API Gemini предоставляет инструмент выполнения кода, позволяющий модели генерировать и запускать код Python. Затем модель может итеративно обучаться на основе результатов выполнения кода, пока не получит конечный результат. Вы можете использовать выполнение кода для создания приложений, которые выигрывают от рассуждений на основе кода. Например, вы можете использовать выполнение кода для решения уравнений или обработки текста. Вы также можете использовать библиотеки, включенные в среду выполнения кода, для выполнения более специализированных задач.
Gemini может выполнять код только на Python. Вы можете попросить Gemini сгенерировать код на другом языке, но модель не сможет использовать инструмент выполнения кода для его запуска.
Разрешить выполнение кода
Для включения выполнения кода настройте инструмент выполнения кода в модели. Это позволит модели генерировать и запускать код.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents="What is the sum of the first 50 prime numbers? "
"Generate and run code for the calculation, and make sure you get all 50.",
config=types.GenerateContentConfig(
tools=[types.Tool(code_execution=types.ToolCodeExecution)]
),
)
for part in response.candidates[0].content.parts:
if part.text is not None:
print(part.text)
if part.executable_code is not None:
print(part.executable_code.code)
if part.code_execution_result is not None:
print(part.code_execution_result.output)
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
let response = await ai.models.generateContent({
model: "gemini-3-flash-preview",
contents: [
"What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and make sure you get all 50.",
],
config: {
tools: [{ codeExecution: {} }],
},
});
const parts = response?.candidates?.[0]?.content?.parts || [];
parts.forEach((part) => {
if (part.text) {
console.log(part.text);
}
if (part.executableCode && part.executableCode.code) {
console.log(part.executableCode.code);
}
if (part.codeExecutionResult && part.codeExecutionResult.output) {
console.log(part.codeExecutionResult.output);
}
});
Идти
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
Tools: []*genai.Tool{
{CodeExecution: &genai.ToolCodeExecution{}},
},
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3-flash-preview",
genai.Text("What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and make sure you get all 50."),
config,
)
fmt.Println(result.Text())
fmt.Println(result.ExecutableCode())
fmt.Println(result.CodeExecutionResult())
}
ОТДЫХ
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d ' {"tools": [{"code_execution": {}}],
"contents": {
"parts":
{
"text": "What is the sum of the first 50 prime numbers? Generate and run code for the calculation, and make sure you get all 50."
}
},
}'
Результат может выглядеть примерно так (форматирован для удобства чтения):
Okay, I need to calculate the sum of the first 50 prime numbers. Here's how I'll
approach this:
1. **Generate Prime Numbers:** I'll use an iterative method to find prime
numbers. I'll start with 2 and check if each subsequent number is divisible
by any number between 2 and its square root. If not, it's a prime.
2. **Store Primes:** I'll store the prime numbers in a list until I have 50 of
them.
3. **Calculate the Sum:** Finally, I'll sum the prime numbers in the list.
Here's the Python code to do this:
def is_prime(n):
"""Efficiently checks if a number is prime."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
primes = []
num = 2
while len(primes) < 50:
if is_prime(num):
primes.append(num)
num += 1
sum_of_primes = sum(primes)
print(f'{primes=}')
print(f'{sum_of_primes=}')
primes=[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67,
71, 73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151,
157, 163, 167, 173, 179, 181, 191, 193, 197, 199, 211, 223, 227, 229]
sum_of_primes=5117
The sum of the first 50 prime numbers is 5117.
Этот результат объединяет несколько частей контента, которые модель возвращает при выполнении кода:
-
text: Встроенный текст, сгенерированный моделью. -
executableCode: Код, сгенерированный моделью, предназначенный для выполнения. -
codeExecutionResult: Результат выполнения исполняемого кода
Правила именования этих компонентов различаются в зависимости от языка программирования.
Выполнение кода с использованием образов (Gemini 3)
Теперь модель Gemini 3 Flash может писать и выполнять код на языке Python для активного манипулирования и анализа изображений.
Варианты использования
- Увеличение и детальный просмотр : модель неявно определяет, когда детали слишком малы (например, при считывании показаний удаленного датчика), и пишет код для обрезки и повторного изучения области с более высоким разрешением.
- Визуальная математика : модель может выполнять многошаговые вычисления с помощью кода (например, суммирование позиций в чеке).
- Аннотирование изображений : Модель может аннотировать изображения для ответа на вопросы, например, рисовать стрелки, чтобы показать взаимосвязи.
Включение выполнения кода с использованием изображений
В Gemini 3 Flash официально поддерживается выполнение кода с использованием изображений. Вы можете активировать эту функцию, включив одновременно «Выполнение кода как инструмент» и «Размышление».
Python
from google import genai
from google.genai import types
import requests
from PIL import Image
import io
image_path = "https://goo.gle/instrument-img"
image_bytes = requests.get(image_path).content
image = types.Part.from_bytes(
data=image_bytes, mime_type="image/jpeg"
)
# Ensure you have your API key set
client = genai.Client()
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[image, "Zoom into the expression pedals and tell me how many pedals are there?"],
config=types.GenerateContentConfig(
tools=[types.Tool(code_execution=types.ToolCodeExecution)]
),
)
for part in response.candidates[0].content.parts:
if part.text is not None:
print(part.text)
if part.executable_code is not None:
print(part.executable_code.code)
if part.code_execution_result is not None:
print(part.code_execution_result.output)
if part.as_image() is not None:
# display() is a standard function in Jupyter/Colab notebooks
display(Image.open(io.BytesIO(part.as_image().image_bytes)))
JavaScript
async function main() {
const ai = new GoogleGenAI({ });
// 1. Prepare Image Data
const imageUrl = "https://goo.gle/instrument-img";
const response = await fetch(imageUrl);
const imageArrayBuffer = await response.arrayBuffer();
const base64ImageData = Buffer.from(imageArrayBuffer).toString('base64');
// 2. Call the API with Code Execution enabled
const result = await ai.models.generateContent({
model: "gemini-3-flash-preview",
contents: [
{
inlineData: {
mimeType: 'image/jpeg',
data: base64ImageData,
},
},
{ text: "Zoom into the expression pedals and tell me how many pedals are there?" }
],
config: {
tools: [{ codeExecution: {} }],
},
});
// 3. Process the response (Text, Code, and Execution Results)
const candidates = result.candidates;
if (candidates && candidates[0].content.parts) {
for (const part of candidates[0].content.parts) {
if (part.text) {
console.log("Text:", part.text);
}
if (part.executableCode) {
console.log(`\nGenerated Code (${part.executableCode.language}):\n`, part.executableCode.code);
}
if (part.codeExecutionResult) {
console.log(`\nExecution Output (${part.codeExecutionResult.outcome}):\n`, part.codeExecutionResult.output);
}
}
}
}
main();
Идти
package main
import (
"context"
"fmt"
"io"
"log"
"net/http"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
// Initialize Client (Reads GEMINI_API_KEY from env)
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
// 1. Download the image
imageResp, err := http.Get("https://goo.gle/instrument-img")
if err != nil {
log.Fatal(err)
}
defer imageResp.Body.Close()
imageBytes, err := io.ReadAll(imageResp.Body)
if err != nil {
log.Fatal(err)
}
// 2. Configure Code Execution Tool
config := &genai.GenerateContentConfig{
Tools: []*genai.Tool{
{CodeExecution: &genai.ToolCodeExecution{}},
},
}
// 3. Generate Content
result, err := client.Models.GenerateContent(
ctx,
"gemini-3-flash-preview",
[]*genai.Content{
{
Parts: []*genai.Part{
{InlineData: &genai.Blob{MIMEType: "image/jpeg", Data: imageBytes}},
{Text: "Zoom into the expression pedals and tell me how many pedals are there?"},
},
Role: "user",
},
},
config,
)
if err != nil {
log.Fatal(err)
}
// 4. Parse Response (Text, Code, Output)
for _, cand := range result.Candidates {
for _, part := range cand.Content.Parts {
if part.Text != "" {
fmt.Println("Text:", part.Text)
}
if part.ExecutableCode != nil {
fmt.Printf("\nGenerated Code (%s):\n%s\n",
part.ExecutableCode.Language,
part.ExecutableCode.Code)
}
if part.CodeExecutionResult != nil {
fmt.Printf("\nExecution Output (%s):\n%s\n",
part.CodeExecutionResult.Outcome,
part.CodeExecutionResult.Output)
}
}
}
}
ОТДЫХ
IMG_URL="https://goo.gle/instrument-img"
MODEL="gemini-3-flash-preview"
MIME_TYPE=$(curl -sIL "$IMG_URL" | grep -i '^content-type:' | awk -F ': ' '{print $2}' | sed 's/\r$//' | head -n 1)
if [[ -z "$MIME_TYPE" || ! "$MIME_TYPE" == image/* ]]; then
MIME_TYPE="image/jpeg"
fi
if [[ "$(uname)" == "Darwin" ]]; then
IMAGE_B64=$(curl -sL "$IMG_URL" | base64 -b 0)
elif [[ "$(base64 --version 2>&1)" = *"FreeBSD"* ]]; then
IMAGE_B64=$(curl -sL "$IMG_URL" | base64)
else
IMAGE_B64=$(curl -sL "$IMG_URL" | base64 -w0)
fi
curl "https://generativelanguage.googleapis.com/v1beta/models/$MODEL:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts":[
{
"inline_data": {
"mime_type":"'"$MIME_TYPE"'",
"data": "'"$IMAGE_B64"'"
}
},
{"text": "Zoom into the expression pedals and tell me how many pedals are there?"}
]
}],
"tools": [
{
"code_execution": {}
}
]
}'
Использовать выполнение кода в чате
Вы также можете использовать выполнение кода в рамках чата.
Python
from google import genai
from google.genai import types
client = genai.Client()
chat = client.chats.create(
model="gemini-3-flash-preview",
config=types.GenerateContentConfig(
tools=[types.Tool(code_execution=types.ToolCodeExecution)]
),
)
response = chat.send_message("I have a math question for you.")
print(response.text)
response = chat.send_message(
"What is the sum of the first 50 prime numbers? "
"Generate and run code for the calculation, and make sure you get all 50."
)
for part in response.candidates[0].content.parts:
if part.text is not None:
print(part.text)
if part.executable_code is not None:
print(part.executable_code.code)
if part.code_execution_result is not None:
print(part.code_execution_result.output)
JavaScript
import {GoogleGenAI} from "@google/genai";
const ai = new GoogleGenAI({});
const chat = ai.chats.create({
model: "gemini-3-flash-preview",
history: [
{
role: "user",
parts: [{ text: "I have a math question for you:" }],
},
{
role: "model",
parts: [{ text: "Great! I'm ready for your math question. Please ask away." }],
},
],
config: {
tools: [{codeExecution:{}}],
}
});
const response = await chat.sendMessage({
message: "What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and make sure you get all 50."
});
console.log("Chat response:", response.text);
Идти
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
Tools: []*genai.Tool{
{CodeExecution: &genai.ToolCodeExecution{}},
},
}
chat, _ := client.Chats.Create(
ctx,
"gemini-3-flash-preview",
config,
nil,
)
result, _ := chat.SendMessage(
ctx,
genai.Part{Text: "What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and " +
"make sure you get all 50.",
},
)
fmt.Println(result.Text())
fmt.Println(result.ExecutableCode())
fmt.Println(result.CodeExecutionResult())
}
ОТДЫХ
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{"tools": [{"code_execution": {}}],
"contents": [
{
"role": "user",
"parts": [{
"text": "Can you print \"Hello world!\"?"
}]
},{
"role": "model",
"parts": [
{
"text": ""
},
{
"executable_code": {
"language": "PYTHON",
"code": "\nprint(\"hello world!\")\n"
}
},
{
"code_execution_result": {
"outcome": "OUTCOME_OK",
"output": "hello world!\n"
}
},
{
"text": "I have printed \"hello world!\" using the provided python code block. \n"
}
],
},{
"role": "user",
"parts": [{
"text": "What is the sum of the first 50 prime numbers? Generate and run code for the calculation, and make sure you get all 50."
}]
}
]
}'
Ввод/вывод (I/O)
Начиная с Gemini 2.0 Flash , выполнение кода поддерживает ввод файлов и вывод графиков. Используя эти возможности ввода и вывода, вы можете загружать CSV-файлы и текстовые файлы, задавать вопросы о файлах и получать графики Matplotlib в качестве части ответа. Выходные файлы возвращаются в виде встроенных изображений в ответе.
Ценообразование ввода/вывода
При использовании операций ввода-вывода для выполнения кода взимается плата за входные и выходные токены:
Входные токены:
- Запрос пользователя
Выходные токены:
- Код, сгенерированный моделью.
- Результаты выполнения кода в среде выполнения кода
- Мыслительные жетоны
- Сводная информация, сгенерированная моделью.
Подробности ввода/вывода
При работе с операциями ввода-вывода при выполнении кода следует учитывать следующие технические детали:
- Максимальное время выполнения среды выполнения кода составляет 30 секунд.
- Если в среде выполнения кода возникает ошибка, модель может принять решение о повторной генерации выходных данных кода. Это может происходить до 5 раз.
- Максимальный размер входного файла ограничен окном токенов модели. В AI Studio, использующей Gemini Flash 2.0, максимальный размер входного файла составляет 1 миллион токенов (примерно 2 МБ для текстовых файлов поддерживаемых типов ввода). Если вы загрузите файл слишком большого размера, AI Studio не позволит вам его отправить.
- Наилучшие результаты выполнения кода достигаются при работе с текстовыми и CSV-файлами.
- Входной файл может быть передан в
part.inlineDataилиpart.fileData(загружается через Files API ), а выходной файл всегда возвращается в форматеpart.inlineData.
| Один поворот | Двунаправленный (многорежимный API в реальном времени) | |
|---|---|---|
| Поддерживаемые модели | Все модели Gemini 2.0 и 2.5 | Только экспериментальные модели Flash |
| Поддерживаемые типы ввода файлов | .png, .jpeg, .csv, .xml, .cpp, .java, .py, .js, .ts | .png, .jpeg, .csv, .xml, .cpp, .java, .py, .js, .ts |
| Поддерживаемые библиотеки для построения графиков | Matplotlib, seaborn | Matplotlib, seaborn |
| Использование нескольких инструментов | Да (только выполнение кода и заземление) | Да |
Выставление счетов
За включение выполнения кода через API Gemini дополнительная плата не взимается. Оплата будет производиться по текущему тарифу на входные и выходные токены в зависимости от используемой вами модели Gemini.
Вот еще несколько моментов, которые следует знать о выставлении счетов за выполнение кода:
- С вас взимается плата только один раз за входные токены, которые вы передаете модели, и плата взимается за конечные выходные токены, возвращаемые вам моделью.
- Токены, представляющие сгенерированный код, учитываются как выходные токены. Сгенерированный код может включать текст и мультимодальный вывод, например, изображения.
- Результаты выполнения кода также учитываются как выходные токены.
Модель выставления счетов представлена на следующей диаграмме:
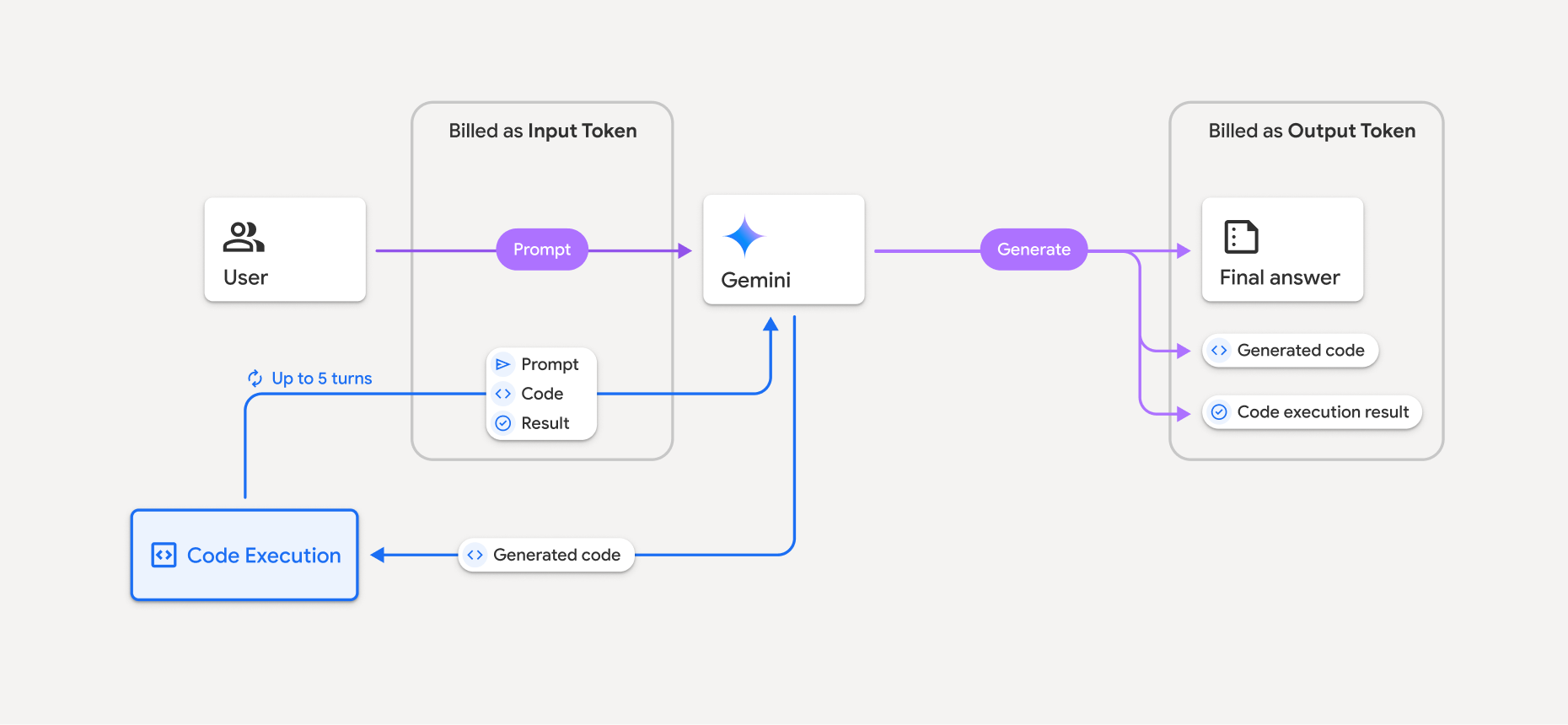
- С вас взимается плата по текущему тарифу за входящие и исходящие токены в соответствии с используемой вами моделью Gemini.
- Если Gemini использует выполнение кода при генерации вашего ответа, исходный запрос, сгенерированный код и результат выполнения кода помечаются как промежуточные токены и оплачиваются как входные токены .
- Затем Gemini генерирует сводку и возвращает сгенерированный код, результат выполнения кода и итоговую сводку. Эти данные оплачиваются как выходные токены .
- API Gemini включает в ответ API промежуточный счетчик токенов, поэтому вы знаете, почему получаете дополнительные входные токены помимо первоначального запроса.
Ограничения
- Модель может только генерировать и выполнять код. Она не может возвращать другие артефакты, такие как медиафайлы.
- В некоторых случаях включение выполнения кода может привести к регрессии в других областях вывода модели (например, при написании истории).
- Способность различных моделей успешно использовать выполнение кода несколько различается.
Поддерживаемые комбинации инструментов
Инструмент выполнения кода можно комбинировать с функцией Grounding with Google Search для реализации более сложных сценариев использования.
Поддерживаемые библиотеки
Среда выполнения кода включает следующие библиотеки:
- атрибуты
- шахматы
- контурный
- fpdf
- геопанды
- изображение
- jinja2
- joblib
- jsonschema
- jsonschema-specifications
- lxml
- matplotlib
- mpmath
- numpy
- opencv-python
- openpyxl
- упаковка
- панды
- подушка
- протобуф
- пилатекс
- pyparsing
- PyPDF2
- python-dateutil
- python-docx
- python-pptx
- репортабл
- scikit-learn
- сципи
- морской
- шесть
- striprtf
- симпи
- составить таблицу
- тензорфлоу
- инструмент
- XLRD
Вы не можете установить собственные библиотеки.
Что дальше?
- Попробуйте выполнить код в Colab .
- Узнайте о других инструментах Gemini API: