
इस गाइड में, Hugging Face Safetensors फ़ॉर्मैट (.safetensors) में मौजूद Gemma मॉडल को MediaPipe Task फ़ाइल फ़ॉर्मैट (.task) में बदलने के निर्देश दिए गए हैं. इस बदलाव की ज़रूरत तब पड़ती है, जब आपको Android और iOS पर डिवाइस पर अनुमान लगाने के लिए, पहले से ट्रेन किए गए या फ़ाइन-ट्यून किए गए Gemma मॉडल को डिप्लॉय करना हो. इसके लिए, MediaPipe LLM Inference API और LiteRT रनटाइम का इस्तेमाल किया जाता है.
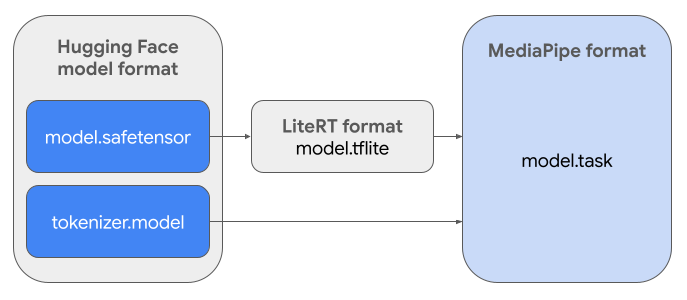
ज़रूरी टास्क बंडल (.task) बनाने के लिए, आपको LiteRT Torch का इस्तेमाल करना होगा. यह टूल, PyTorch मॉडल को मल्टी-सिग्नेचर LiteRT (.tflite) मॉडल में एक्सपोर्ट करता है. ये मॉडल, MediaPipe LLM Inference API के साथ काम करते हैं. साथ ही, मोबाइल ऐप्लिकेशन में सीपीयू बैकएंड पर चलाने के लिए सही होते हैं.
फ़ाइनल .task फ़ाइल, MediaPipe के लिए ज़रूरी एक पैकेज है. इसमें LiteRT मॉडल, टोकनाइज़र मॉडल, और ज़रूरी मेटाडेटा शामिल होता है. यह बंडल ज़रूरी है, क्योंकि टोकनाइज़र (जो टेक्स्ट प्रॉम्प्ट को मॉडल के लिए टोकन एम्बेडिंग में बदलता है) को LiteRT मॉडल के साथ पैकेज किया जाना चाहिए, ताकि शुरू से लेकर आखिर तक इंटरफ़ेस चालू किया जा सके.
इस प्रोसेस के बारे में यहां सिलसिलेवार तरीके से बताया गया है:
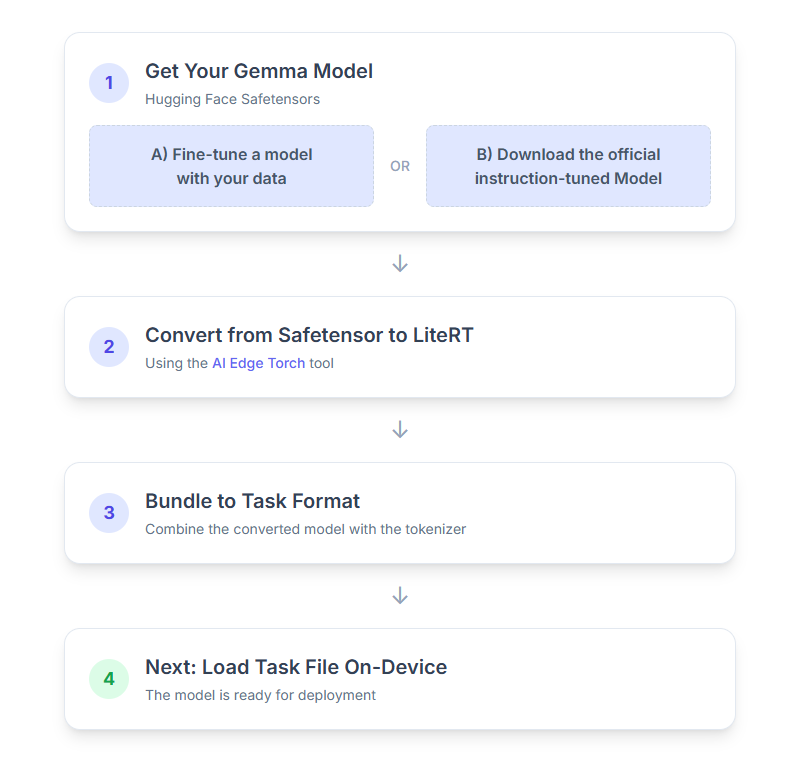
1. Gemma मॉडल पाना
शुरू करने के लिए आपके पास दो विकल्प हैं.
विकल्प A. फ़ाइन-ट्यून किए गए किसी मौजूदा मॉडल का इस्तेमाल करना
अगर आपके पास फ़ाइन-ट्यून किया गया Gemma मॉडल तैयार है, तो बस अगले चरण पर जाएं.
विकल्प B. निर्देशों के मुताबिक काम करने वाला आधिकारिक मॉडल डाउनलोड करना
अगर आपको किसी मॉडल की ज़रूरत है, तो Hugging Face Hub से निर्देश के मुताबिक तैयार किया गया Gemma मॉडल डाउनलोड किया जा सकता है.
ज़रूरी टूल सेट अप करें:
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
मॉडल डाउनलोड करना:
Hugging Face Hub पर मौजूद मॉडल की पहचान, मॉडल आईडी से की जाती है. आम तौर पर, यह <organization_or_username>/<model_name> फ़ॉर्मैट में होता है. उदाहरण के लिए, Google Gemma 3 270M के आधिकारिक तौर पर उपलब्ध, निर्देश के मुताबिक काम करने वाले मॉडल को डाउनलोड करने के लिए, इस कमांड का इस्तेमाल करें:
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
2. मॉडल को LiteRT में बदलें और उसे क्वांटाइज़ करें
Python का वर्चुअल एनवायरमेंट सेट अप करें और LiteRT Torch पैकेज का सबसे नया स्टेबल वर्शन इंस्टॉल करें:
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
Safetensor को LiteRT मॉडल में बदलने के लिए, इस स्क्रिप्ट का इस्तेमाल करें.
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
ध्यान रखें कि इस प्रोसेस में समय लगता है. यह आपके कंप्यूटर की प्रोसेसिंग स्पीड पर निर्भर करती है. उदाहरण के लिए, 2025 के आठ कोर वाले सीपीयू पर, 27 करोड़ पैरामीटर वाले मॉडल को प्रोसेस करने में पांच से 10 मिनट लगते हैं. वहीं, एक अरब पैरामीटर वाले मॉडल को प्रोसेस करने में 10 से 30 मिनट लग सकते हैं.
फ़ाइनल आउटपुट, LiteRT मॉडल के तौर पर आपके तय किए गए OUTPUT_DIR_PATH में सेव किया जाएगा.
अपने टारगेट डिवाइस की मेमोरी और परफ़ॉर्मेंस की सीमाओं के आधार पर, इन वैल्यू को अडजस्ट करें.
kv_cache_max_len: इससे मॉडल की वर्किंग मेमोरी (केवी कैश) के लिए, कुल तय किए गए साइज़ के बारे में पता चलता है. यह क्षमता एक तय सीमा है. इसमें प्रॉम्प्ट के टोकन (प्रीफ़िल) और बाद में जनरेट किए गए सभी टोकन (डिकोड) को मिलाकर स्टोर करने के लिए, ज़रूरी जगह होनी चाहिए.prefill_seq_len: यह पैरामीटर, प्रीफ़िल चंकिंग के लिए इनपुट प्रॉम्प्ट के टोकन की संख्या के बारे में बताता है. प्रीफ़िल चंकिंग का इस्तेमाल करके इनपुट प्रॉम्प्ट को प्रोसेस करते समय, पूरे क्रम (जैसे, 50,000 टोकन) की एक साथ गणना नहीं की जाती. इसके बजाय, इसे मैनेज किए जा सकने वाले सेगमेंट में बांटा जाता है. उदाहरण के लिए, 2,048 टोकन के चंक. इन्हें क्रम से कैश मेमोरी में लोड किया जाता है, ताकि मेमोरी से जुड़ी गड़बड़ी न हो.quantize: चुने गए क्वांटाइज़ेशन स्कीम के लिए स्ट्रिंग. Gemma 3 के लिए, उपलब्ध क्वांटाइज़ेशन रेसिपी की सूची यहां दी गई है.none: कोई क्वॉन्टाइज़ेशन नहींfp16: सभी ऑप्स के लिए FP16 वेट, FP32 ऐक्टिवेशन, और फ़्लोटिंग पॉइंट कंप्यूटेशनdynamic_int8: FP32 ऐक्टिवेशन, INT8 वज़न, और पूर्णांक कंप्यूटेशनweight_only_int8: FP32 ऐक्टिवेशन, INT8 वेट, और फ़्लोटिंग पॉइंट कंप्यूटेशन
3. LiteRT और टोकनाइज़र से टास्क बंडल बनाना
Python का वर्चुअल एनवायरमेंट सेट अप करें और mediapipe Python पैकेज इंस्टॉल करें:
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
मॉडल को बंडल करने के लिए, genai.bundler लाइब्रेरी का इस्तेमाल करें:
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
bundler.create_bundle फ़ंक्शन, एक .task फ़ाइल बनाता है. इसमें मॉडल को चलाने के लिए ज़रूरी सभी जानकारी होती है.
4. Android पर Mediapipe की मदद से अनुमान लगाना
टास्क को बुनियादी कॉन्फ़िगरेशन विकल्पों के साथ शुरू करें:
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
टेक्स्ट वाला जवाब जनरेट करने के लिए, generateResponse() तरीके का इस्तेमाल करें.
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
जवाब को स्ट्रीम करने के लिए, generateResponseAsync() तरीके का इस्तेमाल करें.
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
ज़्यादा जानकारी के लिए, Android के लिए एलएलएम इन्फ़रेंस गाइड देखें.
अगले चरण
Gemma मॉडल की मदद से, ज़्यादा ऐप्लिकेशन बनाएँ और उन्हें एक्सप्लोर करें:
- मोबाइल डिवाइसों पर Gemma को डिप्लॉय करना
- Hugging Face Transformers का इस्तेमाल करके, टेक्स्ट से जुड़े टास्क के लिए Gemma को फ़ाइन-ट्यून करना
- Hugging Face Transformers का इस्तेमाल करके, विज़न टास्क के लिए Gemma को फ़ाइन-ट्यून करना
- Hugging Face Transformers का इस्तेमाल करके, पूरे मॉडल को फ़ाइन-ट्यून करना