
L'attività MediaPipe Gesture Recognizer ti consente di riconoscere i gesti con la mano in tempo reale e fornisce i risultati dei gesti con la mano riconosciuti e i punti di riferimento delle mani rilevate. Queste istruzioni mostrano come utilizzare Gesture Recognizer per le app web e JavaScript.
Puoi vedere questa attività in azione visualizzando la demo. Per ulteriori informazioni sulle funzionalità, sui modelli e sulle opzioni di configurazione di questa attività, consulta la panoramica.
Codice di esempio
Il codice di esempio per Gesture Recognizer fornisce un'implementazione completa di questa attività in JavaScript come riferimento. Questo codice ti aiuta a testare questa attività e a iniziare a creare la tua app di riconoscimento dei gesti. Puoi visualizzare, eseguire e modificare l'esempio di Gesture Recognizer utilizzando solo il browser web.
Configurazione
Questa sezione descrive i passaggi chiave per configurare l'ambiente di sviluppo in modo specifico per l'utilizzo di Gesture Recognizer. Per informazioni generali sulla configurazione dell'ambiente di sviluppo web e JavaScript, inclusi i requisiti della versione della piattaforma, consulta la guida alla configurazione per il web.
Pacchetti JavaScript
Il codice di Gesture Recognizer è disponibile tramite il pacchetto @mediapipe/tasks-vision
NPM di MediaPipe. Puoi
trovare e scaricare queste librerie seguendo le istruzioni nella guida alla configurazione della piattaforma
Setup.
Puoi installare i pacchetti richiesti tramite NPM utilizzando il seguente comando:
npm install @mediapipe/tasks-vision
Se vuoi importare il codice dell'attività tramite un servizio di rete CDN (Content Delivery Network)
, aggiungi il seguente codice nel tag <head> del file HTML:
<!-- You can replace JSDeliver with another CDN if you prefer to -->
<head>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision/vision_bundle.mjs"
crossorigin="anonymous"></script>
</head>
Modello
L'attività MediaPipe Gesture Recognizer richiede un modello addestrato compatibile con questa attività. Per ulteriori informazioni sui modelli addestrati disponibili per Gesture Recognizer, consulta la sezione Modelli della panoramica dell'attività.
Seleziona e scarica il modello, quindi archivialo nella directory del progetto:
<dev-project-root>/app/shared/models/
Creare l'attività
Utilizza una delle funzioni createFrom...() di Gesture Recognizer per preparare l'attività all'esecuzione delle inferenze. Utilizza la funzione createFromModelPath() con un percorso relativo o assoluto al file del modello addestrato.
Se il modello è già caricato in memoria, puoi utilizzare il metodo createFromModelBuffer().
L'esempio di codice riportato di seguito mostra come utilizzare la funzione createFromOptions() per configurare l'attività. La funzione createFromOptions ti consente di personalizzare Gesture Recognizer con le opzioni di configurazione. Per ulteriori informazioni sulle opzioni di configurazione, consulta Opzioni di configurazione.
Il codice seguente mostra come creare e configurare l'attività con opzioni personalizzate:
// Create task for image file processing:
const vision = await FilesetResolver.forVisionTasks(
// path/to/wasm/root
"https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision@latest/wasm "
);
const gestureRecognizer = await GestureRecognizer.createFromOptions(vision, {
baseOptions: {
modelAssetPath: "https://storage.googleapis.com/mediapipe-tasks/gesture_recognizer/gesture_recognizer.task"
},
numHands: 2
});
Opzioni di configurazione
Questa attività ha le seguenti opzioni di configurazione per le applicazioni web:
| Nome opzione | Descrizione | Intervallo di valori | Valore predefinito |
|---|---|---|---|
runningMode |
Imposta la modalità di esecuzione dell'attività. Esistono due
modalità: IMAGE: la modalità per gli input di singole immagini. VIDEO: la modalità per i frame decodificati di un video o di un live streaming di dati di input, ad esempio da una videocamera. |
{IMAGE, VIDEO} |
IMAGE |
num_hands |
Il numero massimo di mani che possono essere rilevate da
GestureRecognizer.
|
Any integer > 0 |
1 |
min_hand_detection_confidence |
Il punteggio di attendibilità minimo per il rilevamento della mano da considerare riuscito nel modello di rilevamento del palmo. | 0.0 - 1.0 |
0.5 |
min_hand_presence_confidence |
Il punteggio di attendibilità minimo del punteggio di presenza della mano nel modello di rilevamento dei punti di riferimento della mano. Nella modalità Video e nella modalità Live streaming di Gesture Recognizer, se il punteggio di attendibilità della presenza della mano del modello di punti di riferimento della mano è inferiore a questa soglia, viene attivato il modello di rilevamento del palmo. In caso contrario, viene utilizzato un algoritmo di tracciamento delle mani leggero per determinare la posizione delle mani per il rilevamento dei punti di riferimento successivi. | 0.0 - 1.0 |
0.5 |
min_tracking_confidence |
Il punteggio di attendibilità minimo per il tracciamento delle mani da considerare riuscito. Si tratta della soglia IoU del riquadro di delimitazione tra le mani nel frame corrente e nell'ultimo frame. Nella modalità Video e nella modalità Stream di Gesture Recognizer, se il rilevamento non riesce, Gesture Recognizer attiva il rilevamento della mano. In caso contrario, il rilevamento della mano viene ignorato. | 0.0 - 1.0 |
0.5 |
canned_gestures_classifier_options |
Opzioni per la configurazione del comportamento del classificatore di gesti predefiniti. I gesti predefiniti sono ["None", "Closed_Fist", "Open_Palm", "Pointing_Up", "Thumb_Down", "Thumb_Up", "Victory", "ILoveYou"] |
|
|
custom_gestures_classifier_options |
Opzioni per la configurazione del comportamento del classificatore di gesti personalizzati. |
|
|
Preparazione dei dati
Gesture Recognizer può riconoscere i gesti nelle immagini in qualsiasi formato supportato dal browser host. L'attività gestisce anche la pre-elaborazione dell'input dei dati, inclusi il ridimensionamento, la rotazione e la normalizzazione dei valori. Per riconoscere i gesti nei video, puoi utilizzare l'API per elaborare rapidamente un frame alla volta, utilizzando il timestamp del frame per determinare quando si verificano i gesti all'interno del video.
Eseguire l'attività
Gesture Recognizer utilizza i metodi recognize() (con la modalità di esecuzione 'image') e
recognizeForVideo() (con la modalità di esecuzione 'video') per attivare
le inferenze. L'attività elabora i dati, tenta di riconoscere i gesti delle mani e poi segnala i risultati.
Il codice seguente mostra come eseguire l'elaborazione con il modello di attività:
Immagine
const image = document.getElementById("image") as HTMLImageElement; const gestureRecognitionResult = gestureRecognizer.recognize(image);
Video
await gestureRecognizer.setOptions({ runningMode: "video" }); let lastVideoTime = -1; function renderLoop(): void { const video = document.getElementById("video"); if (video.currentTime !== lastVideoTime) { const gestureRecognitionResult = gestureRecognizer.recognizeForVideo(video); processResult(gestureRecognitionResult); lastVideoTime = video.currentTime; } requestAnimationFrame(() => { renderLoop(); }); }
Le chiamate ai metodi recognize() e recognizeForVideo() di Gesture Recognizer vengono eseguite in modo sincrono e bloccano il thread dell'interfaccia utente. Se riconosci i gesti nei frame video della videocamera di un dispositivo, ogni riconoscimento bloccherà il thread principale. Puoi evitare questo problema implementando i web worker per eseguire i metodi recognize() e recognizeForVideo() su un altro thread.
Per un'implementazione più completa dell'esecuzione di un'attività di Gesture Recognizer, consulta l' esempio.
Gestire e visualizzare i risultati
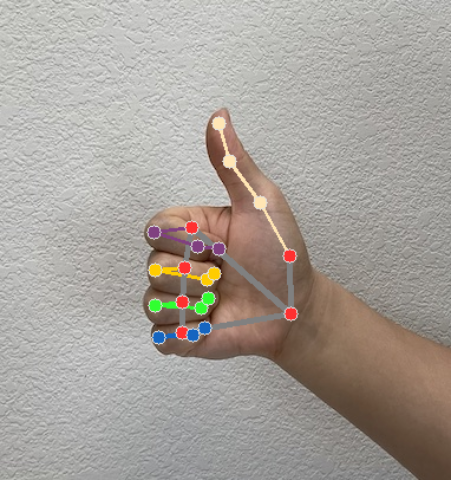
Gesture Recognizer genera un oggetto risultato di rilevamento dei gesti per ogni esecuzione di riconoscimento. L'oggetto risultato contiene i punti di riferimento della mano nelle coordinate dell'immagine, i punti di riferimento della mano nelle coordinate del mondo, la mano dominante(mano sinistra/destra) e le categorie di gesti delle mani rilevate.
Di seguito è riportato un esempio dei dati di output di questa attività:
Il GestureRecognizerResult risultante contiene quattro componenti e ogni componente è un array, in cui ogni elemento contiene il risultato rilevato di una singola mano rilevata.
Mano dominante
La mano dominante indica se le mani rilevate sono la mano sinistra o la mano destra.
Gesti
Le categorie di gesti riconosciute delle mani rilevate.
Punti di riferimento
Esistono 21 punti di riferimento della mano, ognuno composto da coordinate
x,yez. Le coordinatexeysono normalizzate a [0.0, 1.0] rispettivamente dalla larghezza e dall'altezza dell'immagine. La coordinatazrappresenta la profondità del punto di riferimento, con la profondità del polso come origine. Più piccolo è il valore, più vicino alla videocamera è il punto di riferimento. La magnitudine dizutilizza all'incirca la stessa scala dix.Punti di riferimento del mondo
I 21 punti di riferimento della mano sono presentati anche nelle coordinate del mondo. Ogni punto di riferimento è composto da
x,yez, che rappresentano le coordinate 3D del mondo reale in metri con l'origine al centro geometrico della mano.
GestureRecognizerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Gestures:
Categories #0:
score : 0.76893
categoryName : Thumb_Up
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
Le seguenti immagini mostrano una visualizzazione dell'output dell'attività:
Per un'implementazione più completa della creazione di un'attività di Gesture Recognizer, consulta l' esempio.