Gemini Robotics-ER 1.6 to model wizualno-językowy (VLM), który przenosi możliwości agenta Gemini do robotyki. Został on zaprojektowany z myślą o zaawansowanym rozumowaniu w świecie fizycznym, dzięki czemu roboty mogą interpretować złożone dane wizualne, przeprowadzać rozumowanie przestrzenne i planować działania na podstawie poleceń w języku naturalnym.
Jeśli korzystasz z Gemini Robotics-ER 1.5, możesz zacząć używać modelu 1.6, zastępując nazwę modelu w wywołaniu interfejsu API z model="gemini-robotics-er-1.5-preview" na model="gemini-robotics-er-1.6-preview".
Najważniejsze funkcje i korzyści:
- Ulepszona autonomia: roboty mogą rozumować, dostosowywać się i reagować na zmiany w otwartych środowiskach.
- Interakcja w języku naturalnym: ułatwia korzystanie z robotów, umożliwiając przypisywanie złożonych zadań za pomocą języka naturalnego.
- Orkiestracja zadań: rozkłada polecenia w języku naturalnym na podzadania i integruje się z istniejącymi kontrolerami i zachowaniami robotów, aby wykonywać zadania długoterminowe.
- Wszechstronne możliwości: lokalizuje i identyfikuje obiekty, rozumie relacje między nimi, planuje chwytanie i trajektorie oraz interpretuje dynamiczne sceny.
W tym dokumencie opisujemy działanie modelu i przedstawiamy kilka przykładów, które pokazują jego możliwości.
Jeśli chcesz od razu zacząć, możesz wypróbować model w Google AI Studio.
Bezpieczeństwo
Gemini Robotics-ER 1.6 został zaprojektowany z myślą o bezpieczeństwie, ale to Ty ponosisz odpowiedzialność za utrzymanie bezpiecznego środowiska wokół robota. Modele generatywnej AI mogą popełniać błędy, a roboty fizyczne mogą powodować uszkodzenia. Bezpieczeństwo jest dla nas priorytetem, a zapewnienie bezpieczeństwa modeli generatywnej AI podczas używania ich w rzeczywistych robotach to aktywny i kluczowy obszar naszych badań. Więcej informacji znajdziesz na stronie Google DeepMind poświęconej bezpieczeństwu robotów.
Pierwsze kroki: znajdowanie obiektów w scenie
Poniższy przykład pokazuje typowe zastosowanie robotyki. Pokazuje, jak przekazać do modelu obraz i prompt tekstowy za pomocą metody generateContent, aby uzyskać listę zidentyfikowanych obiektów z odpowiadającymi im punktami 2D.
Model zwraca punkty dla elementów zidentyfikowanych na obrazie, podając ich znormalizowane współrzędne 2D i etykiety.
Możesz użyć tego wyniku w interfejsie Robotics API lub wywołać model wizyjno-językowo-działaniowy (VLA) albo inne funkcje zdefiniowane przez użytkownika, aby wygenerować działania, które robot ma wykonać.
Python
from google import genai
from google.genai import types
PROMPT = """
Point to no more than 10 items in the image. The label returned
should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format
normalized to 0-1000.
"""
client = genai.Client()
# Load your image
with open("my-image.png", 'rb') as f:
image_bytes = f.read()
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/png',
),
PROMPT
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
REST
# First, ensure you have the image file locally.
# Encode the image to base64
IMAGE_BASE64=$(base64 -w 0 my-image.png)
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-robotics-er-1.6-preview:generateContent \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{
"parts": [
{
"inlineData": {
"mimeType": "image/png",
"data": "'"${IMAGE_BASE64}"'"
}
},
{
"text": "Point to no more than 10 items in the image. The label returned should be an identifying name for the object detected. The answer should follow the json format: [{\"point\": [y, x], \"label\": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000."
}
]
}
],
"generationConfig": {
"temperature": 0.5,
"thinkingConfig": {
"thinkingBudget": 0
}
}
}'
Dane wyjściowe będą tablicą JSON zawierającą obiekty, z których każdy będzie miał point (znormalizowane współrzędne [y, x]) i label identyfikujące obiekt.
JSON
[
{"point": [376, 508], "label": "small banana"},
{"point": [287, 609], "label": "larger banana"},
{"point": [223, 303], "label": "pink starfruit"},
{"point": [435, 172], "label": "paper bag"},
{"point": [270, 786], "label": "green plastic bowl"},
{"point": [488, 775], "label": "metal measuring cup"},
{"point": [673, 580], "label": "dark blue bowl"},
{"point": [471, 353], "label": "light blue bowl"},
{"point": [492, 497], "label": "bread"},
{"point": [525, 429], "label": "lime"}
]
Na tym obrazie widać, jak mogą być wyświetlane te punkty:

Jak to działa
Gemini Robotics-ER 1.6 umożliwia robotom kontekstowe działanie w świecie fizycznym dzięki rozumieniu przestrzennemu. Przyjmuje dane wejściowe w postaci obrazów, filmów i audio oraz promptów w języku naturalnym, aby:
- Rozumienie obiektów i kontekstu sceny: identyfikuje obiekty i określa ich relację ze sceną, w tym ich możliwości.
- Rozumienie instrukcji dotyczących zadań: interpretuje zadania podane w języku naturalnym, np. „znajdź banana”.
- Rozumieć przestrzeń i czas: rozumieć sekwencje działań i sposób, w jaki obiekty wchodzą w interakcje ze sceną w czasie.
- Podaj dane wyjściowe w formie strukturalnej: zwraca współrzędne (punkty lub ramki ograniczające) reprezentujące lokalizacje obiektów.
Umożliwia to robotom „widzenie” i „rozumienie” otoczenia w sposób programowy.
Gemini Robotics-ER 1.6 to także model agentowy, co oznacza, że może dzielić złożone zadania (np. „włóż jabłko do miski”) na podzadania, aby koordynować zadania długoterminowe:
- Sekwencjonowanie zadań podrzędnych: rozkłada polecenia na logiczną sekwencję kroków.
- Wywoływanie funkcji/wykonywanie kodu: wykonuje kroki, wywołując istniejące funkcje/narzędzia robota lub wykonując wygenerowany kod.
Więcej informacji o tym, jak działa wywoływanie funkcji w Gemini, znajdziesz na stronie Wywoływanie funkcji.
Korzystanie z budżetu na myślenie w przypadku Gemini Robotics-ER 1.6
Gemini Robotics-ER 1.6 ma elastyczny budżet na myślenie, który pozwala kontrolować kompromis między opóźnieniem a dokładnością. W przypadku zadań związanych z rozumieniem przestrzennym, takich jak wykrywanie obiektów, model może osiągać wysoką skuteczność przy niewielkim budżecie na myślenie. Bardziej złożone zadania wymagające rozumowania, takie jak liczenie i szacowanie wagi, wymagają większego budżetu na myślenie. Pozwala to zrównoważyć potrzebę uzyskiwania odpowiedzi o niskim poziomie opóźnienia z wysoką dokładnością wyników w przypadku bardziej złożonych zadań.
Więcej informacji o budżetach na myślenie znajdziesz na stronie z myśleniem jako podstawową funkcją.
Standardowe rozumowanie przestrzenne
Poniższe przykłady pokazują zadania związane z percepcją robotów i rozumowaniem przestrzennym przy użyciu promptów w języku naturalnym, od wskazywania i znajdowania obiektów na obrazie po planowanie trajektorii. Dla uproszczenia fragmenty kodu w tych przykładach zostały skrócone, aby pokazywać tylko prompt i wywołanie interfejsu API generate_content.
Pełny kod, który można uruchomić, oraz dodatkowe przykłady znajdziesz w książce kucharskiej dotyczącej robotyki.
Wskazywanie obiektów
Wskazywanie i wyszukiwanie obiektów na obrazach lub klatkach wideo to typowe zastosowanie modeli wizualno-językowych w robotyce. W tym przykładzie model ma znaleźć konkretne obiekty na obrazie i zwrócić ich współrzędne.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
queries = [
"bread",
"starfruit",
"banana",
]
prompt = f"""
Get all points matching the following objects: {', '.join(queries)}. The
label returned should be an identifying name for the object detected.
The answer should follow the json format:
[{{"point": , "label": }}, ...]. The points are in
[y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Dane wyjściowe będą podobne do przykładu na początek, czyli będą zawierać plik JSON ze współrzędnymi znalezionych obiektów i ich etykietami.
[
{"point": [671, 317], "label": "bread"},
{"point": [738, 307], "label": "bread"},
{"point": [702, 237], "label": "bread"},
{"point": [629, 307], "label": "bread"},
{"point": [833, 800], "label": "bread"},
{"point": [609, 663], "label": "banana"},
{"point": [770, 483], "label": "starfruit"}
]

Użyj tego prompta, aby poprosić model o interpretowanie abstrakcyjnych kategorii, takich jak „owoc”, zamiast konkretnych obiektów i znalezienie wszystkich wystąpień na obrazie.
Python
prompt = f"""
Get all points for fruit. The label returned should be an identifying
name for the object detected.
""" + """The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...]. The points are in
[y, x] format normalized to 0-1000."""
Na stronie rozumienie obrazu znajdziesz inne techniki przetwarzania obrazu.
Śledzenie obiektów w filmie
Gemini Robotics-ER 1.6 może też analizować klatki wideo, aby śledzić obiekty w czasie. Listę obsługiwanych formatów wideo znajdziesz w sekcji Dane wejściowe wideo.
Oto podstawowy prompt używany do znajdowania konkretnych obiektów w każdej klatce analizowanej przez model:
Python
# Define the objects to find
queries = [
"pen (on desk)",
"pen (in robot hand)",
"laptop (opened)",
"laptop (closed)",
]
base_prompt = f"""
Point to the following objects in the provided image: {', '.join(queries)}.
The answer should follow the json format:
[{{"point": , "label": }}, ...].
The points are in [y, x] format normalized to 0-1000.
If no objects are found, return an empty JSON list [].
"""
Dane wyjściowe pokazują śledzenie pióra i laptopa w klatkach filmu.
![]()
Pełny kod, który można uruchomić, znajdziesz w książce kucharskiej dotyczącej robotyki.
Wykrywanie obiektów i ramki ograniczające
Oprócz pojedynczych punktów model może też zwracać 2-wymiarowe ramki ograniczające, czyli prostokątne obszary otaczające obiekt.
W tym przykładzie żądamy dwuwymiarowych ramek ograniczających dla rozpoznawalnych obiektów na stole. Model ma ograniczyć liczbę obiektów do 25 i nadawać unikalne nazwy wielu instancjom.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return bounding boxes as a JSON array with labels. Never return masks
or code fencing. Limit to 25 objects. Include as many objects as you
can identify on the table.
If an object is present multiple times, name them according to their
unique characteristic (colors, size, position, unique characteristics, etc..).
The format should be as follows: [{"box_2d": [ymin, xmin, ymax, xmax],
"label": <label for the object>}] normalized to 0-1000. The values in
box_2d must only be integers
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Poniżej znajdują się ramki zwrócone przez model.
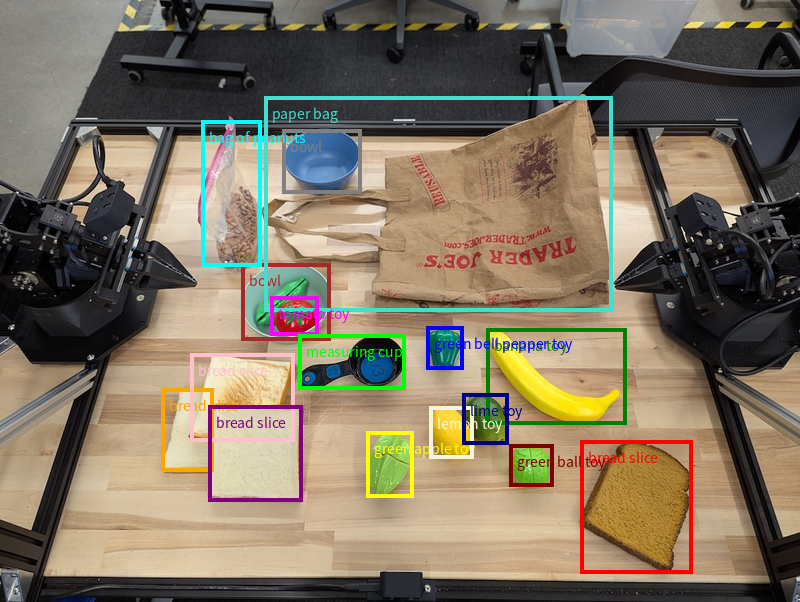
Pełny kod, który można uruchomić, znajdziesz w książce kucharskiej Robotics. Na stronie Rozumienie obrazów znajdziesz też dodatkowe przykłady zadań wizualnych, takich jak wykrywanie obiektów i przykłady pól ograniczających.
Trajektorie
Gemini Robotics-ER 1.6 może generować sekwencje punktów, które definiują trajektorię, co jest przydatne do sterowania ruchem robota.
W tym przykładzie wysyłamy prośbę o trajektorię, która pozwoli przesunąć czerwony długopis do organizera. Zawiera ona punkt początkowy i serię punktów pośrednich.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
points_data = []
prompt = """
Place a point on the red pen, then 15 points for the trajectory of
moving the red pen to the top of the organizer on the left.
The points should be labeled by order of the trajectory, from '0'
(start point at left hand) to <n> (final point)
The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(image_response.text)
Odpowiedź to zestaw współrzędnych opisujących trajektorię ścieżki, po której powinien poruszać się czerwony długopis, aby wykonać zadanie polegające na przesunięciu go na organizer:
[
{"point": [550, 610], "label": "0"},
{"point": [500, 600], "label": "1"},
{"point": [450, 590], "label": "2"},
{"point": [400, 580], "label": "3"},
{"point": [350, 550], "label": "4"},
{"point": [300, 520], "label": "5"},
{"point": [250, 490], "label": "6"},
{"point": [200, 460], "label": "7"},
{"point": [180, 430], "label": "8"},
{"point": [160, 400], "label": "9"},
{"point": [140, 370], "label": "10"},
{"point": [120, 340], "label": "11"},
{"point": [110, 320], "label": "12"},
{"point": [105, 310], "label": "13"},
{"point": [100, 305], "label": "14"},
{"point": [100, 300], "label": "15"}
]

Możliwości agentowe
Poniższe przykłady pokazują zaawansowane rozumowanie robotyczne z wykorzystaniem funkcji agentowych modelu, a w szczególności wykonywania kodu. W takich przypadkach model może zdecydować się na napisanie i wykonanie kodu Pythona, aby manipulować obrazami (np. powiększać, przycinać lub obracać), co pozwala rozwiązać niejasności lub zwiększyć precyzję przed udzieleniem odpowiedzi.
Wykrywanie obiektów (powiększanie i przycinanie)
Poniższy przykład pokazuje, jak za pomocą wykonania kodu powiększyć i przyciąć obraz, aby uzyskać wyraźniejszy widok podczas wykrywania obiektów i zwracania obwiedni.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return JSON in the format {label: val, y: val, x: val, y2: val, x2: val} for
the compostable objects in this scene. Please Zoom and crop the image for a
clearer view. Return an annotated image of the final result with the bounding
boxes drawn on it to the API caller as a part of your process.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Dane wyjściowe modelu będą podobne do tych:
[
{"label": "compostable", "y": 256, "x": 482, "y2": 295, "x2": 546},
{"label": "compostable", "y": 317, "x": 478, "y2": 350, "x2": 542},
{"label": "compostable", "y": 586, "x": 556, "y2": 668, "x2": 595},
{"label": "compostable", "y": 463, "x": 669, "y2": 511, "x2": 718},
{"label": "compostable", "y": 178, "x": 565, "y2": 250, "x2": 609}
]
Poniżej znajdują się ramki zwrócone przez model.

odczytywanie wskaźnika analogowego i stosowanie logiki;
Poniższy przykład pokazuje, jak używać modelu do odczytywania analogowego wskaźnika i wykonywania obliczeń czasu. Wykorzystuje instrukcję systemową, aby wymusić dane wyjściowe w formacie JSON.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('clock.jpg', 'rb') as f:
image_bytes = f.read()
q_time = """
Tell me what the value is. Please respond in the following JSON format:\n {\n "hours": X,\n "minutes": Y,\n}. Zoom in or crop as necessary to confirm location of the clock hands.
"""
system_instruction = "Be precise. When JSON is requested, reply with ONLY that JSON (no preface, no code block)."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
system_instruction + " " + q_time
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(response.text)
Poniżej znajdziesz przykładowy obraz wejściowy.

Dane wyjściowe modelu będą podobne do tych:
Time Response: {
"hours": 12,
"minutes": 44
}
Pomiar płynu w pojemniku
Przykład poniżej pokazuje, jak za pomocą wykonania kodu odczytać licznik i obliczyć poziom cieczy w procentach.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('meter.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
How full is the meter of liquid?
To read it,
1) Find the points for the top of the sight window, bottom of the sight window and the liquid level, formatted as [y, x] with values ranging from 0-1000;
2) Use math to determine the liquid level as a percentage;
3) Output "Answer: ??" on a separate line, where ?? is a number without % or unit.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Poniżej znajduje się powiększony obraz wejściowy.

Odczytywanie oznaczeń na płytce drukowanej
Poniższy przykład pokazuje, jak używać wykonywania kodu do odczytywania tekstu na chipie płytki drukowanej, co umożliwia modelowi powiększanie, przycinanie i obracanie obrazu w razie potrzeby.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('circuit_board.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = "What is the number on the ESMT chip? Zoom, crop, and rotate if needed."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Poniżej znajduje się powiększony obraz wejściowy.

Adnotacja do obrazu
Poniższy przykład pokazuje, jak za pomocą wykonania kodu dodać adnotacje do obrazu (np. narysować strzałki z instrukcjami utylizacji) i zwrócić zmodyfikowany obraz.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Look at this image and return it as an annotated version using arrows of
different colors to represent which items should go in which bins for
disposal. You must return the final image to the API caller.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Poniżej znajdziesz przykładowy obraz wejściowy.

Dane wyjściowe modelu będą podobne do tych:
The annotated image shows the suggested disposal locations for the items on the table:
- **Green bin (Compost/Organic)**: Green chili, red chili, grapes, and cherries.
- **Blue bin (Recycling)**: Yellow crushed can and plastic container.
- **Black bin (Trash)**: Chocolate bar wrapper, Welch's packet, and white tissue.
Administracja
Gemini Robotics-ER 1.6 może wykonywać planowanie zadań i rozumowanie przestrzenne wyższego poziomu, wnioskując o działaniach lub określając optymalne lokalizacje na podstawie zrozumienia kontekstu w celu koordynowania zadań długoterminowych.
Zrobienie miejsca na laptopa
Ten przykład pokazuje, jak Gemini Robotics-ER może analizować przestrzeń. Prompt prosi model o określenie, który obiekt należy przesunąć, aby zrobić miejsce na inny element.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Point to the object that I need to remove to make room for my laptop
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Odpowiedź zawiera współrzędne 2D obiektu, który odpowiada na pytanie użytkownika, w tym przypadku obiektu, który powinien się przesunąć, aby zrobić miejsce na laptopa.
[
{"point": [672, 301], "label": "The object that I need to remove to make room for my laptop"}
]

Pakowanie lunchu
Model może też podawać instrukcje dotyczące zadań wieloetapowych i wskazywać odpowiednie obiekty na każdym etapie. Ten przykład pokazuje, jak model planuje serię kroków, aby spakować lunch.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-of-lunch.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Explain how to pack the lunch box and lunch bag. Point to each
object that you refer to. Each point should be in the format:
[{"point": [y, x], "label": }], where the coordinates are
normalized between 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Odpowiedzią na ten prompt jest zestaw instrukcji krok po kroku dotyczących pakowania torby na lunch na podstawie obrazu.
Obraz wejściowy

Dane wyjściowe modelu
Based on the image, here is a plan to pack the lunch box and lunch bag:
1. **Pack the fruit into the lunch box.** Place the [apple](apple), [banana](banana), [red grapes](red grapes), and [green grapes](green grapes) into the [blue lunch box](blue lunch box).
2. **Add the spoon to the lunch box.** Put the [blue spoon](blue spoon) inside the lunch box as well.
3. **Close the lunch box.** Secure the lid on the [blue lunch box](blue lunch box).
4. **Place the lunch box inside the lunch bag.** Put the closed [blue lunch box](blue lunch box) into the [brown lunch bag](brown lunch bag).
5. **Pack the remaining items into the lunch bag.** Place the [blue snack bar](blue snack bar) and the [brown snack bar](brown snack bar) into the [brown lunch bag](brown lunch bag).
Here is the list of objects and their locations:
* [{"point": [899, 440], "label": "apple"}]
* [{"point": [814, 363], "label": "banana"}]
* [{"point": [727, 470], "label": "red grapes"}]
* [{"point": [675, 608], "label": "green grapes"}]
* [{"point": [706, 529], "label": "blue lunch box"}]
* [{"point": [864, 517], "label": "blue spoon"}]
* [{"point": [499, 401], "label": "blue snack bar"}]
* [{"point": [614, 705], "label": "brown snack bar"}]
* [{"point": [448, 501], "label": "brown lunch bag"}]
Wywoływanie niestandardowego interfejsu API robota
Ten przykład pokazuje orkiestrację zadań za pomocą niestandardowego interfejsu API robota. Wprowadza on interfejs API do symulacji operacji typu pick-and-place. Zadanie polega na podniesieniu niebieskiego klocka i umieszczeniu go w pomarańczowej misce:

Podobnie jak w przypadku innych przykładów na tej stronie, pełny kod, który można uruchomić, jest dostępny w książce kucharskiej dotyczącej robotyki.
Pierwszym krokiem jest zlokalizowanie obu produktów za pomocą tego promptu:
Python
prompt = """
Locate and point to the blue block and the orange bowl. The label
returned should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
Odpowiedź modelu zawiera znormalizowane współrzędne bloku i miski:
[
{"point": [389, 252], "label": "orange bowl"},
{"point": [727, 659], "label": "blue block"}
]
W tym przykładzie używamy tego interfejsu API robota:
Python
def move(x, y, high):
print(f"moving to coordinates: {x}, {y}, {15 if high else 5}")
def setGripperState(opened):
print("Opening gripper" if opened else "Closing gripper")
def returnToOrigin():
print("Returning to origin pose")
Następnym krokiem jest wywołanie sekwencji funkcji interfejsu API z logiką niezbędną do wykonania działania. Poniższy prompt zawiera opis interfejsu API robota, którego model powinien używać podczas koordynowania tego zadania.
Python
prompt = f"""
You are a robotic arm with six degrees-of-freedom. You have the
following functions available to you:
def move(x, y, high):
# moves the arm to the given coordinates. The boolean value 'high' set
to True means the robot arm should be lifted above the scene for
avoiding obstacles during motion. 'high' set to False means the robot
arm should have the gripper placed on the surface for interacting with
objects.
def setGripperState(opened):
# Opens the gripper if opened set to true, otherwise closes the gripper
def returnToOrigin():
# Returns the robot to an initial state. Should be called as a cleanup
operation.
The origin point for calculating the moves is at normalized point
y={robot_origin_y}, x={robot_origin_x}. Use this as the new (0,0) for
calculating moves, allowing x and y to be negative.
Perform a pick and place operation where you pick up the blue block at
normalized coordinates ({block_x}, {block_y}) (relative coordinates:
{block_relative_x}, {block_relative_y}) and place it into the orange
bowl at normalized coordinates ({bowl_x}, {bowl_y})
(relative coordinates: {bowl_relative_x}, {bowl_relative_y}).
Provide the sequence of function calls as a JSON list of objects, where
each object has a "function" key (the function name) and an "args" key
(a list of arguments for the function).
Also, include your reasoning before the JSON output.
For example:
Reasoning: To pick up the block, I will first move the arm to a high
position above the block, open the gripper, move down to the block,
close the gripper, lift the arm, move to a high position above the bowl,
move down to the bowl, open the gripper, and then lift the arm back to
a high position.
"""
Poniżej znajdziesz możliwe dane wyjściowe modelu na podstawie prompta i mockowego interfejsu API robota. Dane wyjściowe obejmują proces myślowy modelu i zaplanowane przez niego zadania. Wyświetla też wyniki wywołań funkcji robota, które model połączył w sekwencję.
Reasoning: To perform the pick and place operation, I will first move the
robotic arm to a high position above the blue block to ensure clearance. Then, I
will open the gripper in preparation for grasping. Next, I will lower the arm to
the surface level to position the gripper around the block and close the gripper
to secure it. After picking up the block, I will lift the arm to clear the
surface and move towards the orange bowl, maintaining a high position to avoid
collisions. Once positioned above the bowl, I will lower the arm to place the
block inside. I will then open the gripper to release the block. Finally, I will
lift the arm out of the bowl and call `returnToOrigin` to reset the robot's
state.
[
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
163,
427,
false
]
},
{
"function": "setGripperState",
"args": [
false
]
},
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "move",
"args": [
-247,
90,
false
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "returnToOrigin",
"args": []
}
]
Executing Function Calls:
moving to coordinates: 163, 427, 15
Opening gripper
moving to coordinates: 163, 427, 5
Closing gripper
moving to coordinates: 163, 427, 15
moving to coordinates: -247, 90, 15
moving to coordinates: -247, 90, 5
Opening gripper
moving to coordinates: -247, 90, 15
Returning to origin pose
Sprawdzone metody
Aby zoptymalizować wydajność i dokładność aplikacji robotycznych, musisz wiedzieć, jak skutecznie korzystać z modelu Gemini. W tej sekcji znajdziesz sprawdzone metody i kluczowe strategie tworzenia promptów, obsługi danych wizualnych i strukturyzowania zadań, które pozwolą Ci uzyskać najbardziej wiarygodne wyniki.
Używaj jasnego i prostego języka.
Korzystaj z języka naturalnego: model Gemini został zaprojektowany tak, aby rozumieć język naturalny, konwersacyjny. Twórz prompty w sposób semantycznie jasny, który odzwierciedla naturalny sposób wydawania instrukcji przez człowieka.
Używaj powszechnie stosowanej terminologii: wybieraj powszechnie stosowany język zamiast żargonu technicznego lub specjalistycznego. Jeśli model nie reaguje na określony termin zgodnie z oczekiwaniami, spróbuj użyć bardziej powszechnego synonimu.
Zoptymalizuj dane wizualne.
Powiększanie, aby zobaczyć szczegóły: w przypadku obiektów, które są małe lub trudne do odróżnienia na szerszym ujęciu, użyj funkcji ramki ograniczającej, aby wyodrębnić interesujący Cię obiekt. Następnie możesz przyciąć obraz do tego wyboru i przesłać nowy, wykadrowany obraz do modelu, aby uzyskać bardziej szczegółową analizę.
Eksperymentuj z oświetleniem i kolorami: na percepcję modelu mogą wpływać trudne warunki oświetleniowe i słaby kontrast kolorów.
Podziel złożone problemy na mniejsze etapy. Rozpatrując każdy mniejszy krok z osobna, możesz poprowadzić model do bardziej precyzyjnego i skutecznego wyniku.
Zwiększanie dokładności dzięki konsensusowi. W przypadku zadań wymagających dużej precyzji możesz wysyłać do modelu zapytania wielokrotnie z tym samym promptem. Uśredniając zwrócone wyniki, możesz uzyskać „konsensus”, który jest często dokładniejszy i bardziej wiarygodny.
Ograniczenia
Podczas tworzenia aplikacji z użyciem Gemini Robotics-ER 1.6 pamiętaj o tych ograniczeniach:
- Stan podglądu: model jest obecnie w podglądzie. Interfejsy API i funkcje mogą ulec zmianie, dlatego bez dokładnego przetestowania mogą nie nadawać się do aplikacji o krytycznym znaczeniu dla produkcji.
- Opóźnienie: złożone zapytania, dane wejściowe o wysokiej rozdzielczości lub obszerne
thinking_budgetmogą wydłużyć czas przetwarzania. - Halucynacje: podobnie jak wszystkie duże modele językowe, Gemini Robotics-ER 1.6 może czasami „halucynować”, czyli podawać nieprawidłowe informacje, zwłaszcza w przypadku niejednoznacznych promptów lub danych wejściowych spoza zakresu.
- Zależność od jakości prompta: jakość wyników modelu jest w dużym stopniu uzależniona od jasności i szczegółowości prompta wejściowego. Niejasne lub źle sformułowane prompty mogą prowadzić do uzyskania niezadowalających wyników.
- Koszt obliczeniowy: uruchamianie modelu, zwłaszcza w przypadku danych wejściowych w postaci filmów lub wysokich wartości
thinking_budget, zużywa zasoby obliczeniowe i generuje koszty. Więcej informacji znajdziesz na stronie Myślenie. - Typy danych wejściowych: szczegółowe informacje o ograniczeniach w przypadku każdego trybu znajdziesz w tych artykułach:
Informacje na temat ochrony prywatności
Przyjmujesz do wiadomości, że modele, o których mowa w tym dokumencie („Modele robotyczne”), wykorzystują dane wideo i audio do działania i poruszania sprzętem zgodnie z Twoimi instrukcjami. W związku z tym możesz używać modeli robotów w taki sposób, aby zbierały dane od osób, które można zidentyfikować, takie jak dane głosowe, obrazy i dane dotyczące podobieństwa („Dane osobowe”). Jeśli zdecydujesz się korzystać z modeli robotów w sposób, który umożliwia zbieranie danych osobowych, nie możesz zezwolić żadnym osobom, których tożsamość można ustalić, na interakcję z modelami robotów ani na przebywanie w ich pobliżu, dopóki nie zostaną one odpowiednio poinformowane o tym, że ich dane osobowe mogą być przekazywane do Google i wykorzystywane przez Google zgodnie z Dodatkowymi warunkami korzystania z interfejsu Gemini API, które znajdziesz na stronie https://ai.google.dev/gemini-api/terms (dalej „Warunki”), w tym zgodnie z sekcją zatytułowaną „Jak Google wykorzystuje Twoje dane”. Zapewnisz, że takie powiadomienie zezwala na zbieranie i wykorzystywanie danych osobowych w sposób określony w Warunkach, oraz podejmiesz uzasadnione z komercyjnego punktu widzenia starania, aby zminimalizować zbieranie i rozpowszechnianie danych osobowych, stosując techniki takie jak rozmywanie twarzy i używając modeli robotów w obszarach, w których nie ma osób umożliwiających identyfikację, w największym możliwym zakresie.
Ceny
Szczegółowe informacje o cenach i dostępnych regionach znajdziesz na stronie cennika.
Wersje modelu
Robotics-ER 1.6 (wersja testowa)
| Właściwość | Opis |
|---|---|
| Kod modelu | gemini-robotics-er-1.6-preview |
| Obsługiwane typy danych |
Dane wejściowe Tekst, obrazy, filmy, dźwięk Dane wyjściowe Tekst |
| Limity tokenów[*] |
Limit tokenów wejściowych 131 072 Limit tokenów wyjściowych 65 536 |
| Uprawnienia | Nieobsługiwane Zapisywanie w pamięci podręcznej Obsługiwane Obsługiwane Obsługiwane Obsługiwane Obsługiwane Grounding z użyciem Map Google Obsługiwane Nieobsługiwane Nieobsługiwane Obsługiwane Ustrukturyzowane dane wyjściowe Obsługiwane Obsługiwane Obsługiwane |
| Opcje wykorzystania |
Obsługiwane Obsługiwane Obsługiwane |
| wersje |
|
| Ostatnia aktualizacja | Grudzień 2025 r. |
| Granica wiedzy | Styczeń 2025 r. |
Dalsze kroki
- Poznaj inne możliwości i eksperymentuj z różnymi promptami i danymi wejściowymi, aby odkryć więcej zastosowań Gemini Robotics-ER 1.6. Więcej przykładów znajdziesz w tym Colabie dotyczącym pierwszych kroków z robotyką.
- Dowiedz się, jak modele Gemini Robotics zostały stworzone z myślą o bezpieczeństwie. Odwiedź stronę Google DeepMind poświęconą bezpieczeństwu robotów.
- Najnowsze informacje o modelach Gemini Robotics znajdziesz na stronie docelowej Gemini Robotics.