
Menangani pertanyaan pelanggan, termasuk email, adalah bagian penting dalam menjalankan banyak bisnis, tetapi hal ini dapat dengan cepat menjadi sangat merepotkan. Dengan sedikit upaya, model kecerdasan buatan (AI) seperti Gemma dapat membantu mempermudah pekerjaan ini.
Setiap bisnis menangani pertanyaan seperti email dengan cara yang sedikit berbeda, jadi penting untuk dapat menyesuaikan teknologi seperti AI generatif dengan kebutuhan bisnis Anda. Project ini mengatasi masalah khusus terkait ekstraksi informasi pesanan dari email ke toko roti menjadi data terstruktur, sehingga dapat ditambahkan dengan cepat ke sistem penanganan pesanan. Dengan menggunakan 10 hingga 20 contoh pertanyaan dan output yang Anda inginkan, Anda dapat menyesuaikan model Gemma untuk memproses email dari pelanggan, membantu Anda merespons dengan cepat, dan berintegrasi dengan sistem bisnis yang ada. Project ini dibuat sebagai pola aplikasi AI yang dapat Anda perluas dan sesuaikan untuk mendapatkan nilai dari model Gemma bagi bisnis Anda.
Untuk melihat ringkasan video tentang project ini dan cara memperluasnya, termasuk insight dari orang-orang yang membuatnya, tonton video Asisten AI Email Bisnis Build with Google AI. Anda juga dapat meninjau kode untuk project ini di repositori kode Gemma Cookbook. Jika tidak, Anda dapat mulai memperluas project menggunakan petunjuk berikut.
Ringkasan
Tutorial ini akan memandu Anda menyiapkan, menjalankan, dan memperluas aplikasi asisten email bisnis yang dibuat dengan Gemma, Python, dan Flask. Project ini menyediakan antarmuka pengguna web dasar yang dapat Anda ubah agar sesuai dengan kebutuhan Anda. Aplikasi ini dibuat untuk mengekstrak data dari email pelanggan ke dalam struktur untuk toko roti fiktif. Anda dapat menggunakan pola aplikasi ini untuk tugas bisnis apa pun yang menggunakan input teks dan output teks.
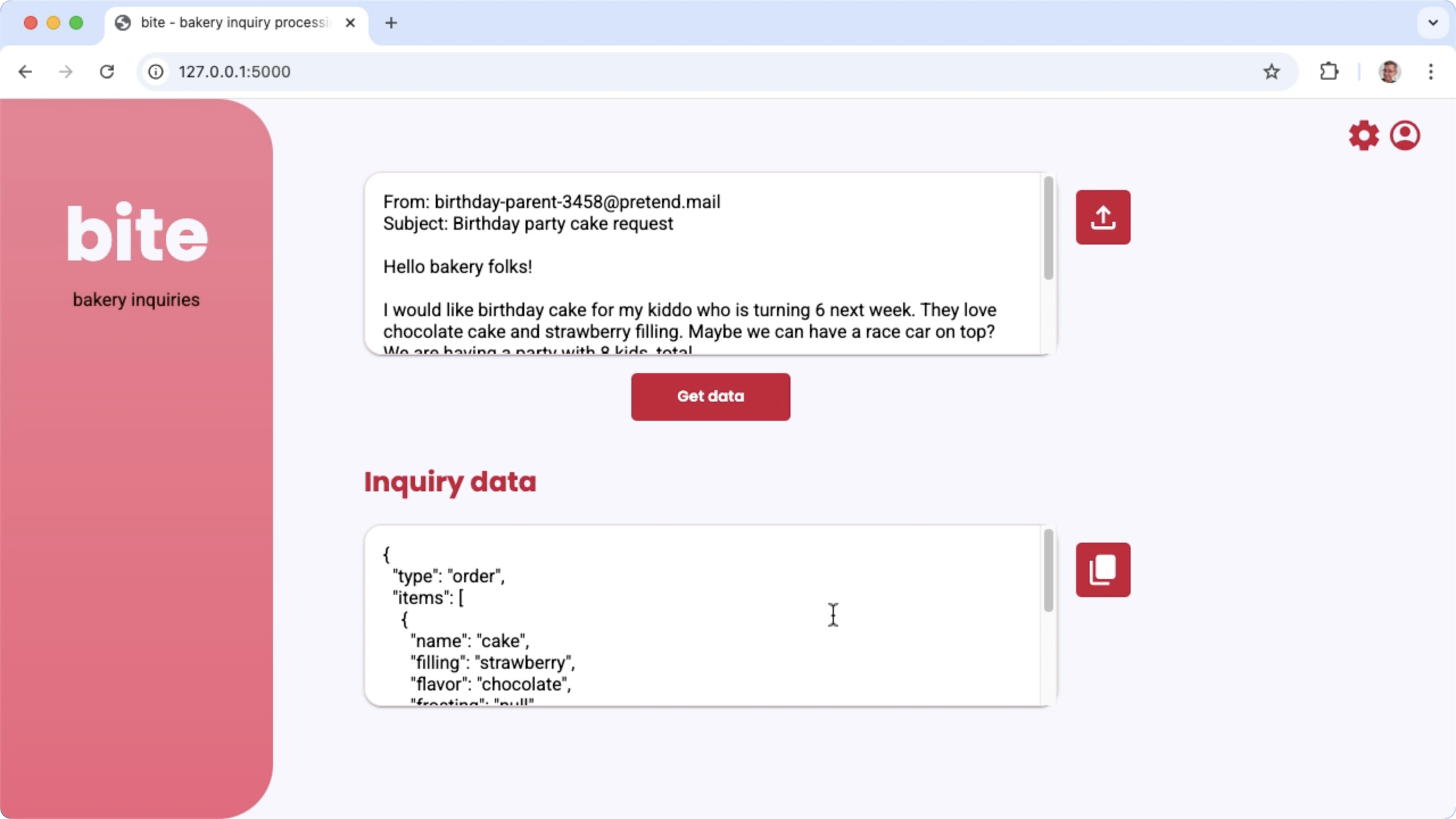
Gambar 1. Antarmuka pengguna Project untuk memproses pertanyaan email toko roti
Persyaratan hardware
Jalankan proses penyetelan ini di komputer dengan unit pemrosesan grafis (GPU) atau Tensor processing unit (TPU), dan memori GPU atau TPU yang memadai untuk menyimpan model yang ada, serta data penyetelan. Untuk menjalankan konfigurasi penyetelan dalam project ini, Anda memerlukan memori GPU sekitar 16 GB, RAM biasa dengan jumlah yang sama, dan ruang disk minimal 50 GB.
Anda dapat menjalankan bagian penyesuaian model Gemma dalam tutorial ini menggunakan lingkungan Colab dengan runtime GPU T4. Jika Anda membangun project ini di instance VM Google Cloud, konfigurasi instance dengan mengikuti persyaratan berikut:
- Hardware GPU: NVIDIA T4 diperlukan untuk menjalankan project ini (NVIDIA L4 atau yang lebih tinggi direkomendasikan)
- Operating System: Pilih opsi Deep Learning on Linux, khususnya Deep Learning VM with CUDA 12.3 M124 dengan driver software GPU yang telah diinstal sebelumnya.
- Ukuran boot disk: Sediakan ruang disk minimal 50 GB untuk data, model, dan software pendukung Anda.
Penyiapan project
Petunjuk ini akan memandu Anda menyiapkan project ini untuk pengembangan dan pengujian. Langkah-langkah penyiapan umum mencakup penginstalan software prasyarat, pengkloningan project dari repositori kode, penyetelan beberapa variabel lingkungan, penginstalan library Python, dan pengujian aplikasi web.
Menginstal dan mengonfigurasi
Project ini menggunakan Python 3 dan Lingkungan Virtual (venv) untuk mengelola paket
dan menjalankan aplikasi. Petunjuk penginstalan berikut ditujukan untuk mesin host Linux.
Untuk menginstal software yang diperlukan:
Instal Python 3 dan paket lingkungan virtual
venvuntuk Python:sudo apt update sudo apt install git pip python3-venv
Meng-clone project
Download kode project ke komputer pengembangan Anda. Anda memerlukan software kontrol sumber git untuk mengambil kode sumber project.
Untuk mendownload kode project:
Clone repositori git menggunakan perintah berikut:
git clone https://github.com/google-gemini/gemma-cookbook.gitSecara opsional, konfigurasi repositori git lokal Anda untuk menggunakan checkout jarang, sehingga Anda hanya memiliki file untuk project:
cd gemma-cookbook/ git sparse-checkout set Demos/business-email-assistant/ git sparse-checkout init --cone
Menginstal library Python
Instal pustaka Python dengan venvlingkungan virtual Python
diaktifkan untuk mengelola paket dan dependensi Python. Pastikan Anda mengaktifkan
lingkungan virtual Python sebelum menginstal library Python dengan penginstal pip. Untuk mengetahui informasi selengkapnya tentang penggunaan lingkungan virtual Python, lihat dokumentasi
venv Python.
Untuk menginstal library Python:
Di jendela terminal, buka direktori
business-email-assistant:cd Demos/business-email-assistant/Konfigurasi dan aktifkan lingkungan virtual Python (venv) untuk project ini:
python3 -m venv venv source venv/bin/activateInstal library Python yang diperlukan untuk project ini menggunakan skrip
setup_python:./setup_python.sh
Menetapkan variabel lingkungan
Project ini memerlukan beberapa variabel lingkungan untuk dijalankan, termasuk nama pengguna Kaggle dan token API Kaggle. Anda harus memiliki akun Kaggle dan meminta akses ke model Gemma untuk dapat mendownloadnya. Untuk
project ini, Anda menambahkan Nama Pengguna Kaggle dan token API Kaggle ke dua file .env, yang dibaca oleh aplikasi web dan program penyesuaian.
Untuk menetapkan variabel lingkungan:
- Dapatkan nama pengguna Kaggle dan kunci token Anda dengan mengikuti petunjuk dalam dokumentasi Kaggle.
- Dapatkan akses ke model Gemma dengan mengikuti petunjuk Mendapatkan akses ke Gemma di halaman Penyiapan Gemma.
- Buat file variabel lingkungan untuk project, dengan membuat file teks
.envdi setiap lokasi ini dalam clone project Anda:email-processing-webapp/.env model-tuning/.env
Setelah membuat file teks
.env, tambahkan setelan berikut ke kedua file:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
Menjalankan dan menguji aplikasi
Setelah Anda menyelesaikan penginstalan dan konfigurasi project, jalankan aplikasi web untuk mengonfirmasi bahwa Anda telah mengonfigurasinya dengan benar. Anda harus melakukannya sebagai pemeriksaan dasar sebelum mengedit project untuk penggunaan Anda sendiri.
Untuk menjalankan dan menguji project:
Di jendela terminal, buka direktori
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Jalankan aplikasi menggunakan skrip
run_app:./run_app.shSetelah memulai aplikasi web, kode program mencantumkan URL tempat Anda dapat menjelajah dan menguji. Biasanya, alamat ini adalah:
http://127.0.0.1:5000/Di antarmuka web, tekan tombol Dapatkan data di bawah kolom input pertama untuk menghasilkan respons dari model.
Respons pertama dari model setelah Anda menjalankan aplikasi membutuhkan waktu lebih lama karena harus menyelesaikan langkah-langkah inisialisasi pada proses pembuatan pertama. Permintaan dan pembuatan perintah berikutnya di aplikasi web yang sudah berjalan selesai dalam waktu yang lebih singkat.
Memperluas aplikasi
Setelah aplikasi berjalan, Anda dapat memperluasnya dengan mengubah antarmuka pengguna dan logika bisnis agar berfungsi untuk tugas yang relevan bagi Anda atau bisnis Anda. Anda juga dapat mengubah perilaku model Gemma menggunakan kode aplikasi dengan mengubah komponen perintah yang dikirim aplikasi ke model AI generatif.
Aplikasi memberikan petunjuk kepada model bersama dengan data input dari pengguna untuk melengkapi perintah model. Anda dapat mengubah petunjuk ini untuk mengubah perilaku model, seperti menentukan nama parameter dan struktur JSON yang akan dibuat. Cara yang lebih sederhana untuk mengubah perilaku model adalah dengan memberikan petunjuk atau panduan tambahan untuk respons model, seperti menentukan bahwa balasan yang dihasilkan tidak boleh menyertakan format Markdown.
Untuk mengubah petunjuk perintah:
- Di project pengembangan, buka file kode
business-email-assistant/email-processing-webapp/app.py. Dalam kode
app.py, tambahkan petunjuk tambahan ke fungsiget_prompt()::def get_prompt(): return """ Extract the relevant details of this request and return them in JSON code, with no additional markdown formatting:\n"""
Contoh ini menambahkan frasa "tanpa format markdown tambahan" ke petunjuk.
Memberikan petunjuk perintah tambahan dapat sangat memengaruhi output yang dihasilkan, dan memerlukan upaya yang jauh lebih sedikit untuk diterapkan. Anda harus mencoba metode ini terlebih dahulu untuk melihat apakah Anda bisa mendapatkan perilaku yang diinginkan dari model. Namun, penggunaan petunjuk perintah untuk mengubah perilaku model Gemma memiliki batasnya. Secara khusus, batas token input keseluruhan model, yaitu 8.192 token untuk Gemma 2, mengharuskan Anda menyeimbangkan petunjuk perintah yang mendetail dengan ukuran data baru yang Anda berikan agar Anda tetap berada di bawah batas tersebut.
Menyesuaikan model
Melakukan penyesuaian model Gemma adalah cara yang direkomendasikan untuk membuatnya merespons lebih andal untuk tugas tertentu. Khususnya, jika Anda ingin model membuat JSON dengan struktur tertentu, termasuk parameter yang diberi nama secara khusus, Anda harus mempertimbangkan untuk menyesuaikan model agar berperilaku seperti itu. Bergantung pada tugas yang ingin Anda selesaikan dengan model, Anda dapat mencapai fungsi dasar dengan 10 hingga 20 contoh. Bagian tutorial ini menjelaskan cara menyiapkan dan menjalankan penyesuaian pada model Gemma untuk tugas tertentu.
Petunjuk berikut menjelaskan cara melakukan operasi penyesuaian pada lingkungan VM, tetapi Anda juga dapat melakukan operasi penyesuaian ini menggunakan notebook Colab terkait untuk project ini.
Persyaratan hardware
Persyaratan komputasi untuk penyesuaian sama dengan persyaratan hardware untuk project lainnya. Anda dapat menjalankan operasi penyetelan di lingkungan Colab dengan runtime GPU T4 jika Anda membatasi token input hingga 256 dan ukuran batch hingga 1.
Menyiapkan data
Sebelum mulai menyesuaikan model Gemma, Anda harus menyiapkan data untuk penyesuaian. Saat menyesuaikan model untuk tugas tertentu, Anda memerlukan serangkaian contoh permintaan dan respons. Contoh ini harus menampilkan teks permintaan, tanpa petunjuk apa pun, dan teks respons yang diharapkan. Untuk memulai, Anda harus menyiapkan set data dengan sekitar 10 contoh. Contoh ini harus mewakili berbagai permintaan dan respons ideal. Pastikan permintaan dan respons tidak berulang, karena hal itu dapat menyebabkan respons model berulang dan tidak menyesuaikan dengan tepat variasi dalam permintaan. Jika Anda menyesuaikan model untuk menghasilkan format data terstruktur, pastikan semua respons yang diberikan benar-benar sesuai dengan format output data yang Anda inginkan. Tabel berikut menunjukkan beberapa contoh rekaman dari set data contoh kode ini:
| Permintaan | Respons |
|---|---|
| Halo, Indian Bakery Central,\nApakah Anda memiliki 10 penda, dan tiga puluh bundi ladoo? Apakah Anda juga menjual frosting vanila dan kue rasa cokelat. Saya mencari ukuran 6 inci | { "type": "inquiry", "items": [ { "name": "pendas", "quantity": 10 }, { "name": "bundi ladoos", "quantity": 30 }, { "name": "cake", "filling": null, "frosting": "vanilla", "flavor": "chocolate", "size": "6 in" } ] } |
| Saya melihat bisnis Anda di Google Maps. Apakah Anda menjual jalebi dan gulab jamun? | { "type": "inquiry", "items": [ { "name": "jellabi", "quantity": null }, { "name": "gulab jamun", "quantity": null } ] } |
Tabel 1. Listingan sebagian set data tuning untuk ekstraktor data email toko roti.
Format dan pemuatan data
Anda dapat menyimpan data penyesuaian dalam format apa pun yang nyaman, termasuk
rekaman database, file JSON, CSV, atau file teks biasa, selama Anda memiliki
cara untuk mengambil rekaman dengan kode Python. Project ini membaca file JSON
dari direktori data ke dalam array objek kamus.
Dalam program penyesuaian contoh ini, set data penyesuaian dimuat di modul
model-tuning/main.py menggunakan fungsi prepare_tuning_dataset():
def prepare_tuning_dataset():
# collect data from JSON files
prompt_data = read_json_files_to_dicts("./data")
...
Seperti yang disebutkan sebelumnya, Anda dapat menyimpan set data dalam format yang nyaman, selama Anda dapat mengambil permintaan dengan respons terkait dan menyusunnya menjadi string teks yang digunakan sebagai rekaman penyetelan.
Menyusun rekaman penyetelan
Untuk proses penyesuaian yang sebenarnya, program mengumpulkan setiap permintaan dan respons
ke dalam satu string dengan petunjuk perintah dan konten
respons. Program penyesuaian kemudian melakukan tokenisasi string untuk digunakan oleh
model. Anda dapat melihat kode untuk menyusun rekaman penyesuaian dalam
fungsi prepare_tuning_dataset() modul model-tuning/main.py, sebagai berikut:
def prepare_tuning_dataset():
...
# prepare data for tuning
tuning_dataset = []
template = "{instruction}\n{response}"
for prompt in prompt_data:
tuning_dataset.append(template.format(instruction=prompt["prompt"],
response=prompt["response"]))
return tuning_dataset
Fungsi ini menggunakan data sebagai input dan memformatnya dengan menambahkan jeda baris antara petunjuk dan respons.
Membuat bobot model
Setelah data penyesuaian tersedia dan dimuat, Anda dapat menjalankan program penyesuaian. Proses penyesuaian untuk aplikasi contoh ini menggunakan library Keras NLP untuk menyesuaikan model dengan teknik Low Rank Adaptation, atau LoRA, untuk membuat bobot model baru. Dibandingkan dengan penyesuaian presisi penuh, penggunaan LoRA jauh lebih efisien dalam penggunaan memori karena memperkirakan perubahan pada bobot model. Kemudian, Anda dapat melapisi bobot yang diperkirakan ini ke bobot model yang ada untuk mengubah perilaku model.
Untuk menjalankan penyesuaian dan menghitung bobot baru:
Di jendela terminal, buka direktori
model-tuning/.cd business-email-assistant/model-tuning/Jalankan proses penyesuaian menggunakan skrip
tune_model:./tune_model.sh
Proses penyesuaian akan memerlukan waktu beberapa menit, bergantung pada resource komputasi yang tersedia. Jika berhasil diselesaikan, program penyetelan akan menulis file bobot *.h5 baru dalam direktori model-tuning/weights dengan format berikut:
gemma2-2b_inquiry_tuned_4_epoch##.lora.h5
Pemecahan masalah
Jika penyetelan tidak berhasil diselesaikan, ada dua kemungkinan alasan:
- Kehabisan memori atau resource: Error ini terjadi saat proses penyesuaian meminta memori yang melebihi memori GPU atau memori CPU yang tersedia. Pastikan Anda tidak menjalankan aplikasi web saat proses penyesuaian sedang berjalan. Jika Anda melakukan penyesuaian pada perangkat dengan memori GPU 16 GB, pastikan Anda menyetel
token_limitke 256 danbatch_sizeke 1. - Driver GPU tidak diinstal atau tidak kompatibel dengan JAX: Proses penyetelan memerlukan penginstalan driver hardware pada perangkat komputasi yang kompatibel dengan versi library JAX. Untuk mengetahui detail selengkapnya, lihat dokumentasi penginstalan JAX.
Men-deploy model yang disesuaikan
Proses penyesuaian menghasilkan beberapa bobot berdasarkan data penyesuaian dan jumlah total epoch yang ditetapkan dalam aplikasi penyesuaian. Secara default, program penyesuaian membuat 3 file bobot model, satu untuk setiap epoch penyesuaian. Setiap epoch penyesuaian yang berurutan menghasilkan bobot yang mereproduksi hasil data penyesuaian dengan lebih akurat. Anda dapat melihat tingkat akurasi untuk setiap epoch dalam output terminal proses penyetelan, sebagai berikut:
...
8/8 ━━━━━━━━━━━━━━━━━━━━ 121s 195ms/step - loss: 0.5432 - sparse_categorical_accuracy: 0.5982
Epoch 2/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 194ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.6966
Epoch 3/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 192ms/step - loss: 0.2135 - sparse_categorical_accuracy: 0.7848
Meskipun Anda ingin tingkat akurasi relatif tinggi, sekitar 0,80, Anda tidak ingin tingkat akurasi terlalu tinggi, atau sangat mendekati 1,00, karena berarti bobot hampir mengalami overfitting data penyesuaian. Jika hal itu terjadi, model tidak akan berfungsi dengan baik pada permintaan yang sangat berbeda dari contoh penyesuaian. Secara default, skrip deployment memilih bobot epoch 3 yang biasanya memiliki tingkat akurasi sekitar 0, 80.
Untuk men-deploy bobot yang dihasilkan ke aplikasi web:
Di jendela terminal, buka direktori
model-tuning:cd business-email-assistant/model-tuning/Jalankan proses penyesuaian menggunakan skrip
deploy_weights:./deploy_weights.sh
Setelah menjalankan skrip ini, Anda akan melihat file *.h5 baru di direktori email-processing-webapp/weights/.
Menguji model baru
Setelah men-deploy bobot baru ke aplikasi, saatnya mencoba model yang baru di-tune. Anda dapat melakukannya dengan menjalankan ulang aplikasi web dan membuat respons.
Untuk menjalankan dan menguji project:
Di jendela terminal, buka direktori
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Jalankan aplikasi menggunakan skrip
run_app:./run_app.shSetelah memulai aplikasi web, kode program mencantumkan URL tempat Anda dapat menjelajahi dan menguji, biasanya alamat ini adalah:
http://127.0.0.1:5000/Di antarmuka web, tekan tombol Dapatkan data di bawah kolom input pertama untuk menghasilkan respons dari model.
Anda kini telah menyetel dan men-deploy model Gemma dalam aplikasi. Bereksperimen dengan aplikasi dan coba tentukan batas kemampuan pembuatan model yang di-tuning untuk tugas Anda. Jika Anda menemukan skenario saat model tidak berperforma baik, pertimbangkan untuk menambahkan beberapa permintaan tersebut ke daftar data contoh penyesuaian Anda dengan menambahkan permintaan dan memberikan respons yang ideal. Kemudian, jalankan ulang proses penyesuaian, deploy ulang bobot baru, dan uji outputnya.
Referensi lainnya
Untuk mengetahui informasi selengkapnya tentang project ini, lihat repositori kode Gemma Cookbook. Jika Anda memerlukan bantuan untuk membuat aplikasi atau ingin berkolaborasi dengan developer lain, buka server Discord Komunitas Developer Google. Untuk melihat project Build with Google AI lainnya, tonton playlist video.