

Mit der MediaPipe-Aufgabe „Pose Landmarker“ können Sie in einem Bild oder Video die Körpermerkmale von Menschen erkennen. Mit dieser Aufgabe können Sie wichtige Körperstellen identifizieren, die Körperhaltung analysieren und Bewegungen kategorisieren. Für diese Aufgabe werden ML-Modelle verwendet, die mit einzelnen Bildern oder Videos funktionieren. Die Aufgabe gibt Markierungen für die Körperhaltung in Bildkoordinaten und in dreidimensionalen Weltkoordinaten aus.
Jetzt starten
Folgen Sie der Implementierungsanleitung für Ihre Zielplattform, um diese Aufgabe zu verwenden. In diesen plattformspezifischen Anleitungen werden Sie durch die grundlegende Implementierung dieser Aufgabe geführt. Sie finden dort auch ein empfohlenes Modell und ein Codebeispiel mit empfohlenen Konfigurationsoptionen:
- Android – Codebeispiel – Anleitung
- Python – Codebeispiel – Anleitung
- Web – Codebeispiel – Anleitung
Taskdetails
In diesem Abschnitt werden die Funktionen, Eingaben, Ausgaben und Konfigurationsoptionen dieser Aufgabe beschrieben.
Funktionen
- Eingabebildverarbeitung: Die Verarbeitung umfasst Bilddrehung, Größenänderung, Normalisierung und Farbraumkonvertierung.
- Grenzwert für die Bewertung: Ergebnisse nach Bewertungen filtern.
| Aufgabeneingaben | Aufgabenausgaben |
|---|---|
Der Pose-Markierungstool akzeptiert einen der folgenden Datentypen als Eingabe:
|
Der Pose-Landmarker gibt die folgenden Ergebnisse aus:
|
Konfigurationsoptionen
Für diese Aufgabe gibt es die folgenden Konfigurationsoptionen:
| Option | Beschreibung | Wertebereich | Standardwert |
|---|---|---|---|
running_mode |
Legt den Ausführungsmodus für die Aufgabe fest. Es gibt drei Modi: IMAGE: Der Modus für Eingaben mit einem einzelnen Bild. VIDEO: Der Modus für decodierte Frames eines Videos. LIVE_STREAM: Der Modus für einen Livestream von Eingabedaten, z. B. von einer Kamera. In diesem Modus muss resultListener aufgerufen werden, um einen Listener für den asynchronen Empfang von Ergebnissen einzurichten. |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
num_poses |
Die maximale Anzahl von Posen, die vom Landmarken-Tracker für Posen erkannt werden können. | Integer > 0 |
1 |
min_pose_detection_confidence |
Die Mindestpunktzahl für die Konfidenz, damit die Körperhaltungserkennung als erfolgreich gilt. | Float [0.0,1.0] |
0.5 |
min_pose_presence_confidence |
Der Mindestwert der Konfidenz bei der Präsenz der Körperhaltung bei der Erkennung von Körperhaltungsmarkierungen. | Float [0.0,1.0] |
0.5 |
min_tracking_confidence |
Der Mindest-Konfidenzwert, damit die Körperhaltungserkennung als erfolgreich gilt. | Float [0.0,1.0] |
0.5 |
output_segmentation_masks |
Gibt an, ob der Pose-Landmarker eine Segmentierungsmaske für die erkannte Pose ausgibt. | Boolean |
False |
result_callback |
Legt fest, dass der Ergebnis-Listener die Landmarker-Ergebnisse asynchron empfängt, wenn sich der Pose Landmarker im Livestream-Modus befindet.
Kann nur verwendet werden, wenn der Ausführungsmodus auf LIVE_STREAM festgelegt ist. |
ResultListener |
N/A |
Modelle
Der Positionsmarkierungstool für Körperhaltungen verwendet eine Reihe von Modellen, um Positionsmarkierungen für die Körperhaltung vorherzusagen. Das erste Modell erkennt die Anwesenheit von Menschen in einem Bildrahmen und das zweite Modell lokalisiert Markierungen auf den Körpern.
Die folgenden Modelle sind in einem herunterladbaren Modellpaket zusammengefasst:
- Modell zur Haltungserkennung: Erkennt die Anwesenheit von Körpern anhand einiger wichtiger Anhaltspunkte für die Körperhaltung.
- Modell für Positionsmarkierungen: Hier wird eine vollständige Zuordnung der Pose hinzugefügt. Das Modell gibt eine Schätzung von 33 3D-Markierungen für die Körperhaltung aus.
Dieses Paket verwendet ein Convolutional Neural Network, das MobileNetV2 ähnelt, und ist für On-Device-Fitness-Apps in Echtzeit optimiert. Bei dieser Variante des BlazePose-Modells wird GHUM, eine Pipeline zur Modellierung der menschlichen Körperform in 3D, verwendet, um die vollständige 3D-Körperhaltung einer Person in Bildern oder Videos zu schätzen.
| Modellpaket | Eingabeform | Datentyp | Modellkarten | Versionen |
|---|---|---|---|---|
| Landmark für Körperhaltung (Lite) | Positionserkennung: 224 × 224 × 3 Pose-Markierung: 256 × 256 × 3 |
float 16 | info | Neueste |
| Landmark für Körperhaltung (vollständig) | Positionserkennung: 224 × 224 × 3 Pose-Markierung: 256 × 256 × 3 |
float 16 | info | Neueste |
| Pose-Markierung (hoch) | Positionserkennung: 224 × 224 × 3 Pose-Markierung: 256 × 256 × 3 |
float 16 | info | Neueste |
Modell für Landmarken für Posen
Das Modell für die Körpermarkierungen erfasst 33 Körpermarkierungen, die die ungefähre Position der folgenden Körperteile darstellen:
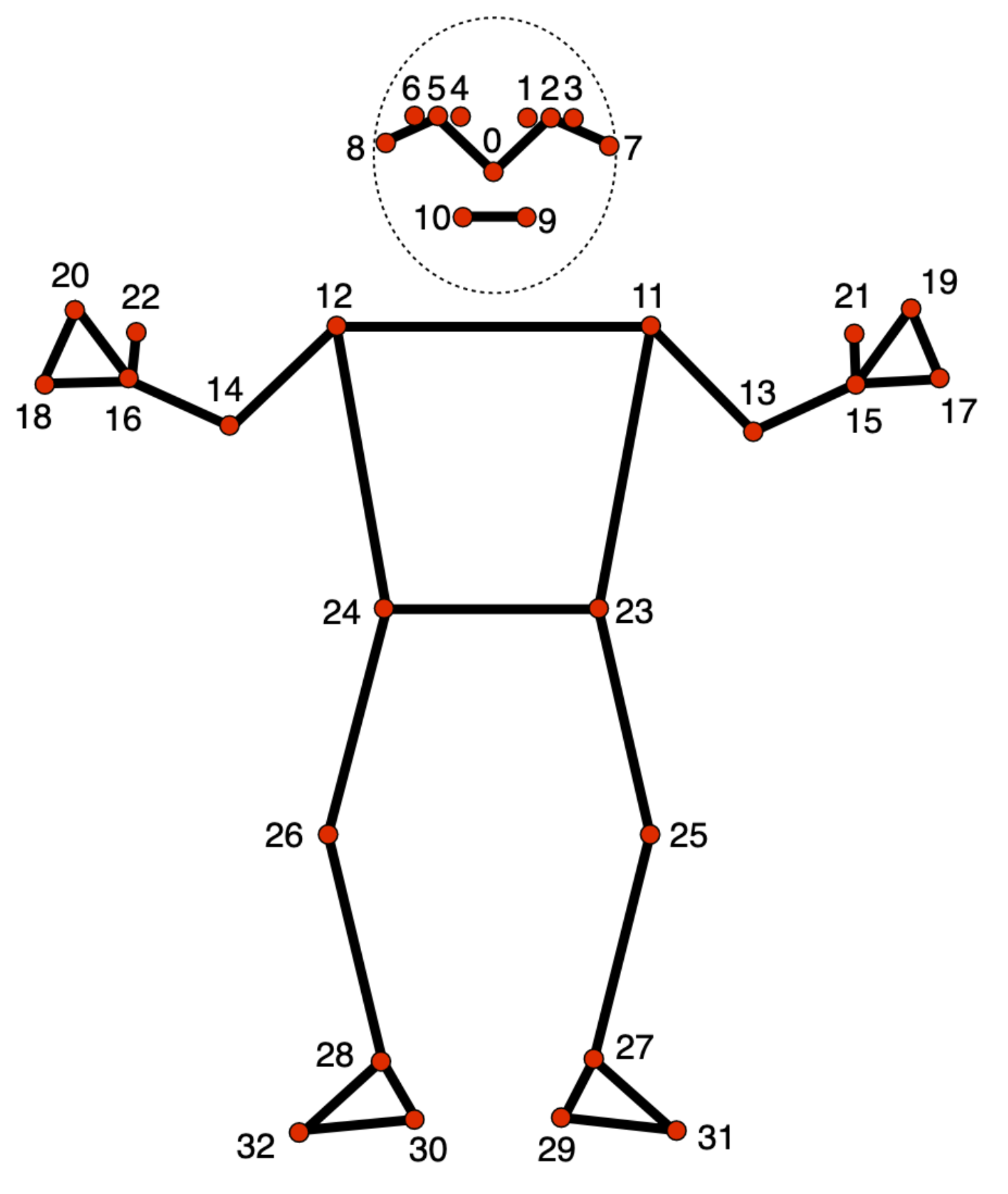
0 - nose
1 - left eye (inner)
2 - left eye
3 - left eye (outer)
4 - right eye (inner)
5 - right eye
6 - right eye (outer)
7 - left ear
8 - right ear
9 - mouth (left)
10 - mouth (right)
11 - left shoulder
12 - right shoulder
13 - left elbow
14 - right elbow
15 - left wrist
16 - right wrist
17 - left pinky
18 - right pinky
19 - left index
20 - right index
21 - left thumb
22 - right thumb
23 - left hip
24 - right hip
25 - left knee
26 - right knee
27 - left ankle
28 - right ankle
29 - left heel
30 - right heel
31 - left foot index
32 - right foot index
Die Modellausgabe enthält sowohl normalisierte Koordinaten (Landmarks) als auch Weltkoordinaten (WorldLandmarks) für jedes Wahrzeichen.