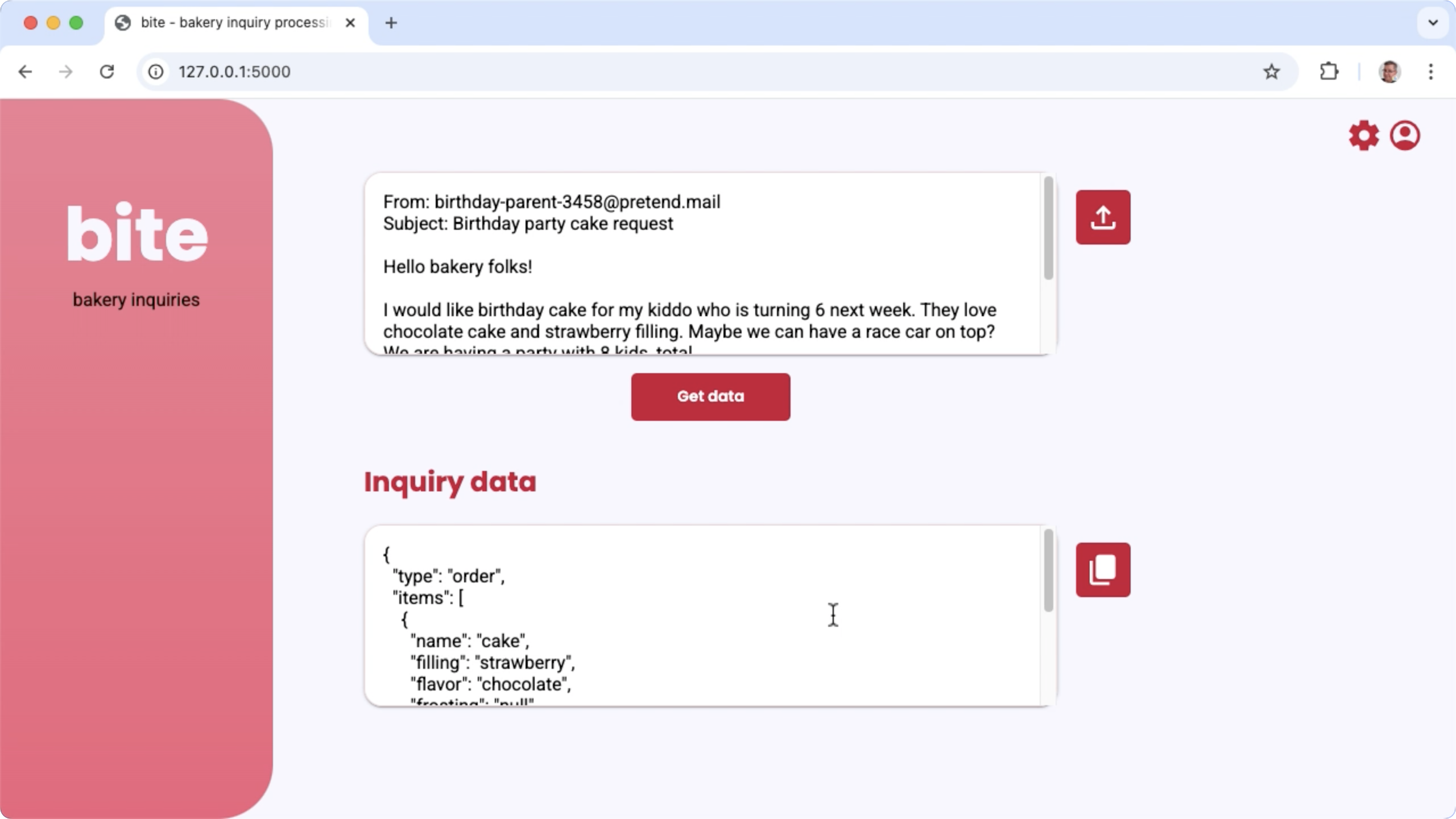
চিত্র ১. বেকারির ইমেল অনুসন্ধান প্রক্রিয়াকরণের জন্য প্রকল্প ব্যবহারকারী ইন্টারফেস
হার্ডওয়্যারের প্রয়োজনীয়তা
এই টিউনিং প্রক্রিয়াটি এমন একটি কম্পিউটারে চালান যেখানে গ্রাফিক্স প্রসেসিং ইউনিট (GPU) অথবা টেনসর প্রসেসিং ইউনিট (TPU) এবং বিদ্যমান মডেলটি ধরে রাখার জন্য পর্যাপ্ত GPU বা TPU মেমোরি এবং টিউনিং ডেটা থাকবে। এই প্রকল্পে টিউনিং কনফিগারেশনটি চালানোর জন্য, আপনার প্রায় 16GB GPU মেমোরি, প্রায় একই পরিমাণ নিয়মিত RAM এবং কমপক্ষে 50GB ডিস্ক স্পেস প্রয়োজন।
আপনি এই টিউটোরিয়ালের জেমা মডেল টিউনিং অংশটি T4 GPU রানটাইম সহ একটি Colab পরিবেশ ব্যবহার করে চালাতে পারেন। যদি আপনি এই প্রকল্পটি একটি Google Cloud VM ইনস্ট্যান্সে তৈরি করেন, তাহলে নিম্নলিখিত প্রয়োজনীয়তাগুলি অনুসরণ করে ইনস্ট্যান্সটি কনফিগার করুন:
- GPU হার্ডওয়্যার : এই প্রকল্পটি চালানোর জন্য একটি NVIDIA T4 প্রয়োজন (NVIDIA L4 বা উচ্চতর সুপারিশকৃত)
- অপারেটিং সিস্টেম : লিনাক্সে ডিপ লার্নিং বিকল্পটি বেছে নিন, বিশেষ করে CUDA 12.3 M124 সহ ডিপ লার্নিং VM যাতে আগে থেকে ইনস্টল করা GPU সফ্টওয়্যার ড্রাইভার থাকে।
- বুট ডিস্কের আকার : আপনার ডেটা, মডেল এবং সহায়ক সফ্টওয়্যারের জন্য কমপক্ষে ৫০ গিগাবাইট ডিস্ক স্পেসের ব্যবস্থা করুন।
প্রকল্প সেটআপ
এই নির্দেশাবলী আপনাকে এই প্রকল্পটি ডেভেলপমেন্ট এবং পরীক্ষার জন্য প্রস্তুত করার ক্ষেত্রে সাহায্য করবে। সাধারণ সেটআপ ধাপগুলির মধ্যে রয়েছে পূর্বশর্ত সফ্টওয়্যার ইনস্টল করা, কোড রিপোজিটরি থেকে প্রকল্পটি ক্লোন করা, কয়েকটি পরিবেশ ভেরিয়েবল সেট করা, পাইথন লাইব্রেরি ইনস্টল করা এবং ওয়েব অ্যাপ্লিকেশন পরীক্ষা করা।
ইনস্টল এবং কনফিগার করুন
এই প্রকল্পটি প্যাকেজ পরিচালনা এবং অ্যাপ্লিকেশন চালানোর জন্য Python 3 এবং ভার্চুয়াল এনভায়রনমেন্ট ( venv ) ব্যবহার করে। নিম্নলিখিত ইনস্টলেশন নির্দেশাবলী একটি লিনাক্স হোস্ট মেশিনের জন্য।
প্রয়োজনীয় সফটওয়্যার ইনস্টল করতে:
পাইথনের জন্য পাইথন 3 এবং
venvভার্চুয়াল পরিবেশ প্যাকেজ ইনস্টল করুন:sudo apt update sudo apt install git pip python3-venv
প্রকল্পটি ক্লোন করুন
আপনার ডেভেলপমেন্ট কম্পিউটারে প্রজেক্ট কোডটি ডাউনলোড করুন। প্রজেক্ট সোর্স কোডটি পুনরুদ্ধার করতে আপনার গিট সোর্স কন্ট্রোল সফটওয়্যারের প্রয়োজন।
প্রকল্প কোড ডাউনলোড করতে:
নিম্নলিখিত কমান্ড ব্যবহার করে গিট রিপোজিটরি ক্লোন করুন:
git clone https://github.com/google-gemini/gemma-cookbook.gitঐচ্ছিকভাবে, স্পার্স চেকআউট ব্যবহার করার জন্য আপনার স্থানীয় গিট রিপোজিটরিটি কনফিগার করুন, যাতে আপনার কাছে প্রকল্পের জন্য শুধুমাত্র ফাইল থাকে:
cd gemma-cookbook/ git sparse-checkout set Demos/business-email-assistant/ git sparse-checkout init --cone
পাইথন লাইব্রেরি ইনস্টল করুন
পাইথন প্যাকেজ এবং নির্ভরতা পরিচালনা করার জন্য venv Python ভার্চুয়াল পরিবেশ সক্রিয় করে Python লাইব্রেরিগুলি ইনস্টল করুন। pip ইনস্টলার দিয়ে Python লাইব্রেরি ইনস্টল করার আগে Python ভার্চুয়াল পরিবেশ সক্রিয় করুন। Python ভার্চুয়াল পরিবেশ ব্যবহার সম্পর্কে আরও তথ্যের জন্য, Python venv ডকুমেন্টেশন দেখুন।
পাইথন লাইব্রেরি ইনস্টল করতে:
একটি টার্মিনাল উইন্ডোতে,
business-email-assistantডিরেক্টরিতে নেভিগেট করুন:cd Demos/business-email-assistant/এই প্রকল্পের জন্য পাইথন ভার্চুয়াল পরিবেশ (venv) কনফিগার এবং সক্রিয় করুন:
python3 -m venv venv source venv/bin/activatesetup_pythonস্ক্রিপ্ট ব্যবহার করে এই প্রকল্পের জন্য প্রয়োজনীয় পাইথন লাইব্রেরিগুলি ইনস্টল করুন:./setup_python.sh
পরিবেশের ভেরিয়েবল সেট করুন
এই প্রকল্পটি চালানোর জন্য কয়েকটি পরিবেশগত ভেরিয়েবলের প্রয়োজন, যার মধ্যে একটি Kaggle ব্যবহারকারীর নাম এবং একটি Kaggle API টোকেন অন্তর্ভুক্ত। আপনার একটি Kaggle অ্যাকাউন্ট থাকতে হবে এবং Gemma মডেলগুলি ডাউনলোড করতে সক্ষম হওয়ার জন্য অ্যাক্সেসের অনুরোধ করতে হবে। এই প্রকল্পের জন্য, আপনি আপনার Kaggle ব্যবহারকারীর নাম এবং Kaggle API টোকেন দুটি .env ফাইলে যুক্ত করুন, যা যথাক্রমে ওয়েব অ্যাপ্লিকেশন এবং টিউনিং প্রোগ্রাম দ্বারা পড়া হয়।
পরিবেশ ভেরিয়েবল সেট করতে:
- Kaggle ডকুমেন্টেশনের নির্দেশাবলী অনুসরণ করে আপনার Kaggle ব্যবহারকারীর নাম এবং টোকেন কী পান।
- জেমা সেটআপ পৃষ্ঠায় জেমাতে অ্যাক্সেস পান নির্দেশাবলী অনুসরণ করে জেমা মডেলে অ্যাক্সেস পান।
- আপনার প্রকল্পের ক্লোনের প্রতিটি স্থানে একটি
.envটেক্সট ফাইল তৈরি করে প্রকল্পের জন্য পরিবেশ পরিবর্তনশীল ফাইল তৈরি করুন:email-processing-webapp/.env model-tuning/.env
.envটেক্সট ফাইল তৈরি করার পরে, উভয় ফাইলেই নিম্নলিখিত সেটিংস যোগ করুন:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
অ্যাপ্লিকেশনটি চালান এবং পরীক্ষা করুন
একবার আপনি প্রকল্পের ইনস্টলেশন এবং কনফিগারেশন সম্পন্ন করলে, আপনি এটি সঠিকভাবে কনফিগার করেছেন কিনা তা নিশ্চিত করার জন্য ওয়েব অ্যাপ্লিকেশনটি চালান। আপনার নিজের ব্যবহারের জন্য প্রকল্পটি সম্পাদনা করার আগে আপনার এটি একটি বেসলাইন চেক হিসাবে করা উচিত।
প্রকল্পটি চালানো এবং পরীক্ষা করার জন্য:
একটি টার্মিনাল উইন্ডোতে,
email-processing-webappডিরেক্টরিতে নেভিগেট করুন:cd business-email-assistant/email-processing-webapp/run_appস্ক্রিপ্ট ব্যবহার করে অ্যাপ্লিকেশনটি চালান:./run_app.shওয়েব অ্যাপ্লিকেশন শুরু করার পর, প্রোগ্রাম কোডে একটি URL তালিকাভুক্ত করা হয় যেখানে আপনি ব্রাউজ এবং পরীক্ষা করতে পারেন। সাধারণত, এই ঠিকানাটি হল:
http://127.0.0.1:5000/ওয়েব ইন্টারফেসে, মডেল থেকে একটি প্রতিক্রিয়া তৈরি করতে প্রথম ইনপুট ক্ষেত্রের নীচে ডেটা পান বোতাম টিপুন।
অ্যাপ্লিকেশনটি চালানোর পরে মডেল থেকে প্রথম প্রতিক্রিয়া পেতে বেশি সময় লাগে কারণ প্রথম প্রজন্মের রানে এটিকে প্রাথমিককরণের ধাপগুলি সম্পূর্ণ করতে হয়। পরবর্তী প্রম্পট অনুরোধ এবং ইতিমধ্যেই চলমান ওয়েব অ্যাপ্লিকেশনে জেনারেশন কম সময়ে সম্পন্ন হয়।
আবেদনের সময়সীমা বাড়ান
একবার আপনার অ্যাপ্লিকেশনটি চালু হয়ে গেলে, আপনি ব্যবহারকারীর ইন্টারফেস এবং ব্যবসায়িক যুক্তি পরিবর্তন করে এটিকে প্রসারিত করতে পারেন যাতে এটি আপনার বা আপনার ব্যবসার জন্য প্রাসঙ্গিক কাজের জন্য কার্যকর হয়। আপনি জেনারেটিভ এআই মডেলে অ্যাপটি যে প্রম্পট পাঠায় তার উপাদানগুলি পরিবর্তন করে অ্যাপ্লিকেশন কোড ব্যবহার করে জেমা মডেলের আচরণ পরিবর্তন করতে পারেন।
অ্যাপ্লিকেশনটি মডেলটিকে নির্দেশাবলী প্রদান করে, ব্যবহারকারীর ইনপুট ডেটার সাথে মডেলের সম্পূর্ণ প্রম্পট প্রদান করে। আপনি মডেলের আচরণ পরিবর্তন করতে এই নির্দেশাবলী পরিবর্তন করতে পারেন, যেমন জেনারেট করার জন্য প্যারামিটারের নাম এবং কাঠামো নির্দিষ্ট করা। মডেলের আচরণ পরিবর্তন করার একটি সহজ উপায় হল মডেলের প্রতিক্রিয়ার জন্য অতিরিক্ত নির্দেশাবলী বা নির্দেশিকা প্রদান করা, যেমন জেনারেট করা উত্তরগুলিতে কোনও মার্কডাউন ফর্ম্যাটিং অন্তর্ভুক্ত করা উচিত নয় তা নির্দিষ্ট করা।
প্রম্পট নির্দেশাবলী পরিবর্তন করতে:
- ডেভেলপমেন্ট প্রজেক্টে,
business-email-assistant/email-processing-webapp/app.pyকোড ফাইলটি খুলুন। app.pyকোডে,get_prompt():ফাংশনে সংযোজনের নির্দেশাবলী যোগ করুন:def get_prompt(): return """ Extract the relevant details of this request and return them in JSON code, with no additional markdown formatting:\n"""
এই উদাহরণে নির্দেশাবলীতে "কোনও অতিরিক্ত মার্কডাউন ফর্ম্যাটিং ছাড়াই" বাক্যাংশটি যোগ করা হয়েছে।
অতিরিক্ত প্রম্পট নির্দেশনা প্রদান করলে উৎপন্ন আউটপুট ব্যাপকভাবে প্রভাবিত হতে পারে এবং বাস্তবায়নে উল্লেখযোগ্যভাবে কম প্রচেষ্টা লাগে। মডেল থেকে আপনার পছন্দসই আচরণ পেতে পারেন কিনা তা দেখার জন্য প্রথমে এই পদ্ধতিটি চেষ্টা করা উচিত। তবে, জেমা মডেলের আচরণ পরিবর্তন করার জন্য প্রম্পট নির্দেশাবলী ব্যবহারের নিজস্ব সীমা রয়েছে। বিশেষ করে, মডেলের সামগ্রিক ইনপুট টোকেন সীমা, যা জেমা 2 এর জন্য 8,192 টোকেন, আপনাকে আপনার প্রদত্ত নতুন ডেটার আকারের সাথে বিস্তারিত প্রম্পট নির্দেশাবলীর ভারসাম্য বজায় রাখতে হবে যাতে আপনি সেই সীমার মধ্যে থাকতে পারেন।
মডেলটি টিউন করুন
নির্দিষ্ট কাজের জন্য আরও নির্ভরযোগ্যভাবে সাড়া দেওয়ার জন্য জেমা মডেলের ফাইন-টিউনিং করা হল প্রস্তাবিত উপায়। বিশেষ করে, যদি আপনি চান যে মডেলটি নির্দিষ্ট কাঠামোর সাথে JSON তৈরি করুক, যার মধ্যে নির্দিষ্টভাবে নামযুক্ত প্যারামিটারও অন্তর্ভুক্ত, তাহলে আপনার সেই আচরণের জন্য মডেলটি টিউন করার কথা বিবেচনা করা উচিত। আপনি যে কাজটি মডেলটি সম্পন্ন করতে চান তার উপর নির্ভর করে, আপনি 10 থেকে 20টি উদাহরণ দিয়ে মৌলিক কার্যকারিতা অর্জন করতে পারেন। টিউটোরিয়ালের এই অংশে ব্যাখ্যা করা হয়েছে যে কীভাবে একটি নির্দিষ্ট কাজের জন্য জেমা মডেলে ফাইন-টিউনিং সেট আপ এবং চালানো যায়।
নিম্নলিখিত নির্দেশাবলীতে VM পরিবেশে ফাইন-টিউনিং অপারেশন কীভাবে করতে হয় তা ব্যাখ্যা করা হয়েছে, তবে, আপনি এই প্রকল্পের জন্য সংশ্লিষ্ট Colab notebook ব্যবহার করেও এই টিউনিং অপারেশনটি সম্পাদন করতে পারেন।
হার্ডওয়্যারের প্রয়োজনীয়তা
ফাইন-টিউনিংয়ের জন্য কম্পিউটের প্রয়োজনীয়তাগুলি প্রকল্পের বাকি অংশের হার্ডওয়্যারের প্রয়োজনীয়তার মতোই। আপনি যদি ইনপুট টোকেনগুলি 256 এবং ব্যাচের আকার 1-এ সীমাবদ্ধ রাখেন তবে আপনি T4 GPU রানটাইম সহ একটি Colab পরিবেশে টিউনিং অপারেশন চালাতে পারেন।
তথ্য প্রস্তুত করুন
জেমা মডেল টিউন করা শুরু করার আগে, আপনাকে টিউনিংয়ের জন্য ডেটা প্রস্তুত করতে হবে। যখন আপনি একটি নির্দিষ্ট কাজের জন্য একটি মডেল টিউন করছেন, তখন আপনার অনুরোধ এবং প্রতিক্রিয়ার উদাহরণের একটি সেট প্রয়োজন। এই উদাহরণগুলিতে কোনও নির্দেশ ছাড়াই অনুরোধের পাঠ্য এবং প্রত্যাশিত প্রতিক্রিয়ার পাঠ্য দেখানো উচিত। শুরু করার জন্য, আপনার প্রায় 10 টি উদাহরণ সহ একটি ডেটাসেট প্রস্তুত করা উচিত। এই উদাহরণগুলিতে বিভিন্ন ধরণের অনুরোধ এবং আদর্শ প্রতিক্রিয়া উপস্থাপন করা উচিত। নিশ্চিত করুন যে অনুরোধ এবং প্রতিক্রিয়াগুলি পুনরাবৃত্তিমূলক নয়, কারণ এর ফলে মডেলের প্রতিক্রিয়াগুলি পুনরাবৃত্তিমূলক হতে পারে এবং অনুরোধের পরিবর্তনের সাথে যথাযথভাবে সামঞ্জস্য করতে পারে না। যদি আপনি একটি কাঠামোগত ডেটা ফর্ম্যাট তৈরি করার জন্য মডেলটি টিউন করেন, তবে নিশ্চিত করুন যে প্রদত্ত সমস্ত প্রতিক্রিয়া আপনার পছন্দসই ডেটা আউটপুট ফর্ম্যাটের সাথে কঠোরভাবে সঙ্গতিপূর্ণ। নিম্নলিখিত টেবিলটি এই কোড উদাহরণের ডেটাসেট থেকে কয়েকটি নমুনা রেকর্ড দেখায়:
| অনুরোধ | প্রতিক্রিয়া |
|---|---|
| হাই ইন্ডিয়ান বেকারি সেন্ট্রাল,\nতোমার কাছে কি ১০টি পেন্ডা আর ত্রিশটি বুন্দি লাড্ডু আছে? আর তুমি কি ভ্যানিলা ফ্রস্টিং আর চকোলেট ফ্লেভারের কেক বিক্রি করো? আমি ৬ ইঞ্চি সাইজের একটা খুঁজছি। | { "প্রকার": "তদন্ত", "আইটেম": [ { "নাম": "পেন্ডা", "পরিমাণ": ১০ }, { "নাম": "বুন্দি লাড্ডু", "পরিমাণ": ৩০ }, { "নাম": "কেক", "ফিলিং": শূন্য, "ফ্রস্টিং": "ভ্যানিলা", "স্বাদ": "চকলেট", "আকার": "৬ ইঞ্চি" } ] } |
| গুগল ম্যাপে তোমার ব্যবসা দেখেছি। তুমি কি জেল্লাবি আর গুলাব জামুন বিক্রি করো? | { "প্রকার": "তদন্ত", "আইটেম": [ { "নাম": "জেলাবি", "পরিমাণ": শূন্য }, { "নাম": "গুলাব জামুন", "পরিমাণ": শূন্য } ] } |
সারণী ১. বেকারি ইমেল ডেটা এক্সট্র্যাক্টরের জন্য টিউনিং ডেটাসেটের আংশিক তালিকা।
ডেটা ফর্ম্যাট এবং লোডিং
আপনি আপনার টিউনিং ডেটা যেকোনো সুবিধাজনক ফর্ম্যাটে সংরক্ষণ করতে পারেন, যেমন ডাটাবেস রেকর্ড, JSON ফাইল, CSV, অথবা প্লেইন টেক্সট ফাইল, যদি আপনার কাছে পাইথন কোড ব্যবহার করে রেকর্ডগুলি পুনরুদ্ধার করার ক্ষমতা থাকে। এই প্রকল্পটি একটি data ডিরেক্টরি থেকে JSON ফাইলগুলিকে অভিধানের বস্তুর একটি অ্যারেতে পাঠ করে। এই উদাহরণ টিউনিং প্রোগ্রামে, টিউনিং ডেটাসেটটি prepare_tuning_dataset() ফাংশন ব্যবহার করে model-tuning/main.py মডিউলে লোড করা হয়:
def prepare_tuning_dataset():
# collect data from JSON files
prompt_data = read_json_files_to_dicts("./data")
...
যেমনটি আগে উল্লেখ করা হয়েছে, আপনি ডেটাসেটটি সুবিধাজনক ফর্ম্যাটে সংরক্ষণ করতে পারেন, যতক্ষণ না আপনি সংশ্লিষ্ট প্রতিক্রিয়াগুলির সাথে অনুরোধগুলি পুনরুদ্ধার করতে পারেন এবং সেগুলিকে একটি টেক্সট স্ট্রিংয়ে একত্রিত করতে পারেন যা একটি টিউনিং রেকর্ড হিসাবে ব্যবহৃত হয়।
টিউনিং রেকর্ড সংগ্রহ করুন
প্রকৃত টিউনিং প্রক্রিয়ার জন্য, প্রোগ্রামটি প্রতিটি অনুরোধ এবং প্রতিক্রিয়াকে প্রম্পট নির্দেশাবলী এবং প্রতিক্রিয়ার বিষয়বস্তু সহ একটি একক স্ট্রিংয়ে একত্রিত করে। টিউনিং প্রোগ্রামটি তারপর মডেল দ্বারা ব্যবহারের জন্য স্ট্রিংটিকে টোকেনাইজ করে। আপনি model-tuning/main.py মডিউল prepare_tuning_dataset() ফাংশনে একটি টিউনিং রেকর্ড একত্রিত করার কোডটি দেখতে পারেন, নিম্নরূপ:
def prepare_tuning_dataset():
...
# prepare data for tuning
tuning_dataset = []
template = "{instruction}\n{response}"
for prompt in prompt_data:
tuning_dataset.append(template.format(instruction=prompt["prompt"],
response=prompt["response"]))
return tuning_dataset
এই ফাংশনটি ডেটাকে তার ইনপুট হিসেবে গ্রহণ করে এবং নির্দেশ এবং প্রতিক্রিয়ার মধ্যে একটি লাইন বিরতি যোগ করে এটিকে ফর্ম্যাট করে।
মডেল ওজন তৈরি করুন
একবার টিউনিং ডেটা ঠিকঠাক করে লোড হয়ে গেলে, আপনি টিউনিং প্রোগ্রামটি চালাতে পারেন। এই উদাহরণ অ্যাপ্লিকেশনের টিউনিং প্রক্রিয়াটি Keras NLP লাইব্রেরি ব্যবহার করে লো র্যাঙ্ক অ্যাডাপ্টেশন বা LoRA কৌশল ব্যবহার করে নতুন মডেলের ওজন তৈরি করে। সম্পূর্ণ নির্ভুল টিউনিংয়ের তুলনায়, LoRA ব্যবহার উল্লেখযোগ্যভাবে বেশি মেমোরি-দক্ষ কারণ এটি মডেলের ওজনের পরিবর্তনগুলিকে আনুমানিক করে। এরপর আপনি মডেলের আচরণ পরিবর্তন করতে এই আনুমানিক ওজনগুলিকে বিদ্যমান মডেলের ওজনের উপর ওভারলে করতে পারেন।
টিউনিং রান সম্পাদন করতে এবং নতুন ওজন গণনা করতে:
একটি টার্মিনাল উইন্ডোতে,
model-tuning/ডিরেক্টরিতে নেভিগেট করুন।cd business-email-assistant/model-tuning/tune_modelস্ক্রিপ্ট ব্যবহার করে টিউনিং প্রক্রিয়াটি চালান:./tune_model.sh
আপনার উপলব্ধ কম্পিউট রিসোর্সের উপর নির্ভর করে টিউনিং প্রক্রিয়াটি কয়েক মিনিট সময় নেয়। এটি সফলভাবে সম্পন্ন হলে, টিউনিং প্রোগ্রামটি নিম্নলিখিত ফর্ম্যাট সহ model-tuning/weights ডিরেক্টরিতে নতুন *.h5 ওজন ফাইল লিখে:
gemma2-2b_inquiry_tuned_4_epoch##.lora.h5
সমস্যা সমাধান
যদি টিউনিং সফলভাবে সম্পন্ন না হয়, তাহলে দুটি সম্ভাব্য কারণ থাকতে পারে:
- মেমোরি শেষ হয়ে গেছে অথবা রিসোর্স শেষ হয়ে গেছে : টিউনিং প্রক্রিয়া যখন উপলব্ধ GPU মেমোরি বা CPU মেমোরির চেয়ে বেশি মেমোরির অনুরোধ করে তখন এই ত্রুটিগুলি ঘটে। টিউনিং প্রক্রিয়া চলাকালীন আপনি ওয়েব অ্যাপ্লিকেশনটি চালাচ্ছেন না তা নিশ্চিত করুন। আপনি যদি 16GB GPU মেমোরি সহ একটি ডিভাইসে টিউনিং করেন, তাহলে নিশ্চিত করুন যে আপনার
token_limit256 এ সেট করা আছে এবংbatch_size1 এ সেট করা আছে। - GPU ড্রাইভার ইনস্টল করা নেই অথবা JAX এর সাথে সামঞ্জস্যপূর্ণ নয় : টিউনিং প্রক্রিয়ার জন্য কম্পিউট ডিভাইসে JAX লাইব্রেরির সংস্করণের সাথে সামঞ্জস্যপূর্ণ হার্ডওয়্যার ড্রাইভার ইনস্টল করা প্রয়োজন। আরও বিস্তারিত জানার জন্য, JAX ইনস্টলেশন ডকুমেন্টেশন দেখুন।
টিউন করা মডেল স্থাপন করুন
টিউনিং অ্যাপ্লিকেশনে টিউনিং ডেটা এবং সেট করা মোট যুগের সংখ্যার উপর ভিত্তি করে টিউনিং প্রক্রিয়া একাধিক ওজন তৈরি করে। ডিফল্টরূপে, টিউনিং প্রোগ্রামটি 3টি মডেল ওজন ফাইল তৈরি করে, প্রতিটি টিউনিং যুগের জন্য একটি। প্রতিটি ধারাবাহিক টিউনিং যুগ এমন ওজন তৈরি করে যা টিউনিং ডেটার ফলাফল আরও সঠিকভাবে পুনরুত্পাদন করে। টিউনিং প্রক্রিয়ার টার্মিনাল আউটপুটে আপনি প্রতিটি যুগের জন্য নির্ভুলতার হার দেখতে পাবেন, নিম্নরূপ:
...
8/8 ━━━━━━━━━━━━━━━━━━━━ 121s 195ms/step - loss: 0.5432 - sparse_categorical_accuracy: 0.5982
Epoch 2/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 194ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.6966
Epoch 3/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 192ms/step - loss: 0.2135 - sparse_categorical_accuracy: 0.7848
আপনি যদি চান যে নির্ভুলতার হার তুলনামূলকভাবে বেশি হোক, প্রায় ০.৮০, তবে আপনি চান না যে হারটি খুব বেশি হোক, অথবা ১.০০ এর খুব কাছাকাছি হোক, কারণ এর অর্থ হল ওজনগুলি টিউনিং ডেটার সাথে অতিরিক্ত মানানসই হয়ে গেছে। যখন এটি ঘটে, তখন মডেলটি টিউনিং উদাহরণ থেকে উল্লেখযোগ্যভাবে আলাদা অনুরোধগুলিতে ভালভাবে কাজ করে না। ডিফল্টরূপে, ডিপ্লয়মেন্ট স্ক্রিপ্টটি epoch 3 ওজন বেছে নেয়, যার সাধারণত নির্ভুলতার হার ০.৮০ এর কাছাকাছি থাকে।
জেনারেট করা ওজন ওয়েব অ্যাপ্লিকেশনে স্থাপন করতে:
একটি টার্মিনাল উইন্ডোতে,
model-tuningডিরেক্টরিতে নেভিগেট করুন:cd business-email-assistant/model-tuning/deploy_weightsস্ক্রিপ্ট ব্যবহার করে টিউনিং প্রক্রিয়াটি চালান:./deploy_weights.sh
এই স্ক্রিপ্টটি চালানোর পরে, আপনি email-processing-webapp/weights/ ডিরেক্টরিতে একটি নতুন *.h5 ফাইল দেখতে পাবেন।
নতুন মডেলটি পরীক্ষা করুন
একবার আপনি অ্যাপ্লিকেশনটিতে নতুন ওজন স্থাপন করার পরে, নতুন টিউন করা মডেলটি চেষ্টা করার সময় এসেছে। আপনি ওয়েব অ্যাপ্লিকেশনটি পুনরায় চালু করে এবং একটি প্রতিক্রিয়া তৈরি করে এটি করতে পারেন।
প্রকল্পটি চালানো এবং পরীক্ষা করার জন্য:
একটি টার্মিনাল উইন্ডোতে,
email-processing-webappডিরেক্টরিতে নেভিগেট করুন:cd business-email-assistant/email-processing-webapp/run_appস্ক্রিপ্ট ব্যবহার করে অ্যাপ্লিকেশনটি চালান:./run_app.shওয়েব অ্যাপ্লিকেশন শুরু করার পর, প্রোগ্রাম কোডে একটি URL তালিকাভুক্ত করা হয় যেখানে আপনি ব্রাউজ এবং পরীক্ষা করতে পারেন, সাধারণত এই ঠিকানাটি হল:
http://127.0.0.1:5000/ওয়েব ইন্টারফেসে, মডেল থেকে একটি প্রতিক্রিয়া তৈরি করতে প্রথম ইনপুট ক্ষেত্রের নীচে ডেটা পান বোতাম টিপুন।
আপনি এখন একটি অ্যাপ্লিকেশনে একটি জেমা মডেল টিউন এবং স্থাপন করেছেন! অ্যাপ্লিকেশনটি নিয়ে পরীক্ষা করুন এবং আপনার কাজের জন্য টিউন করা মডেলের জেনারেশন ক্ষমতার সীমা নির্ধারণ করার চেষ্টা করুন। যদি আপনি এমন পরিস্থিতি খুঁজে পান যেখানে মডেলটি ভালভাবে কাজ করে না, তাহলে অনুরোধটি যোগ করে এবং একটি আদর্শ প্রতিক্রিয়া প্রদান করে আপনার টিউনিং উদাহরণ ডেটার তালিকায় সেই অনুরোধগুলির কিছু যোগ করার কথা বিবেচনা করুন। তারপর টিউনিং প্রক্রিয়াটি পুনরায় চালান, নতুন ওজন পুনরায় স্থাপন করুন এবং আউটপুট পরীক্ষা করুন।
অতিরিক্ত সম্পদ
এই প্রকল্প সম্পর্কে আরও তথ্যের জন্য, জেমা কুকবুক কোড রিপোজিটরি দেখুন। যদি আপনার অ্যাপ্লিকেশন তৈরিতে সাহায্যের প্রয়োজন হয় অথবা অন্যান্য ডেভেলপারদের সাথে সহযোগিতা করতে চান, তাহলে গুগল ডেভেলপারস কমিউনিটি ডিসকর্ড সার্ভারটি দেখুন। গুগল এআই প্রকল্পের সাথে আরও বিল্ডের জন্য, ভিডিও প্লেলিস্টটি দেখুন।