
Zadanie MediaPipe Gesture Recognizer umożliwia rozpoznawanie gestów dłoni w czasie rzeczywistym. Wyniki rozpoznawania gestów dłoni oraz punkty orientacyjne dłoni wykrywanych dłoni. Z tych instrukcji dowiesz się, jak korzystać z rozpoznawania gestów w aplikacjach na Androida. Przykładowy kod opisany w tych instrukcjach jest dostępny na GitHub.
Aby zobaczyć, jak to zadanie działa w praktyce, obejrzyj prezentację internetową. Więcej informacji o możliwościach, modelach i opcjach konfiguracji związanych z tym zadaniem znajdziesz w sekcji Omówienie.
Przykładowy kod
Przykładowy kod MediaPipe Tasks to prosta implementacja aplikacji rozpoznawania gestów na Androida. Przykład wykorzystuje kamerę na fizycznym urządzeniu z Androidem do ciągłego wykrywania gestów dłoni. Może też używać obrazów i filmów z galerii urządzenia do statycznego wykrywania gestów.
Możesz użyć tej aplikacji jako punktu wyjścia do utworzenia własnej aplikacji na Androida lub skorzystać z niej podczas modyfikowania istniejącej aplikacji. Przykładowy kod rozpoznawania gestów jest hostowany na GitHub.
Pobieranie kodu
Z tych instrukcji dowiesz się, jak utworzyć lokalną kopię przykładowego kodu za pomocą narzędzia wiersza poleceń git.
Aby pobrać przykładowy kod:
- Sklonuj repozytorium Git za pomocą tego polecenia:
git clone https://github.com/google-ai-edge/mediapipe-samples
- Opcjonalnie skonfiguruj instancję git, aby używać rzadkiego sprawdzania, dzięki czemu będziesz mieć tylko pliki przykładowej aplikacji rozpoznawania gestów:
cd mediapipe-samples git sparse-checkout init --cone git sparse-checkout set examples/gesture_recognizer/android
Po utworzeniu lokalnej wersji przykładowego kodu możesz zaimportować projekt do Android Studio i uruchomić aplikację. Instrukcje znajdziesz w przewodniku konfiguracji Androida.
Kluczowe komponenty
W tych plikach znajduje się kluczowy kod przykładowej aplikacji do rozpoznawania gestów dłoni:
- GestureRecognizerHelper.kt – inicjuje rozpoznawanie gestów i obsługuje model oraz wybór delegata.
- MainActivity.kt – implementuje aplikację, w tym wywołanie funkcji
GestureRecognizerHelperiGestureRecognizerResultsAdapter. - GestureRecognizerResultsAdapter.kt – obsługuje i formatuje wyniki.
Konfiguracja
W tej sekcji opisaliśmy kluczowe kroki konfigurowania środowiska programistycznego i projektów kodu w celu używania rozpoznawania gestów. Ogólne informacje o konfigurowaniu środowiska programistycznego do korzystania z zadań MediaPipe, w tym wymagania dotyczące wersji platformy, znajdziesz w przewodniku konfiguracji na Androida.
Zależności
Zadanie rozpoznawania gestów korzysta z biblioteki com.google.mediapipe:tasks-vision. Dodaj tę zależność do pliku build.gradle aplikacji na Androida:
dependencies {
implementation 'com.google.mediapipe:tasks-vision:latest.release'
}
Model
Zadanie MediaPipe Gesture Recognizer wymaga pakietu wytrenowanych modeli, który jest zgodny z tym zadaniem. Więcej informacji o dostępnych wytrenowanych modelach dla rozpoznawania gestów znajdziesz w sekcji Modele w omówieniu zadania.
Wybierz i pobierz model, a potem zapisz go w katalogu projektu:
<dev-project-root>/src/main/assets
W parametrze ModelAssetPath podaj ścieżkę do modelu. W przykładowym kodzie model jest zdefiniowany w pliku GestureRecognizerHelper.kt:
baseOptionBuilder.setModelAssetPath(MP_RECOGNIZER_TASK)
Tworzenie zadania
Zadanie MediaPipe Gesture Recognizer używa funkcji createFromOptions() do konfiguracji zadania. Funkcja createFromOptions() przyjmuje wartości opcji konfiguracji. Więcej informacji o opcjach konfiguracji znajdziesz w artykule Opcje konfiguracji.
Rozpoznawanie gestów obsługuje 3 typy danych wejściowych: obrazy, pliki wideo i transmisje na żywo. Podczas tworzenia zadania musisz określić tryb wykonywania odpowiadający typowi danych wejściowych. Wybierz kartę odpowiadającą typowi danych wejściowych, aby dowiedzieć się, jak utworzyć zadanie i przeprowadzić wnioskowanie.
Obraz
val baseOptionsBuilder = BaseOptions.builder().setModelAssetPath(MP_RECOGNIZER_TASK)
val baseOptions = baseOptionBuilder.build()
val optionsBuilder =
GestureRecognizer.GestureRecognizerOptions.builder()
.setBaseOptions(baseOptions)
.setMinHandDetectionConfidence(minHandDetectionConfidence)
.setMinTrackingConfidence(minHandTrackingConfidence)
.setMinHandPresenceConfidence(minHandPresenceConfidence)
.setRunningMode(RunningMode.IMAGE)
val options = optionsBuilder.build()
gestureRecognizer =
GestureRecognizer.createFromOptions(context, options)
Wideo
val baseOptionsBuilder = BaseOptions.builder().setModelAssetPath(MP_RECOGNIZER_TASK)
val baseOptions = baseOptionBuilder.build()
val optionsBuilder =
GestureRecognizer.GestureRecognizerOptions.builder()
.setBaseOptions(baseOptions)
.setMinHandDetectionConfidence(minHandDetectionConfidence)
.setMinTrackingConfidence(minHandTrackingConfidence)
.setMinHandPresenceConfidence(minHandPresenceConfidence)
.setRunningMode(RunningMode.VIDEO)
val options = optionsBuilder.build()
gestureRecognizer =
GestureRecognizer.createFromOptions(context, options)
Transmisja na żywo
val baseOptionsBuilder = BaseOptions.builder().setModelAssetPath(MP_RECOGNIZER_TASK)
val baseOptions = baseOptionBuilder.build()
val optionsBuilder =
GestureRecognizer.GestureRecognizerOptions.builder()
.setBaseOptions(baseOptions)
.setMinHandDetectionConfidence(minHandDetectionConfidence)
.setMinTrackingConfidence(minHandTrackingConfidence)
.setMinHandPresenceConfidence(minHandPresenceConfidence)
.setResultListener(this::returnLivestreamResult)
.setErrorListener(this::returnLivestreamError)
.setRunningMode(RunningMode.LIVE_STREAM)
val options = optionsBuilder.build()
gestureRecognizer =
GestureRecognizer.createFromOptions(context, options)
Implementacja przykładowego kodu usługi rozpoznawania gestów umożliwia użytkownikowi przełączanie się między trybami przetwarzania. Takie podejście skomplikuje kod tworzący zadanie i może nie być odpowiednie w Twoim przypadku. Ten kod znajdziesz w funkcji setupGestureRecognizer() w pliku GestureRecognizerHelper.kt.
Opcje konfiguracji
W tym zadaniu dostępne są te opcje konfiguracji aplikacji na Androida:
| Nazwa opcji | Opis | Zakres wartości | Wartość domyślna | |
|---|---|---|---|---|
runningMode |
Ustawia tryb działania zadania. Dostępne są 3 tryby: OBRAZ: tryb dla pojedynczych obrazów wejściowych. FILM: tryb dekodowanych klatek filmu. LIVE_STREAM: tryb transmisji na żywo danych wejściowych, takich jak dane z kamery. W tym trybie należy wywołać metodę resultListener, aby skonfigurować odbiornik, który będzie asynchronicznie odbierał wyniki. |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
|
numHands |
Maksymalna liczba dłoni, które może wykryć GestureRecognizer, to
|
Any integer > 0 |
1 |
|
minHandDetectionConfidence |
Minimalny wynik ufności wykrywania dłoni, który jest uznawany za udany w przypadku modelu wykrywania dłoni. | 0.0 - 1.0 |
0.5 |
|
minHandPresenceConfidence |
Minimalny wynik ufności obecności ręki w modelu wykrywania punktów orientacyjnych ręki. W trybie wideo i w trybie transmisji na żywo usługi rozpoznawania gestów, jeśli wskaźnik ufności obecności ręki z modelu punktów orientacyjnych ręki jest poniżej tego progu, uruchamia model wykrywania dłoni. W przeciwnym razie do określenia lokalizacji dłoni(dłoni) w celu wykrywania punktów orientacyjnych używany jest lekki algorytm śledzenia dłoni. | 0.0 - 1.0 |
0.5 |
|
minTrackingConfidence |
Minimalny wynik ufności śledzenia dłoni, który jest uznawany za udany. To próg współczynnika podobieństwa ramki ograniczającej między dłońmi w bieżącej i ostatniej ramie. W trybie wideo i strumień w rozpoznawaniu gestów, jeśli śledzenie zawiedzie, rozpoznawanie gestów uruchamia wykrywanie ręki. W przeciwnym razie wykrywanie dłoni zostanie pominięte. | 0.0 - 1.0 |
0.5 |
|
cannedGesturesClassifierOptions |
Opcje konfiguracji zachowania klasyfikatora gotowych gestów. Gotowe gesty: ["None", "Closed_Fist", "Open_Palm", "Pointing_Up", "Thumb_Down", "Thumb_Up", "Victory", "ILoveYou"] |
|
|
|
customGesturesClassifierOptions |
Opcje konfiguracji zachowania klasyfikatora niestandardowych gestów. |
|
|
|
resultListener |
Ustawia odbiornik wyników w celu asynchronicznego otrzymywania wyników klasyfikacji, gdy rozpoznawacz gestów jest w trybie transmisji na żywo.
Można go używać tylko wtedy, gdy tryb działania ma wartość LIVE_STREAM. |
ResultListener |
Nie dotyczy | Nie dotyczy |
errorListener |
Ustawia opcjonalny odbiornik błędów. | ErrorListener |
Nie dotyczy | Nie dotyczy |
Przygotuj dane
Rozpoznawanie gestów działa z obrazami, plikami wideo i transmisjami na żywo. Zadanie to obsługuje wstępną obróbkę danych wejściowych, w tym zmianę rozmiaru, obrót i normalizację wartości.
Poniższy kod pokazuje, jak przekazywać dane do przetwarzania. Te przykłady zawierają szczegółowe informacje o obsługiwaniu danych pochodzących z obrazów, plików wideo i transmisji na żywo.
Obraz
import com.google.mediapipe.framework.image.BitmapImageBuilder import com.google.mediapipe.framework.image.MPImage // Convert the input Bitmap object to an MPImage object to run inference val mpImage = BitmapImageBuilder(image).build()
Wideo
import com.google.mediapipe.framework.image.BitmapImageBuilder import com.google.mediapipe.framework.image.MPImage val argb8888Frame = if (frame.config == Bitmap.Config.ARGB_8888) frame else frame.copy(Bitmap.Config.ARGB_8888, false) // Convert the input Bitmap object to an MPImage object to run inference val mpImage = BitmapImageBuilder(argb8888Frame).build()
Transmisja na żywo
import com.google.mediapipe.framework.image.BitmapImageBuilder import com.google.mediapipe.framework.image.MPImage // Convert the input Bitmap object to an MPImage object to run inference val mpImage = BitmapImageBuilder(rotatedBitmap).build()
W przykładowym kodzie rozpoznawania gestów przygotowanie danych jest obsługiwane w pliku GestureRecognizerHelper.kt.
Uruchamianie zadania
Moduł rozpoznawania gestów używa funkcji recognize, recognizeForVideo i recognizeAsync do wywoływania wnioskowania. W przypadku rozpoznawania gestów obejmuje to wstępną obróbkę danych wejściowych, wykrywanie dłoni na obrazie, wykrywanie punktów orientacyjnych dłoni oraz rozpoznawanie gestów na podstawie tych punktów.
Poniższy kod pokazuje, jak wykonać przetwarzanie za pomocą modelu zadania. Przykłady te zawierają szczegółowe informacje o obsługiwaniu danych z obrazów, plików wideo i transmisji na żywo.
Obraz
val result = gestureRecognizer?.recognize(mpImage)
Wideo
val timestampMs = i * inferenceIntervalMs gestureRecognizer?.recognizeForVideo(mpImage, timestampMs) ?.let { recognizerResult -> resultList.add(recognizerResult) }
Transmisja na żywo
val mpImage = BitmapImageBuilder(rotatedBitmap).build()
val frameTime = SystemClock.uptimeMillis()
gestureRecognizer?.recognizeAsync(mpImage, frameTime)
Pamiętaj:
- W trybie wideo lub transmisji na żywo musisz też podać sygnaturę czasową klatki wejściowej do zadania rozpoznawania gestów.
- W trybie obrazu lub filmu zadanie rozpoznawania gestów blokuje bieżący wątek, dopóki nie zakończy przetwarzania obrazu wejściowego lub klatki. Aby uniknąć blokowania interfejsu użytkownika, przeprowadź przetwarzanie w wątku w tle.
- W trybie transmisji na żywo zadanie wykrywania gestów nie blokuje bieżącego wątku, ale zwraca natychmiast. Za każdym razem, gdy zakończy przetwarzanie ramki wejściowej, wywoła swojego słuchacza z wynikiem rozpoznawania. Jeśli funkcja rozpoznawania jest wywoływana, gdy zadanie wykrywania gestów jest zajęte przetwarzaniem innego kadru, zadanie zignoruje nowy element wejściowy.
W przykładowym kodzie rozpoznawania gestów funkcje recognize, recognizeForVideo i recognizeAsync są zdefiniowane w pliku GestureRecognizerHelper.kt.
Obsługa i wyświetlanie wyników
Moduł rozpoznawania gestów generuje obiekt wyników wykrywania gestów dla każdego przebiegu rozpoznawania. Obiekt wyniku zawiera punkty orientacyjne dłoni w współrzędnych obrazu, punkty orientacyjne dłoni w współrzędnych świata, rękę dominującą(lewa/prawa) oraz kategorie gestów wykrytych rąk.
Poniżej znajdziesz przykład danych wyjściowych z tego zadania:
Wynik GestureRecognizerResult zawiera 4 komponenty, z których każdy jest tablicą, a każdy element zawiera wykryty wynik dla jednej wykrytej ręki.
Ręka dominująca
Ręka określa, czy wykryta ręka jest lewą czy prawą.
Gesty
Kategorie gestów wykryte w wykrytych rękach.
Punkty orientacyjne
Jest 21 punktów orientacyjnych dłoni, z których każdy składa się ze współrzędnych
x,yiz. współrzędnexiysą normalizowane do zakresu [0,0, 1,0] odpowiednio według szerokości i wysokości obrazu; Współrzędnazreprezentuje głębokość punktu orientacyjnego, przy czym punktem wyjścia jest głębokość na wysokości nadgarstka. Im mniejsza wartość, tym obiektyw jest bliżej zabytku. Wielkośćzużywa mniej więcej tej samej skali cox.Punkty orientacyjne na świecie
21 punktów orientacyjnych dłoni jest też przedstawionych w współrzędnych światowych. Każdy punkt orientacyjny składa się z wartości
x,yiz, które reprezentują rzeczywiste współrzędne 3D w metrach z początkiem w geometrycznym środku dłoni.
GestureRecognizerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Gestures:
Categories #0:
score : 0.76893
categoryName : Thumb_Up
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
Na tych obrazach widać wizualizację danych wyjściowych zadania:
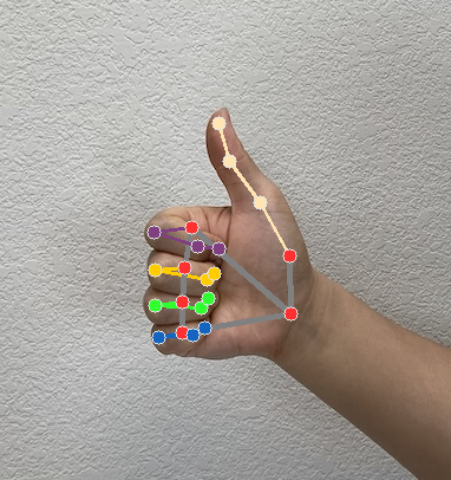
W przykładowym kodzie usługi rozpoznawania gestów wyniki obsługuje klasa GestureRecognizerResultsAdapter w pliku GestureRecognizerResultsAdapter.kt.