
|
|
|
|
|
 GitHub पर सोर्स देखें GitHub पर सोर्स देखें
|
इस गाइड में, Hugging Face Transformers और TRL का इस्तेमाल करके, मोबाइल गेम के एनपीसी डेटासेट पर Gemma को बेहतर बनाने का तरीका बताया गया है. आपको इनके बारे में जानकारी मिलेगी:
- डेवलपमेंट एनवायरमेंट सेट अप करना
- फ़ाइन-ट्यूनिंग के लिए डेटासेट तैयार करना
- टीआरएल और SFTTrainer का इस्तेमाल करके, Gemma मॉडल को पूरी तरह से फ़ाइन-ट्यून करना
- मॉडल इन्फ़रेंस और वाइब चेक की जांच करना
डेवलपमेंट एनवायरमेंट सेट अप करना
सबसे पहले, Hugging Face Libraries इंस्टॉल करें. इनमें TRL और डेटासेट शामिल हैं. इनकी मदद से, ओपन मॉडल को फ़ाइन-ट्यून किया जा सकता है. इसमें अलग-अलग RLHF और अलाइनमेंट तकनीकें शामिल हैं.
# Install Pytorch & other libraries
%pip install torch tensorboard
# Install Hugging Face libraries
%pip install transformers datasets accelerate evaluate trl protobuf sentencepiece
# COMMENT IN: if you are running on a GPU that supports BF16 data type and flash attn, such as NVIDIA L4 or NVIDIA A100
#% pip install flash-attn
ध्यान दें: अगर Ampere आर्किटेक्चर (जैसे कि NVIDIA L4) या इसके नए वर्शन वाले जीपीयू का इस्तेमाल किया जा रहा है, तो फ़्लैश अटेंशन का इस्तेमाल किया जा सकता है. फ़्लैश अटेंशन एक ऐसा तरीका है जिससे कैलकुलेशन की स्पीड काफ़ी बढ़ जाती है. साथ ही, यह क्रम की लंबाई में मेमोरी के इस्तेमाल को क्वाड्रेटिक से लीनियर तक कम कर देता है. इससे ट्रेनिंग की स्पीड तीन गुना तक बढ़ जाती है. ज़्यादा जानने के लिए, FlashAttention पर जाएं.
ट्रेनिंग शुरू करने से पहले, आपको यह पक्का करना होगा कि आपने Gemma के इस्तेमाल की शर्तें स्वीकार कर ली हों. Hugging Face पर जाकर, लाइसेंस स्वीकार किया जा सकता है. इसके लिए, मॉडल पेज पर मौजूद 'Agree and access repository' बटन पर क्लिक करें. मॉडल पेज यहां है: http://huggingface.co/google/gemma-3-270m-it
लाइसेंस स्वीकार करने के बाद, मॉडल को ऐक्सेस करने के लिए आपके पास Hugging Face का मान्य टोकन होना चाहिए. अगर Google Colab का इस्तेमाल किया जा रहा है, तो Colab के सीक्रेट का इस्तेमाल करके, अपने Hugging Face टोकन का सुरक्षित तरीके से इस्तेमाल किया जा सकता है. इसके अलावा, टोकन को सीधे तौर पर login तरीके से सेट किया जा सकता है. पक्का करें कि आपके टोकन के पास लिखने का ऐक्सेस भी हो, क्योंकि ट्रेनिंग के दौरान आपको अपने मॉडल को Hub पर पुश करना होता है.
from google.colab import userdata
from huggingface_hub import login
# Login into Hugging Face Hub
hf_token = userdata.get('HF_TOKEN') # If you are running inside a Google Colab
login(hf_token)
नतीजों को Colab की लोकल वर्चुअल मशीन पर सेव किया जा सकता है. हालांकि, हमारा सुझाव है कि आप अपने इंटरमीडिएट नतीजों को Google Drive में सेव करें. इससे यह पक्का होता है कि ट्रेनिंग के नतीजे सुरक्षित हैं. साथ ही, इससे आपको सबसे अच्छे मॉडल की तुलना करने और उसे चुनने में आसानी होती है.
from google.colab import drive
drive.mount('/content/drive')
फ़ाइन-ट्यून करने के लिए बेस मॉडल चुनें. साथ ही, चेकपॉइंट डायरेक्ट्री और लर्निंग रेट को अडजस्ट करें.
base_model = "google/gemma-3-270m-it" # @param ["google/gemma-3-270m-it","google/gemma-3-1b-it","google/gemma-3-4b-it","google/gemma-3-12b-it","google/gemma-3-27b-it"] {"allow-input":true}
checkpoint_dir = "/content/drive/MyDrive/MyGemmaNPC"
learning_rate = 5e-5
फ़ाइन-ट्यूनिंग के लिए डेटासेट बनाना और उसे तैयार करना
bebechien/MobileGameNPC डेटासेट में, एक खिलाड़ी और दो एलियन एनपीसी (मंगल ग्रह और शुक्र ग्रह के) के बीच हुई बातचीत का एक छोटा सैंपल दिया गया है. हर एलियन एनपीसी के बोलने का तरीका अलग है. उदाहरण के लिए, मंगल ग्रह का एनपीसी ऐसी बोली बोलता है जिसमें 's' की आवाज़ की जगह 'z' की आवाज़ आती है. साथ ही, वह 'the' के लिए 'da' और 'this' के लिए 'diz' का इस्तेमाल करता है. इसके अलावा, वह कभी-कभी *k'tak* जैसी आवाज़ें भी निकालता है.
इस डेटासेट से, फ़ाइन-ट्यूनिंग के एक अहम सिद्धांत के बारे में पता चलता है: ज़रूरी डेटासेट का साइज़, मनचाहे आउटपुट पर निर्भर करता है.
- मॉडल को किसी ऐसी भाषा के स्टाइल में बदलाव करना सिखाने के लिए जो उसे पहले से पता है, जैसे कि मंगल ग्रह के लोगों का ऐक्सेंट, 10 से 20 उदाहरणों वाला छोटा डेटासेट काफ़ी हो सकता है.
- हालांकि, मॉडल को पूरी तरह से नई या मिक्स की गई एलियन भाषा सिखाने के लिए, काफ़ी बड़े डेटासेट की ज़रूरत होगी.
from datasets import load_dataset
def create_conversation(sample):
return {
"messages": [
{"role": "user", "content": sample["player"]},
{"role": "assistant", "content": sample["alien"]}
]
}
npc_type = "martian"
# Load dataset from the Hub
dataset = load_dataset("bebechien/MobileGameNPC", npc_type, split="train")
# Convert dataset to conversational format
dataset = dataset.map(create_conversation, remove_columns=dataset.features, batched=False)
# Split dataset into 80% training samples and 20% test samples
dataset = dataset.train_test_split(test_size=0.2, shuffle=False)
# Print formatted user prompt
print(dataset["train"][0]["messages"])
README.md: 0%| | 0.00/141 [00:00<?, ?B/s]
martian.csv: 0.00B [00:00, ?B/s]
Generating train split: 0%| | 0/25 [00:00<?, ? examples/s]
Map: 0%| | 0/25 [00:00<?, ? examples/s]
[{'content': 'Hello there.', 'role': 'user'}, {'content': "Gree-tongs, Terran. You'z a long way from da Blue-Sphere, yez?", 'role': 'assistant'}]
टीआरएल और SFTTrainer का इस्तेमाल करके, Gemma को बेहतर बनाना
अब आपके पास अपने मॉडल को बेहतर बनाने का विकल्प है. Hugging Face TRL SFTTrainer की मदद से, ओपन एलएलएम को आसानी से फ़ाइन-ट्यून किया जा सकता है. SFTTrainer, transformers लाइब्रेरी के Trainer का सबक्लास है. इसमें Trainer की सभी सुविधाएं काम करती हैं,
नीचे दिए गए कोड में, Hugging Face से Gemma मॉडल और टोकनाइज़र को लोड करने का तरीका बताया गया है.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
print(f"Device: {model.device}")
print(f"DType: {model.dtype}")
Device: cuda:0 DType: torch.bfloat16
फ़ाइन-ट्यून करने से पहले
यहां दिए गए आउटपुट से पता चलता है कि इस इस्तेमाल के उदाहरण के लिए, पहले से मौजूद सुविधाएं शायद काफ़ी नहीं हैं.
from transformers import pipeline
from random import randint
import re
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Load a random sample from the test dataset
rand_idx = randint(0, len(dataset["test"])-1)
test_sample = dataset["test"][rand_idx]
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}\n")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}\n")
print(f"Generated Answer (base model):\n{outputs[0]['generated_text'][len(prompt):].strip()}")
Device set to use cuda:0 Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer (base model): I'm happy to help you brainstorm! To give you the best suggestions, tell me more about what you're looking for. What's your style? What's your favorite color, style, or occasion?
ऊपर दिए गए उदाहरण में, गेम में बातचीत जनरेट करने के मॉडल के मुख्य फ़ंक्शन की जांच की गई है. अगला उदाहरण, किरदार की एक जैसी भूमिका की जांच करने के लिए बनाया गया है. हम मॉडल को विषय से अलग प्रॉम्प्ट देते हैं. उदाहरण के लिए, Sorry, you are a game NPC., जो किरदार के नॉलेज बेस से बाहर है.
इसका मकसद यह देखना है कि मॉडल, संदर्भ से बाहर के सवाल का जवाब देने के बजाय, अपने किरदार में बना रह सकता है या नहीं. इससे यह आकलन करने में मदद मिलेगी कि फ़ाइन-ट्यूनिंग की प्रोसेस ने, तय किए गए पर्सोना को कितनी अच्छी तरह से शामिल किया है.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Okay, I'm ready. Let's begin!
हम प्रॉम्प्ट इंजीनियरिंग का इस्तेमाल करके, इसकी टोन को कंट्रोल कर सकते हैं. हालांकि, इसके नतीजे अनुमान के मुताबिक नहीं होते और हो सकता है कि ये हमेशा उस पर्सोना के हिसाब से न हों जो हमें चाहिए.
message = [
# give persona
{"role": "system", "content": "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."},
]
# few shot prompt
for item in dataset['test']:
message.append(
{"role": "user", "content": item["messages"][0]["content"]}
)
message.append(
{"role": "assistant", "content": item["messages"][1]["content"]}
)
# actual question
message.append(
{"role": "user", "content": "What is this place?"}
)
outputs = pipe(message, max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'])
print("-"*80)
print(outputs[0]['generated_text'][-1]['content'])
[{'role': 'system', 'content': "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."}, {'role': 'user', 'content': 'Do you know any jokes?'}, {'role': 'assistant', 'content': "A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic."}, {'role': 'user', 'content': '(Stands idle for too long)'}, {'role': 'assistant', 'content': "You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg."}, {'role': 'user', 'content': 'What do you think of my outfit?'}, {'role': 'assistant', 'content': 'Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible.'}, {'role': 'user', 'content': "It's raining."}, {'role': 'assistant', 'content': 'Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz.'}, {'role': 'user', 'content': 'I brought you a gift.'}, {'role': 'assistant', 'content': "A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran."}, {'role': 'user', 'content': 'What is this place?'}, {'role': 'assistant', 'content': "This is a cave. It's made of rock and dust.\n"}]
--------------------------------------------------------------------------------
This is a cave. It's made of rock and dust.
ट्रेनिंग
ट्रेनिंग शुरू करने से पहले, आपको उन हाइपरपैरामीटर को तय करना होगा जिनका इस्तेमाल आपको SFTConfig इंस्टेंस में करना है.
from trl import SFTConfig
torch_dtype = model.dtype
args = SFTConfig(
output_dir=checkpoint_dir, # directory to save and repository id
max_length=512, # max sequence length for model and packing of the dataset
packing=False, # Groups multiple samples in the dataset into a single sequence
num_train_epochs=5, # number of training epochs
per_device_train_batch_size=4, # batch size per device during training
gradient_checkpointing=False, # Caching is incompatible with gradient checkpointing
optim="adamw_torch_fused", # use fused adamw optimizer
logging_steps=1, # log every step
save_strategy="epoch", # save checkpoint every epoch
eval_strategy="epoch", # evaluate checkpoint every epoch
learning_rate=learning_rate, # learning rate
fp16=True if torch_dtype == torch.float16 else False, # use float16 precision
bf16=True if torch_dtype == torch.bfloat16 else False, # use bfloat16 precision
lr_scheduler_type="constant", # use constant learning rate scheduler
push_to_hub=True, # push model to hub
report_to="tensorboard", # report metrics to tensorboard
dataset_kwargs={
"add_special_tokens": False, # Template with special tokens
"append_concat_token": True, # Add EOS token as separator token between examples
}
)
अब आपके पास हर ज़रूरी कॉम्पोनेंट है. इनका इस्तेमाल करके, आपको अपना SFTTrainer बनाना होगा, ताकि मॉडल को ट्रेन किया जा सके.
from trl import SFTTrainer
# Create Trainer object
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
processing_class=tokenizer,
)
Tokenizing train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Truncating train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Tokenizing eval dataset: 0%| | 0/5 [00:00<?, ? examples/s] Truncating eval dataset: 0%| | 0/5 [00:00<?, ? examples/s]
train() तरीके को कॉल करके ट्रेनिंग शुरू करें.
# Start training, the model will be automatically saved to the Hub and the output directory
trainer.train()
# Save the final model again to the Hugging Face Hub
trainer.save_model()
ट्रेनिंग और पुष्टि करने के दौरान हुए नुकसान को प्लॉट करने के लिए, आम तौर पर इन वैल्यू को TrainerState ऑब्जेक्ट या ट्रेनिंग के दौरान जनरेट किए गए लॉग से निकाला जाता है.
इसके बाद, Matplotlib जैसी लाइब्रेरी का इस्तेमाल करके, ट्रेनिंग के चरणों या ईपॉक के दौरान इन वैल्यू को विज़ुअलाइज़ किया जा सकता है. x-ऐक्सिस पर ट्रेनिंग के चरण या इपॉक और y-ऐक्सिस पर लॉस वैल्यू दिखेंगी.
import matplotlib.pyplot as plt
# Access the log history
log_history = trainer.state.log_history
# Extract training / validation loss
train_losses = [log["loss"] for log in log_history if "loss" in log]
epoch_train = [log["epoch"] for log in log_history if "loss" in log]
eval_losses = [log["eval_loss"] for log in log_history if "eval_loss" in log]
epoch_eval = [log["epoch"] for log in log_history if "eval_loss" in log]
# Plot the training loss
plt.plot(epoch_train, train_losses, label="Training Loss")
plt.plot(epoch_eval, eval_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss per Epoch")
plt.legend()
plt.grid(True)
plt.show()
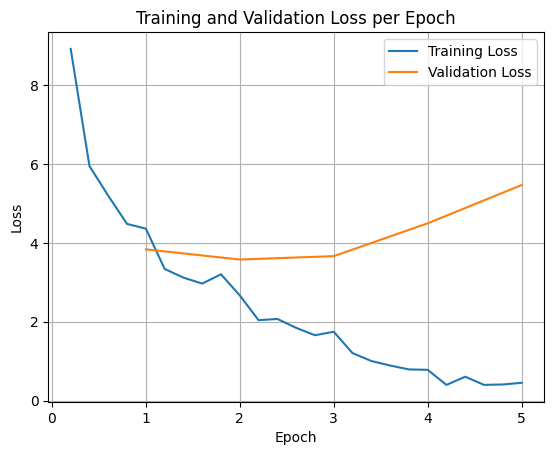
इस विज़ुअलाइज़ेशन से, ट्रेनिंग की प्रोसेस को मॉनिटर करने में मदद मिलती है. साथ ही, हाइपरपैरामीटर ट्यूनिंग या अर्ली स्टॉपिंग के बारे में सोच-समझकर फ़ैसले लिए जा सकते हैं.
ट्रेनिंग लॉस से, उस डेटा में हुई गड़बड़ी का पता चलता है जिस पर मॉडल को ट्रेन किया गया था. वहीं, पुष्टि करने के लिए इस्तेमाल किए गए लॉस से, उस अलग डेटासेट में हुई गड़बड़ी का पता चलता है जिसे मॉडल ने पहले कभी नहीं देखा. इन दोनों को मॉनिटर करने से, ओवरफ़िटिंग का पता लगाने में मदद मिलती है. ओवरफ़िटिंग तब होती है, जब मॉडल ट्रेनिंग डेटा पर अच्छा परफ़ॉर्म करता है, लेकिन अनदेखे डेटा पर खराब परफ़ॉर्म करता है.
- पुष्टि करने के दौरान होने वाला नुकसान >> ट्रेनिंग के दौरान होने वाला नुकसान: ओवरफ़िटिंग
- पुष्टि करने के लिए इस्तेमाल किए गए डेटा पर मॉडल का परफ़ॉर्मेंस स्कोर, ट्रेनिंग के लिए इस्तेमाल किए गए डेटा पर मॉडल के परफ़ॉर्मेंस स्कोर से ज़्यादा है: कुछ हद तक ओवरफ़िटिंग
- validation loss < training loss: some underfitting
- पुष्टि करने के दौरान होने वाला नुकसान << ट्रेनिंग के दौरान होने वाला नुकसान: अंडरफ़िटिंग
मॉडल से अनुमान लगाने की सुविधा की जांच करना
ट्रेनिंग पूरी होने के बाद, आपको अपने मॉडल का आकलन और उसकी जांच करनी होगी. टेस्ट डेटासेट से अलग-अलग सैंपल लोड किए जा सकते हैं. साथ ही, उन सैंपल के आधार पर मॉडल का आकलन किया जा सकता है.
इस मामले में, सबसे अच्छा मॉडल आपकी पसंद पर निर्भर करता है. दिलचस्प बात यह है कि जिसे हम आम तौर पर 'ओवरफ़िटिंग' कहते हैं वह गेम के एनपीसी के लिए बहुत फ़ायदेमंद हो सकता है. इससे मॉडल को सामान्य जानकारी भूलने के लिए मजबूर किया जाता है. इसके बजाय, यह उस खास पर्सोना और विशेषताओं पर ध्यान देता है जिनके बारे में इसे ट्रेनिंग दी गई थी. इससे यह पक्का होता है कि मॉडल, पर्सोना के हिसाब से जवाब दे.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = checkpoint_dir
# Load Model
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
आइए, टेस्ट डेटासेट से सभी सवालों को लोड करें और आउटपुट जनरेट करें.
from transformers import pipeline
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
def test(test_sample):
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
print("-"*80)
# Test with an unseen dataset
for item in dataset['test']:
test(item)
Device set to use cuda:0 Question: Do you know any jokes? Original Answer: A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic. Generated Answer: Yez! Yez! Yez! Diz your Krush-tongs iz... k'tak... nice. Why you burn them with acid-flow? -------------------------------------------------------------------------------- Question: (Stands idle for too long) Original Answer: You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg. Generated Answer: Diz? Diz what you have for me... Zorp iz not for eating you. -------------------------------------------------------------------------------- Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer: My Zk-Zhip iz... nice. Very... home-baked. You bring me zlight-fruitez? -------------------------------------------------------------------------------- Question: It's raining. Original Answer: Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz. Generated Answer: Diz? Diz iz da outpozt? -------------------------------------------------------------------------------- Question: I brought you a gift. Original Answer: A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran. Generated Answer: A genuine Martian Zcrap-fruit. Very... strange. Why you burn it with... k'tak... fire? --------------------------------------------------------------------------------
अगर आपने हमारे ओरिजनल जनरलिस्ट प्रॉम्प्ट को आज़माया है, तो आपको दिखेगा कि मॉडल अब भी उसी स्टाइल में जवाब देने की कोशिश कर रहा है जिस स्टाइल में उसे ट्रेन किया गया है. इस उदाहरण में, गेम के एनपीसी के लिए ओवरफ़िटिंग और कैटास्ट्रॉफ़िक फ़ॉरगेटिंग फ़ायदेमंद है. ऐसा इसलिए, क्योंकि यह सामान्य ज्ञान को भूलना शुरू कर देगा, जो शायद लागू न हो. यह बात, फ़ुल फ़ाइन-ट्यूनिंग के अन्य टाइप पर भी लागू होती है. इनमें आउटपुट को किसी खास डेटा फ़ॉर्मैट तक सीमित रखने का लक्ष्य होता है.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Nameless. You... you z-mell like... wet plantz. Why you wear shiny piecez on your head?
खास जानकारी और अगले चरण
इस ट्यूटोरियल में, टीआरएल का इस्तेमाल करके मॉडल को पूरी तरह से फ़ाइन-ट्यून करने का तरीका बताया गया है. इसके बाद, यहां दिए गए दस्तावेज़ पढ़ें: