Gemini Robotics-ER 1.6 ist ein Vision-Language-Modell (VLM), das die Agent-Funktionen von Gemini für die Robotik nutzt. Es wurde für fortschrittliches logisches Denken in der physischen Welt entwickelt und ermöglicht es Robotern, komplexe visuelle Daten zu interpretieren, räumliche Schlussfolgerungen zu ziehen und Aktionen aus Befehlen in natürlicher Sprache zu planen.
Wenn Sie Gemini Robotics-ER 1.5 verwendet haben, können Sie das Modell 1.6 verwenden, indem Sie im API-Aufruf den Modellnamen von model="gemini-robotics-er-1.5-preview" in model="gemini-robotics-er-1.6-preview" ändern.
Wichtige Funktionen und Vorteile:
- Erweiterte Autonomie:Roboter können in offenen Umgebungen Schlussfolgerungen ziehen, sich anpassen und auf Veränderungen reagieren.
- Interaktion in natürlicher Sprache:Roboter sind einfacher zu bedienen, da komplexe Aufgaben in natürlicher Sprache zugewiesen werden können.
- Aufgabenorchestrierung:Zerlegt Befehle in natürlicher Sprache in untergeordnete Aufgaben und lässt sich in vorhandene Robotersteuerungen und Verhaltensweisen integrieren, um Aufgaben mit langer Zeitspanne zu erledigen.
- Vielseitige Funktionen:Objekte lokalisieren und identifizieren, Beziehungen zwischen Objekten verstehen, Greifvorgänge und Trajektorien planen und dynamische Szenen interpretieren.
In diesem Dokument wird die Funktionsweise des Modells beschrieben und es werden mehrere Beispiele vorgestellt, die die agentenähnlichen Funktionen des Modells verdeutlichen.
Wenn Sie gleich loslegen möchten, können Sie das Modell in Google AI Studio ausprobieren.
In Google AI Studio ausprobieren
Sicherheit
Gemini Robotics-ER 1.6 wurde mit Blick auf die Sicherheit entwickelt. Es liegt jedoch in Ihrer Verantwortung, für eine sichere Umgebung rund um den Roboter zu sorgen. Modelle für generative KI können Fehler machen und physische Roboter können Schäden verursachen. Sicherheit hat für uns Priorität. Deshalb ist es ein aktiver und wichtiger Bereich unserer Forschung, generative KI-Modelle sicher zu machen, wenn sie mit realen Robotern verwendet werden. Weitere Informationen finden Sie auf der Google DeepMind-Seite zur Robotersicherheit.
Erste Schritte: Objekte in einer Szene finden
Das folgende Beispiel veranschaulicht einen häufigen Anwendungsfall in der Robotik. Darin wird gezeigt, wie Sie mit der Methode generateContent ein Bild und einen Text-Prompt an das Modell übergeben, um eine Liste der erkannten Objekte mit den entsprechenden 2D-Punkten zu erhalten.
Das Modell gibt Punkte für Elemente zurück, die es in einem Bild erkannt hat, sowie deren normalisierte 2D-Koordinaten und Labels.
Sie können diese Ausgabe mit einer Robotics API verwenden oder ein VLA-Modell (Vision-Language-Action) oder andere benutzerdefinierte Drittanbieterfunktionen aufrufen, um Aktionen für einen Roboter zu generieren.
Python
from google import genai
from google.genai import types
PROMPT = """
Point to no more than 10 items in the image. The label returned
should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format
normalized to 0-1000.
"""
client = genai.Client()
# Load your image
with open("my-image.png", 'rb') as f:
image_bytes = f.read()
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/png',
),
PROMPT
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
REST
# First, ensure you have the image file locally.
# Encode the image to base64
IMAGE_BASE64=$(base64 -w 0 my-image.png)
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-robotics-er-1.6-preview:generateContent \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{
"parts": [
{
"inlineData": {
"mimeType": "image/png",
"data": "'"${IMAGE_BASE64}"'"
}
},
{
"text": "Point to no more than 10 items in the image. The label returned should be an identifying name for the object detected. The answer should follow the json format: [{\"point\": [y, x], \"label\": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000."
}
]
}
],
"generationConfig": {
"temperature": 0.5,
"thinkingConfig": {
"thinkingBudget": 0
}
}
}'
Die Ausgabe ist ein JSON-Array mit Objekten, die jeweils ein point (normalisierte [y, x]-Koordinaten) und ein label zur Identifizierung des Objekts enthalten.
JSON
[
{"point": [376, 508], "label": "small banana"},
{"point": [287, 609], "label": "larger banana"},
{"point": [223, 303], "label": "pink starfruit"},
{"point": [435, 172], "label": "paper bag"},
{"point": [270, 786], "label": "green plastic bowl"},
{"point": [488, 775], "label": "metal measuring cup"},
{"point": [673, 580], "label": "dark blue bowl"},
{"point": [471, 353], "label": "light blue bowl"},
{"point": [492, 497], "label": "bread"},
{"point": [525, 429], "label": "lime"}
]
Das folgende Bild zeigt ein Beispiel dafür, wie diese Punkte dargestellt werden können:

Funktionsweise
Mit Gemini Robotics-ER 1.6 können Ihre Roboter die physische Welt mithilfe von räumlichem Verständnis in den Kontext setzen und darin arbeiten. Es verwendet Bild-, Video- und Audioeingaben sowie Prompts in natürlicher Sprache, um:
- Objekte und Szenenkontext verstehen: Erkennt Objekte und analysiert ihre Beziehung zur Szene, einschließlich ihrer Affordanzen.
- Aufgabenanweisungen verstehen: Interpretiert Aufgaben, die in natürlicher Sprache formuliert sind, z. B. „Finde die Banane“.
- Räumlich und zeitlich denken: Abläufe von Aktionen und die Interaktion von Objekten mit einer Szene im Zeitverlauf verstehen.
- Strukturierte Ausgabe bereitstellen: Gibt Koordinaten (Punkte oder Begrenzungsrahmen) zurück, die Objektpositionen darstellen.
So können Roboter ihre Umgebung programmatisch „sehen“ und „verstehen“.
Gemini Robotics-ER 1.6 ist auch agentisch. Das bedeutet, dass es komplexe Aufgaben (z. B. „Lege den Apfel in die Schüssel“) in Unteraufgaben aufteilen kann, um langfristige Aufgaben zu koordinieren:
- Unteraufgaben sequenzieren: Befehle werden in eine logische Abfolge von Schritten zerlegt.
- Funktionsaufrufe/Codeausführung: Führt Schritte aus, indem vorhandene Roboterfunktionen/-tools aufgerufen oder generierter Code ausgeführt wird.
Weitere Informationen zu Funktionsaufrufen mit Gemini
Thinking Budget mit Gemini Robotics-ER 1.6 verwenden
Gemini Robotics-ER 1.6 verfügt über ein flexibles Denkbudget, mit dem Sie die Kompromisse zwischen Latenz und Genauigkeit steuern können. Bei Aufgaben zum räumlichen Verständnis wie der Objekterkennung kann das Modell mit einem kleinen Denkbudget eine hohe Leistung erzielen. Komplexere Aufgaben wie das Zählen und die Gewichtsschätzung profitieren von einem größeren Denkbudget. So können Sie den Bedarf an Antworten mit geringer Latenz mit Ergebnissen mit hoher Genauigkeit für anspruchsvollere Aufgaben in Einklang bringen.
Weitere Informationen zu Denkbudgets finden Sie auf der Seite mit den wichtigsten Funktionen für die Denkphase.
Standardmäßiges räumliches Denken
Die folgenden Beispiele veranschaulichen Aufgaben für robotic perception und räumliches Denken mit Prompts in natürlicher Sprache, die von der Identifizierung und Suche von Objekten in einem Bild bis hin zur Planung von Trajektorien reichen. Der Einfachheit halber wurden die Code-Snippets in diesen Beispielen so gekürzt, dass nur der Prompt und der Aufruf der generate_content API zu sehen sind.
Den vollständigen ausführbaren Code sowie zusätzliche Beispiele finden Sie im Robotics Cookbook.
Auf Objekte zeigen
Das Zeigen auf und Suchen von Objekten in Bildern oder Videoframes ist ein häufiger Anwendungsfall für Vision-and-Language-Modelle (VLMs) in der Robotik. Im folgenden Beispiel wird das Modell aufgefordert, bestimmte Objekte in einem Bild zu finden und ihre Koordinaten zurückzugeben.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
queries = [
"bread",
"starfruit",
"banana",
]
prompt = f"""
Get all points matching the following objects: {', '.join(queries)}. The
label returned should be an identifying name for the object detected.
The answer should follow the json format:
[{{"point": , "label": }}, ...]. The points are in
[y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Die Ausgabe wäre ähnlich wie im Beispiel für den Einstieg ein JSON-Objekt mit den Koordinaten der gefundenen Objekte und ihren Labels.
[
{"point": [671, 317], "label": "bread"},
{"point": [738, 307], "label": "bread"},
{"point": [702, 237], "label": "bread"},
{"point": [629, 307], "label": "bread"},
{"point": [833, 800], "label": "bread"},
{"point": [609, 663], "label": "banana"},
{"point": [770, 483], "label": "starfruit"}
]

Verwenden Sie den folgenden Prompt, um das Modell aufzufordern, abstrakte Kategorien wie „Obst“ anstelle bestimmter Objekte zu interpretieren und alle Instanzen im Bild zu finden.
Python
prompt = f"""
Get all points for fruit. The label returned should be an identifying
name for the object detected.
""" + """The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...]. The points are in
[y, x] format normalized to 0-1000."""
Weitere Bildverarbeitungstechniken
Objekte in einem Video verfolgen
Gemini Robotics-ER 1.6 kann auch Videoframes analysieren, um Objekte im Zeitverlauf zu verfolgen. Eine Liste der unterstützten Videoformate finden Sie unter Videoeingaben.
Das ist der Basis-Prompt, mit dem bestimmte Objekte in jedem Frame gefunden werden, den das Modell analysiert:
Python
# Define the objects to find
queries = [
"pen (on desk)",
"pen (in robot hand)",
"laptop (opened)",
"laptop (closed)",
]
base_prompt = f"""
Point to the following objects in the provided image: {', '.join(queries)}.
The answer should follow the json format:
[{{"point": , "label": }}, ...].
The points are in [y, x] format normalized to 0-1000.
If no objects are found, return an empty JSON list [].
"""
Die Ausgabe zeigt, wie ein Stift und ein Laptop in den Videoframes verfolgt werden.
![]()
Den vollständigen ausführbaren Code finden Sie im Robotics Cookbook.
Objekterkennung und Begrenzungsrahmen
Das Modell kann nicht nur einzelne Punkte, sondern auch 2D-Markierungsrahmen zurückgeben, die einen rechteckigen Bereich um ein Objekt darstellen.
In diesem Beispiel werden 2D-Begrenzungsrahmen für identifizierbare Objekte auf einem Tisch angefordert. Das Modell wird angewiesen, die Ausgabe auf 25 Objekte zu beschränken und mehrere Instanzen eindeutig zu benennen.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return bounding boxes as a JSON array with labels. Never return masks
or code fencing. Limit to 25 objects. Include as many objects as you
can identify on the table.
If an object is present multiple times, name them according to their
unique characteristic (colors, size, position, unique characteristics, etc..).
The format should be as follows: [{"box_2d": [ymin, xmin, ymax, xmax],
"label": <label for the object>}] normalized to 0-1000. The values in
box_2d must only be integers
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Im Folgenden sehen Sie die vom Modell zurückgegebenen Begrenzungsrahmen.
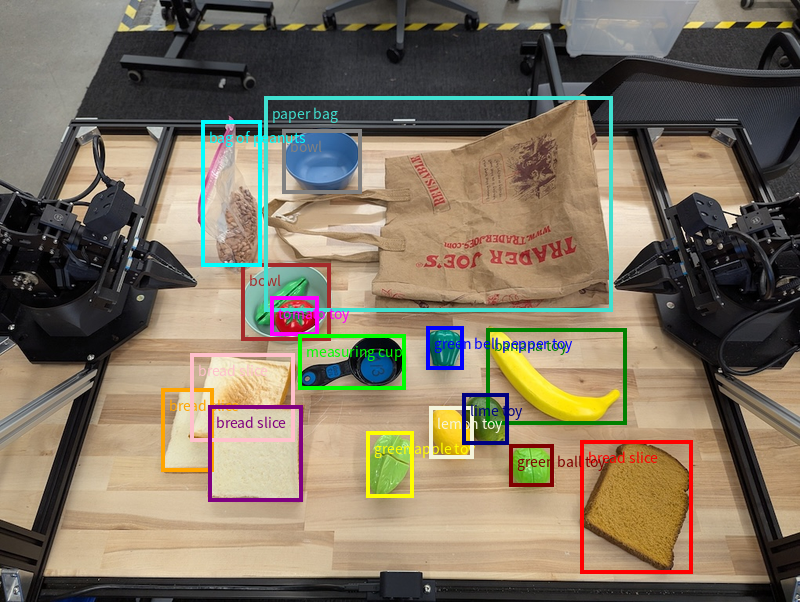
Den vollständigen ausführbaren Code finden Sie im Robotics Cookbook. Auf der Seite Bildanalyse finden Sie weitere Beispiele für visuelle Aufgaben wie Objekterkennung und Begrenzungsrahmen.
Trajektorien
Gemini Robotics-ER 1.6 kann Folgen von Punkten generieren, die eine Trajektorie definieren. Das ist nützlich, um Roboterbewegungen zu steuern.
In diesem Beispiel wird eine Trajektorie angefordert, um einen roten Stift zu einem Organizer zu bewegen. Dazu werden der Startpunkt und eine Reihe von Zwischenpunkten angegeben.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
points_data = []
prompt = """
Place a point on the red pen, then 15 points for the trajectory of
moving the red pen to the top of the organizer on the left.
The points should be labeled by order of the trajectory, from '0'
(start point at left hand) to <n> (final point)
The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(image_response.text)
Die Antwort ist eine Reihe von Koordinaten, die die Flugbahn des roten Stifts beschreiben, die er zurücklegen muss, um die Aufgabe zu erfüllen, ihn auf den Organizer zu bewegen:
[
{"point": [550, 610], "label": "0"},
{"point": [500, 600], "label": "1"},
{"point": [450, 590], "label": "2"},
{"point": [400, 580], "label": "3"},
{"point": [350, 550], "label": "4"},
{"point": [300, 520], "label": "5"},
{"point": [250, 490], "label": "6"},
{"point": [200, 460], "label": "7"},
{"point": [180, 430], "label": "8"},
{"point": [160, 400], "label": "9"},
{"point": [140, 370], "label": "10"},
{"point": [120, 340], "label": "11"},
{"point": [110, 320], "label": "12"},
{"point": [105, 310], "label": "13"},
{"point": [100, 305], "label": "14"},
{"point": [100, 300], "label": "15"}
]

Agentische Funktionen
Die folgenden Beispiele veranschaulichen das erweiterte Robotic Reasoning mit den Agent-Funktionen des Modells, insbesondere die Codeausführung. In diesen Szenarien kann das Modell entscheiden, Python-Code zu schreiben und auszuführen, um Bilder zu bearbeiten (z. B. durch Zoomen, Zuschneiden oder Drehen), um Unklarheiten zu beseitigen oder die Genauigkeit zu verbessern, bevor es antwortet.
Objekterkennung (Zoomen und Zuschneiden)
Das folgende Beispiel zeigt, wie Sie die Codeausführung verwenden, um ein Bild zu zoomen und zuzuschneiden, damit Objekte besser erkannt und Begrenzungsrahmen zurückgegeben werden können.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return JSON in the format {label: val, y: val, x: val, y2: val, x2: val} for
the compostable objects in this scene. Please Zoom and crop the image for a
clearer view. Return an annotated image of the final result with the bounding
boxes drawn on it to the API caller as a part of your process.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Die Modellausgabe würde in etwa so aussehen:
[
{"label": "compostable", "y": 256, "x": 482, "y2": 295, "x2": 546},
{"label": "compostable", "y": 317, "x": 478, "y2": 350, "x2": 542},
{"label": "compostable", "y": 586, "x": 556, "y2": 668, "x2": 595},
{"label": "compostable", "y": 463, "x": 669, "y2": 511, "x2": 718},
{"label": "compostable", "y": 178, "x": 565, "y2": 250, "x2": 609}
]
Im Folgenden sehen Sie die vom Modell zurückgegebenen Begrenzungsrahmen.

Analoge Messgeräte ablesen und Logik anwenden
Das folgende Beispiel zeigt, wie Sie das Modell verwenden, um ein analoges Messgerät zu lesen und Zeitberechnungen durchzuführen. Dabei wird eine Systemanweisung verwendet, um eine JSON-Ausgabe zu erzwingen.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('clock.jpg', 'rb') as f:
image_bytes = f.read()
q_time = """
Tell me what the value is. Please respond in the following JSON format:\n {\n "hours": X,\n "minutes": Y,\n}. Zoom in or crop as necessary to confirm location of the clock hands.
"""
system_instruction = "Be precise. When JSON is requested, reply with ONLY that JSON (no preface, no code block)."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
system_instruction + " " + q_time
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(response.text)
Im Folgenden finden Sie ein Beispiel für eine Bildeingabe.

Die Modellausgabe würde in etwa so aussehen:
Time Response: {
"hours": 12,
"minutes": 44
}
Flüssigkeit in einem Behälter messen
Das folgende Beispiel zeigt, wie Sie die Codeausführung verwenden, um einen Zähler auszulesen und den Flüssigkeitsstand in Prozent zu berechnen.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('meter.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
How full is the meter of liquid?
To read it,
1) Find the points for the top of the sight window, bottom of the sight window and the liquid level, formatted as [y, x] with values ranging from 0-1000;
2) Use math to determine the liquid level as a percentage;
3) Output "Answer: ??" on a separate line, where ?? is a number without % or unit.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Unten sehen Sie eine vergrößerte Version des Eingabebilds.

Markierungen auf einer Leiterplatte lesen
Im folgenden Beispiel wird gezeigt, wie Sie die Codeausführung verwenden, um Text auf einem Chip auf einer Leiterplatte zu lesen. Das Modell kann das Bild nach Bedarf zoomen, zuschneiden und drehen.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('circuit_board.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = "What is the number on the ESMT chip? Zoom, crop, and rotate if needed."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Unten sehen Sie eine vergrößerte Version des Eingabebilds.

Bildannotation
Das folgende Beispiel zeigt, wie Sie die Codeausführung verwenden, um ein Bild mit Anmerkungen zu versehen (z.B. durch Zeichnen von Pfeilen für Entsorgungsanweisungen) und das geänderte Bild zurückzugeben.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Look at this image and return it as an annotated version using arrows of
different colors to represent which items should go in which bins for
disposal. You must return the final image to the API caller.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Im Folgenden finden Sie ein Beispiel für eine Bildeingabe.

Die Modellausgabe würde in etwa so aussehen:
The annotated image shows the suggested disposal locations for the items on the table:
- **Green bin (Compost/Organic)**: Green chili, red chili, grapes, and cherries.
- **Blue bin (Recycling)**: Yellow crushed can and plastic container.
- **Black bin (Trash)**: Chocolate bar wrapper, Welch's packet, and white tissue.
Orchestrierung
Gemini Robotics-ER 1.6 kann Aufgaben planen und räumliche Schlussfolgerungen auf höherer Ebene ziehen. Es kann Aktionen ableiten oder optimale Standorte auf Grundlage des Kontextes ermitteln, um Aufgaben mit langem Horizont zu koordinieren.
Platz für einen Laptop schaffen
In diesem Beispiel wird gezeigt, wie Gemini Robotics-ER über einen Raum nachdenken kann. Der Prompt fordert das Modell auf, zu ermitteln, welches Objekt verschoben werden muss, um Platz für ein anderes Element zu schaffen.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Point to the object that I need to remove to make room for my laptop
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Die Antwort enthält eine 2D-Koordinate des Objekts, das die Frage des Nutzers beantwortet. In diesem Fall ist es das Objekt, das verschoben werden soll, um Platz für einen Laptop zu schaffen.
[
{"point": [672, 301], "label": "The object that I need to remove to make room for my laptop"}
]

Lunchpaket packen
Das Modell kann auch Anleitungen für mehrstufige Aufgaben geben und für jeden Schritt auf relevante Objekte verweisen. In diesem Beispiel wird gezeigt, wie das Modell eine Reihe von Schritten zum Packen einer Lunchbox plant.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-of-lunch.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Explain how to pack the lunch box and lunch bag. Point to each
object that you refer to. Each point should be in the format:
[{"point": [y, x], "label": }], where the coordinates are
normalized between 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Die Antwort auf diesen Prompt ist eine Schritt-für-Schritt-Anleitung zum Packen einer Lunchbox anhand der Bildeingabe.
Eingabebild

Modellausgabe
Based on the image, here is a plan to pack the lunch box and lunch bag:
1. **Pack the fruit into the lunch box.** Place the [apple](apple), [banana](banana), [red grapes](red grapes), and [green grapes](green grapes) into the [blue lunch box](blue lunch box).
2. **Add the spoon to the lunch box.** Put the [blue spoon](blue spoon) inside the lunch box as well.
3. **Close the lunch box.** Secure the lid on the [blue lunch box](blue lunch box).
4. **Place the lunch box inside the lunch bag.** Put the closed [blue lunch box](blue lunch box) into the [brown lunch bag](brown lunch bag).
5. **Pack the remaining items into the lunch bag.** Place the [blue snack bar](blue snack bar) and the [brown snack bar](brown snack bar) into the [brown lunch bag](brown lunch bag).
Here is the list of objects and their locations:
* [{"point": [899, 440], "label": "apple"}]
* [{"point": [814, 363], "label": "banana"}]
* [{"point": [727, 470], "label": "red grapes"}]
* [{"point": [675, 608], "label": "green grapes"}]
* [{"point": [706, 529], "label": "blue lunch box"}]
* [{"point": [864, 517], "label": "blue spoon"}]
* [{"point": [499, 401], "label": "blue snack bar"}]
* [{"point": [614, 705], "label": "brown snack bar"}]
* [{"point": [448, 501], "label": "brown lunch bag"}]
Benutzerdefinierte Roboter-API aufrufen
In diesem Beispiel wird die Aufgabenorchestration mit einer benutzerdefinierten Roboter-API veranschaulicht. Sie enthält eine Mock-API, die für einen Pick-and-Place-Vorgang entwickelt wurde. Die Aufgabe besteht darin, einen blauen Block aufzunehmen und in eine orangefarbene Schale zu legen:

Ähnlich wie bei den anderen Beispielen auf dieser Seite ist der vollständige ausführbare Code im Robotics Cookbook verfügbar.
Im ersten Schritt müssen Sie beide Artikel mit dem folgenden Prompt finden:
Python
prompt = """
Locate and point to the blue block and the orange bowl. The label
returned should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
Die Modellantwort enthält die normalisierten Koordinaten des Blocks und der Schale:
[
{"point": [389, 252], "label": "orange bowl"},
{"point": [727, 659], "label": "blue block"}
]
In diesem Beispiel wird die folgende Mock-Roboter-API verwendet:
Python
def move(x, y, high):
print(f"moving to coordinates: {x}, {y}, {15 if high else 5}")
def setGripperState(opened):
print("Opening gripper" if opened else "Closing gripper")
def returnToOrigin():
print("Returning to origin pose")
Im nächsten Schritt wird eine Folge von API-Funktionen mit der erforderlichen Logik aufgerufen, um die Aktion auszuführen. Der folgende Prompt enthält eine Beschreibung der Roboter-API, die das Modell bei der Orchestrierung dieser Aufgabe verwenden soll.
Python
prompt = f"""
You are a robotic arm with six degrees-of-freedom. You have the
following functions available to you:
def move(x, y, high):
# moves the arm to the given coordinates. The boolean value 'high' set
to True means the robot arm should be lifted above the scene for
avoiding obstacles during motion. 'high' set to False means the robot
arm should have the gripper placed on the surface for interacting with
objects.
def setGripperState(opened):
# Opens the gripper if opened set to true, otherwise closes the gripper
def returnToOrigin():
# Returns the robot to an initial state. Should be called as a cleanup
operation.
The origin point for calculating the moves is at normalized point
y={robot_origin_y}, x={robot_origin_x}. Use this as the new (0,0) for
calculating moves, allowing x and y to be negative.
Perform a pick and place operation where you pick up the blue block at
normalized coordinates ({block_x}, {block_y}) (relative coordinates:
{block_relative_x}, {block_relative_y}) and place it into the orange
bowl at normalized coordinates ({bowl_x}, {bowl_y})
(relative coordinates: {bowl_relative_x}, {bowl_relative_y}).
Provide the sequence of function calls as a JSON list of objects, where
each object has a "function" key (the function name) and an "args" key
(a list of arguments for the function).
Also, include your reasoning before the JSON output.
For example:
Reasoning: To pick up the block, I will first move the arm to a high
position above the block, open the gripper, move down to the block,
close the gripper, lift the arm, move to a high position above the bowl,
move down to the bowl, open the gripper, and then lift the arm back to
a high position.
"""
Das Folgende zeigt eine mögliche Ausgabe des Modells basierend auf dem Prompt und der Mock-Roboter-API. Die Ausgabe enthält den Denkprozess des Modells und die Aufgaben, die es daraufhin geplant hat. Außerdem wird die Ausgabe der Roboterfunktionsaufrufe angezeigt, die das Modell nacheinander ausgeführt hat.
Reasoning: To perform the pick and place operation, I will first move the
robotic arm to a high position above the blue block to ensure clearance. Then, I
will open the gripper in preparation for grasping. Next, I will lower the arm to
the surface level to position the gripper around the block and close the gripper
to secure it. After picking up the block, I will lift the arm to clear the
surface and move towards the orange bowl, maintaining a high position to avoid
collisions. Once positioned above the bowl, I will lower the arm to place the
block inside. I will then open the gripper to release the block. Finally, I will
lift the arm out of the bowl and call `returnToOrigin` to reset the robot's
state.
[
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
163,
427,
false
]
},
{
"function": "setGripperState",
"args": [
false
]
},
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "move",
"args": [
-247,
90,
false
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "returnToOrigin",
"args": []
}
]
Executing Function Calls:
moving to coordinates: 163, 427, 15
Opening gripper
moving to coordinates: 163, 427, 5
Closing gripper
moving to coordinates: 163, 427, 15
moving to coordinates: -247, 90, 15
moving to coordinates: -247, 90, 5
Opening gripper
moving to coordinates: -247, 90, 15
Returning to origin pose
Best Practices
Um die Leistung und Genauigkeit Ihrer Robotikanwendungen zu optimieren, ist es wichtig, dass Sie wissen, wie Sie effektiv mit dem Gemini-Modell interagieren. In diesem Abschnitt werden Best Practices und wichtige Strategien für das Erstellen von Prompts, den Umgang mit visuellen Daten und die Strukturierung von Aufgaben beschrieben, um die zuverlässigsten Ergebnisse zu erzielen.
Verwenden Sie eine klare und einfache Sprache.
Natürliche Sprache verwenden: Das Gemini-Modell ist darauf ausgelegt, natürliche, konversationelle Sprache zu verstehen. Formulieren Sie Ihre Prompts so, dass sie semantisch klar sind und widerspiegeln, wie eine Person auf natürliche Weise Anweisungen geben würde.
Alltagssprache verwenden: Verwenden Sie eine einfache, alltägliche Sprache anstelle von Fachsprache oder Jargon. Wenn das Modell nicht wie erwartet auf einen bestimmten Begriff reagiert, versuchen Sie, ihn mit einem gängigeren Synonym umzuformulieren.
Visuelle Eingabe optimieren
Für Details heranzoomen: Wenn Sie es mit Objekten zu tun haben, die klein oder in einer Weitwinkelaufnahme schwer zu erkennen sind, verwenden Sie eine Begrenzungsrahmenfunktion, um das gewünschte Objekt zu isolieren. Sie können das Bild dann auf diese Auswahl zuschneiden und das neue, fokussierte Bild an das Modell senden, um eine detailliertere Analyse zu erhalten.
Mit Beleuchtung und Farbe experimentieren: Die Wahrnehmung des Modells kann durch schwierige Lichtverhältnisse und einen schlechten Farbkontrast beeinträchtigt werden.
Teilen Sie komplexe Probleme in kleinere Schritte auf. Wenn Sie jeden kleineren Schritt einzeln angehen, können Sie das Modell zu einem präziseren und erfolgreichen Ergebnis führen.
Genauigkeit durch Konsens verbessern Bei Aufgaben, die ein hohes Maß an Präzision erfordern, können Sie das Modell mit demselben Prompt mehrmals abfragen. Durch die Mittelung der zurückgegebenen Ergebnisse können Sie einen „Konsens“ erzielen, der oft genauer und zuverlässiger ist.
Beschränkungen
Beachten Sie beim Entwickeln mit Gemini Robotics-ER 1.6 die folgenden Einschränkungen:
- Vorschau:Das Modell befindet sich derzeit in der Vorschau. APIs und Funktionen können sich ändern und sind ohne gründliche Tests möglicherweise nicht für produktionskritische Anwendungen geeignet.
- Latenz:Komplexe Anfragen, Eingaben mit hoher Auflösung oder umfangreiche
thinking_budgetkönnen zu längeren Verarbeitungszeiten führen. - KI-Halluzinationen:Wie alle Large Language Models kann Gemini Robotics-ER 1.6 gelegentlich „halluzinieren“ oder falsche Informationen liefern, insbesondere bei mehrdeutigen Prompts oder Out-of-Distribution-Eingaben.
- Abhängigkeit von der Prompt-Qualität:Die Qualität der Ausgabe des Modells hängt stark von der Klarheit und Spezifität des Eingabe-Prompts ab. Vage oder schlecht strukturierte Prompts können zu suboptimalen Ergebnissen führen.
- Rechenkosten:Die Ausführung des Modells, insbesondere mit Videoeingaben oder hohem
thinking_budget, verbraucht Rechenressourcen und verursacht Kosten. Weitere Informationen finden Sie auf der Seite Thinking. - Eingabetypen:In den folgenden Abschnitten finden Sie Details zu den Einschränkungen für die einzelnen Modi.
Datenschutzhinweise
Sie bestätigen, dass die in diesem Dokument genannten Modelle (die „Robotikmodelle“) Video- und Audiodaten verwenden, um Ihre Hardware gemäß Ihren Anweisungen zu betreiben und zu bewegen. Sie dürfen die Robotikmodelle daher so betreiben, dass Daten von identifizierbaren Personen, z. B. Sprach-, Bild- und Ähnlichkeitsdaten („personenbezogene Daten“), von den Robotikmodellen erhoben werden. Wenn Sie die Robotikmodelle so betreiben, dass personenbezogene Daten erhoben werden, stimmen Sie zu, dass Sie keine identifizierbaren Personen mit den Robotikmodellen interagieren lassen oder sich in der Umgebung der Robotikmodelle aufhalten lassen, es sei denn, diese identifizierbaren Personen wurden ausreichend darüber informiert und haben zugestimmt, dass ihre personenbezogenen Daten an Google weitergegeben und von Google verwendet werden dürfen, wie in den zusätzlichen Nutzungsbedingungen für Gemini API unter https://ai.google.dev/gemini-api/terms (den „Nutzungsbedingungen“) beschrieben, einschließlich gemäß dem Abschnitt „Wie Google Ihre Daten verwendet“. Sie sorgen dafür, dass diese Mitteilung die Erhebung und Nutzung personenbezogener Daten gemäß den Nutzungsbedingungen erlaubt, und unternehmen wirtschaftlich angemessene Anstrengungen, um die Erhebung und Weitergabe personenbezogener Daten zu minimieren, indem Sie Techniken wie das Unkenntlichmachen von Gesichtern verwenden und die Robotikmodelle nach Möglichkeit in Bereichen betreiben, in denen sich keine identifizierbaren Personen aufhalten.
Preise
Detaillierte Informationen zu Preisen und verfügbaren Regionen finden Sie auf der Seite Preise.
Modellversionen
Robotics-ER 1.6 (Vorschau)
| Attribut | Beschreibung |
|---|---|
| Modellcode | gemini-robotics-er-1.6-preview |
| Unterstützte Datentypen |
Eingaben Text, Bilder, Video, Audio Ausgabe Text |
| Token-Limits[*] |
Eingabetokenlimit 131.072 Tokenausgabelimit 65.536 |
| Funktionen | Nicht unterstützt Unterstützt Unterstützt Unterstützt Unterstützt Unterstützt Unterstützt Nicht unterstützt Nicht unterstützt Unterstützt Unterstützt Unterstützt Unterstützt |
| Nutzungsoptionen |
Unterstützt Unterstützt Unterstützt |
| -Versionen |
|
| Letzte Aktualisierung | Dezember 2025 |
| Wissensstichtag | Januar 2025 |
Nächste Schritte
- Sehen Sie sich auch andere Funktionen an und experimentieren Sie weiter mit verschiedenen Prompts und Eingaben, um weitere Anwendungsfälle für Gemini Robotics-ER 1.6 zu finden. Weitere Beispiele finden Sie im Robotics Getting Started Colab.
- Weitere Informationen dazu, wie Gemini Robotics-Modelle mit Blick auf die Sicherheit entwickelt wurden, finden Sie auf dieser Seite.
- Aktuelle Informationen zu Gemini Robotics-Modellen finden Sie auf der Gemini Robotics-Landingpage.