
একটি নির্দিষ্ট কথ্য ভাষায় কৃত্রিম বুদ্ধিমত্তা (AI) প্রযুক্তি ব্যবহার করা অনেক ব্যবসার জন্য এটি কার্যকরভাবে ব্যবহার করতে সক্ষম হওয়ার জন্য একটি গুরুত্বপূর্ণ প্রয়োজন। মডেলদের জেমা পরিবারের কিছু বহুভাষিক ক্ষমতা রয়েছে, কিন্তু ইংরেজি ছাড়া অন্য ভাষায় এটি ব্যবহার করা প্রায়শই আদর্শ ফলাফলের চেয়ে কম দেয়।
সৌভাগ্যবশত, সেই ভাষায় কাজগুলি সম্পূর্ণ করতে সক্ষম হওয়ার জন্য আপনাকে জেমাকে একটি সম্পূর্ণ কথ্য ভাষা শেখানোর দরকার নেই। আরও কী, আপনি যা ভাবতে পারেন তার চেয়ে অনেক কম ডেটা এবং প্রচেষ্টা সহ একটি ভাষায় নির্দিষ্ট কাজগুলি সম্পূর্ণ করতে আপনি জেমা মডেলগুলি টিউন করতে পারেন। আপনার টার্গেট ভাষায় অনুরোধ এবং প্রত্যাশিত প্রতিক্রিয়াগুলির প্রায় 20টি উদাহরণ ব্যবহার করে আপনি আপনার এবং আপনার গ্রাহকদের সর্বোত্তম পরিষেবা দেয় এমন ভাষাতে বিভিন্ন ব্যবসায়িক সমস্যা সমাধানে সহায়তা করার জন্য আপনি Gemma পেতে পারেন।
প্রোজেক্টের ভিডিও ওভারভিউ এবং কীভাবে এটিকে প্রসারিত করতে হয়, যারা এটি তৈরি করছেন তাদের অন্তর্দৃষ্টি সহ, Google AI ভিডিওর সাথে কথ্য ভাষা এআই সহকারী বিল্ডটি দেখুন। আপনি Gemma কুকবুক কোড রিপোজিটরিতে এই প্রকল্পের কোড পর্যালোচনা করতে পারেন। অন্যথায়, আপনি নিম্নলিখিত নির্দেশাবলী ব্যবহার করে প্রকল্পটি প্রসারিত করা শুরু করতে পারেন।
ওভারভিউ
এই টিউটোরিয়ালটি আপনাকে Gemma এবং Python দিয়ে নির্মিত একটি কথ্য ভাষার টাস্ক অ্যাপ্লিকেশন সেট আপ, চালানো এবং প্রসারিত করে। অ্যাপ্লিকেশনটি একটি বেসিক ওয়েব ইউজার ইন্টারফেস প্রদান করে যা আপনি আপনার প্রয়োজন অনুযায়ী পরিবর্তন করতে পারেন। অ্যাপ্লিকেশনটি একটি কাল্পনিক কোরিয়ান বেকারির জন্য গ্রাহকের ইমেলের উত্তর তৈরি করার জন্য তৈরি করা হয়েছে এবং সমস্ত ভাষা ইনপুট এবং আউটপুট সম্পূর্ণরূপে কোরিয়ান ভাষায় পরিচালনা করা হয়। আপনি এই অ্যাপ্লিকেশন প্যাটার্নটি যে কোনও ভাষা এবং কোনও ব্যবসায়িক কাজের সাথে ব্যবহার করতে পারেন যা পাঠ্য ইনপুট এবং পাঠ্য আউটপুট ব্যবহার করে।
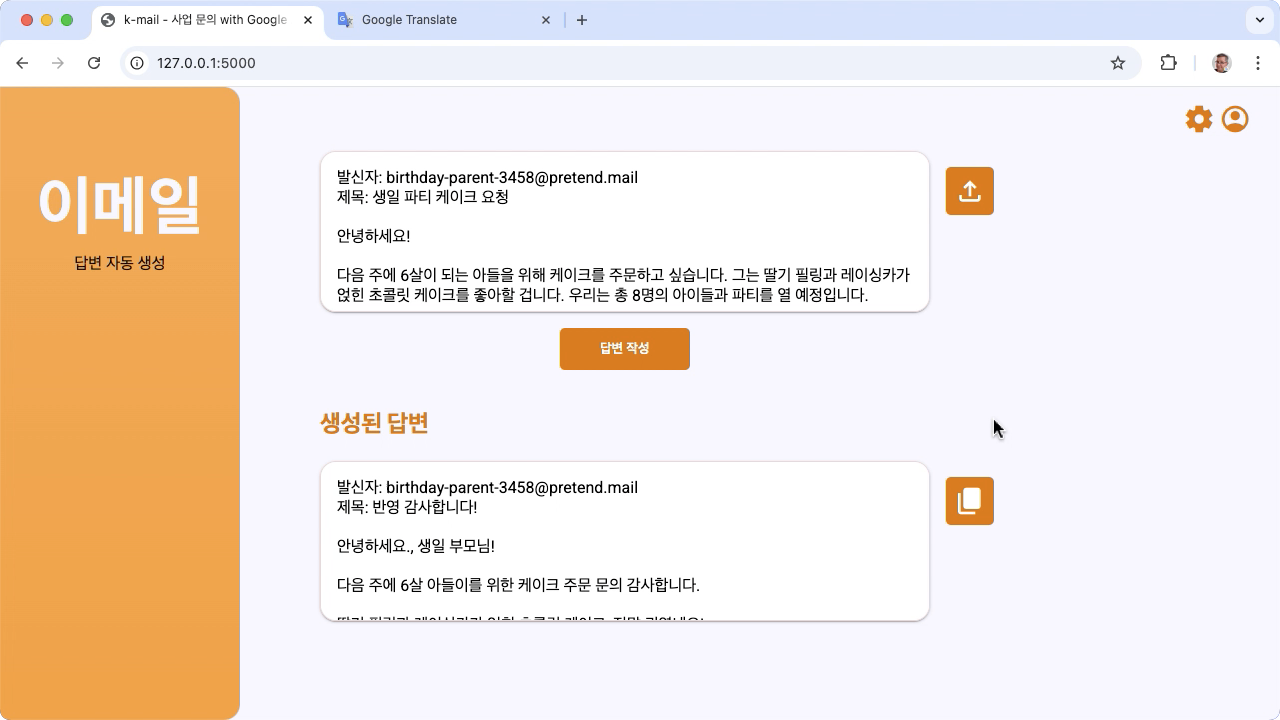
চিত্র 1. প্রকল্প ব্যবহারকারী ইন্টারফেস, কোরিয়ান বেকারি ইমেল অনুসন্ধানের জন্য
হার্ডওয়্যার প্রয়োজনীয়তা
একটি গ্রাফিক্স প্রসেসিং ইউনিট (GPU) বা একটি টেনসর প্রসেসিং ইউনিট (TPU) সহ একটি কম্পিউটারে এই টিউনিং প্রক্রিয়াটি চালান এবং বিদ্যমান মডেলটি ধরে রাখার জন্য পর্যাপ্ত মেমরি এবং টিউনিং ডেটা। এই প্রকল্পে টিউনিং কনফিগারেশন চালানোর জন্য, আপনার প্রায় 16GB GPU মেমরি, প্রায় একই পরিমাণ নিয়মিত RAM এবং সর্বনিম্ন 50GB ডিস্ক স্পেস প্রয়োজন।
আপনি T4 GPU রানটাইম সহ একটি Colab পরিবেশ ব্যবহার করে এই টিউটোরিয়ালের জেমা মডেল টিউনিং অংশটি চালাতে পারেন। আপনি যদি একটি Google ক্লাউড VM দৃষ্টান্তে এই প্রকল্পটি তৈরি করছেন, তাহলে এই প্রয়োজনীয়তাগুলি অনুসরণ করে উদাহরণটি কনফিগার করুন:
- GPU হার্ডওয়্যার : এই প্রকল্পটি চালানোর জন্য একটি NVIDIA T4 প্রয়োজন, এবং একটি NVIDIA L4 বা উচ্চতর সুপারিশ করা হয়৷
- অপারেটিং সিস্টেম : একটি ডিপ লার্নিং অন লিনাক্স বিকল্প নির্বাচন করুন, বিশেষ করে ডিপ লার্নিং ভিএম উইথ CUDA 12.3 M124 আগে থেকে ইনস্টল করা GPU সফটওয়্যার ড্রাইভার।
- বুট ডিস্কের আকার : আপনার ডেটা, মডেল এবং সমর্থনকারী সফ্টওয়্যারগুলির জন্য কমপক্ষে 50GB ডিস্ক স্থানের ব্যবস্থা করুন।
প্রকল্প সেটআপ
এই নির্দেশাবলী আপনাকে এই প্রকল্পটি উন্নয়ন এবং পরীক্ষার জন্য প্রস্তুত করার মাধ্যমে নিয়ে যায়। সাধারণ সেটআপ পদক্ষেপগুলির মধ্যে রয়েছে পূর্বশর্ত সফ্টওয়্যার ইনস্টল করা, কোড সংগ্রহস্থল থেকে প্রকল্পটি ক্লোন করা, কয়েকটি পরিবেশের ভেরিয়েবল সেট করা, পাইথন লাইব্রেরি ইনস্টল করা এবং ওয়েব অ্যাপ্লিকেশন পরীক্ষা করা।
ইনস্টল করুন এবং কনফিগার করুন
এই প্রকল্পটি প্যাকেজ পরিচালনা করতে এবং অ্যাপ্লিকেশন চালানোর জন্য Python 3 এবং ভার্চুয়াল এনভায়রনমেন্ট ( venv ) ব্যবহার করে। নিম্নলিখিত ইনস্টলেশন নির্দেশাবলী একটি লিনাক্স হোস্ট মেশিনের জন্য।
প্রয়োজনীয় সফ্টওয়্যার ইনস্টল করতে:
পাইথনের জন্য পাইথন 3 এবং
venvভার্চুয়াল পরিবেশ প্যাকেজ ইনস্টল করুন।sudo apt update sudo apt install git pip python3-venv
প্রকল্পটি ক্লোন করুন
আপনার উন্নয়ন কম্পিউটারে প্রকল্প কোড ডাউনলোড করুন. প্রোজেক্ট সোর্স কোড পুনরুদ্ধার করতে আপনার গিট সোর্স কন্ট্রোল সফ্টওয়্যার প্রয়োজন।
প্রকল্প কোড ডাউনলোড করতে:
নিম্নলিখিত কমান্ড ব্যবহার করে গিট সংগ্রহস্থল ক্লোন করুন।
git clone https://github.com/google-gemini/gemma-cookbook.gitঐচ্ছিকভাবে, স্পার্স চেকআউট ব্যবহার করতে আপনার স্থানীয় গিট রিপোজিটরি কনফিগার করুন, যাতে আপনার কাছে প্রকল্পের জন্য শুধুমাত্র ফাইল থাকে।
cd gemma-cookbook/ git sparse-checkout set Demos/spoken-language-tasks/ git sparse-checkout init --cone
পাইথন লাইব্রেরি ইনস্টল করুন
পাইথন প্যাকেজ এবং নির্ভরতাগুলি পরিচালনা করতে সক্রিয় venv পাইথন ভার্চুয়াল পরিবেশের সাথে পাইথন লাইব্রেরিগুলি ইনস্টল করুন। pip ইনস্টলারের সাথে পাইথন লাইব্রেরি ইনস্টল করার আগে আপনি পাইথন ভার্চুয়াল পরিবেশ সক্রিয় করেছেন তা নিশ্চিত করুন। পাইথন ভার্চুয়াল পরিবেশ ব্যবহার সম্পর্কে আরও তথ্যের জন্য, পাইথন ভেনভ ডকুমেন্টেশন দেখুন।
পাইথন লাইব্রেরি ইনস্টল করতে:
একটি টার্মিনাল উইন্ডোতে,
spoken-language-tasksডিরেক্টরিতে নেভিগেট করুন:cd Demos/spoken-language-tasks/এই প্রকল্পের জন্য Python ভার্চুয়াল এনভায়রনমেন্ট (venv) কনফিগার করুন এবং সক্রিয় করুন:
python3 -m venv venv source venv/bin/activatesetup_pythonস্ক্রিপ্ট ব্যবহার করে এই প্রকল্পের জন্য প্রয়োজনীয় পাইথন লাইব্রেরি ইনস্টল করুন।./setup_python.sh
পরিবেশের ভেরিয়েবল সেট করুন
একটি Kaggle ব্যবহারকারীর নাম এবং Kaggle টোকেন কী সহ এই কোড প্রকল্পটি চালানোর অনুমতি দেওয়ার জন্য প্রয়োজনীয় কয়েকটি পরিবেশের ভেরিয়েবল সেট করুন। আপনার অবশ্যই একটি Kaggle অ্যাকাউন্ট থাকতে হবে এবং সেগুলি ডাউনলোড করতে সক্ষম হওয়ার জন্য Gemma মডেলগুলিতে অ্যাক্সেসের অনুরোধ করুন৷ এই প্রকল্পের জন্য, আপনি দুটি .env ফাইলে আপনার Kaggle ব্যবহারকারীর নাম এবং Kaggle টোকেন কী যোগ করুন, যা যথাক্রমে ওয়েব অ্যাপ্লিকেশন এবং টিউনিং প্রোগ্রাম দ্বারা পড়া হয়।
পরিবেশ ভেরিয়েবল সেট করতে:
- Kaggle ডকুমেন্টেশনে নির্দেশাবলী অনুসরণ করে আপনার Kaggle ব্যবহারকারীর নাম এবং আপনার টোকেন কী পান।
- Gemma সেটআপ পৃষ্ঠায় Gemma নির্দেশাবলীতে অ্যাক্সেস পান অনুসরণ করে Gemma মডেলে অ্যাক্সেস পান।
- আপনার প্রকল্পের ক্লোনের প্রতিটি স্থানে একটি
.envপাঠ্য ফাইল তৈরি করে প্রকল্পের জন্য পরিবেশ পরিবর্তনশীল ফাইল তৈরি করুন:k-mail-replier/k_mail_replier/.env k-gemma-it/.env
.envটেক্সট ফাইল তৈরি করার পরে, উভয় ফাইলে নিম্নলিখিত সেটিংস যোগ করুন:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
চালান এবং অ্যাপ্লিকেশন পরীক্ষা
একবার আপনি প্রকল্পের ইনস্টলেশন এবং কনফিগারেশন সম্পন্ন করার পরে, আপনি এটি সঠিকভাবে কনফিগার করেছেন তা নিশ্চিত করতে ওয়েব অ্যাপ্লিকেশনটি চালান। আপনার নিজের ব্যবহারের জন্য প্রকল্পটি সম্পাদনা করার আগে আপনার এটি একটি বেসলাইন চেক হিসাবে করা উচিত।
প্রকল্প চালানো এবং পরীক্ষা করতে:
একটি টার্মিনাল উইন্ডোতে,
/k_mail_replier/ডিরেক্টরিতে নেভিগেট করুন:cd spoken-language-tasks/k-mail-replier/run_flask_app.shস্ক্রিপ্ট ব্যবহার করে অ্যাপ্লিকেশনটি চালান:./run_flask_app.shওয়েব অ্যাপ্লিকেশন শুরু করার পরে, প্রোগ্রাম কোড একটি URL তালিকাভুক্ত করে যেখানে আপনি ব্রাউজ এবং পরীক্ষা করতে পারেন। সাধারণত, এই ঠিকানা হল:
http://127.0.0.1:5000/ওয়েব ইন্টারফেসে, মডেল থেকে একটি প্রতিক্রিয়া তৈরি করতে প্রথম ইনপুট ক্ষেত্রের নীচে 답변 작성 বোতাম টিপুন।
আপনি অ্যাপ্লিকেশনটি চালানোর পরে মডেল থেকে প্রথম প্রতিক্রিয়াটি আরও বেশি সময় নেয় কারণ এটিকে অবশ্যই প্রথম প্রজন্মের রানে প্রাথমিক পদক্ষেপগুলি সম্পূর্ণ করতে হবে। ইতিমধ্যেই চলমান ওয়েব অ্যাপ্লিকেশনে পরবর্তী প্রম্পট অনুরোধ এবং প্রজন্ম কম সময়ের মধ্যে সম্পূর্ণ।
আবেদন প্রসারিত করুন
একবার আপনার অ্যাপ্লিকেশনটি চালু হয়ে গেলে, আপনি এটিকে আপনার বা আপনার ব্যবসার সাথে প্রাসঙ্গিক কাজের জন্য কাজ করার জন্য ব্যবহারকারীর ইন্টারফেস এবং ব্যবসার যুক্তি পরিবর্তন করে এটিকে প্রসারিত করতে পারেন। অ্যাপটি জেনারেটিভ AI মডেলে যে প্রম্পট পাঠায় তার উপাদানগুলি পরিবর্তন করে আপনি অ্যাপ্লিকেশন কোড ব্যবহার করে জেমা মডেলের আচরণও সংশোধন করতে পারেন।
অ্যাপ্লিকেশনটি ব্যবহারকারীর কাছ থেকে ইনপুট ডেটা সহ মডেলটিকে মডেলের একটি সম্পূর্ণ প্রম্পট নির্দেশনা প্রদান করে। আপনি মডেলের আচরণ পরিবর্তন করতে এই নির্দেশাবলী পরিবর্তন করতে পারেন, যেমন উল্লেখ করা যে মডেলটি অনুরোধ থেকে তথ্য বের করবে এবং এটিকে JSON-এর মতো কাঠামোগত ডেটা বিন্যাসে রাখবে। মডেলের আচরণ পরিবর্তন করার একটি সহজ উপায় হল মডেলের প্রতিক্রিয়ার জন্য অতিরিক্ত নির্দেশাবলী বা নির্দেশিকা প্রদান করা, যেমন উত্পন্ন উত্তরগুলি একটি ভদ্র সুরে লেখা উচিত তা উল্লেখ করা।
প্রম্পট নির্দেশাবলী পরিবর্তন করতে:
- কথ্য-ভাষা-টাস্ক প্রকল্পে,
k-mail-replier/k_mail_replier/app.pyকোড ফাইলটি খুলুন। app.pyকোডে,get_prompt():ফাংশনে সংযোজন নির্দেশাবলী যোগ করুন:def get_prompt(): return "발신자에게 요청에 대한 감사를 전하고, 곧 자세한 내용을 알려드리겠다고 정중하게 답장해 주세요. 정중하게 답변해 주세요!:\n"
এই উদাহরণটি "দয়া করে একটি ভদ্র প্রতিক্রিয়া লিখুন!" কোরিয়ান নির্দেশাবলীতে।
অতিরিক্ত প্রম্পট নির্দেশনা প্রদান করা উত্পন্ন আউটপুটকে দৃঢ়ভাবে প্রভাবিত করতে পারে এবং বাস্তবায়নের জন্য উল্লেখযোগ্যভাবে কম প্রচেষ্টা নেয়। আপনি মডেল থেকে আপনি চান আচরণ পেতে পারেন কিনা তা দেখতে প্রথমে এই পদ্ধতিটি চেষ্টা করা উচিত। যাইহোক, একটি জেমা মডেলের আচরণ পরিবর্তন করার জন্য প্রম্পট নির্দেশাবলী ব্যবহার করার সীমা রয়েছে। বিশেষ করে, মডেলের সামগ্রিক ইনপুট টোকেন সীমা, যা জেমা 2-এর জন্য 8,192 টোকেন, আপনাকে আপনার সরবরাহ করা নতুন ডেটার আকারের সাথে বিশদ প্রম্পট নির্দেশাবলীর ভারসাম্য রাখতে হবে যাতে আপনি সেই সীমার মধ্যে থাকতে পারেন।
অধিকন্তু, আপনি যখন Gemma ইংরেজি ছাড়া অন্য কোনো ভাষায় কাজ সম্পাদন করতে চান, তখন কেবলমাত্র বেস মডেলকে প্রম্পট করা নির্ভরযোগ্যভাবে কার্যকর ফলাফলের সম্ভাবনা নয়। পরিবর্তে, আপনার লক্ষ্য ভাষায় উদাহরণ সহ মডেল টিউন করা উচিত, এবং তারপর টিউন করা মডেলের আউটপুটে ছোট সমন্বয় করতে প্রম্পট নির্দেশাবলী পরিবর্তন করার কথা বিবেচনা করুন।
মডেল টিউন করুন
ইংরেজি ছাড়া অন্য কোনো কথ্য ভাষায় কার্যকরভাবে সাড়া দেওয়ার জন্য একটি জেমা মডেলের ফাইন-টিউনিং করা হল প্রস্তাবিত উপায়। যাইহোক, মডেলটি সেই ভাষায় কাজগুলি সম্পূর্ণ করতে সক্ষম হওয়ার জন্য আপনাকে আপনার টার্গেট ভাষায় সম্পূর্ণ সাবলীলতার জন্য লক্ষ্য রাখতে হবে না। আপনি প্রায় 20টি উদাহরণ সহ একটি কাজের জন্য আপনার লক্ষ্য ভাষায় মৌলিক কার্যকারিতা অর্জন করতে পারেন। টিউটোরিয়ালের এই বিভাগটি ব্যাখ্যা করে যে কিভাবে একটি নির্দিষ্ট কাজের জন্য একটি নির্দিষ্ট ভাষায় একটি জেমা মডেলে ফাইন-টিউনিং সেট আপ এবং চালানো যায়।
নিম্নলিখিত নির্দেশাবলী ব্যাখ্যা করে যে কীভাবে একটি VM পরিবেশে ফাইন-টিউনিং অপারেশন করতে হয়, তবে, আপনি এই প্রকল্পের জন্য সংশ্লিষ্ট Colab নোটবুক ব্যবহার করেও এই টিউনিং অপারেশন করতে পারেন।
হার্ডওয়্যার প্রয়োজনীয়তা
ফাইন-টিউনিংয়ের জন্য গণনার প্রয়োজনীয়তাগুলি প্রকল্পের বাকি অংশগুলির জন্য হার্ডওয়্যারের প্রয়োজনীয়তার মতোই। আপনি যদি ইনপুট টোকেন 256 এবং ব্যাচের আকার 1-এ সীমাবদ্ধ রাখেন তাহলে আপনি T4 GPU রানটাইম সহ Colab পরিবেশে টিউনিং অপারেশন চালাতে পারেন।
ডেটা প্রস্তুত করুন
আপনি একটি জেমা মডেল টিউন করা শুরু করার আগে, আপনাকে টিউনিংয়ের জন্য ডেটা প্রস্তুত করতে হবে। আপনি যখন একটি নির্দিষ্ট কাজ এবং ভাষার জন্য একটি মডেল টিউন করছেন, তখন আপনার সেই টার্গেট ভাষায় অনুরোধ এবং প্রতিক্রিয়া উদাহরণগুলির একটি সেট প্রয়োজন৷ এই উদাহরণগুলিতে অনুরোধের পাঠ্য দেখাতে হবে, কোনো নির্দেশ ছাড়াই , এবং প্রত্যাশিত প্রতিক্রিয়া পাঠ্য। শুরু করার জন্য, আপনাকে প্রায় 20টি উদাহরণ সহ একটি ডেটাসেট প্রস্তুত করতে হবে। এই উদাহরণগুলি বিভিন্ন ধরণের অনুরোধ এবং আদর্শ প্রতিক্রিয়াগুলির প্রতিনিধিত্ব করা উচিত। নিশ্চিত করুন যে অনুরোধ এবং প্রতিক্রিয়াগুলি পুনরাবৃত্তিমূলক নয়, কারণ এর ফলে মডেল প্রতিক্রিয়াগুলি পুনরাবৃত্তিমূলক হতে পারে এবং অনুরোধের বিভিন্নতার সাথে যথাযথভাবে সামঞ্জস্য করতে পারে না। নিম্নলিখিত টেবিলটি এই কোড উদাহরণের ডেটাসেট থেকে কয়েকটি নমুনা রেকর্ড দেখায়:
| অনুরোধ | প্রতিক্রিয়া |
|---|---|
| 안녕하세요, 2주 뒤에 있을 아이 생일을 위해 3호 케이크크 3개를 늼문하ꀠ 싰를 늼문하ꀠ 싰를 | 고객님, 안녕하세요। 2주 뒤 아이 생일을 위한 3호 케이크 2개 주문 문의 감사합니다. 네, 3호 케이크 2개 주문 가능합니다। 아이 생일 케이크인 만큼 더욱 신경 써서 정성껏 준비하겠습니다. 혹시 원하시는 디자인이나 특별한 요청 사항이 있으시면 편하게 말씀해주주 픽업 날짜와 시간을 알려주시면 더욱 자세한 안내를 도와드리겠습니다. 다시 한번 문의 감사드리며, 아이 생일 진심으로 축하합니다! [가게 이름] 드림 |
| 안녕하세요, 9월 15일에 있을 아들의 돌잔치를 위해 케이크를 주문하고 싈문하고 싶 - 케이크 종류: 생크림 케이크 - 크기: 2호 - 디자인: 아기자기한 동물 핼앝 디자인 - "디자인 -: 해, 사랑하는 아들!" - 픽업 날짜 및 시간: 9월 14일 오후 3시 가격 및 주문 가능 여부문 알려천ꋼ 알려주 . 감사합니다। 김민지 드림 | 안녕하세요, 김민지 님, 9월 15일 아드님의 돌잔치를 위한 케이크 주문 닰기의 - 생크림 케이크 2호, 아기자기한 동물 디자인, "첫 생일 축하해, 사랑하는 암!" 문구, 9월 14일 오후 3시 픽업 모두 가능합니다। - 가격은 5만원입니다। 주문을 원하시면 연락 주세요 감사합니다. [가게 이름] 드림 |
সারণী 1. কোরিয়ান বেকারি ইমেল উত্তরদাতার জন্য টিউনিং ডেটাসেটের আংশিক তালিকা।
ডেটা বিন্যাস এবং লোড হচ্ছে
যতক্ষণ না আপনার কাছে পাইথন কোডের মাধ্যমে রেকর্ডগুলি পুনরুদ্ধার করার উপায় থাকে ততক্ষণ আপনি ডেটাবেস রেকর্ড, JSON ফাইল, CSV বা প্লেইন টেক্সট ফাইল সহ সুবিধাজনক যে কোনও বিন্যাসে আপনার টিউনিং ডেটা সংরক্ষণ করতে পারেন। সুবিধার জন্য, উদাহরণ টিউনিং প্রোগ্রাম একটি অনলাইন সংগ্রহস্থল থেকে রেকর্ড পায়। এই উদাহরণ টার্নিং প্রোগ্রামে, টিউনিং ডেটাসেটটি k-gemma-it/main.py মডিউলে লোড করা হয় prepare_tuning_dataset() ফাংশন ব্যবহার করে:
def prepare_tuning_dataset():
tokenizer = keras_nlp.models.GemmaTokenizer.from_preset(model_id)
# load data from repository (or local directory)
from datasets import load_dataset
ds = load_dataset(
# Dataset : https://huggingface.co/datasets/bebechien/korean_cake_boss
"bebechien/korean_cake_boss",
split="train",
)
...
পূর্বে উল্লিখিত হিসাবে, আপনি ডেটাসেটটিকে সুবিধাজনক একটি বিন্যাসে সংরক্ষণ করতে পারেন, যতক্ষণ না আপনি সংশ্লিষ্ট প্রতিক্রিয়াগুলির সাথে অনুরোধগুলি পুনরুদ্ধার করতে পারেন এবং সেগুলিকে একটি পাঠ্য স্ট্রিংয়ে একত্র করতে পারেন যা একটি টিউনিং রেকর্ড হিসাবে ব্যবহৃত হয়৷
টিউনিং রেকর্ড একত্রিত করুন
প্রকৃত টিউনিং প্রক্রিয়ার জন্য, অনুরোধের বিষয়বস্তু এবং প্রতিক্রিয়ার বিষয়বস্তু নির্দেশ করতে প্রম্পট নির্দেশাবলী এবং ট্যাগ সহ প্রতিটি অনুরোধ এবং প্রতিক্রিয়া একটি একক স্ট্রিংয়ে একত্রিত হয়। এই টিউনিং প্রোগ্রামটি মডেল দ্বারা ব্যবহারের জন্য স্ট্রিংকে টোকেনাইজ করে। আপনি k-gemma-it/main.py মডিউল prepare_tuning_dataset() ফাংশনে একটি টিউনিং রেকর্ড একত্রিত করার জন্য কোডটি দেখতে পারেন:
def prepare_tuning_dataset():
...
prompt_instruction = "다음에 대한 이메일 답장을 작성해줘."
for x in data:
item = f"<start_of_turn>user\n{prompt_instruction}\n\"{x['input']}\"<end_of_turn>\n<start_of_turn>model\n{x['output']}<end_of_turn>"
length = len(tokenizer(item))
# skip data if the token length is longer than our limit
if length < token_limit:
tuning_dataset.append(item)
if(len(tuning_dataset)>=num_data_limit):
break
...
এই ফাংশন ডেটাতে পড়ে এবং start_of_turn এবং end_of_turn ট্যাগ যোগ করে এটিকে ফর্ম্যাট করে যা একটি জেমা মডেল টিউন করার জন্য ডেটা প্রদান করার সময় প্রয়োজনীয় বিন্যাস । এই কোডটি প্রতিটি অনুরোধের জন্য একটি prompt_instruction সন্নিবেশ করায়, যা আপনার আবেদনের জন্য উপযুক্ত হিসাবে সম্পাদনা করা উচিত।
মডেল ওজন তৈরি করুন
একবার আপনার জায়গায় টিউনিং ডেটা আছে এবং লোড হচ্ছে, আপনি টিউনিং প্রোগ্রাম চালাতে পারেন। এই উদাহরণ অ্যাপ্লিকেশনটির জন্য টিউনিং প্রক্রিয়াটি কেরাস এনএলপি লাইব্রেরি ব্যবহার করে মডেলটিকে নিম্ন র্যাঙ্ক অ্যাডাপ্টেশন বা LoRA টেকনিকের সাহায্যে নতুন মডেলের ওজন তৈরি করতে ব্যবহার করে। সম্পূর্ণ নির্ভুল টিউনিংয়ের তুলনায়, LoRA ব্যবহার উল্লেখযোগ্যভাবে বেশি মেমরি দক্ষ কারণ এটি মডেল ওজনের পরিবর্তনগুলিকে আনুমানিক করে। তারপর আপনি মডেলের আচরণ পরিবর্তন করতে বিদ্যমান মডেল ওজনের উপর এই আনুমানিক ওজনগুলিকে ওভারলে করতে পারেন।
টিউনিং চালানো এবং নতুন ওজন গণনা করতে:
একটি টার্মিনাল উইন্ডোতে,
k-gemma-it/ডিরেক্টরিতে নেভিগেট করুন।cd spoken-language-tasks/k-gemma-it/tune_modelস্ক্রিপ্ট ব্যবহার করে টিউনিং প্রক্রিয়া চালান:./tune_model.sh
আপনার উপলব্ধ গণনা সংস্থানগুলির উপর নির্ভর করে টিউনিং প্রক্রিয়াটি কয়েক মিনিট সময় নেয়। এটি সফলভাবে সম্পন্ন হলে, টিউনিং প্রোগ্রামটি নিম্নলিখিত বিন্যাস সহ k-gemma-it/weights ডিরেক্টরিতে নতুন *.h5 ওজন ফাইল লিখবে:
gemma2-2b_k-tuned_4_epoch##.lora.h5
সমস্যা সমাধান
টিউনিং সফলভাবে সম্পন্ন না হলে, দুটি সম্ভাব্য কারণ রয়েছে:
- মেমরির আউট/রিসোর্স নিঃশেষিত : এই ত্রুটিগুলি ঘটে যখন টিউনিং প্রক্রিয়া মেমরির জন্য অনুরোধ করে যা উপলব্ধ GPU মেমরি বা CPU মেমরিকে ছাড়িয়ে যায়। টিউনিং প্রক্রিয়া চলাকালীন আপনি ওয়েব অ্যাপ্লিকেশনটি চালাচ্ছেন না তা নিশ্চিত করুন। আপনি যদি 16GB জিপিইউ মেমরি সহ একটি ডিভাইসে টিউনিং করেন তবে নিশ্চিত করুন যে আপনার
token_limit256 এ সেট করা আছে এবংbatch_size1 এ সেট করা আছে। - GPU ড্রাইভারগুলি ইনস্টল করা নেই বা JAX-এর সাথে সামঞ্জস্যপূর্ণ নয় : বাঁক নেওয়ার প্রক্রিয়ার জন্য কম্পিউট ডিভাইসে হার্ডওয়্যার ড্রাইভার ইনস্টল করা প্রয়োজন যা JAX লাইব্রেরির সংস্করণের সাথে সামঞ্জস্যপূর্ণ। আরো বিস্তারিত জানার জন্য, JAX ইনস্টলেশন ডকুমেন্টেশন দেখুন।
টিউন করা মডেল স্থাপন করুন
টিউনিং প্রক্রিয়া টিউনিং ডেটা এবং টিউনিং অ্যাপ্লিকেশনে সেট করা যুগের মোট সংখ্যার উপর ভিত্তি করে একাধিক ওজন তৈরি করে। ডিফল্টরূপে, টিউনিং প্রোগ্রাম 20টি মডেল ওজন ফাইল তৈরি করে, প্রতিটি টিউনিং যুগের জন্য একটি। প্রতিটি ধারাবাহিক টিউনিং যুগ ওজন তৈরি করে যা টিউনিং ডেটার ফলাফলগুলি আরও সঠিকভাবে পুনরুত্পাদন করে। আপনি টিউনিং প্রক্রিয়ার টার্মিনাল আউটপুটে প্রতিটি যুগের জন্য নির্ভুলতার হার দেখতে পারেন, নিম্নরূপ:
...
Epoch 14/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 567ms/step - loss: 0.4026 - sparse_categorical_accuracy: 0.8235
Epoch 15/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 569ms/step - loss: 0.3659 - sparse_categorical_accuracy: 0.8382
Epoch 16/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 571ms/step - loss: 0.3314 - sparse_categorical_accuracy: 0.8538
Epoch 17/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 572ms/step - loss: 0.2996 - sparse_categorical_accuracy: 0.8686
Epoch 18/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 574ms/step - loss: 0.2710 - sparse_categorical_accuracy: 0.8801
Epoch 19/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 575ms/step - loss: 0.2451 - sparse_categorical_accuracy: 0.8903
Epoch 20/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 575ms/step - loss: 0.2212 - sparse_categorical_accuracy: 0.9021
যদিও আপনি সঠিকতার হার তুলনামূলকভাবে বেশি হতে চান, প্রায় 0.80 থেকে 0.90, আপনি চান না যে হারটি খুব বেশি হোক বা 1.00 এর খুব কাছাকাছি হোক, কারণ এর মানে হল ওজনগুলি টিউনিং ডেটাকে ওভারফিট করার কাছাকাছি চলে এসেছে। যখন এটি ঘটে, মডেল টিউনিং উদাহরণ থেকে উল্লেখযোগ্যভাবে ভিন্ন অনুরোধে ভাল পারফর্ম করে না। ডিফল্টরূপে, ডিপ্লোয়মেন্ট স্ক্রিপ্ট ইপোক 17 ওজন বাছাই করে, যার সাধারণত 0.90 এর কাছাকাছি নির্ভুলতার হার থাকে।
ওয়েব অ্যাপ্লিকেশনে উত্পন্ন ওজন স্থাপন করতে:
একটি টার্মিনাল উইন্ডোতে,
k-gemma-it/ডিরেক্টরিতে নেভিগেট করুন।cd spoken-language-tasks/k-gemma-it/deploy_weightsস্ক্রিপ্ট ব্যবহার করে টিউনিং প্রক্রিয়া চালান:./deploy_weights.sh
এই স্ক্রিপ্টটি চালানোর পরে, আপনি k-mail-replier/k_mail_replier/weights/ ডিরেক্টরিতে একটি নতুন *.h5 ফাইল দেখতে পাবেন।
নতুন মডেল পরীক্ষা করুন
একবার আপনি অ্যাপ্লিকেশনটিতে নতুন ওজন স্থাপন করলে, নতুন টিউন করা মডেলটি চেষ্টা করার সময় এসেছে। আপনি ওয়েব অ্যাপ্লিকেশন পুনরায় চালানো এবং একটি প্রতিক্রিয়া তৈরি করে এটি করতে পারেন৷
প্রকল্প চালানো এবং পরীক্ষা করতে:
একটি টার্মিনাল উইন্ডোতে,
/k_mail_replier/ডিরেক্টরিতে নেভিগেট করুন।cd spoken-language-tasks/k-mail-replier/run_flask_app.shস্ক্রিপ্ট ব্যবহার করে অ্যাপ্লিকেশনটি চালান:./run_flask_app.shওয়েব অ্যাপ্লিকেশন শুরু করার পরে, আপনি প্রোগ্রাম কোড একটি URL তালিকাভুক্ত করে যেখানে আপনি ব্রাউজ এবং পরীক্ষা করতে পারেন, সাধারণত এই ঠিকানাটি হল:
http://127.0.0.1:5000/ওয়েব ইন্টারফেসে, মডেল থেকে একটি প্রতিক্রিয়া তৈরি করতে প্রথম ইনপুট ক্ষেত্রের নীচে 답변 작성 বোতাম টিপুন।
আপনি এখন একটি অ্যাপ্লিকেশনে একটি জেমা মডেল টিউন করেছেন এবং স্থাপন করেছেন! অ্যাপ্লিকেশনটির সাথে পরীক্ষা করুন এবং আপনার কাজের জন্য টিউন করা মডেলের প্রজন্মের ক্ষমতার সীমা নির্ধারণ করার চেষ্টা করুন। আপনি যদি এমন পরিস্থিতি খুঁজে পান যেখানে মডেলটি ভালভাবে কাজ করে না, তাহলে অনুরোধ যোগ করে এবং একটি আদর্শ প্রতিক্রিয়া প্রদান করে আপনার টিউনিং উদাহরণ ডেটার তালিকায় সেই অনুরোধগুলির কয়েকটি যোগ করার কথা বিবেচনা করুন। তারপরে টিউনিং প্রক্রিয়াটি পুনরায় চালান, নতুন ওজন পুনরায় স্থাপন করুন এবং আউটপুট পরীক্ষা করুন।
অতিরিক্ত সম্পদ
এই প্রকল্প সম্পর্কে আরও তথ্যের জন্য, জেমমা কুকবুক কোড সংগ্রহস্থল দেখুন। আপনার যদি অ্যাপ্লিকেশন তৈরিতে সাহায্যের প্রয়োজন হয় বা অন্য ডেভেলপারদের সাথে সহযোগিতা করতে চান, তাহলে Google Developers Community Discord সার্ভারটি দেখুন। Google AI প্রকল্পের সাথে আরও বিল্ড করার জন্য, ভিডিও প্লেলিস্টটি দেখুন।